目录
一、unordered_map 的基本介绍
二、unordered_set 的基本介绍
三、相关练习
3.1 - 在长度 2N 的数组中找出重复 N 次的元素
3.2 - 存在重复元素
3.3 - 两句话中的不常见单词
四、哈希表的查找
4.1 - 哈希表的基本概念
4.2 - 哈希函数的构造方法
4.3 - 处理冲突的方法
4.3.1 - 开放地址法
4.3.2 - 链地址法
五、unordered_map 和 unordered_set 的模拟实现
5.1 - HashTable.h
5.2 - unordered_map.h
5.3 - unordered_set.h
5.4 - test.cpp
一、unordered_map 的基本介绍
unordered_map 以类模板的形式定义在 <unordered_map> 头文件中,并位于 std 命名空间中。
template < class Key, // unordered_map::key_typeclass T, // unordered_map::mapped_typeclass Hash = hash<Key>, // unordered_map::hasherclass Pred = equal_to<Key>, // unordered_map::key_equalclass Alloc = allocator< pair<const Key,T> > // unordered_map::allocator_type> class unordered_map;unordered_map 是关联式容器,用于存储 <key, value> 键值对,并允许根据 key 快速检索到元素。
key 的类型为 key_type,即 Key;value 的类型为 mapped_type,即 T。
注意:
typedef pair<const Key, T> value_type;。
在 unordered_map 中,key 通常用于唯一标识元素,而 value 是一个内容与此 key 相关联的对象。key 和 value 的类型可能不同。
在内部,unordered_map 中的元素不会根据 key 或者 value 按任何特定顺序排序,而是根据哈希值(hash value)组织到桶中,以允许直接通过 key 快速访问元素(时间复杂度为常数阶)。
unordered_map 通过 key 访问元素的速度比 map 要快,尽管它通过其元素的子集进行范围迭代时通常效率更低。
unordered_map 实现了直接访问运算符(operator[]),它允许使用 key 作为参数直接访问 value。
unordered_map 的迭代器类型是前向迭代器(forward iterator)。
二、unordered_set 的基本介绍
unordered_set 以类模板的形式定义在 <unordered_set> 头文件中,并位于 std 命名空间中。
template < class Key, // unordered_set::key_type/value_typeclass Hash = hash<Key>, // unordered_set::hasherclass Pred = equal_to<Key>, // unordered_set::key_equalclass Alloc = allocator<Key> // unordered_set::allocator_typeunordered_set 是不按特定顺序存储唯一元素的容器,它允许根据元素的值快速检索元素。
在 unordered_set 中,元素的值同时也是其键值 key,它唯一标识元素。key 是不可变的,因此,unordered_set 中的元素不能在容器中修改一次,但是可以插入和删除元素。
key 的类型是 key_type/value_type,即 Key。
在内部,unordered_set 中的元素不按任何特定顺序排序,而是根据哈希值(hash value)组织到桶中,以允许直接通过 key 快速访问元素(时间复杂度为常数阶)。
unordered_set 通过 key 访问元素的速度比 set 要快,尽管它通过其元素的子集进行范围迭代时效率更低。
unordered_set 的迭代器类型是前向迭代器(forward iterator)。
三、相关练习
3.1 - 在长度 2N 的数组中找出重复 N 次的元素
class Solution {
public:int repeatedNTimes(vector<int>& nums) { // 统计每个元素出现的次数unordered_map<int, int> countMap;for (const auto& e : nums){++countMap[e];}
// 找出重复 N 次的元素size_t N = nums.size() / 2;for (const auto& kv : countMap){if (kv.second == N)return kv.first;}return -1;}
};3.2 - 存在重复元素
class Solution {
public:bool containsDuplicate(vector<int>& nums) {unordered_map<int, int> countMap;for (const auto& e : nums){if (++countMap[e] > 1)return true;}return false;}
};3.3 - 两句话中的不常见单词
class Solution {
public:vector<string> uncommonFromSentences(string s1, string s2) {unordered_map<string, int> countMap;string str;for (const auto& e : s1){if (e == ' '){++countMap[str];str.clear();}else{str.push_back(e);}}++countMap[str];str.clear();
for (const auto& e : s2){if (e == ' '){++countMap[str];str.clear();}else{str.push_back(e);}}++countMap[str];
vector<string> ret;for (const auto& kv : countMap){if (kv.second == 1)ret.push_back(kv.first);}return ret;}
};思路:
根据题目描述,我们需要找出 "在句子 s1 中恰好出现一次,但在句子 s2 中没有出现的单词",并找出 "在句子 s2 中恰好出现一次,但在句子 s1 中没有出现的单词",这其实等价于找出 "在两个句子中只出现一次的单词"。
四、哈希表的查找
4.1 - 哈希表的基本概念
我们之前所了解的查找方法都是以关键字的比较为基础的,在查找过程中只考虑各元素关键字之间的相对大小,元素在存储结构中的位置和其关键字无直接关系,查找的效率取决于查找过程中元素关键字的比较次数。当节点个数很多时,查找时要大量地与无效节点的关键字进行比较,致使查找速度很慢。
如果能在元素的存储位置和其关键字之间建立某种直接关系,那么在进行查找时,就无需做比较或做很少次的比较,按照这种关系直接由关键字找到对应的元素。
这就是哈希查找法(Hash Search)的思想,它通过对元素的关键字值进行某种运算,直接求出元素的地址,即使用关键字到地址的直接转换方法,而不需要反复比较。
hash n.剁碎的食物;混杂,拼凑;哈希;散列 --> 哈希查找法也叫作散列查找法。
哈希查找法中常用的几个术语:
-
哈希函数和哈希地址:在元素的存储位置 p 和其关键字 key 之间建立一个确定的对应关系 H,使 p = H(key),称这个对应关系 H 为哈希函数,p 为哈希地址。
-
哈希表(Hash Table):一个有限连续的地址空间,用以存储按哈希函数计算得到相应哈希地址的元素。通常哈希表的存储空间是一个一维数组,哈希地址是数组的下标。
-
冲突和同义词:对不同的关键字可能得到同一哈希地址,即
,而 H(key1) = H(key2),这种现象称为冲突。具有相同函数值的关键字对哈希函数来说称作同义词,key1 与 key2 互称为同义词。
哈希查找法主要研究以下两个方面的问题:
-
如何构造哈希函数;
-
如何处理冲突。
4.2 - 哈希函数的构造方法
构造一个 "好" 的哈希函数应遵循以下两条原则:
-
函数计算要简单,每一关键字只能有一个哈希地址与之对应;
-
函数的值域需在表长的范围内,计算出的哈希地址的分布应均匀,尽可能减少冲突。
下面介绍构造哈希函数的几种方法:
-
数学分析法:
如果事先知道关键字集合,且每个关键字的位数比哈希表的地址码位数多,每个关键字由 n 位数组成,如
,则可以从关键字中提取数字分布比较均匀的若干位作为哈希地址。
例如,如果以手机号码作为关键字,那么可以选择后四位作为哈希地址:

数学分析法的适用情况:事先必须明确知道所有的关键字每一位上各种数字的分布情况。
-
平方取中法:
通常在选定哈希函数时不一定能知道关键字的全部情况,取其中哪几位也不一定合适,而一个数平方后的中间几位和数的每一位都相关,如果取关键字平方后的中间几位或者其组合作为哈希地址,则使随机分布的关键字得到的哈希地址也是随机的,具体所取的位数由表长决定。
平方取中法的适用情况:不能事先了解关键字的所有情况,或难于直接从关键字中找到取值较分散的几位。
-
折叠法:
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址,这种方法称为折叠法。根据数位叠加的方式,可以把折叠法分为移位叠加和边界叠加。移位叠加是将分割后的每一部分的最低位对齐,然后相加;边界叠加是将相邻的部分沿边界来回折叠,然后对齐相加。
例如,当哈希表表长为 1000 时,关键字 key = 45387765213,从左到右按 3 位数一段分割,可以得到 4 个部分:453、877、652、13。分别采用移位叠加和边界叠加,求得哈希地址为 955 和 914。

折叠法的适用情况:适合于哈希地址的位数较少,而关键字的位数较多,且难于直接从关键字中找到取值较分散的几位。
-
直接定址法:
H(key) = a * key + b,其中 a 和 b 是常数。
这种方法计算最简单,且不会产生冲突,但它适合关键字的分布基本连续的情况,如果关键字分布不连续,空位较多,则会造成存储空间的浪费。
-
除留余数法:
设哈希表表长为 m,选择一个不大于 m 的数 p(即 p <= m),用 p 去除关键字,除后所得余数为哈希地址,即 H(key) = key % p。
这个方法的关键是选取适当的 p,一般情况下,可以选 p 为表长的最大质数,例如,表长 m = 100,可取 p = 97。
除留余数法计算简单,适用范围非常广,是最常用的构造哈希函数的方法。它不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模,这样能够保证哈希地址一定落在地址空间中。
4.3 - 处理冲突的方法
选择一个 "好" 的哈希函数可以在一定程度上减少冲突,但在实际应用中,很难完全避免发生冲突,所以选择一个有效的处理冲突的方法是哈希查找法的另一个关键问题。创建哈希表和查找哈希表都会遇到冲突,两种情况下处理冲突的方法应该一致。下面以创建哈希表为例,来说明处理冲突的两种方法:开放地址法和链地址法。
4.3.1 - 开放地址法
开放地址法的基本思想是:把元素都存储在哈希表数组中,当某一元素关键字 key 的初始哈希地址 H0 = H(key) 发生冲突时,以 H0 为基础,采取合适方法计算得到另一个地址 H1,如果 H1 仍然发生冲突,以 H1 为基础再求下一个地址 H2,若 H2 仍然发生冲突,再求得 H3。依次类推,直至 Hk 不发生冲突为止,则 Hk 为该元素在表中的哈希地址。
这种方法在寻找下一个空的哈希地址时,原来的数组空间对所有的元素都是开放的,所以被称为开放地址法。通常把寻找下一个空位的过程称为探测。上述方法可用如下公式表示:
其中,H(key) 是哈希函数,m 是哈希表表长, 为增量序列。根据 的取值不同,可分为以下 3 种探测方法。
-
线性探测法:
这种探测方法可以将哈希表假象成一个循环表,发生冲突时,从冲突地址的下一个单元顺序找空单元,如果到最后一个位置也没找到空单元,则回到表头开始继续查找,直到找到一个空位,就把此元素放入此空位中。如果找不到空位,则说明哈希表已满,需要进行溢出处理。实际上,不会在哈希表已满时才做处理。
哈希表的装载因子的定义为
= 表中填入的元素个数 / 哈希表的表长。
对于开放地址法,装载因子是特别重要的因素,应严格限制在 0.7 ~ 0.8 以下,例如 Java 的系统库限制了装载因子为 0.75,超过此值将 resize 哈希表。
#pragma once #include <utility> #include <vector> #include <string> // 给哈希表的每个地址空间做标记 enum State {EMPTY,EXISTENT,DELETED }; template<class K, class V> struct HashData {std::pair<K, V> _kv;State _state; HashData() : _state(EMPTY) { } }; // 将关键字 key 转换为无符号整型 template<class K> struct DefaultHashFunc {size_t operator()(const K& key){return (size_t)key;} }; template<> struct DefaultHashFunc<std::string> {size_t operator()(const std::string& str){// BKDRHashsize_t hash = 0;size_t seed = 131;for (const char& ch : str){hash = hash * seed + ch;}return hash;} }; template<class K, class V, class HashFunc = DefaultHashFunc<K>> class HashTable { public:HashTable(size_t defaultCapacity = 10): _table(defaultCapacity), _n(0){ } bool insert(const std::pair<K, V>& kv){HashFunc hf;size_t hashAddr = hf(kv.first) % _table.size();while (_table[hashAddr]._state == EXISTENT){if (_table[hashAddr]._kv.first == kv.first){return false;}// 线性探测hashAddr = (hashAddr + 1) % _table.size();}_table[hashAddr]._kv = kv;_table[hashAddr]._state = EXISTENT;++_n; // 将装载因子限制在 0.75 及以下if ((double)_n / _table.size() >= 0.75){HashTable<K, V> tmp(2 * _table.size());for (size_t i = 0; i < _table.size(); ++i){if (_table[i]._state == EXISTENT){tmp.insert(_table[i]._kv); // 复用}}_table.swap(tmp._table);}return true;} HashData<const K, V>* find(const K& key) const{HashFunc hf;size_t hashAddr = hf(key) % _table.size();while (_table[hashAddr]._state != EMPTY){if (_table[hashAddr]._state != DELETED &&_table[hashAddr]._kv.first == key){return (HashData<const K, V>*)&_table[hashAddr];}// 线性探测hashAddr = (hashAddr + 1) % _table.size();}return nullptr;} bool erase(const K& key){HashData<const K, V>* ret = find(key);if (ret){ret->_state = DELETED;--_n;return true;}return false;} private:std::vector<HashData<K, V>> _table; // 哈希表size_t _n; // 表中填入的元素个数 }; -
二次探测法:
-
伪随机探测法:
= 伪随机数序列
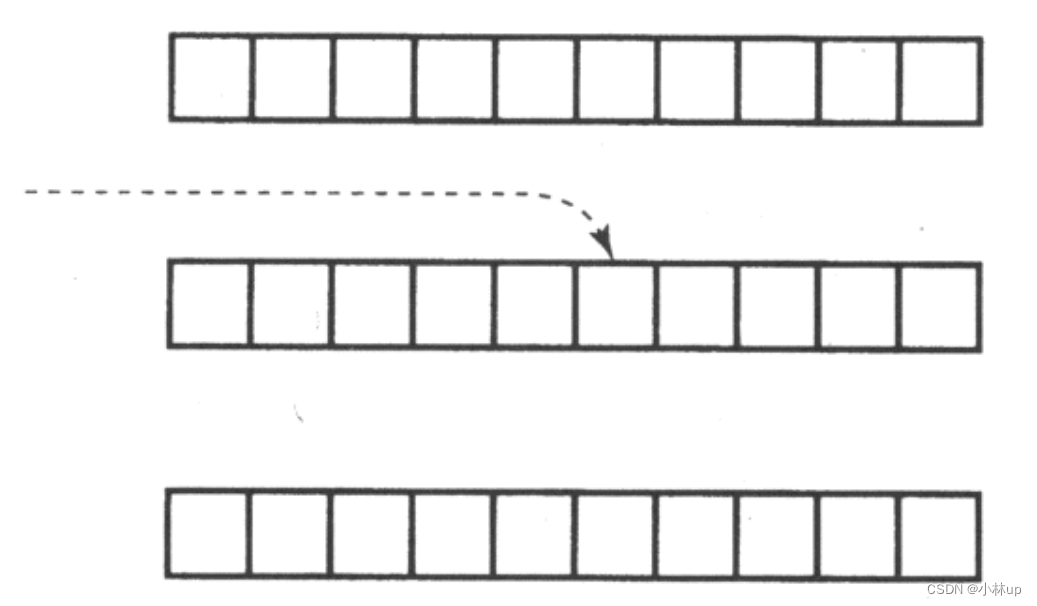
例如,哈希表的长度为 11,哈希函数 H(key) = key % 11,假设表中已填有关键字分别为 17、60、29 的元素,如下图 (a) 所示。现在要插入第四个元素,其关键字为 38,由哈希函数得到哈希地址为 5,产生冲突。
若用线性探测法处理,得到下一个地址 6,仍冲突;再求下一个地址 7,仍冲突;直到哈希地址为 8 的位置为 "空" 时,处理冲突的过程结束,38 填入哈希表中序号为 8 的位置,如下图 (b) 所示。
若用二次探测法处理,得到下一个地址 6,仍冲突;再求下一个地址 4,无冲突,38 填入序号为 4 的位置,如下图 (c) 所示。
若用伪随机探测法处理,假设产生的伪随机数为 9,则下一个哈希地址为 (5 + 9) % 11 = 3,无冲突,所以 38 填入序号为 3 的位置,如下图 (d) 所示。

从上述线性探测法处理的过程中可以看到一个现象:当表中 i,i+1,i+2 位置上已填有元素时,下一个哈希地址为 i,i+1,i+2 和 i+3 的元素都将填入 i+3 的位置,这种在处理冲突过程中发生的两个第一个哈希地址不同的元素争夺同一个后继哈希地址的现象称作 "二次堆积"(或称作 "堆积"),即在处理同义词的冲突过程中又添加了非同义词的冲突。
4.3.2 - 链地址法
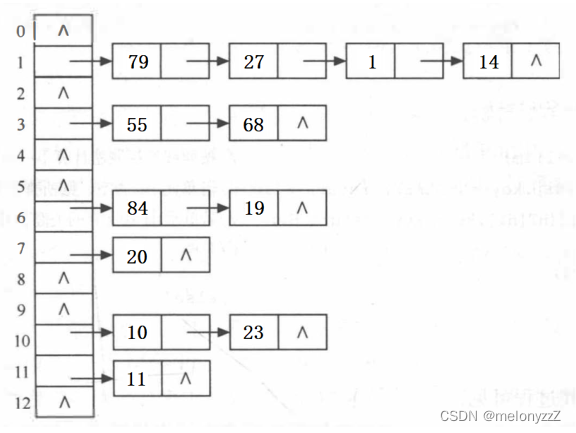
链地址法的基本思想是:把具有相同哈希地址的元素放在同一个单链表中,称为同义词链表。有 m 个哈希地址就有 m 个单链表,同时用数组 _table[0···m-1] 存放各个链表的头指针。
#pragma once
#include <utility>
#include <vector>
#include <string>
#include <iostream>
template<class K, class V>
struct HashNode
{std::pair<K, V> _kv;HashNode<K, V>* _next;
HashNode(const std::pair<K, V>& kv) : _kv(kv), _next(nullptr){ }
};
template<class K>
struct DefaultHashFunc
{size_t operator()(const K& key){return (size_t)key;}
};
template<>
struct DefaultHashFunc<std::string>
{size_t operator()(const std::string& str){// BKDRHashsize_t hash = 0;size_t seed = 131;for (const char& ch : str){hash = hash * seed + ch;}return hash;}
};
template<class K, class V, class HashFunc = DefaultHashFunc<K>>
class HashTable
{typedef HashNode<K, V> Node;
public:HashTable(size_t defaultCapacity = 13): _table(defaultCapacity, nullptr), _n(0){ }
~HashTable(){for (size_t i = 0; i < _table.size(); ++i){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}}
HashNode<const K, V>* find(const K& key) const{HashFunc hf;size_t hashAddr = hf(key) % _table.size();Node* cur = _table[hashAddr];while (cur){if (cur->_kv.first == key){return (HashNode<const K, V>*)cur;}cur = cur->_next;}return nullptr;}
bool insert(const std::pair<K, V>& kv){if (find(kv.first) != nullptr){return false;}
HashFunc hf;size_t hashAddr = hf(kv.first) % _table.size();// 头插Node* newnode = new Node(kv);newnode->_next = _table[hashAddr];_table[hashAddr] = newnode;++_n;
// 将装载因子限制在 1 及以下if (_n == _table.size()){size_t newSize = 2 * _table.size();std::vector<Node*> newTable(newSize, nullptr);for (size_t i = 0; i < _table.size(); ++i){Node* cur = _table[i];while (cur){Node* next = cur->_next;// 将 *cur 头插到新表中size_t hashAddr = hf(cur->_kv.first) % newSize;cur->_next = newTable[hashAddr];newTable[hashAddr] = cur;// 更新 curcur = next;}_table[i] = nullptr;}_table.swap(newTable);}return true;}
bool erase(const K& key){HashFunc hf;size_t hashAddr = hf(key) % _table.size();Node* prev = nullptr;Node* cur = _table[hashAddr];while (cur){if (cur->_kv.first == key){if (prev == nullptr){_table[hashAddr] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}
void print() const{for (size_t i = 0; i < _table.size(); ++i){printf("[%u]->", i);Node* cur = _table[i];while (cur){std::cout << "(" << cur->_kv.first << ","<< cur->_kv.second << ")" << "->";cur = cur->_next;}printf("nullptr\n");}}
private:std::vector<Node*> _table; // 哈希表size_t _n; // 表中填入的元素个数
};例如,已知一组关键字为 { 19, 14, 23, 1, 68, 20, 84, 27, 55, 11, 10, 79 },设哈希函数 H(key) = key % 13。
五、unordered_map 和 unordered_set 的模拟实现
5.1 - HashTable.h
#pragma once
#include <string>
#include <vector>
#include <utility>
namespace yzz
{template<class T>struct HashNode{T _data;HashNode<T>* _next;
HashNode(const T& data): _data(data), _next(nullptr){ }};
template<class K>struct DefaultHashFunc{size_t operator()(const K& key){return (size_t)key;}};
template<>struct DefaultHashFunc<std::string>{size_t operator()(const std::string& str){// BKDRHashsize_t hash = 0;size_t seed = 131;for (const char& ch : str){hash = hash * seed + ch;}return hash;}};
// 声明template<class K, class T, class KOfT, class HashFunc>class HashTable;
template<class K, class T, class KOfT, class HashFunc, class Ref, class Ptr>struct HashIterator{typedef HashNode<T> Node;typedef HashTable<K, T, KOfT, HashFunc> HashTable;typedef HashIterator<K, T, KOfT, HashFunc, T&, T*> iterator;typedef HashIterator<K, T, KOfT, HashFunc, Ref, Ptr> self;Node* _pnode;const HashTable* _pht;
HashIterator(Node* pnode, const HashTable* pht): _pnode(pnode), _pht(pht){ }
HashIterator(const iterator& it) : _pnode(it._pnode), _pht(it._pht){ }
Ref operator*() const{return _pnode->_data;}
Ptr operator->() const{return &_pnode->_data;}
self& operator++(){if (_pnode->_next){_pnode = _pnode->_next;}else{KOfT kot;HashFunc hf;size_t hashAddr = hf(kot(_pnode->_data)) % _pht->_table.size();int flag = 0;for (size_t i = hashAddr + 1; i < _pht->_table.size(); ++i){Node* cur = _pht->_table[i];if (cur){_pnode = cur;flag = 1;break;}}if (flag == 0){_pnode = nullptr;}}return *this;}
bool operator!=(const self& it) const{return _pnode != it._pnode;}};template<class K, class T, class KOfT, class HashFunc = DefaultHashFunc<K>>class HashTable{typedef HashNode<T> Node;
template<class K, class T, class KOfT, class HashFunc, class Ref, class Ptr>friend struct HashIterator;public:/*---------- 构造函数和析构函数 ----------*/HashTable(size_t defaultCapacity = 13): _table(defaultCapacity, nullptr), _n(0){ }
~HashTable(){for (size_t i = 0; i < _table.size(); ++i){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}}
/*---------- 迭代器 ----------*/typedef HashIterator<K, T, KOfT, HashFunc, T&, T*> iterator;typedef HashIterator<K, T, KOfT, HashFunc, const T&, const T*> const_iterator;
iterator begin(){for (size_t i = 0; i < _table.size(); ++i){Node* cur = _table[i];if (cur){return iterator(cur, this);}}return iterator(nullptr, this);}
iterator end(){return iterator(nullptr, this);}
const_iterator begin() const{for (size_t i = 0; i < _table.size(); ++i){Node* cur = _table[i];if (cur){return const_iterator(cur, this);}}return const_iterator(nullptr, this);}
const_iterator end() const{return const_iterator(nullptr, this);}
/*---------- 查找 ----------*/iterator find(const K& key){HashFunc hf;size_t hashAddr = hf(key) % _table.size();KOfT kot;Node* cur = _table[hashAddr];while (cur){if (kot(cur->_data) == key){return iterator(cur, this);}cur = cur->_next;}return iterator(nullptr, this);}
const_iterator find(const K& key) const{HashFunc hf;size_t hashAddr = hf(key) % _table.size();KOfT kot;Node* cur = _table[hashAddr];while (cur){if (kot(cur->_data) == key){return const_iterator(cur, this);}cur = cur->_next;}return const_iterator(nullptr, this);}
/*---------- 插入 ----------*/std::pair<iterator, bool> insert(const T& data){KOfT kot;iterator ret = find(kot(data));if (ret != end()){return std::make_pair(ret, false);}
HashFunc hf;size_t hashAddr = hf(kot(data)) % _table.size();// 头插Node* newnode = new Node(data);newnode->_next = _table[hashAddr];_table[hashAddr] = newnode;++_n;
// 将装载因子限制在 1 及以下if (_n == _table.size()){size_t newSize = 2 * _table.size();std::vector<Node*> newTable(newSize, nullptr);for (size_t i = 0; i < _table.size(); ++i){Node* cur = _table[i];while (cur){Node* next = cur->_next;// 将 *cur 头插到新表中size_t hashAddr = hf(kot(cur->_data)) % newSize;cur->_next = newTable[hashAddr];newTable[hashAddr] = cur;// 更新 curcur = next;}_table[i] = nullptr;}_table.swap(newTable);}return std::make_pair(iterator(newnode, this), true);}
/*---------- 删除 ----------*/size_t erase(const K& key){HashFunc hf;size_t hashAddr = hf(key) % _table.size();KOfT kot;Node* prev = nullptr;Node* cur = _table[hashAddr];while (cur){if (kot(cur->_data) == key){if (prev == nullptr){_table[hashAddr] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}private:std::vector<Node*> _table; // 哈希表size_t _n; // 表中填入的元素个数};
}5.2 - unordered_map.h
#pragma once
#include "HashTable.h"
namespace yzz
{template<class K, class V>class unordered_map{struct MapKOfT{const K& operator()(const std::pair<const K, V>& kv){return kv.first;}};
typedef HashTable<K, std::pair<const K, V>, MapKOfT> HashTable;public:typedef typename HashTable::iterator iterator;typedef typename HashTable::const_iterator const_iterator;
iterator begin(){return _ht.begin();}
iterator end(){return _ht.end();}
const_iterator begin() const{return _ht.begin();}
const_iterator end() const{return _ht.end();}
std::pair<const_iterator, bool> insert(const std::pair<const K, V>& kv){return _ht.insert(kv);}
V& operator[](const K& key){std::pair<iterator, bool> ret = _ht.insert(std::make_pair(key, V()));return ret.first->second;}private:HashTable _ht;};
}5.3 - unordered_set.h
#pragma once
#include "HashTable.h"
namespace yzz
{template<class K>class unordered_set{struct SetKOfT{const K& operator()(const K& key){return key;}};
typedef HashTable<K, K, SetKOfT> HashTable;public:typedef typename HashTable::const_iterator iterator;typedef typename HashTable::const_iterator const_iterator;
const_iterator begin() const{return _ht.begin();}
const_iterator end() const{return _ht.end();}
std::pair<const_iterator, bool> insert(const K& key){std::pair<typename HashTable::iterator, bool> ret = _ht.insert(key);return std::pair<const_iterator, bool>(ret.first, ret.second);}private:HashTable _ht;};
}5.4 - test.cpp
#include "unordered_set.h"
#include "unordered_map.h"
#include <iostream>
using namespace std;
int main()
{int arr[] = { 19, 14, 23, 1, 68, 20, 84, 27, 55, 11, 10, 79 };yzz::unordered_set<int> us;for (const int& e : arr){us.insert(e);}yzz::unordered_set<int>::iterator us_it = us.begin();while (us_it != us.end()){// *us_it = 0; // errorcout << *us_it << " ";++us_it;}cout << endl;
yzz::unordered_map<string, string> um;um.insert(make_pair("insert", "插入"));um.insert(make_pair("erase", "删除"));um.insert(make_pair("find", "查找"));um["left"] = "左边";um["right"] = "右边";yzz::unordered_map<string, string>::iterator um_it = um.begin();while (um_it != um.end()){// um_it->first = "xxx"; // error// um_it->second = "yyy"; // okcout << um_it->first << ":" << um_it->second << endl;++um_it;}return 0;
}




![C/C++:[Error] ld returned 1 exit status 解决方案](https://img-blog.csdnimg.cn/de1daf8b8b7f4ec3bc2148f029061a1a.png)



![[管理与领导-113]:IT人看清职场中的隐性规则 - 10 - 看清人的行动、行为、手段、方法背后的动机与背景条件](https://img-blog.csdnimg.cn/fca4102dbffc40239847bfa53fb8e5a7.png)