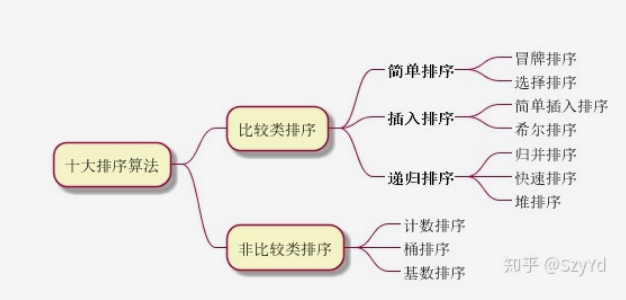
目录
1 冒泡排序(Bubble Sort)
2 插入排序(Insertion Sort)
3 选择排序(Selection Sort)
4. 快速排序(Quick Sort)
5. 归并排序(Merge Sort)
6 堆排序 (Heap Sort)
7 计数排序 (Counting Sort)
8 基数排序 (Radix Sort)
9 希尔排序(Shell Sort)
10 桶排序
1 冒泡排序(Bubble Sort)
冒泡排序是一种基本的排序算法,其核心思想是多次遍历待排序的元素,比较相邻的两个元素,如果它们的顺序不正确,则交换它们,直到整个数组按照指定顺序排列。
def bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n-i-1):# 比较相邻的两个元素if arr[j] > arr[j+1]:# 如果顺序不正确,则交换它们arr[j], arr[j+1] = arr[j+1], arr[j]# 示例用法
arr = [64, 34, 25, 12, 22, 11, 90]
bubble_sort(arr)
print("冒泡排序后的数组:", arr)
冒泡排序通过多次遍历数组,每次比较相邻的两个元素,如果它们的顺序不正确就交换它们。这个过程将最大的元素逐渐“冒泡”到数组的末尾。
时间复杂度为 O(n^2),不适合大规模数据集。
2 插入排序(Insertion Sort)
插入排序是一种稳定的排序算法,其核心思想是将未排序的元素逐个插入到已排序的部分,从前往后遍历,保持前面的元素有序。
def insertion_sort(arr):for i in range(1, len(arr)):key = arr[i]j = i - 1while j >= 0 and key < arr[j]:# 将较大的元素向右移动arr[j + 1] = arr[j]j -= 1arr[j + 1] = key# 示例用法
arr = [64, 34, 25, 12, 22, 11, 90]
insertion_sort(arr)
print("插入排序后的数组:", arr)
插入排序逐个将未排序的元素插入到已排序的部分,从前往后遍历,保持前面的元素有序。时间复杂度为 O(n^2),适合小规模数据集和部分有序的数据。
3 选择排序(Selection Sort)
选择排序是一种简单的不稳定排序算法,其核心思想是找到未排序部分的最小元素,将其与未排序部分的第一个元素交换位置。
def selection_sort(arr):n = len(arr)for i in range(n):min_index = ifor j in range(i+1, n):# 找到未排序部分的最小元素的索引if arr[j] < arr[min_index]:min_index = j# 交换最小元素与未排序部分的第一个元素arr[i], arr[min_index] = arr[min_index], arr[i]# 示例用法
arr = [64, 34, 25, 12, 22, 11, 90]
selection_sort(arr)
print("选择排序后的数组:", arr)
选择排序通过多次选择未排序部分的最小元素,并将其与未排序部分的第一个元素交换位置来进行排序。时间复杂度为 O(n^2),不适合大规模数据集。
4. 快速排序(Quick Sort)
快速排序是一种高效的分治排序算法,它选择一个基准元素,将数组分成两部分,左边的元素都小于基准,右边的元素都大于基准,然后递归对左右两部分进行排序。
def quick_sort(arr):# 基本情况:如果数组为空或只包含一个元素,无需排序if len(arr) <= 1:return arr# 选择中间元素作为基准点(pivot)pivot = arr[len(arr) // 2]# 将数组分成三部分:小于、等于、大于基准点的元素left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]# 递归排序左右两部分,然后合并结果return quick_sort(left) + middle + quick_sort(right)# 示例用法
arr = [64, 34, 25, 12, 22, 11, 90]
arr = quick_sort(arr)
print("快速排序后的数组:", arr)
- 快速排序是一种高效的分治排序算法,它通过选择一个基准点(通常是数组中的中间元素)将数组分成左右两部分,并递归地对左右两部分进行排序。
- 基本情况是数组为空或只包含一个元素,无需排序。
- 针对每个元素,将它与基准点进行比较,分成小于、等于和大于基准点的三个子数组。
- 然后,递归地对左右两部分进行排序,最后将它们与基准点合并,形成一个有序的数组。
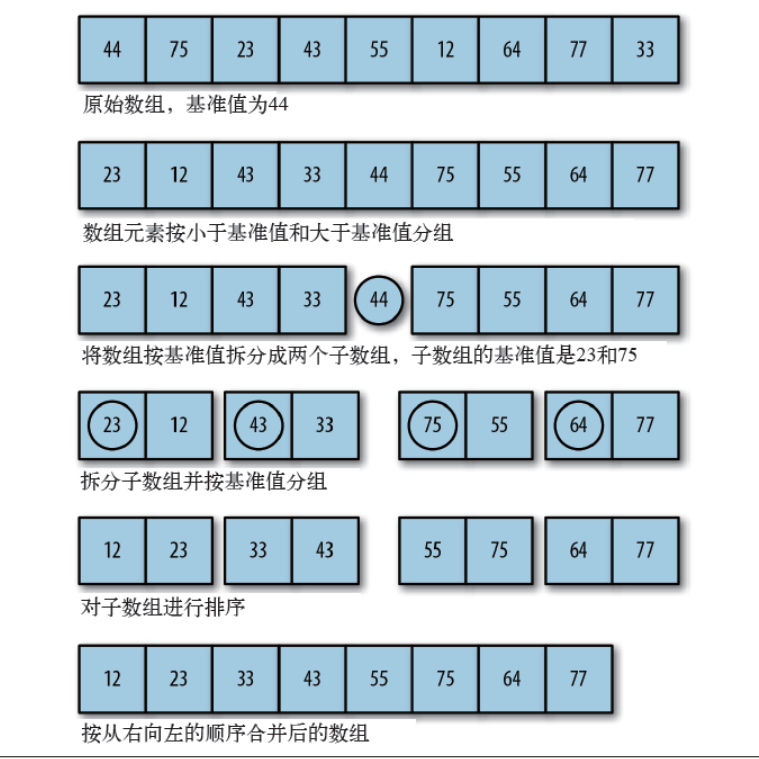
5. 归并排序(Merge Sort)
归并排序是一种稳定的分治排序算法,它将数组分成两半,分别排序,然后将已排序的两个子数组合并成一个有序数组。
def merge_sort(arr):# 基本情况:如果数组为空或只包含一个元素,无需排序if len(arr) <= 1:return arr# 将数组分成两半mid = len(arr) // 2left = arr[:mid]right = arr[mid:]# 递归地对左右两部分进行排序left = merge_sort(left)right = merge_sort(right)# 合并已排序的左右两部分return merge(left, right)def merge(left, right):result = []i = j = 0# 合并两个已排序的子数组while i < len(left) and j < len(right):if left[i] < right[j]:result.append(left[i])i += 1else:result.append(right[j])j += 1# 如果左边或右边的子数组还有剩余元素,将它们添加到结果中result.extend(left[i:])result.extend(right[j:])return result# 示例用法
arr = [64, 34, 25, 12, 22, 11, 90]
arr = merge_sort(arr)
print("归并排序后的数组:", arr)
- 归并排序是一种稳定的分治排序算法,它将数组递归分成两半,然后合并已排序的子数组。
- 基本情况是数组为空或只包含一个元素,无需排序。
- 递归地对左右两部分进行排序,然后使用
merge函数将它们合并成一个有序的数组。merge函数将两个已排序的子数组合并,同时维护它们的有序性。
6 堆排序 (Heap Sort)
堆排序是一种不稳定的排序算法,它使用堆数据结构(通常是最大堆)来进行排序。堆排序分为两个主要步骤:建立堆和排序。
def heapify(arr, n, i):largest = ileft = 2 * i + 1right = 2 * i + 2# 找到左子节点和右子节点中的最大值if left < n and arr[left] > arr[largest]:largest = leftif right < n and arr[right] > arr[largest]:largest = right# 如果最大值不是当前节点,交换它们if largest != i:arr[i], arr[largest] = arr[largest], arr[i]def heap_sort(arr):n = len(arr)# 构建最大堆for i in range(n // 2 - 1, -1, -1):heapify(arr, n, i)# 一个接一个地从堆中取出元素,交换根节点与最后一个节点,然后重新构建堆for i in range(n - 1, 0, -1):arr[i], arr[0] = arr[0], arr[i]heapify(arr, i, 0)# 示例用法
arr = [64, 34, 25, 12, 22, 11, 90]
heap_sort(arr)
print("堆排序后的数组:", arr)
- 排序使用堆数据结构(通常是最大堆)来进行排序。首先构建最大堆,然后一个接一个地从堆中取出元素,交换根节点与最后一个节点,然后重新构建堆。
heapify函数用于维护堆的性质,即父节点的值大于或等于子节点的值。- 这个算法的时间复杂度为 O(nlogn),是一种高效的排序算法。
7 计数排序 (Counting Sort)
计数排序是一种非比较排序算法,它根据输入元素的计数来对元素进行排序。它适用于整数或有限范围内的非负整数。
def counting_sort(arr):max_val = max(arr)min_val = min(arr)range_of_elements = max_val - min_val + 1count_arr = [0] * range_of_elementsoutput_arr = [0] * len(arr)# 计数每个元素的出现次数for num in arr:count_arr[num - min_val] += 1# 计算每个元素的累积计数for i in range(1, len(count_arr)):count_arr[i] += count_arr[i - 1]# 根据累积计数将元素放入输出数组for i in range(len(arr) - 1, -1, -1):output_arr[count_arr[arr[i] - min_val] - 1] = arr[i]count_arr[arr[i] - min_val] -= 1return output_arr# 示例用法
arr = [4, 2, 2, 8, 3, 3, 1]
arr = counting_sort(arr)
print("计数排序后的数组:", arr)
- 计数排序是一种非比较排序算法,适用于整数或有限范围内的非负整数。
- 首先,计算每个元素的出现次数,然后计算每个元素的累积计数,最后根据累积计数将元素放入输出数组。
- 这个算法的时间复杂度为 O(n+k),其中 k 是输入范围的大小。
8 基数排序 (Radix Sort)
基数排序是一种非比较排序算法,它将数字按照每个位数进行排序,从最低位到最高位,依次排列。
def counting_sort(arr, exp):n = len(arr)output = [0] * ncount = [0] * 10# 计数每个元素的出现次数for i in range(n):index = arr[i] // expcount[index % 10] += 1# 计算每个元素的累积计数for i in range(1, 10):count[i] += count[i - 1]# 根据累积计数将元素放入输出数组i = n - 1while i >= 0:index = arr[i] // expoutput[count[index % 10] - 1] = arr[i]count[index % 10] -= 1i -= 1# 将输出数组的内容复制到原始数组中for i in range(n):arr[i] = output[i]def radix_sort(arr):max_val = max(arr)exp = 1while max_val // exp > 0:counting_sort(arr, exp)exp *= 10# 示例用法
arr = [170, 45, 75, 90, 802, 24, 2, 66]
radix_sort(arr)
print("基数排序后的数组:", arr)
- 基数排序是一种非比较排序算法,它按照每个位数进行排序,从最低位到最高位,依次排列。
- 首先使用计数排序对每个位数进行排序,然后再次对下一个位数进行排序,依次进行直到最高位。
- 这个算法的时间复杂度为 O(nk),其中 k 是数字的最大位数。
9 希尔排序(Shell Sort)
希尔排序(Shell Sort)是一种插入排序的改进版本,也被称为缩小增量排序。希尔排序通过将数组分成若干个子序列来排序数据,然后逐渐缩小子序列的间隔,最终得到一个完全排序的数组。希尔排序的主要思想是提前交换较远的元素,以加快排序过程。
算法原理:
选择一个增量序列(间隔序列),通常选择的增量是数组长度的一半,然后逐渐减小增量。
对于每个增量,将数组分成若干个子序列,每个子序列使用插入排序进行排序。
重复步骤2,逐渐减小增量,直到增量为1。
当增量为1时,整个数组成为一个序列,使用插入排序对其进行排序。
def shell_sort(arr):n = len(arr)gap = n // 2 # 初始增量取数组长度的一半while gap > 0:for i in range(gap, n):temp = arr[i]j = i# 使用插入排序对子序列进行排序while j >= gap and arr[j - gap] > temp:arr[j] = arr[j - gap]j -= gaparr[j] = tempgap //= 2 # 缩小增量# 示例用法
arr = [64, 34, 25, 12, 22, 11, 90]
shell_sort(arr)
print("希尔排序后的数组:", arr)
希尔排序的关键在于选择合适的增量序列。常见的增量序列有希尔增量、Hibbard增量、Knuth增量等,不同的增量序列会影响排序的性能。
希尔排序的时间复杂度取决于增量序列的选择,平均时间复杂度通常在 O(n^1.25) 到 O(n^2) 之间,比插入排序要快。
希尔排序是一种不稳定排序算法,适用于中等大小的数据集。虽然不如快速排序和归并排序快,但在某些情况下比插入排序更快。希尔排序通常用于嵌入式系统等资源有限的环境。
10 桶排序(Bucket Sort)
桶排序(Bucket Sort)是一种分布式排序算法,它将元素分散到一组桶中,然后对每个桶中的元素进行排序,最后将所有桶中的元素按顺序合并成一个有序序列。桶排序适用于元素均匀分布在一个范围内的情况,特别适用于浮点数排序。
算法原理:
确定桶的数量和范围,通常根据输入数据的分布来选择桶的数量。如果元素均匀分布在一个范围内,那么可以选择桶的数量等于元素的数量。
将每个元素分配到相应的桶中。元素的分配可以采用不同的方法,例如线性划分或哈希函数。
对每个桶中的元素进行排序,可以使用任何排序算法,通常选择插入排序。
合并所有桶中的元素,按照桶的顺序得到最终的有序序列。
def bucket_sort(arr):# 确定桶的数量,这里选择与输入元素数量相同n = len(arr)if n <= 1:return arr# 初始化桶max_val = max(arr)min_val = min(arr)bucket_range = (max_val - min_val) / n # 每个桶的范围bucket_count = n # 桶的数量等于元素数量buckets = [[] for _ in range(bucket_count)]# 将元素分配到桶中for num in arr:index = int((num - min_val) / bucket_range)buckets[index].append(num)# 对每个桶中的元素进行排序for i in range(bucket_count):buckets[i].sort()# 合并所有桶中的元素sorted_arr = []for bucket in buckets:sorted_arr.extend(bucket)return sorted_arr# 示例用法
arr = [0.897, 0.565, 0.656, 0.1234, 0.665, 0.3434]
arr = bucket_sort(arr)
print("桶排序后的数组:", arr)
桶排序的性能取决于桶的数量和元素的分布。如果元素均匀分布在一个范围内,并且桶的数量足够多,那么桶排序可以非常高效。
桶排序的时间复杂度通常为 O(n + k),其中 n 是元素的数量,k 是桶的数量。
桶排序是一种稳定排序算法,适用于浮点数排序等特定情况。不过,它需要额外的内存空间来存储桶,因此不适用于数据集非常大的情况。