我们在之前学习的稠密数据结构中主要可以分为root,dense,和field三个,而实际上我们还可以定义一个bitmasked和pointer这两个就是用来帮助我们维护空间稀疏性用的
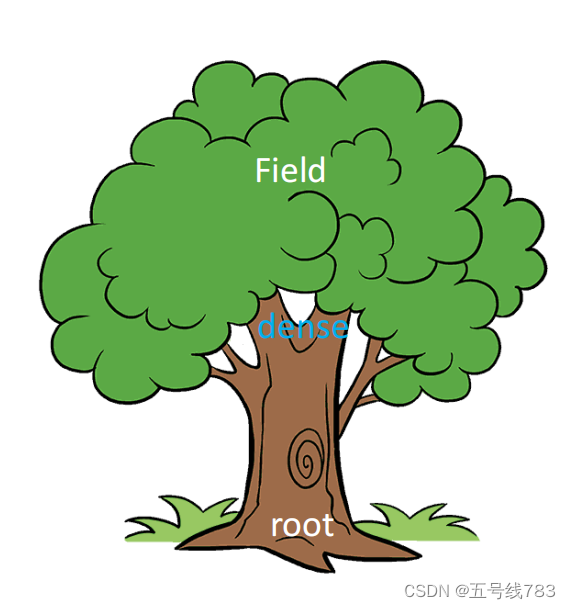
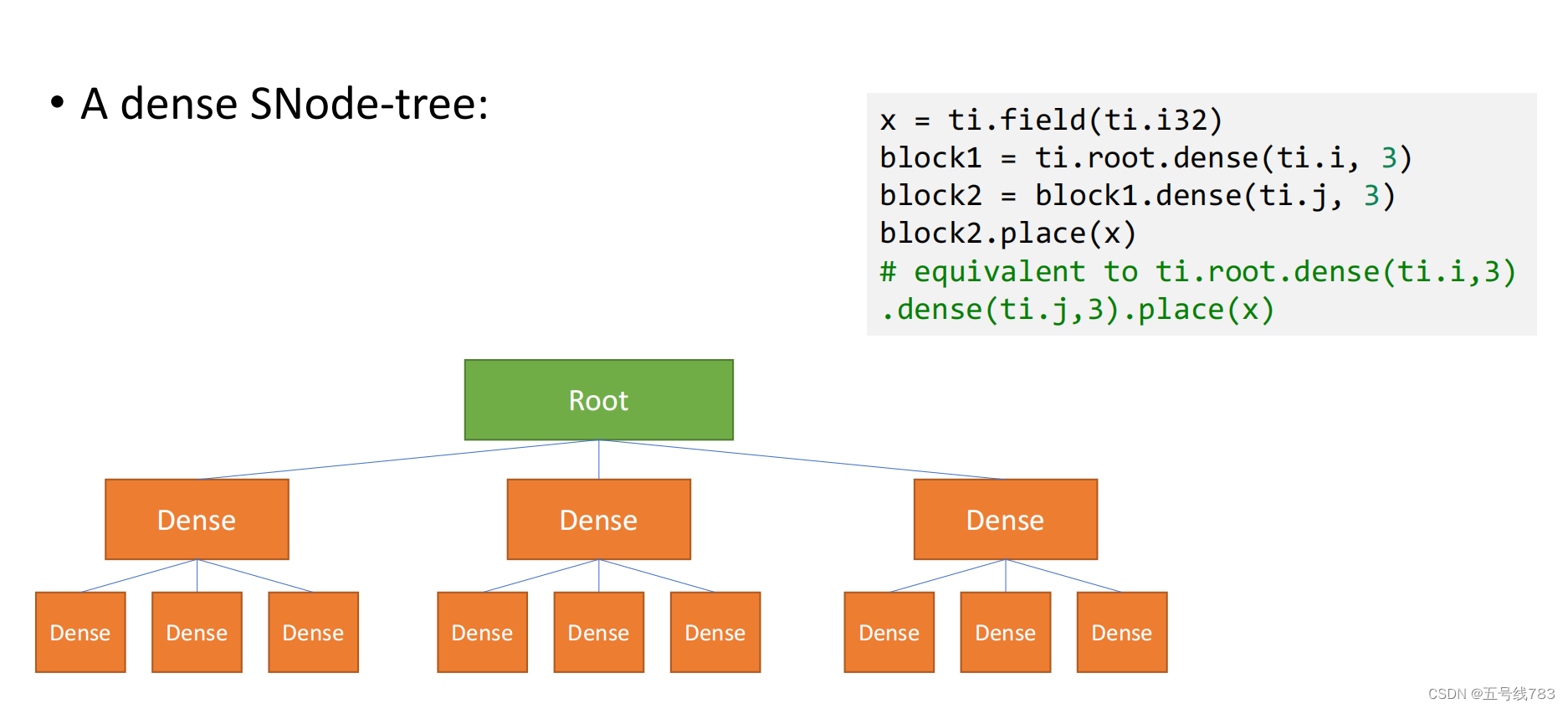
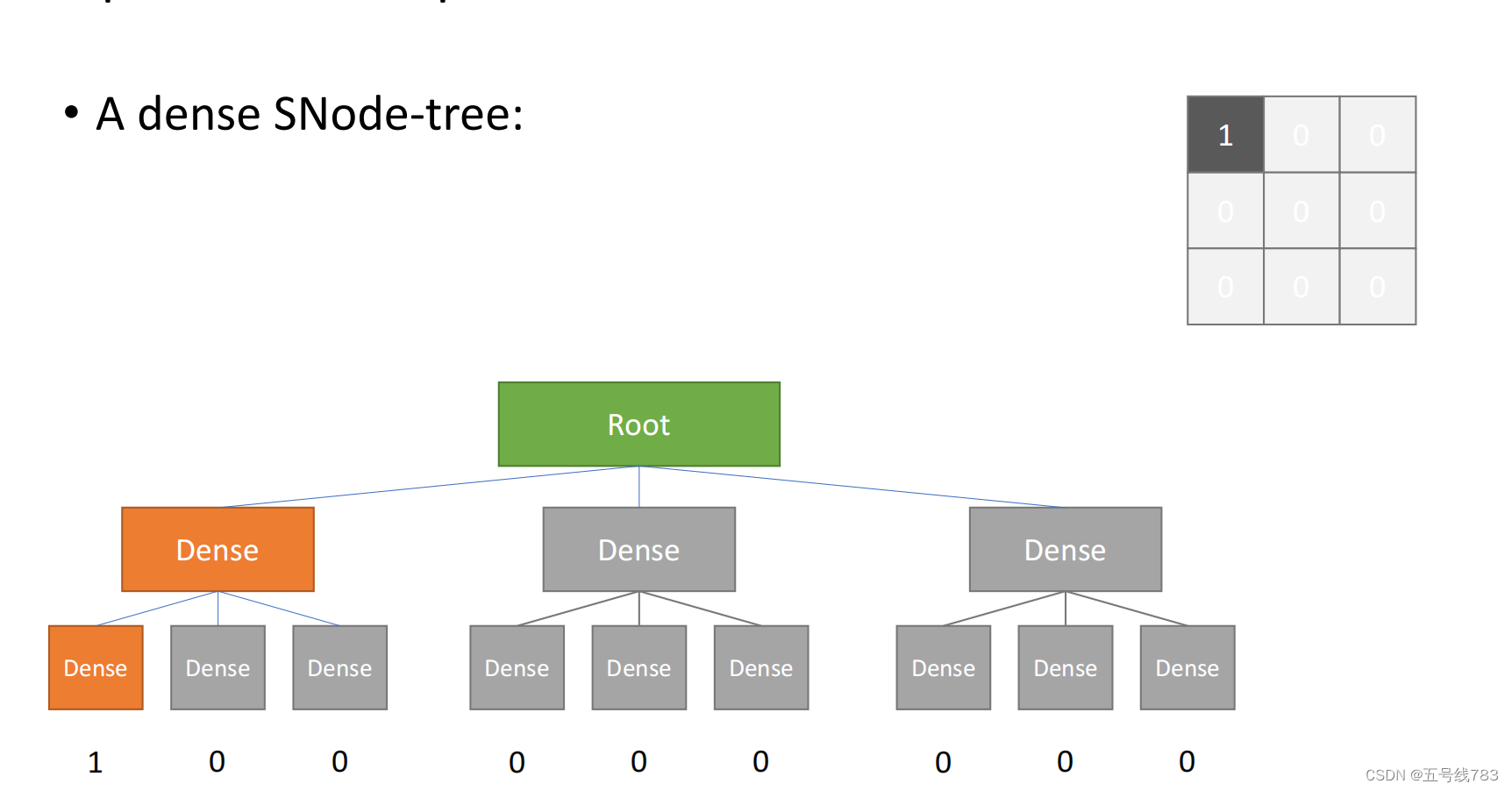
举一个例子,首先是一个稠密结构,它的数据利用率很低
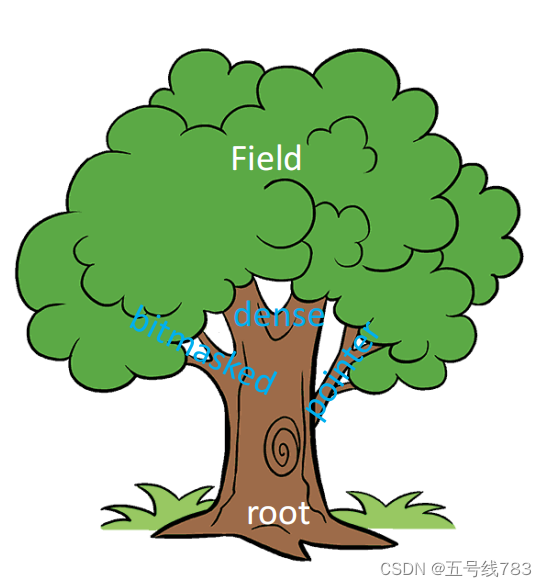
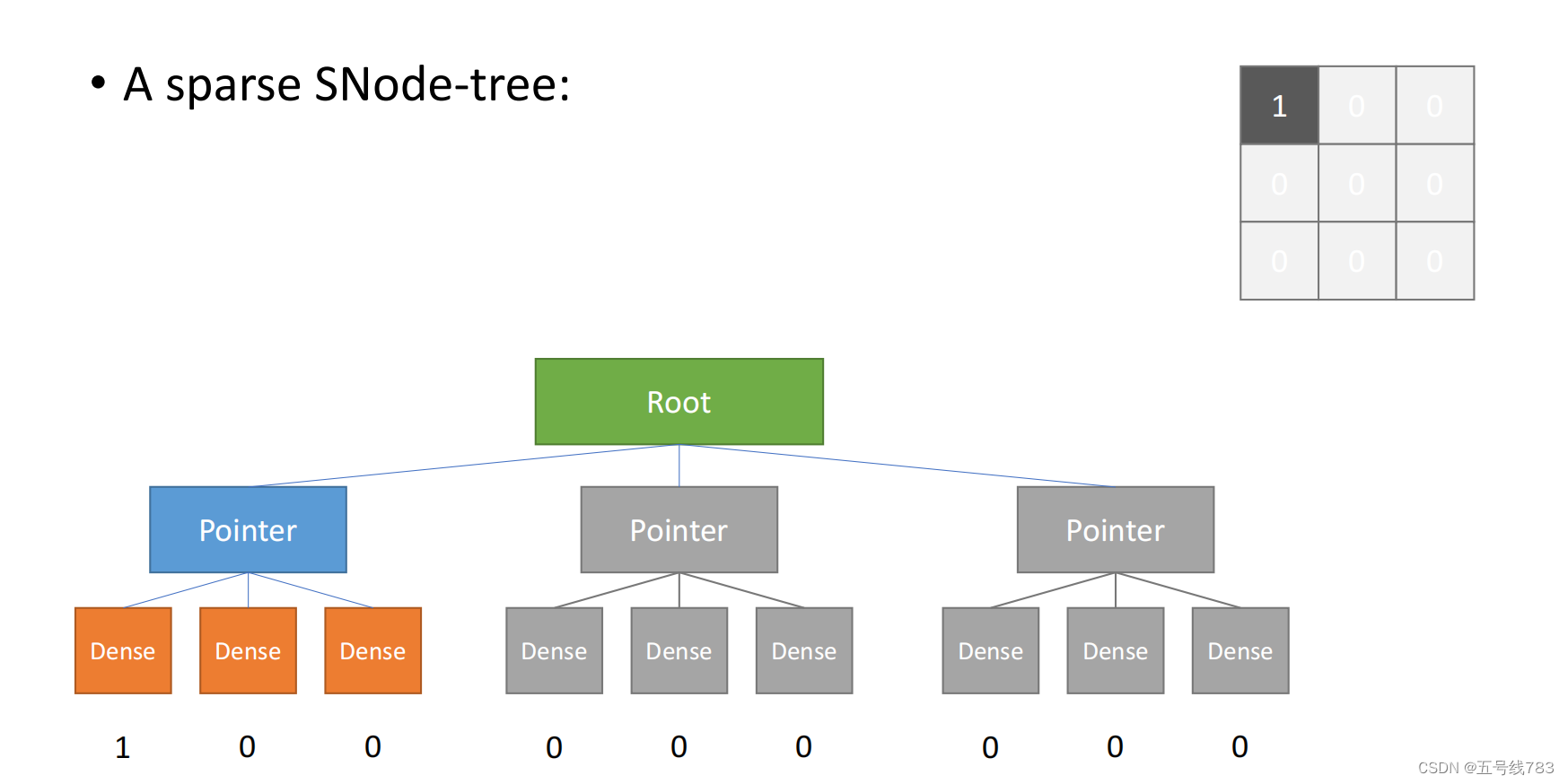
那么为了解决这个数据使用率过低的情况,我们可以使用指针,用指针指向哪些稠密的部分
修改也非常的简单

将稠密的数据结构改成pointer就可以解决问题
在还未写入任何数据的时候,该结构都没激活,只要写入第一个数据,那么首先会激活pointer,然后这一整块指针指向的结构都会激活,也就是block2
那么怎么对这个结构进行访问呢,和原来一样使用for即可
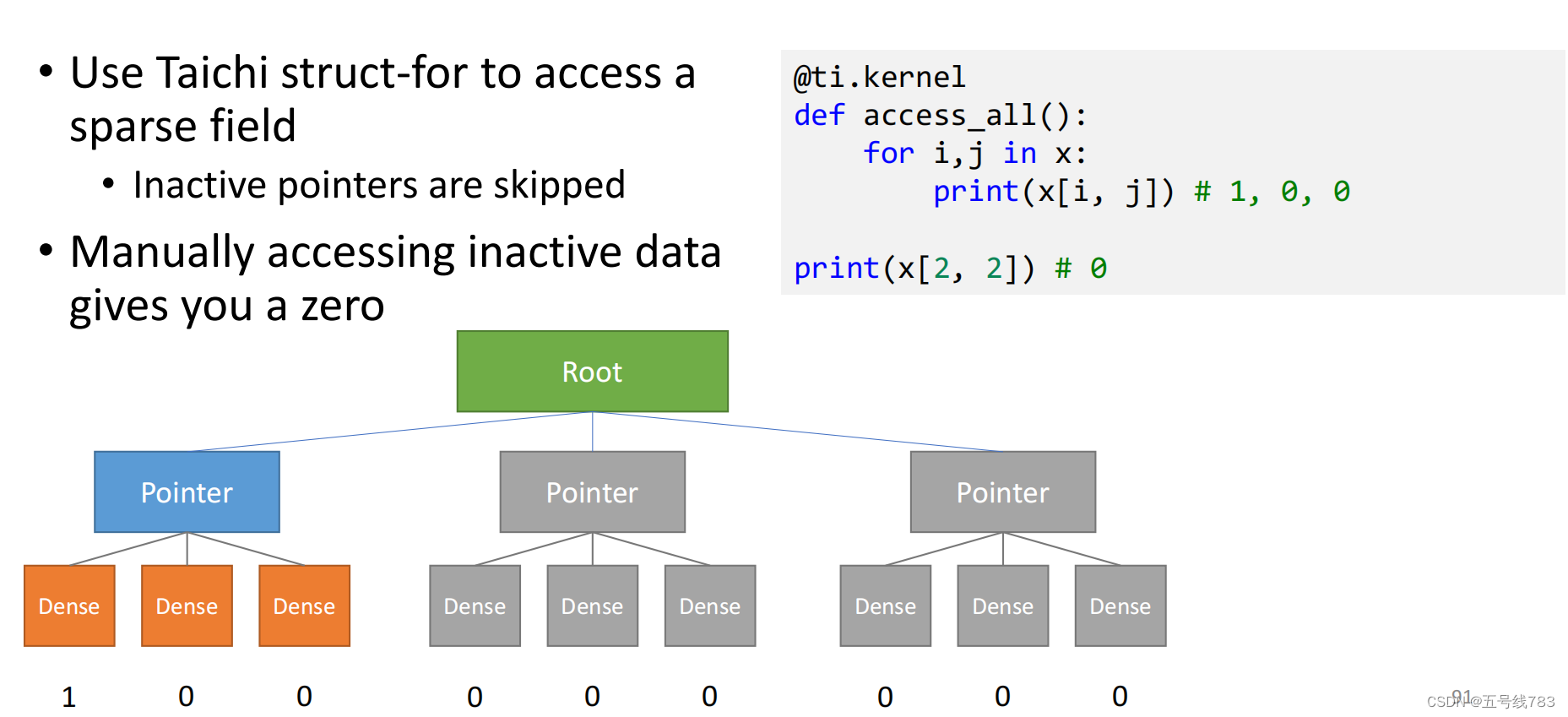
如果我将最后一层换成pointer反而访问的可能会更慢,因为会失去连续性而且pointer可能反而数据结构占据的位数更多,所以我们要用bitmasks

这样做其实没有省下内存,但是有一个好处是,使用for访问的时候,如果一旦发现某一个cell没有激活,它就不会继续访问
有一些API可以操作节点的激活状态
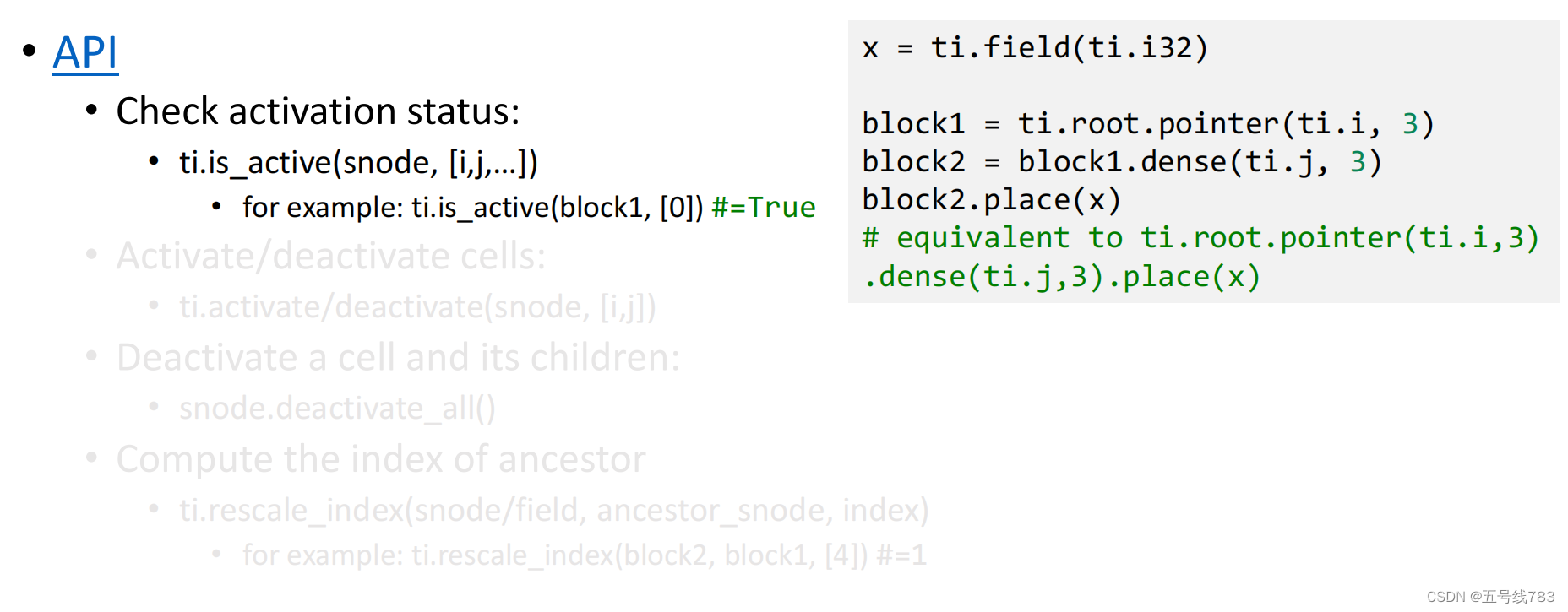
除了查看是否为激活状态外,还可以手动激活,禁用和查看父节点的index
将稠密的和稀疏的数据结构结合起来

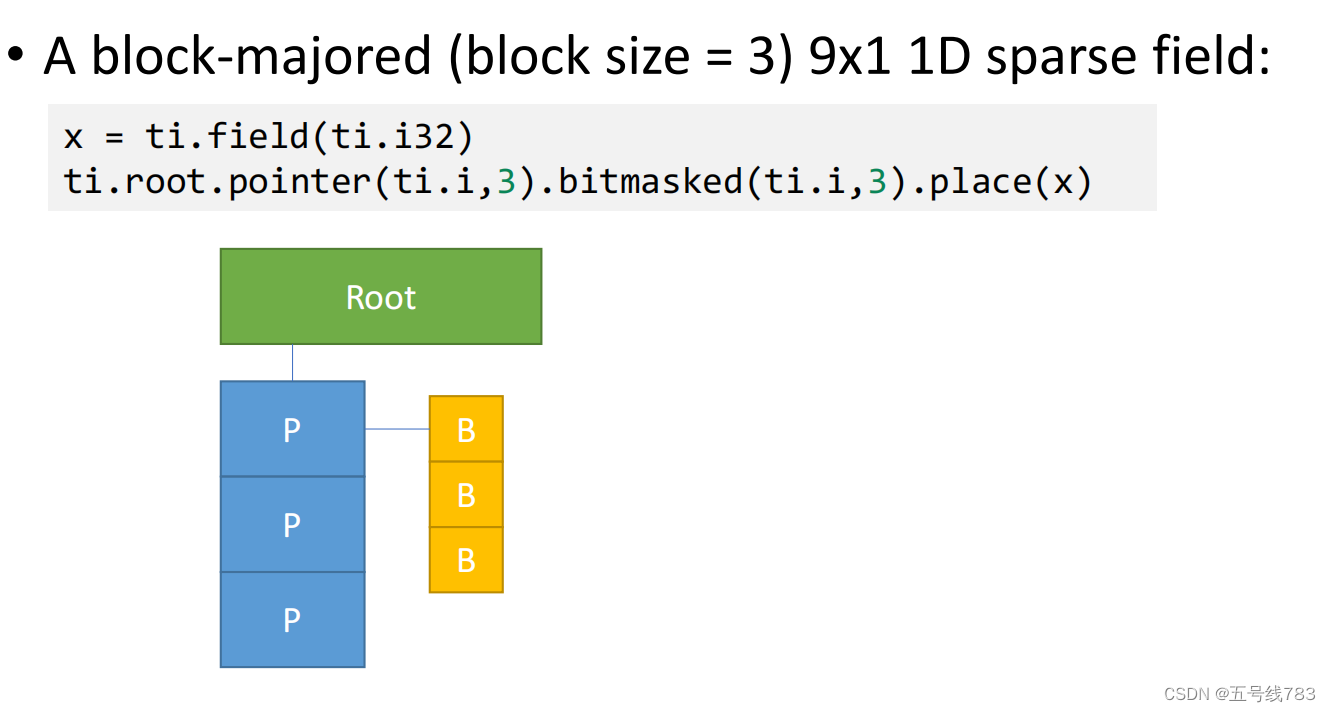

这样的数据定义看起来很复杂,但其实从i和j就可以看出定义的结构,首先是一个2x3的矩阵,使用了pointer作为指针优化,然后是一个4x1的向量,定义了一个指针,指针指向的4x1向量中前两个用稠密结构,后两个用的是掩码
注意:一般不用这解线性系统的解










![[Algorithm][回溯][字母大小写全排列][优美的排列][N皇后]详细讲解](https://img-blog.csdnimg.cn/direct/9c535575aef8428c8bcf308126bf53e4.png)