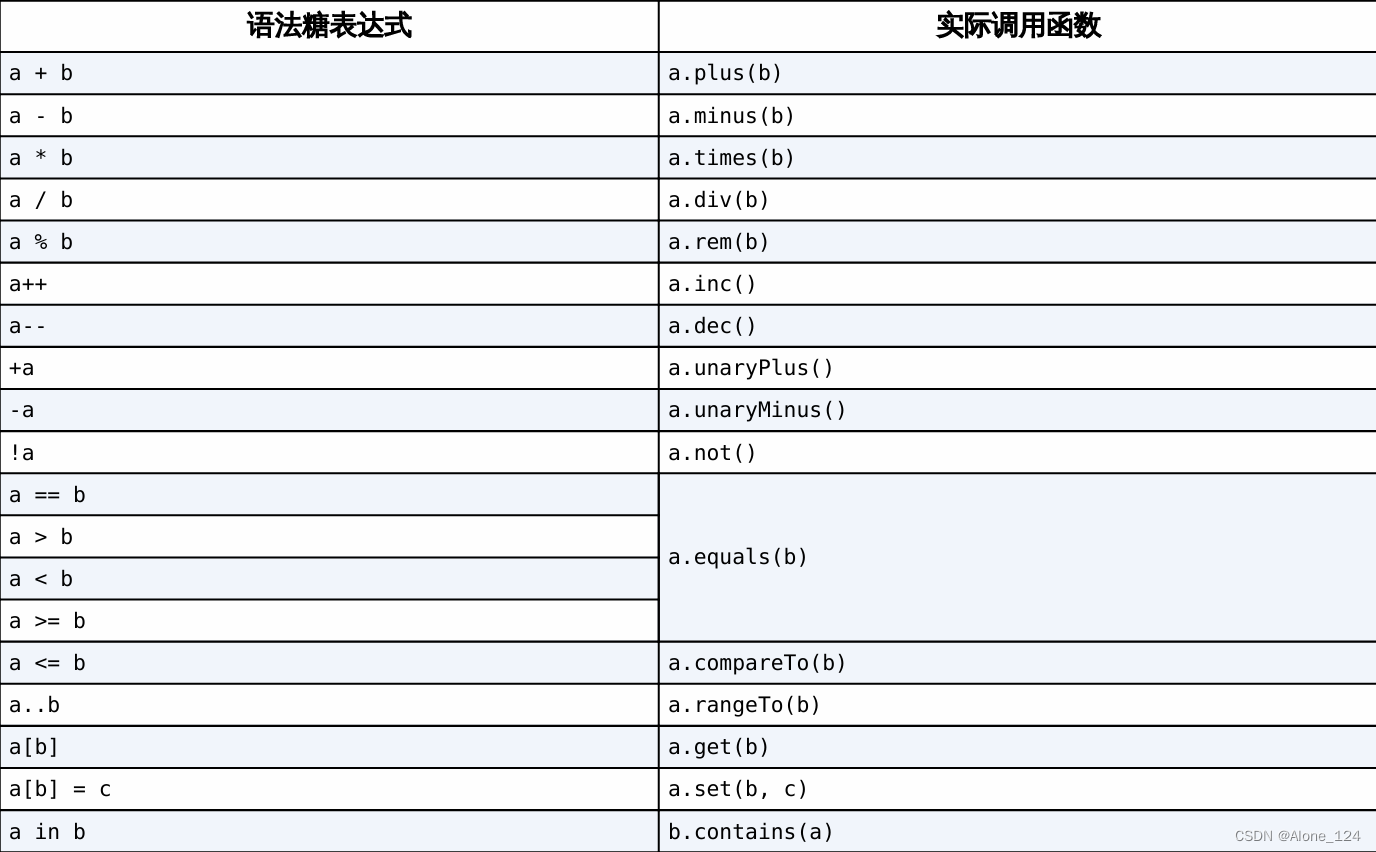
DPO
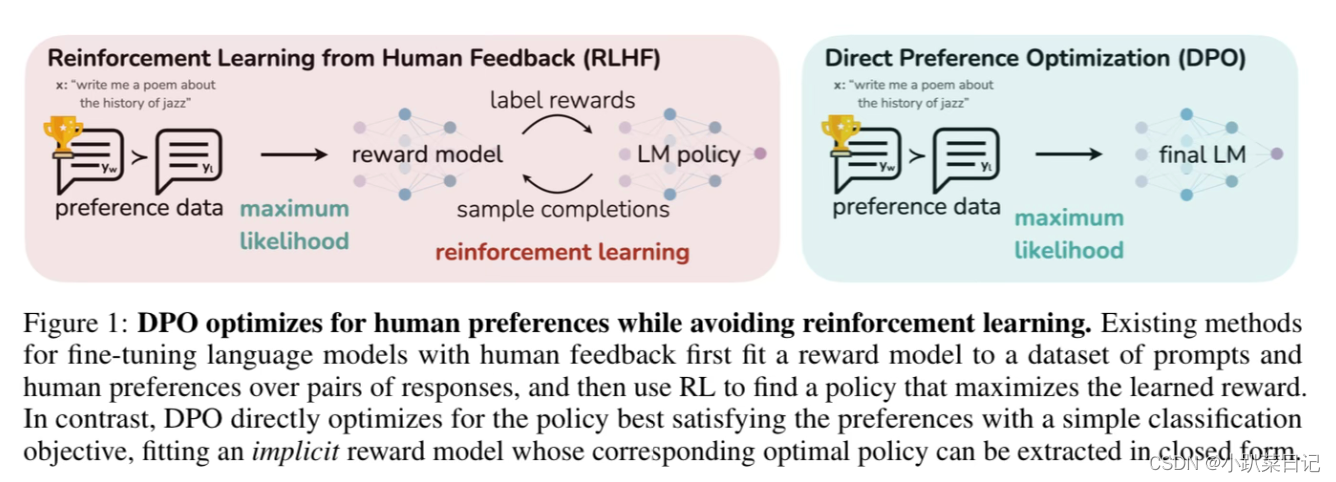
DPO(直接偏好优化)简化了RLHF流程。它的工作原理是创建人类偏好对的数据集,每个偏好对都包含一个提示和两种可能的完成方式——一种是首选,一种是不受欢迎。然后对LLM进行微调,以最大限度地提高生成首选完成的可能性,并最大限度地减少生成不受欢迎的完成的可能性。与传统的微调方法相比,DPO 绕过了建模奖励函数这一步,设计一种包含正负样本对比的损失函数,通过直接在偏好数据上优化模型来提高性能。(即不训练奖励模型,语言模型直接做偏好优化)
工作原理:DPO在多个计算节点上并行运行,每个节点都有自己的一份策略副本,并在各自的环境实例中收集数据。在一定时间步或者周期之后,各个节点会将它们收集到的数据(如梯度信息或者策略更新)发送给中心节点。中心节点会聚合这些数据,并进行策略更新。更新后的策略参数随后会被分发回各个计算节点。由于每个节点可以独立探索不同的状态空间区域,DPO能够更加高效地进行探索和利用,从而加快学习过程。
PPO(不是很懂,copy来的)
PPO的想法是,通过限制在每个训练阶段对策略所做的更改来提高策略的训练稳定性:我们希望避免过大的策略(参数)更新。我们从经验上知道,训练期间较小的策略更新更有可能收敛到最优解。策略更新步幅太大可能导致“坠崖”(获得糟糕的策略),并且需要很长时间甚至不可能恢复。
因此,使用PPO,我们要保守地更新策略。为此,我们需要通过计算当前策略与前一个策略之间的比率来衡量当前策略与前一个策略相比发生了多大的变化。我们将此比率限制在 [1−ϵ,1+ϵ] 的范围内,这意味着我们消除了当前策略偏离旧策略太远的动机(因此称为近端策略术语)。
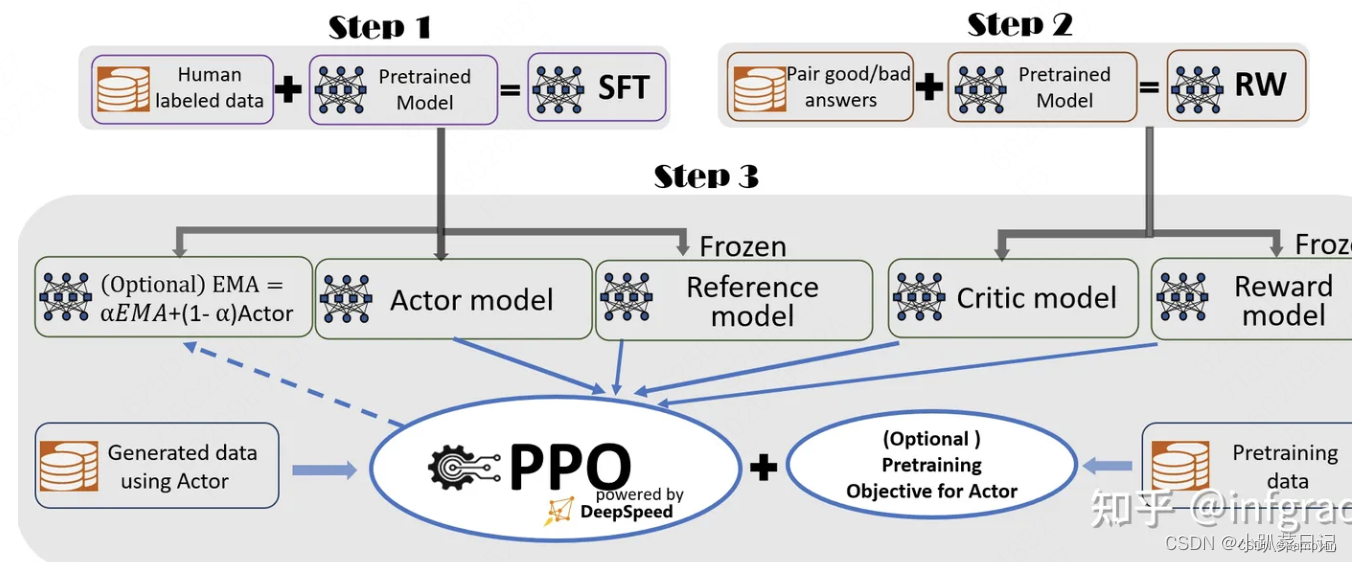
加载4个模型,2个推理,2个训练
- Actor Model:演员模型,想要训练的目标语言模型
- Critic Model:评论家模型,它的作用是预估总收益
- Reward Model:奖励模型,它的作用是计算即时收益
- Reference Model:参考模型,它的作用是在RLHF阶段给语言模型增加一些“约束”,防止语言模型训歪(朝不受控制的方向更新,效果可能越来越差)
其中
- Actor/Critic Model在RLHF阶段是需要训练的;而Reward/Reference Model是参数冻结的。
- Critic/Reward/Reference Model共同组成了一个“奖励-loss”计算体系,我们综合它们的结果计算loss,用于更新Actor和Critic Model
PPO和DPO的不同
分布式训练:DPO的“Distributed”指的是它被设计为在分布式计算环境中运行,可以在多个处理器或机器上并行执行,而PPO通常指单机版本的算法。
扩展性和并行化:由于DPO是为分布式环境设计的,它在处理大规模并行化训练任务时具有更好的扩展性,而PPO则在这方面可能受到限制。
通信和同步:在分布式设置中,DPO需要有效的通信和同步机制来保证多个训练节点之间的协调,这是PPO在单机设置中不需要考虑的问题。
理解RLHF(奖励模型+PPO)
- 预训练的基础LLM
- 监督微调(SFT)LLM
- 奖励模型(LLM,但修改为奖励模型)
- PPO优化的语言模型(最终与偏好对齐的LLM)
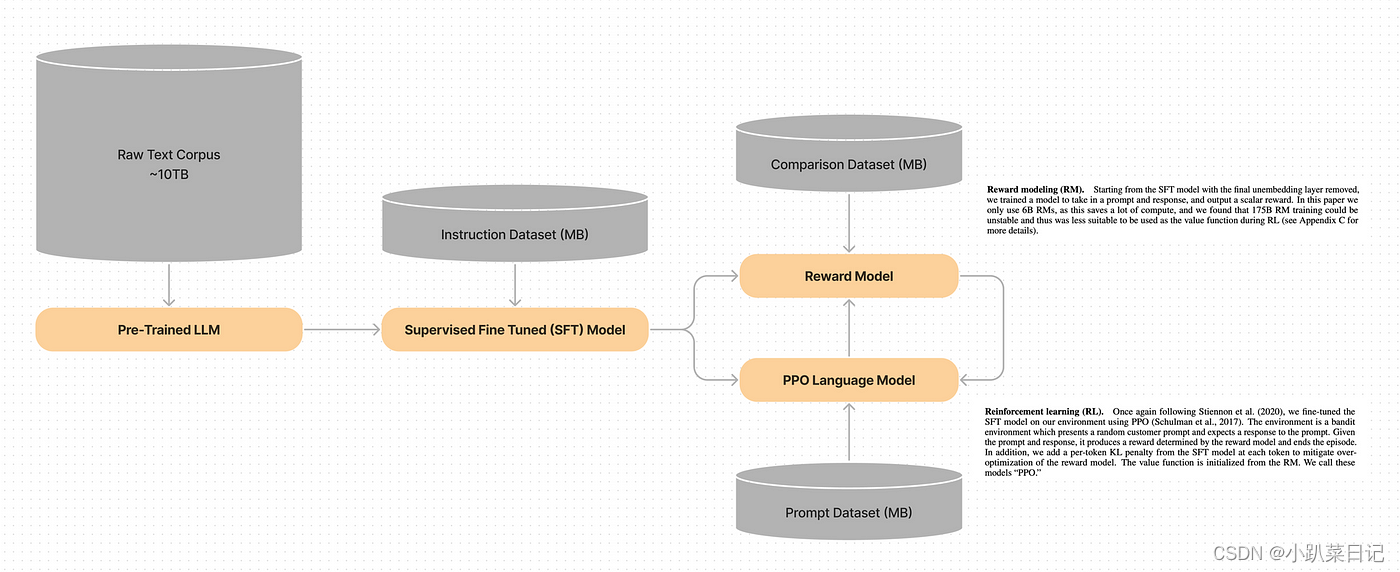
这里奖励模型只是复制了SFT模型,并对其进行修改,删除最终层的非嵌入层(最终层的非嵌入层将文本的内部表示转换为可读的文本输出),并添加一个标量奖励头。该模型接收一个提示并输出一个标量奖励。该层不输出文本,而是输出一个标量值,即表示给定输入的“奖励”或“分数”的单个数字。(然后把这个分数融入到LLM的loss中?)
近端策略优化(PPO)模型也是SFT模型的副本,其中的参数将被更新以与人类偏好对齐。PPO优化“策略”,在这个上下文中指的是根据人类价值观生成文本响应的策略。PPO训练的目标是最大化从奖励模型获得的奖励。(即生成文本的风格能在奖励模型中获得最大奖励,即能够符合人类偏好)
DPO取代奖励模型+PPO
DPO通过完全移除奖励模型来简化这个过程。
- 预训练的基础LLM
- 监督微调(SFT)LLM
- DPO优化的语言模型(最终与偏好对齐的LLM)

参考:强化学习的优化策略PPO和DPO详解并分析异同_dpo ppo-CSDN博客
使用DPO将LLM与人类偏好对齐_llm dpo-CSDN博客







![[Algorithm][回溯][字母大小写全排列][优美的排列][N皇后]详细讲解](https://img-blog.csdnimg.cn/direct/9c535575aef8428c8bcf308126bf53e4.png)