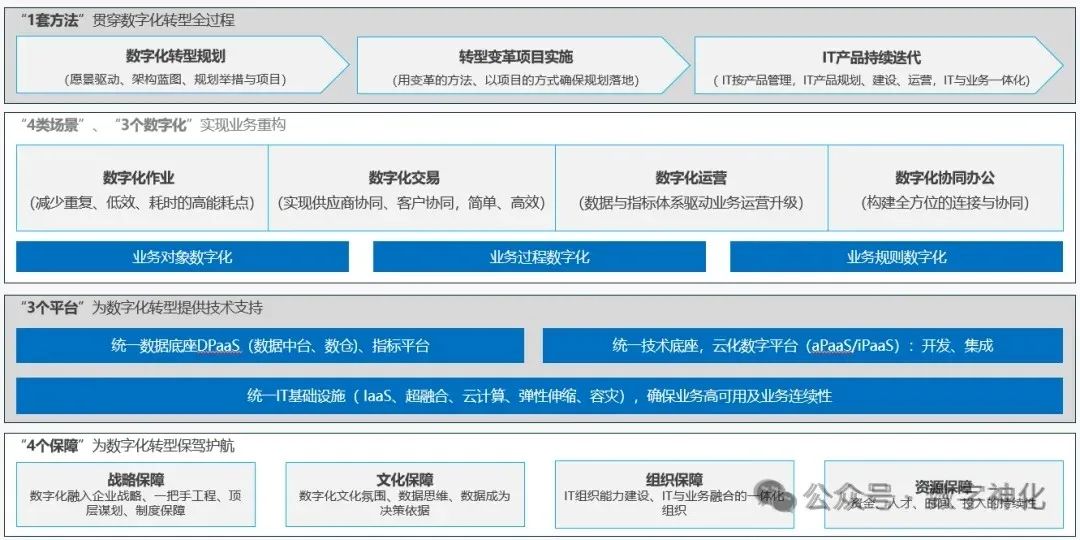
HALCON为分类和语义分割提供了预训练的神经网络。当训练自定义网络时,这些神经网络是很好的起点。它们已经在一个大型图像数据集上进行了预训练。对于异常检测,HALCON提供了初始模型。
用于 3D 抓取点检测的模型
为 3D 抓取点检测提供了以下网络:
'pretrained_dl_3d_gripping_point.hdl'
网络最多需要 5 个类型的图像 :real
'image':强度(灰度值)图像
'x':X 图像(值需要从左到右增加)
'y':Y 图像(值需要从上到下增加)
‘z’: z图像(值需要从靠近传感器的点增加到远点;例如,如果数据是在相机坐标系中给出的情况)
' normals':2D 映射
此外,网络需要某些图像属性(对于上面提到的所有输入图像)。可以使用get_dl_model_param检索相应的值。默认值:
“image_width”: 640
“image_height”: 480
网络架构允许对图像尺寸进行更改。
异常检测模型
异常检测主要检测数据中的离群点,异常数据的特征值与正常数据的特征值距离较远。
提供了以下网络用于异常检测:
'initial_dl_anomaly_medium.hdl'
此神经网络旨在提高内存和运行时效率。
网络期望图像是这种类型的。此外,网络需要某些图像属性。可以使用realget_dl_model_param检索相应的值。默认值:
“image_width”:480
“image_height”: 480
“image_num_channels”: 3
“image_range_min”: -2
“image_range_max”: 2
网络架构允许更改图像尺寸,但是‘image_width’和‘image_height’的大小必须是32像素的倍数,因此最少为32像素
'initial_dl_anomaly_large.hdl'
这种神经网络被认为更适合于更复杂的异常检测任务。这样做的代价是需要更多的时间和内存。
网络期望图像是这种类型的。此外,网络需要某些图像属性。可以使用realget_dl_model_param检索相应的值。默认值:
“image_width”: 480
“image_height”: 480
“image_num_channels”: 3
“image_range_min”: -2
“image_range_max”: 2
网络架构允许更改图像尺寸,但是‘image_width’和‘image_height’的大小必须是32像素的倍数,因此最少为32像素。
全局上下文异常检测模型
“全局上下文异常值检测”是一种独一无二的技术,能够“理解”整个图像的逻辑内容。 与 HALCON 先前异常值检测功能一样,新的“全局上下文异常检测”只需要训练无缺陷图像,无需数据标记。 这项技术可以检测组件缺失、变形或者排布错位等异常,在半导体生产中的印刷电路板检测场景、印刷痕迹的检测场景也有非常优秀的表现。
为全局上下文异常检测提供了以下网络:
“pretrained_dl_anomaly_global_context.hdl”
网络期望图像是这种类型的。此外,网络需要某些图像属性。可以使用realget_dl_model_param检索相应的值。默认值:
“image_width”:256
“image_height”:256
“image_num_channels”:3
“image_range_min”:-127.0
“image_range_max”:128.0
分类模型:
提供以下预训练神经网络用于分类,并可作为检测的骨干:
'pretrained_dl_classifier_alexnet.hdl':
这个神经网络是为简单的分类任务而设计的。它的特点是第一层卷积核比其他具有类似分类性能的网络(例如pretrained_dl_classifier_compact.hdl)中的卷积核要大。这可能有利于特征提取。
此分类器期望图像属于该类型。此外,该网络是为某些图像属性设计的。可以使用realget_dl_model_param检索相应的值。默认值:
“image_width”: 224
“image_height”: 224
“image_num_channels”: 3
“image_range_min”: -127.0
“image_range_max”: 128.0
网络架构允许对图像尺寸进行更改。‘image_width’和‘image_height’不应小于29像素。没有最大图像大小限制,但是大的图像大小会显著增加内存需求和运行时间。改变图像大小将重新初始化完全连接层的权重,因此需要重新训练。
请注意,可以通过融合卷积层和ReLU层来改善该网络的运行时间,参见set_dl_model_param和参数‘fuse_conv_relu’。
“pretrained_dl_classifier_compact.hdl”:
这种神经网络被设计成具有更高的内存和运行效率。
分类器期望图像属于该类型。此外,网络需要某些图像属性。可以使用realget_dl_model_param检索相应的值。默认值:
“image_width”:224
“image_height”:224
“image_num_channels”:3
“image_range_min”:-127.0
“image_range_max”:128.0
该网络不包含任何完全连接的层。网络架构允许对图像尺寸进行更改。‘image_width’和‘image_height’不应小于15像素。
“pretrained_dl_classifier_enhanced.hdl”:
这个神经网络比pretrained_dl_classifier_compact有更多的隐藏层。因此被认为更适合于更复杂的分类任务。这样做的代价是需要更多的时间和内存。
分类器期望图像属于该类型。此外,网络需要某些图像属性。可以使用realget_dl_model_param检索相应的值。默认值:
“image_width”:224
“image_height”:224
“image_num_channels”:3
“image_range_min”:-127.0
“image_range_max”:128.0
网络架构允许对图像尺寸进行更改。‘image_width’和‘image_height’不应小于47像素。没有最大图像大小限制,但是大的图像大小会显著增加内存需求和运行时间。改变图像大小将重新初始化完全连接层的权重,因此需要重新训练。
'pretrained_dl_classifier_mobilenet_v2.hdl':
这个分类器是一个小而低功耗的模型,因为什么原因它更适合于移动和嵌入式视觉应用。
分类器期望图像属于该类型。此外,网络需要某些图像属性。可以使用realget_dl_model_param检索相应的值。默认值:
“image_width”:224
“image_height”:224
“image_num_channels”:3
“image_range_min”:-127.0
“image_range_max”:128.0
网络架构允许对图像尺寸进行更改。‘image_width’和‘image_height’不应小于32像素。没有最大图像大小限制,但是大的图像大小会显著增加内存需求和运行时间。
在GPU上,网络架构可以从特殊的优化中受益匪浅,没有这些优化,网络就会明显变慢。
'pretrained_dl_classifier_resnet18.hdl':
随着神经网络pretrained_dl_classifier_enhanced。这个分类器适用于更复杂的任务。然而,由于其特殊的结构,它提供了使训练更稳定和内部更鲁棒的优势。与神经网络pretrained_dl_classifier_resnet50相比。它不那么复杂,推理时间也更快。
分类器期望图像属于该类型。此外,网络需要某些图像属性。可以使用realget_dl_model_param检索相应的值。默认值:
“image_width”:224
“image_height”:224
“image_num_channels”:3
“image_range_min”:-127.0
“image_range_max”:128.0
网络架构允许对图像尺寸进行更改。‘image_width’和‘image_height’不应小于32像素。没有最大图像大小限制,但是大的图像大小会显著增加内存需求和运行时间。尽管是完全连接层,图像大小的改变并不会导致权重的重新初始化。
'pretrained_dl_classifier_resnet50.hdl':
随着神经网络pretrained_dl_classifier_enhanced。这个分类器适用于更复杂的任务。然而,由于其特殊的结构,它提供了使训练更稳定和内部更鲁棒的优势。
分类器期望图像属于该类型。此外,网络需要某些图像属性。可以使用realget_dl_model_param检索相应的值。默认值:
“image_width”:224
“image_height”:224
“image_num_channels”:3
“image_range_min”:-127.0
“image_range_max”:128.0
网络架构允许对图像尺寸进行更改。‘image_width’和‘image_height’不应小于32像素。没有最大图像大小限制,但是大的图像大小会显著增加内存需求和运行时间。尽管是完全连接层,图像大小的改变并不会导致权重的重新初始化。
语义分割模型
语义分割结合了图像分类、目标检测和图像分割,通过一定的方法将图像分割成具有一定语义含义的区域块,并识别出每个区域块的语义类别,实现从底层到高层的语义推理过程,最终得到一幅具有逐像素语义标注的分割图像。
以下预训练神经网络用于语义 分割:
'pretrained_dl_edge_extractor.hdl':
该神经网络是为边缘提取而设计和预训练的。因此,该模型适用于两类问题,一类用于边缘,一类用于背景。
该网络期望图像是该类型的。此外,该网络是为某些图像属性设计的。可以使用realget_dl_model_param检索相应的值。默认值:
“image_width”:512
“image_height”:512
“image_num_channels”:1
“image_range_min”:-127.0
“image_range_max”:128.0
“num_classes”:2
网络架构允许更改图像尺寸,但是‘image_width’和‘image_height’的大小必须是16像素的倍数,因此最少为16像素。
“pretrained_dl_segmentation_compact.hdl”:
该神经网络设计用于处理具有详细结构的分割任务,并且仅使用少量内存并且运行时效率高。
网络架构允许更改图像尺寸,但要求最小的“image_width”和“image_height”为21像素。
“pretrained_dl_segmentation_enhanced.hdl”:
这个神经网络比pretrained_dl_segmentation_compact有更多的隐藏层。因此更适合于包括更复杂场景在内的分割任务。
网络架构允许更改图像尺寸,但要求最小的image_width和image_height为47像素。
Deep OCR 模型
为 Deep OCR 提供了以下预训练神经网络:
'pretrained_deep_ocr_recognition.hdl':
该神经网络是深度OCR模型的预训练识别组件。它被设计用来识别被裁剪成单个单词的图像上的单词。这是深度OCR的识别部分,可以再训练。
该网络期望图像是该类型的。此外,该网络是为某些图像属性设计的。可以使用realget_dl_model_param检索相应的值。默认值:
“image_width”:120
“image_height”:32
“image_num_channels”:1
“image_range_min”:-1.0
“image_range_max”:1.0
网络架构允许改变图像宽度‘image_width’。图像高度‘image_height’不能更改。参数‘image_width’非常重要:它的值可以减少或增加以适应单词的预期长度,例如,由于每个字符的平均宽度。更大的image_width将消耗更多的时间和内存资源。图像宽度‘image_width’可以在训练后更改。