ProfibusDP转ModbusRTU网关,流量计接入新方案!
ProfibusDP转ModbusRTU网关,流量计接入新方案!
在现代化工控系统中,ProfibusDP作为一种广泛使用的现场总线标准,凭借其高速、可靠的数据传输能力,在自动化领域占据重要地位。而Modbus RTU则以其简单性和兼容性,在各种工业设备中得到了广泛应用。随着工业4.0和智能制造的不断推进,不同通信协议之间的互联互通成为了提升生产效率和灵活性的关键。本文将聚焦于如何将ProfibusDP主站转换为Modbus RTU网关以接入流量计的过程,旨在通过详细的步骤和技术解析,帮助工程师和技术人员理解并实现不同通信协议间的转换,促进工业自动化系统的集成与优化。

我们需要了解ProfibusDP和Modbus RTU的基本概念及特点。ProfibusDP是一种高速、实时的现场总线技术,适用于复杂的自动化系统,能够提供稳定的数据传输性能。而Modbus RTU则是一种串行通信协议,因其实现简单、成本低廉,被广泛应用于各类工业控制设备中。两者虽然各有优势,但在实际应用中,往往需要将它们进行有效整合,以实现更广泛的设备互连。
在进行ProfibusDP主站到Modbus RTU网关的转换之前,我们需要准备相关的硬件和软件工具。硬件方面,我们需要一个支持双协议的网关设备,它应具备ProfibusDP接口和RS485接口,用于分别连接ProfibusDP网络和Modbus RTU设备。此外,还需要相应的电缆、连接器等辅助材料。在软件方面,则需要配置工具和编程软件,以便对网关进行参数设置和功能开发。

接下来是具体的转换步骤。第一步,我们需要对网关设备进行物理连接。将网关的ProfibusDP接口通过专用电缆连接到ProfibusDP网络上,确保连接牢固且符合电气规范。同时,将网关的RS485接口通过另一根电缆连接到流量计或其他Modbus RTU设备上。
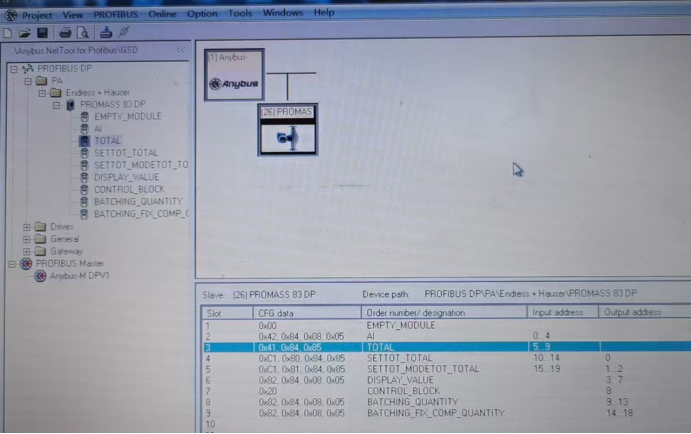
第二步是配置网关参数。使用配置工具或编程软件,对网关进行初始化设置。这包括设定ProfibusDP网络的参数(如站点地址、波特率等),以及Modbus RTU通信的相关参数(如波特率、数据位、停止位等)。此外,还需要根据实际需求,设置数据映射关系,即将ProfibusDP网络中的数据点映射到Modbus寄存器中,反之亦然。
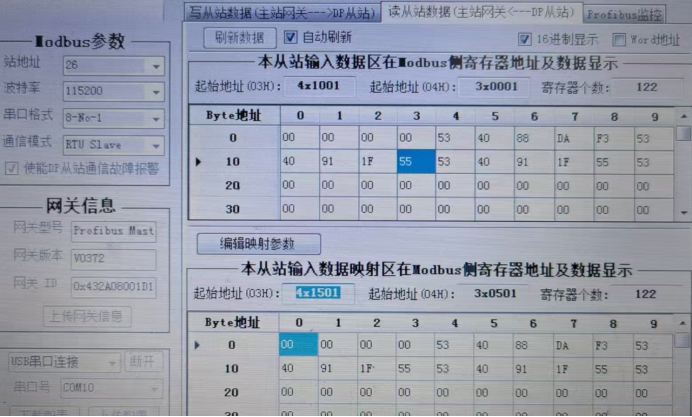
第三步是编写数据转换逻辑。由于ProfibusDP和Modbus RTU在数据格式和传输方式上存在差异,我们需要编写特定的转换程序,以确保数据在不同协议之间正确转换。这通常涉及到对数据的解析、重组以及错误检测等处理过程。在编写过程中,要充分考虑数据的实时性和准确性要求,确保转换后的数据能够满足系统的实际需求。
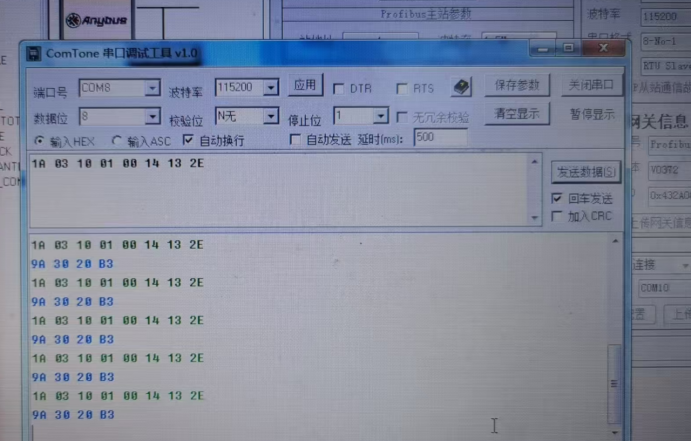
第四步是测试与调试。完成配置和编程后,我们需要对整个系统进行全面的测试。这包括单元测试(检查单个设备的通信状态)、集成测试(验证多个设备之间的协同工作)以及性能测试(评估系统在高负载下的响应能力)。在测试过程中,要注意观察是否有数据传输错误、延迟过大或设备掉线等问题,并根据实际情况进行调整和优化。
第五步是部署与维护。当系统经过充分测试并稳定运行时,可以将其部署到生产环境中。在部署过程中,要做好现场施工和安全防护工作,确保系统的可靠性和安全性。同时,还需要建立完善的维护机制,定期对系统进行检查和维护,及时发现并处理潜在的问题。
通过以上步骤,我们可以实现从ProfibusDP主站到Modbus RTU网关的转换,并将流量计成功接入系统。这一过程不仅提高了系统的灵活性和扩展性,也为工业自动化系统的集成与优化提供了有力的技术支持。希望本文能为工程师和技术人员提供一种解决实际问题的有益参考和方法指导。