🏡作者主页:点击!
🤖编程探索专栏:点击!
⏰️创作时间:2024年11月12日11点25分
点击开启你的论文编程之旅![]() https://www.aspiringcode.com/content?id=17231829233829
https://www.aspiringcode.com/content?id=17231829233829
情感识别:多模态情感计算的发展趋势!
人类语言不仅拥有口头语言而且拥有来自视觉(面部特征)和声学(声调)模态的非语言行为。这种丰富的信息为我们提供了理解人类行为和意图的益处的报告。然而,不同模态之间的异质性往往增加了分析人类语言的难度。例如,音频和视频流的接收器可能随着可变的接收频率而变化,因此我们可能无法获得它们之间的最佳映射。皱眉的脸可能与过去说的悲观的话有关。
此外,人类情绪表达通常是多模态的,它包括自然语言、面部手势和声学行为的混合。然而,在建模这样的多模态人类语言时间序列数据中存在两个主要挑战:
- 由于来自每个模态的序列的可变采样率而导致的固有数据非对齐;
- 跨模态的元素之间的长程依赖性。

抑郁症是一种全球性、广泛存在的心理健康问题,严重影响着患者的日常生活和社会功能,并带来巨大的社会和经济负担。传统的抑郁症检测方法主要依赖于患者的自我报告和临床访谈,但这些方法具有主观性强、受患者表达能力限制的缺点,可能导致早期症状被忽视或误判。因此,寻找更客观、精准的检测手段成为当今抑郁症研究的重点。
多模态抑郁症检测应运而生,依托于人工智能、机器学习和大数据分析等技术的进步,通过综合分析语音、表情、文本、行为、心理生理数据等多种信息源,能够更全面地捕捉和识别抑郁症的多维度表现。这种方法不仅提高了抑郁症检测的准确性和客观性,还具有早期发现、持续监测和个性化干预的潜力,为抑郁症的管理和治疗带来了新的希望和可能性。

我致力于对情感计算领域的经典模型进行分析、解读和总结,此外,由于现如今大多数的情感计算数据集都是基于英文语言开发的,我们计划在之后的整个系列文章中将中文数据集(SIMS, SIMSv2)应用在模型中,以开发适用于国人的情感计算分析模型,并应用在情感疾病(如抑郁症、自闭症)检测任务,为医学心理学等领域提供帮助,在未来,我也计划加入更多小众数据集,以便检测更隐匿的情感,如嫉妒、嘲讽等,使得AI可以更好的服务于社会。
【注】 我们文章中所用到的数据集,都经过重新特征提取形成新的数据集特征文件(.pkl),另外该抑郁症数据集因为涉及患者隐私,需要向数据集原创者申请,申请和下载链接都放在了我们附件中的 readme文件中,感兴趣的小伙伴可以进行下载,谢谢支持!
一、概述
这篇文章,我开始介绍第五篇情感计算经典论文模型,他是ACL 2019的一篇多模态情感计算的论文 “Multimodal Transformer for Unaligned Multimodal Language Sequences”,其中提出的模型是MulT;
此外,原创部分为加入了抑郁症数据集以实现抑郁症检测任务,以及在SIMS数据集和SIMV2数据集上进行实验。
二、论文地址
Multimodal Transformer for Unaligned Multimodal Language Sequences
三、研究背景
Transformer网络首次被引入用于神经机器翻译(NMT)任务,其中编码器和解码器侧各自利用自注意 Transformer。在自关注的每一层之后,编码器和解码器通过附加的解码器子层连接,其中解码器针对目标文本的每个元素来关注源文本的每个元素。为了以获得该模型的更详细解释。除了NMT之外,Transformer网络也已经成功地应用于其他任务,包括语言建模,语义角色标注,词义消歧、学习句子表征,以及视频活动识别。本文从NMT Transformer中汲取了很强的启发,将其扩展到多模态环境中。NMT Transformer侧重于从源文本到目标文本的单向翻译,而人类多模态语言的时间序列既不像单词嵌入那样被很好地表示,也不像单词嵌入那样是离散的,每种模态的序列具有非常不同的频率。因此,我们建议不要明确地从一种模态翻译到另一种模态(这可能极具挑战性),而是通过注意来潜在地调整跨模态的元素。因此,我们的模型(MulT)没有编码器-解码器结构,但它是由多个成对和双向跨模态注意块堆栈构建的,这些块直接关注低层特征(同时去除自注意)。
四、模型结构和代码
1. 总体框架
在本节中,我们描述了用于对未对齐的多模态语言序列进行建模的多模态Transformer(MulT)如下图。在高层次上,MulT通过前馈融合过程从多个方向成对交叉模态变换器合并多模态时间序列。具体来说,每个跨模态Transformer通过学习两种模态的特征之间的注意力,用来自另一源模态的低级特征反复强化目标模态。因此,MulT架构利用这种跨模态变换器对所有模态对进行建模,随后是序列模型(例如,自我注意力(self-attention)Transformer),其使用融合特征进行预测。
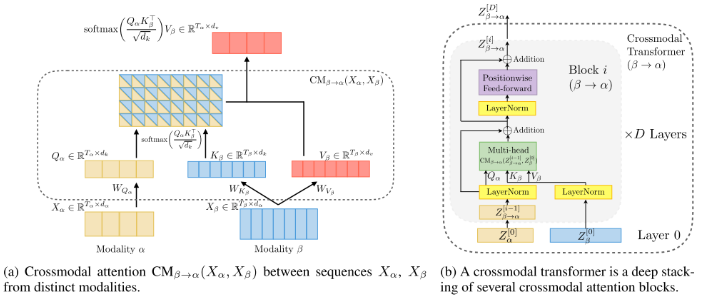
2. Crossmodal Attention
我们考虑了两种模态 𝛼α 和 𝛽β,每种模态中分别有两个(可能未对齐的)序列,分别表示为 𝑋𝛼∈𝑅𝑇𝛼×𝑑𝛼Xα∈RTα×dα 和 𝑋𝛽∈𝑅𝑇𝛽×𝑑𝛽Xβ∈RTβ×dβ。在本文中,𝑇(⋅)T(⋅) 和 𝑑(⋅)d(⋅) 分别表示序列长度和特征维度。受到神经机器翻译(NMT)中解码器 Transformer (Vaswani et al., 2017) 的启发,我们假设融合跨模态信息的一个有效方法是提供跨模态的潜在适配,即从 𝛽β 到 𝛼α。需要注意的是,本文中讨论的模态可能跨越非常不同的领域,例如面部属性和口语单词。
我们定义 Query 为 𝑄𝛼=𝑋𝛼𝑊𝑄𝛼Qα=XαWQα,Key 为 𝐾𝛽=𝑋𝛽𝑊𝐾𝛽Kβ=XβWKβ,Value 为 𝑉𝛽=𝑋𝛽𝑊𝑉𝛽Vβ=XβWVβ,其中 𝑊𝑄𝛼∈𝑅𝑑𝛼×𝑑𝑘WQα∈Rdα×dk,𝑊𝐾𝛽∈𝑅𝑑𝛽×𝑑𝑘WKβ∈Rdβ×dk 和 𝑊𝑉𝛽∈𝑅𝑑𝛽×𝑑𝑣WVβ∈Rdβ×dv 是权重矩阵。从 𝛽β 到 𝛼α 的潜在适配表示为跨模态注意力 𝑌𝛼:=CM𝛽→𝛼(𝑋𝛼,𝑋𝛽)∈𝑅𝑇𝛼×𝑑𝑣Yα:=CMβ→α(Xα,Xβ)∈RTα×dv:
公式可以翻译如下:
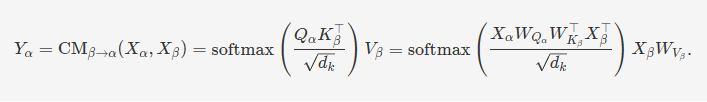
这表示了从模态 𝛽β 到模态 𝛼α 的跨模态注意力 𝑌𝛼Yα 的计算过程。具体步骤如下:
- 计算 Query 向量 𝑄𝛼Qα 和 Key 向量 𝐾𝛽Kβ 的点积,并除以 𝑑𝑘dk 进行缩放。
- 对上述结果应用 softmax 函数以获得注意力权重。
- 使用这些注意力权重对模态 𝛽β 的 Value 向量 𝑉𝛽Vβ 进行加权求和,得到跨模态的注意力表示 𝑌𝛼Yα。
请注意,𝑌𝛼Yα 的长度与 𝑄𝛼Qα 相同(即 𝑇𝛼Tα),但同时它表示在 𝑉𝛽Vβ 的特征空间中。具体来说,公式 (1) 中的缩放 (通过 𝑑𝑘dk) softmax 计算了一个得分矩阵 softmax(⋅)∈𝑅𝑇𝛼×𝑇𝛽softmax(⋅)∈RTα×Tβ,其 (𝑖,𝑗)(i,j) 项表示模态 𝛼α 的第 𝑖i 个时间步对模态 𝛽β 的第 𝑗j 个时间步的注意力。因此,𝑌𝛼Yα 的第 𝑖i 个时间步是 𝑉𝛽Vβ 的加权总结,其中的权重由 softmax(⋅)softmax(⋅) 中的第 𝑖i 行确定。
3. Overall Architecture
多模态语言序列通常涉及三种主要模态:语言 (L)、视频 (V) 和音频 (A) 模态。我们用 𝑋{𝐿,𝑉,𝐴}∈𝑅𝑇{𝐿,𝑉,𝐴}×𝑑{𝐿,𝑉,𝐴}X{L,V,A}∈RT{L,V,A}×d{L,V,A} 表示这三种模态的输入特征序列及其对应的维度。在此符号的基础上,本小节将详细描述多模态 Transformer 的组件以及如何应用跨模态注意力模块。
1. Temporal Convolutions. 为了确保输入序列中的每个元素能够充分感知其邻近元素,我们将输入序列通过一个一维卷积层(1D temporal convolutional layer)进行处理:
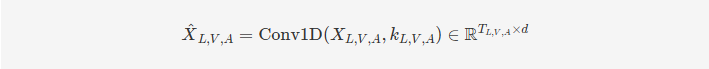
其中,𝑘𝐿,𝑉,𝐴kL,V,A 是针对模态 {L, V, A} 的卷积核大小,而 𝑑d 是统一的特征维度。经过卷积处理后的序列预计能够包含序列的局部结构,这一点非常重要,因为这些序列是在不同的采样率下收集的。此外,由于时间卷积将不同模态的特征投影到相同的维度 𝑑d,因此在跨模态注意力模块中可以进行点积操作。
2.Positional Embedding. 为了使序列能够携带时间信息,参考 (Vaswani et al., 2017) 的方法,我们在 𝑋^𝐿,𝑉,𝐴X^L,V,A 上添加了位置嵌入(PE):
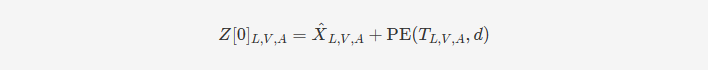
其中,PE(𝑇𝐿,𝑉,𝐴,𝑑)PE(TL,V,A,d) 是位置嵌入,旨在为每个时间步的输入序列提供时间位置信息,而 𝑍𝐿,𝑉,𝐴[0]ZL,V,A[0] 是不同模态的低级位置感知特征。
3.Crossmodal Transformers 基于交叉模态注意力块,我们设计了交叉模态变换器,使得一种模态能够从另一种模态接收信息。在以下内容中,我们以将视觉(V)信息传递给语言(L)的例子进行说明,这被表示为“V → L”。我们将每个交叉模态注意力块的所有维度(d{α,β,k,v})固定为 d。
每个交叉模态变换器由 D 层交叉模态注意力块组成。形式上,交叉模态变换器在 i = 1, …, D 层中按以下方式进行前向计算:

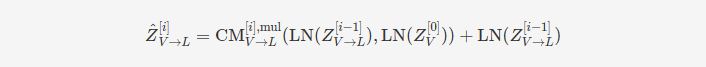
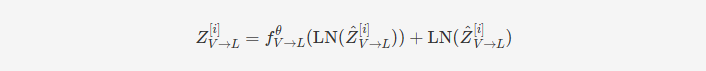
其中 𝑓𝜃fθ 是一个位置逐元素的前馈子层,由参数 𝜃θ 参数化,而 CM𝑉→𝐿[𝑖],mulCMV→L[i],mul 表示第 𝑖i 层的 CM𝑉→𝐿CMV→L 的多头版本。
在这一过程中,每个模态通过多头跨模态注意模块的低级外部信息不断更新其序列。在跨模态注意块的每一层中,源模态的低级信号被转换为不同的键/值对,以便与目标模态进行交互。
4. Self-Attention Transformers and Prediction As a final step, we concatenate the outputs from the cross-modal transformers that share the same target modality to yield 𝑍𝐿,𝑉,𝐴∈𝑅𝑇𝐿,𝑉,𝐴×2𝑑ZL,V,A∈RTL,V,A×2d. For example, 𝑍𝐿=[𝑍𝑉→𝐿[𝐷];𝑍𝐴→𝐿[𝐷]]ZL=[ZV→L[D];ZA→L[D]]. Each of these is then passed through a sequence model to collect temporal information for predictions. We use the self-attention transformer . Finally, the last elements of the sequence models are extracted and passed through fully-connected layers to make predictions.
五、数据集介绍
1. CMU-MOSI: CMU-MOSI数据集是MSA研究中流行的基准数据集。该数据集是YouTube独白的集合,演讲者在其中表达他们对电影等主题的看法。MOSI共有93个视频,跨越89个远距离扬声器,包含2198个主观话语视频片段。这些话语被手动注释为[-3,3]之间的连续意见评分,其中-3/+3表示强烈的消极/积极情绪。
2. CMU-MOSEI: CMU-MOSEI数据集是对MOSI的改进,具有更多的话语数量,样本,扬声器和主题的更大多样性。该数据集包含23453个带注释的视频片段(话语),来自5000个视频,1000个不同的扬声器和250个不同的主题
3. AVEC2019: AVEC2019 DDS数据集是从患者临床访谈的视听记录中获得的。访谈由虚拟代理进行,以排除人为干扰。与上述两个数据集不同的是,AVEC2019中的每种模态都提供了几种不同的特征。例如,声学模态包括MFCC、eGeMaps以及由VGG和DenseNet提取的深度特征。在之前的研究中,发现MFCC和AU姿势分别是声学和视觉模态中两个最具鉴别力的特征。因此,为了简单和高效的目的,我们只使用MFCC和AU姿势特征来检测抑郁症。数据集用区间[0,24]内的PHQ-8评分进行注释,PHQ-8评分越大,抑郁倾向越严重。该基准数据集中有163个训练样本、56个验证样本和56个测试样本。
4. SIMS/SIMSV2: CH-SIMS数据集[35]是一个中文多模态情感分析数据集,为每种模态提供了详细的标注。该数据集包括2281个精选视频片段,这些片段来自各种电影、电视剧和综艺节目,每个样本都被赋予了情感分数,范围从-1(极度负面)到1(极度正面)
六、性能展示
- 在情感计算任务中,可以看到 MFM 模型性能超越其他模型,证明了其有效性;
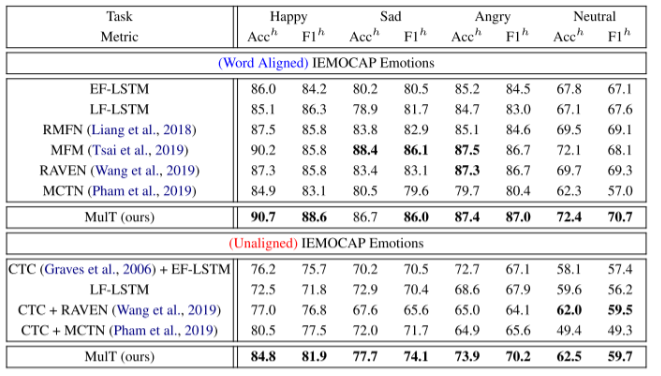
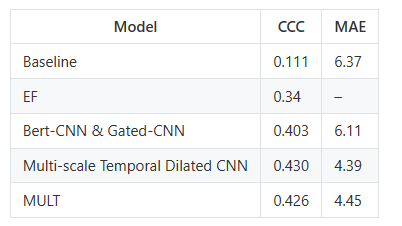
- 抑郁症检测任务,以下是 MFM 模型在抑郁症数据集AVEC2019中的表现:
七、复现过程
在下载附件并准备好数据集并调试代码后,进行下面的步骤,附件已经调通并修改,可直接正常运行;
1. 下载多模态情感分析集成包
pip install MMSA2. 进行训练
from MMSA import MMSA_run# run LMF on MOSI with default hyper parameters
MMSA_run('lmf', 'mosi', seeds=[1111, 1112, 1113], gpu_ids=[0])# tune Self_mm on MOSEI with default hyper parameter range
MMSA_run('self_mm', 'mosei', seeds=[1111], gpu_ids=[1])# run TFN on SIMS with altered config
config = get_config_regression('tfn', 'mosi')
config['post_fusion_dim'] = 32
config['featurePath'] = '~/feature.pkl'
MMSA_run('tfn', 'mosi', config=config, seeds=[1111])# run MTFN on SIMS with custom config file
MMSA_run('mtfn', 'sims', config_file='./config.json')八、运行过程
1.训练过程
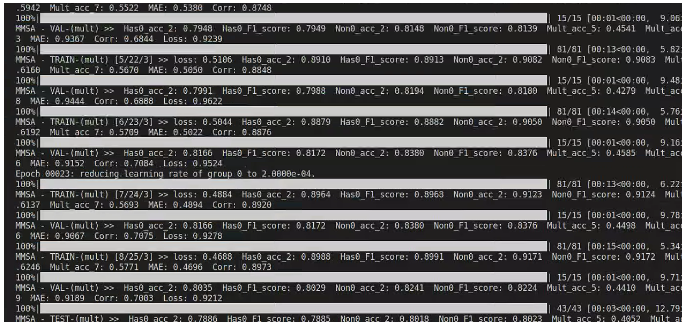
2.最终结果

MULT模型总结
- 高效的多模态融合:MULT模型通过跨模态注意力机制(cross-modal attention)有效融合了多种模态(语言、视频、音频)的信息。这种融合方式不仅能够在模态之间传递信息,还能够保留各模态的独特特征,增强模型的综合表现。
- 适应不同模态的特性:模型引入了1D时域卷积层(Conv1D),这使得不同模态的特征能够在同一维度上进行比较和计算。该层还能捕捉序列的局部结构,这对于处理不同采样率的序列数据尤为重要。
- 位置感知的特征表示:MULT模型通过位置嵌入(Positional Embedding)增强了输入序列的时间信息,使模型在处理时间序列数据时更加准确。这种位置感知的特征表示对于处理具有时间依赖性的多模态数据非常有效。
- 层次化的跨模态交互:MULT模型采用层次化的跨模态注意力机制,使得每一层都能有效地更新模态的表示。随着层数的增加,模型能够逐渐学习到更高层次的跨模态交互信息,提升整体的特征表示能力。
- 强大的预测能力:通过结合自注意力机制(Self-Attention Transformer),MULT模型在捕捉全局时间依赖性和生成最终预测方面表现出色。最后一步将跨模态变压器的输出通过序列模型进行时间信息的汇总,再通过全连接层生成预测,使得预测更加准确和稳健。
适用场景
- 情感分析:MULT模型适用于处理带有复杂情感信息的多模态数据(如文本、视频和音频),并能够精确捕捉和分析情感特征。其多模态融合和跨模态交互能力使其在情感分析任务中表现出色。
- 多模态内容理解:在需要结合多种感知信息(如语言、视觉、声音)来理解内容的任务中,MULT模型表现尤为突出。它能够有效地融合来自不同来源的信息,生成更为全面和精确的理解。
- 视频和音频分析:对于需要同时处理和分析视频与音频数据的任务,MULT模型能够高效地融合视觉和听觉信息,适用于如视频理解、音频分类等场景。
- 人机交互:在涉及多模态数据的人机交互场景中,MULT模型能够融合语言、视觉和听觉信息,提升系统对用户输入的理解能力,从而实现更为自然和智能的交互。
- 医疗诊断:在需要结合多模态数据(如影像、语音、文字)进行诊断的医疗场景中,MULT模型能够提供更为准确的多维度分析,辅助医生做出决策。
成功的路上没有捷径,只有不断的努力与坚持。如果你和我一样,坚信努力会带来回报,请关注我,点个赞,一起迎接更加美好的明天!你的支持是我继续前行的动力!"
"每一次创作都是一次学习的过程,文章中若有不足之处,还请大家多多包容。你的关注和点赞是对我最大的支持,也欢迎大家提出宝贵的意见和建议,让我不断进步。"
神秘泣男子