在图文组合任务中,常见的图文融合方式有多种,比如简单的拼接、加权求和、注意力机制、跨模态Transformer等。为了让图片充分补充文本的语义信息,我们可以使用一种简单且有效的图文融合方法,比如通过注意力机制。
我们可以让文本特征作为查询(Query),图片特征作为键(Key)和值(Value),通过注意力机制让文本特征从图片特征中获取信息。这样,图片特征就可以在文本的指导下为每个文本单词提供补充信息。
核心步骤:
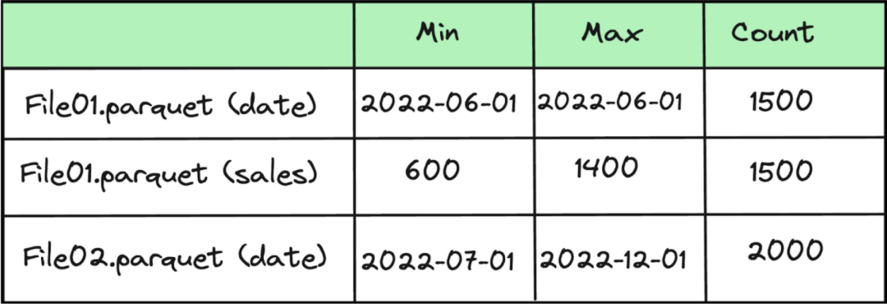
图片特征扩展:由于图片特征是 [1, 768],而文本特征是 [8, 768],我们可以将图片特征扩展成与文本特征相同的形状 [8, 768]。
注意力机制:使用文本特征作为查询(Query),图片特征作为键(Key)和值(Value),计算注意力权重并融合特征。
融合输出:得到新的文本表示,它不仅包含原始文本的语义信息,还从图片中获取了相关的视觉信息。
import torch
import torch.nn as nnclass ImageTextFusion(nn.Module):def __init__(self, feature_dim, num_heads):super(ImageTextFusion, self).__init__()self.feature_dim = feature_dimself.text_proj = nn.Linear(feature_dim, feature_dim) # 映射文本特征self.image_proj = nn.Linear(feature_dim, feature_dim) # 映射图片特征self.attention = nn.MultiheadAttention(embed_dim=feature_dim, num_heads=num_heads)def forward(self, image_feat, text_feat):"""image_feat: 图片特征, shape [1, 768]text_feat: 文本特征, shape [8, 768]"""# 扩展图片特征到与文本特征相同的形状image_feat_expanded = image_feat.expand(text_feat.size(0), -1) # [8, 768]# 映射特征image_feat_proj = self.image_proj(image_feat_expanded) # [8, 768]text_feat_proj = self.text_proj(text_feat) # [8, 768]# 将文本特征作为查询,图片特征作为键和值attn_output, attn_weights = self.attention(query=text_feat_proj.unsqueeze(1), # [8, 1, 768]key=image_feat_proj.unsqueeze(1), # [8, 1, 768]value=image_feat_proj.unsqueeze(1), # [8, 1, 768]need_weights=False)# 将输出重新变形回 [8, 768]fused_text_feat = attn_output.squeeze(1) # [8, 768]return fused_text_feat# 示例输入
image_feat = torch.randn(1, 768) # 图片特征
text_feat = torch.randn(8, 768) # 文本特征# 初始化模型
fusion_model = ImageTextFusion(feature_dim=768, num_heads=8)# 前向传播
fused_output = fusion_model(image_feat, text_feat)print(fused_output.shape) # 输出形状应为 [8, 768]
代码解析:
text_proj 和 image_proj:分别用于将文本特征和图片特征映射到相同的特征空间,以便进行特征融合。
MultiheadAttention:这是 PyTorch 提供的多头注意力机制。我们将文本特征作为 Query,图片特征作为 Key 和 Value,通过注意力机制,使得每个文本单词从图片特征中获取相关的信息。
image_feat.expand(text_feat.size(0), -1):扩展图片特征,使其与文本特征具有相同的形状 [8, 768]。
unsqueeze(1):将特征的维度增加一个维度,符合 MultiheadAttention 的输入格式。
squeeze(1):将多头注意力输出的维度恢复到 [8, 768]。
总结:
这种方法使用了注意力机制,让文本特征能够从图片特征中获取信息,从而实现图文融合。注意力机制的优势在于,它可以为每个文本单词动态地分配不同的图片信息。









![[项目代码] YOLOv5 铁路工人安全帽安全背心识别 [目标检测]](https://i-blog.csdnimg.cn/direct/6b10c23808504f54bca3f9dcab1dd4ad.jpeg)