数据湖仓一体架构由 Apache Hudi、Apache Iceberg 和 Delta Lake 等开放表格式提供支持,提供了一种开放且经济高效的方式来管理组织不断增长的数据和分析需求。它提供了在同一数据存储上运行并发事务的可靠性,从而提高了效率。数据湖仓一体支持关键功能,例如 ACID 事务、架构演变、时间旅行和增量/CDC 查询,这些功能以前在数据湖上不可用。
虽然采用湖仓一体架构提供了这些切实的好处,但重要的是要认识到这只是旅程的第一步。随着越来越多的数据被摄取到存储中,无论是 Amazon S3、GCS 或 Azure Blob 等云对象存储,还是本地系统,都必须考虑湖仓一体中数据文件的最佳管理。对数百 TB 甚至 PB 的数据运行查询需要持续优化以保持性能。
尽管查询可能正在高效运行,但将来可能并非总是如此。如果不进行适当的优化,随着数据的增长和存储空间中积累更多的文件,性能可能会下降。通常可能会开始遇到以下常见问题:
• 由于文件杂乱无章或文件小而导致查询速度变慢:如果不定期维护,计算引擎最终可能会扫描大量大小低下或杂乱无章的文件,从而导致查询时间延长和成本增加。此外由多个团队运行相同的慢速查询可能会导致查询时间和成本增加。
• 不断变化的查询模式:随着时间的推移,业务需求可能会发生变化,从而导致访问和分析最初未针对数据进行优化的新方法。
• 新查询和工作负载:新兴的分析使用案例可能需要不同的查询优化来保持性能。
要应对这些挑战,需要执行各种优化任务,包括分区、压缩、集群、数据跳过和清理。这些技术可以更好地组织数据,有助于在查询期间删除不必要的数据,并确保数据可以有效地访问并随着时间的推移保持可管理性。在查询期间需要扫描的数据越少,查询的速度就越快,成本效益就越高。
在下面的部分中,我们将详细介绍这些技术,并提供有关如何应用它们来优化数据湖仓一体中的存储并提高查询性能的见解。
分区
分区是优化大规模数据数据访问的最基本技术之一。它涉及根据特定列(通常是通常查询的字段)或条件(如日期、地理区域或类别)将数据划分为更小、更易于管理的块或分区。分区通过将需要读取的数据限制为仅相关分区,有助于减少查询期间扫描的数据量。
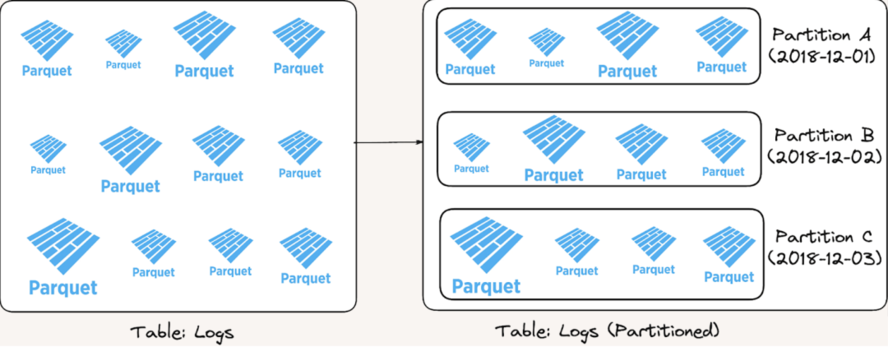
图 1:分区前后的 Logs 表
查询:
SELECT details FROM Logs
WHERE event_date = '2018-12-02'
例如,考虑 Logs 表,如上所示。最初该表由一组数据文件组成,每个文件表示日志条目的混合。如果我们运行查询来检索特定日期范围(例如 2018 年 12 月 2 日)的日志条目,则查询引擎必须扫描表中的所有文件才能找到匹配的行。这种方法效率低下,尤其是在处理大量数据时。
在这种情况下,如果我们按 event_date 对表进行分区,则可以将日志数据组织成组,其中每个分区都包含特定日期的日志。例如,分区 A 保存 2018 年 12 月 1 日的日志,分区 B 保存 2018 年 12 月 2 日的日志,依此类推。此分段允许查询引擎完全跳过不相关的分区。在我们的示例中,如果我们只对 2018 年 12 月 2 日的日志感兴趣,引擎可以忽略分区 A 和 C,它们分别包含 12 月 1 日和 3 日的日志。
除了性能优势之外,分区[1]还为数据架构提供了一系列其他优势。其中一个优势是可扩展性。通过跨多个分区分配数据,系统可以水平扩展,从而允许随着数据量的增长而轻松扩展。分区还可以增强可用性。由于数据分布在多个分区中,因此单个分区的故障不会使整个系统瘫痪;相反只有受影响的特定分区可能暂时不可用,而其余数据仍可访问。
文件大小 (压缩)
随着时间的推移,随着数据被摄取到存储系统中,会产生大量小文件,从而导致通常所说的“小文件问题”。这些小文件会导致查询引擎处理许多文件,从而增加 I/O 开销并降低查询性能,因为打开、读取和关闭每个文件都会产生成本(取决于查询)。
文件大小调整或压缩是数据湖仓一体架构中的一项重要技术,可确保将大小低下的小型文件合并为更大、更优化的文件。如果不定期压缩,文件计数可能会呈指数级增长,随着数据量的增加,系统性能会严重下降。
文件大小调整算法的目标是将这些较小的文件合并为满足系统目标文件大小的较大文件,从而减少文件数量并提高查询效率。通过这样做,系统可以保持快速查询速度并优化存储使用情况,最终提供更好的可扩展性和成本效率。
跨开放表格式进行压缩的最常用算法之一是 bin 打包算法。此算法旨在将小文件合并为较大的、接近最佳大小的文件,确保合并的文件接近系统定义的目标大小,而不会超过该大小。装箱方法简单而有效,因为它可以有效地对小文件进行分组,以最大限度地减少空间浪费并减少整体文件数量。
如图所示,小文件(文件 1:40 MB、文件 2:80 MB 和文件 3:90 MB)被压缩为大小合适的较大文件,达到系统的目标文件大小 120 MB。此过程减少了文件总数,同时确保每个文件都得到充分利用,从而提高了查询性能并降低了存储开销。

图 2:将较小大小的文件合并为较大的文件的压缩过程
Apache Hudi 架构的一个关键设计特征是其避免创建小文件的内置能力。Hudi 经过独特设计,可自动将文件写入最佳大小,无需手动管理文件大小[2]。在数据摄取期间,Hudi 使用配置设置动态调整文件大小,例如:
• Max File Size(最大文件大小):任何文件大小的上限。
• Small File Size:一个阈值,低于该阈值时,将考虑对文件进行压缩/文件大小调整。
• Insert Split Size:插入期间数据拆分的大小。
注意:在 Hudi 中,将较小大小的文件合并为较大的文件的过程(在其他湖仓一体格式中称为压缩)称为文件大小调整。Hudi 使用压缩一词来描述不同的过程[3]:将日志文件(存储在 Avro 中)与现有基本文件(存储在 Parquet 中)合并,以创建新的更新基本文件(也存储在 Parquet 中)。然后,新的更新将转到新的更改日志文件,直到下一次 Hudi 压缩操作。
作为文件大小的 Hudi 实施示例,在上图中 Hudi 使用的最大文件大小为 120 MB,小文件大小为 100 MB。在摄取过程中,Hudi 会填充文件以满足 120 MB 的限制,并根据需要整合较小的文件,以避免留下小文件。这可确保文件大小保持最佳状态,从而提高性能。此自动文件大小调整过程在每个摄取周期中发生,有助于维护大小合适的文件,并防止随着时间的推移积累小而低效的文件。最重要的是除了设置所需的阈值外,此过程不需要用户干预。
聚簇
聚簇是一种优化技术,用于对文件中的数据进行重新组织和分组,通过最大限度地减少扫描的数据量来帮助提高查询性能。聚簇解决的核心问题是数据的写入方式和查询方式之间的不一致。通常,数据是根据到达时间写入的,这不一定与事件时间或稍后查询的其他关键属性一致。例如,在查询经常按特定列(如位置或事件日期)进行筛选的分析工作负载中,分布在许多文件中的数据会迫使查询引擎扫描不必要的文件,这可能会对性能产生巨大影响。聚簇技术通常涉及两个主要策略:简单排序和多维聚簇。
排序
最简单的聚簇形式是排序,其中数据按特定列排序,例如城市(如下图所示)或其他经常查询的字段。排序可确保将具有相似值的数据行分组到一个数据文件中,每个数据文件对于其排序所依据的特定列都有唯一的值范围,从而提高数据局部性。这允许查询引擎快速查找和扫描与查询相关的数据行,从而显著减少需要读取的文件数量。

图 3:按特定字段对数据进行排序
但是,虽然排序对于具有单个谓词的查询有效,但在查询涉及多个谓词时,它有局限性。例如,如果数据按 city 排序,则同时按 city 和 trip_duration 进行筛选的查询仍需要扫描与 city 筛选器匹配的所有文件,即使 trip_duration 筛选器排除了大多数记录。这就是简单排序的不足之处 — 仅优化涉及多个字段的多维查询是不够的。
多维聚簇
为了解决简单排序的局限性,更高级的聚簇技术(如多维聚簇)开始发挥作用。多维聚簇可同时跨多个列重新组织数据,从而优化对多个维度进行筛选的查询。多维聚类中最流行的方法之一是 Z 排序[4] - 一种空间填充曲线。Z 排序以保留空间局部性的方式跨多个列对数据进行排序,这意味着相似类型的记录最终位于同一数据文件中。例如,它适用于涉及纬度和经度数据的查询,确保附近位置的数据存储在一起,从而减少需要读取的文件数。
例如,如果同时对 city 和 trip_duration 进行查询筛选,则多维聚类分析可确保对数据进行组织,以便将两个谓词的相关记录分组到同一文件中。这减少了引擎必须扫描的文件数量,从而比单独进行简单排序的查询执行速度快得多。
其他技术(如 Hilbert 曲线)可实现类似的目标,但对于处理高维数据更有效,并且在查询跨越多个复杂维度时可以提供更好的聚类分析。希尔伯特曲线确保数据点在多个维度上保持紧密联系。
在部署这些聚类算法方面,Apache Hudi 提供了不同的模型。这些大致分为 asynchronous[5] 和 synchronous (inline[6])。内联集群通常作为常规摄取管道的一部分进行,这意味着在聚簇完成之前,无法进行下一轮摄取。另一方面,异步聚簇允许 Hudi 优化数据布局,而不会阻止正在进行的数据摄取。这使得 Hudi 对于需要频繁数据摄取和快速、高效查询的工作负载特别有效。有三种部署模式可用于运行异步聚簇:
• 同一进程内的异步执行
• 由单独的进程异步调度和执行
• 内联调度和异步执行
Hudi 允许根据查询模式,根据不同的排序或多维技术(如 Z 排序和希尔伯特曲线[7])对数据进行聚类。
数据跳过
数据跳过是一种用于通过消除扫描不相关数据文件来提高查询性能的技术。通过这样做,数据跳过可以最大限度地减少扫描的数据量,从而缩短查询执行时间并减少资源使用。这些技术在数据湖存储中尤其突出,因为数据湖存储的数据量通常很高。
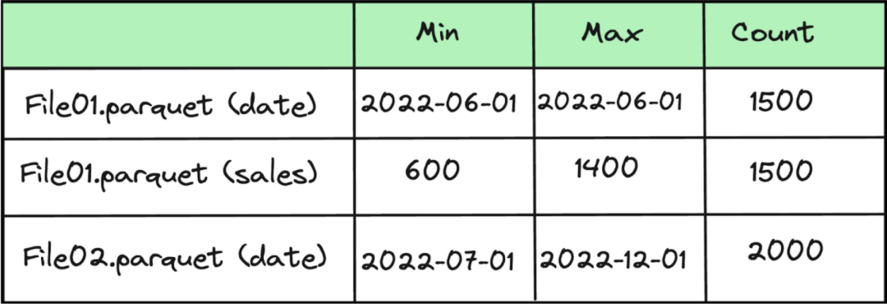
图 4:显示字段的最小/最大值及其计数的 Parquet 页脚元数据
Parquet 文件格式是数据跳过的一个常见示例,该格式存储列级统计信息,例如每个文件的最小值和最大值。例如,在上面显示的 sales 表中,每个 Parquet 文件都记录了有关列(如 date 或 sales)的最小值和最大值的元数据。当查询按特定日期范围(例如,date >= '2022-06-01')进行筛选时,查询引擎会使用这些最小值/最大值跳过日期范围之外的文件,从而避免扫描不相关的数据。数据跳过利用这些列统计信息(例如最小值/最大值、Null 计数和记录计数)来确保仅处理相关数据。这种方法通过减少不必要的文件扫描(尤其是对于大型数据集)来显著提高查询性能。
同样,Bloom 筛选条件提供了另一种在湖仓一体中跳过数据的可靠方法。Bloom 过滤器是一种概率数据结构,可快速确定数据集中是否存在特定值。通过使用多个哈希函数将元素映射到固定大小的位数组中,Bloom 过滤器可以有效地识别“绝对不相关”与查询相关的文件或行组。尽管它们可能会返回误报(指示值可能存在,但实际上不存在),但它们永远不会产生误报。这使得它们能够非常有效地减少大型数据集中不必要的文件扫描。
虽然使用来自单个 Parquet 文件和 Bloom 筛选器的列级统计数据有助于跳过不相关的文件,但对每个文件执行这些操作(打开每个文件、读取页脚和关闭文件)在大规模上可能会成本高昂。为了避免这种开销,Apache Hudi 利用了元数据表[8]。Hudi 元数据表是一个多模式索引子系统[9],可存储各种类型的索引,使查询引擎能够根据查询谓词高效地查找相关数据文件,而无需从每个单独的文件中读取列统计信息或 Bloom 过滤器。通过使用这些索引,Hudi 可以删除不相关的文件并加快查询速度 - 有时甚至会提高几个数量级。
清理
在数据湖仓一体系统中,清理是保持性能和管理存储成本的关键过程。随着数据的不断写入、更新和删除,较旧的文件版本和元数据往往会随着时间的推移而累积。这可能会导致严重的存储空间膨胀和较长的文件列出时间,从而对查询性能产生负面影响。查询引擎必须筛选越来越多的元数据和不相关的数据,这会增加执行查询所需的时间和资源。与传统数据库系统一样,清理通过定期删除不再需要的过时数据版本和文件,并更新元数据以匹配来解决此问题,从而保持数据集精简并针对性能进行优化。
在 Apache Hudi 中,清理[10]是一项关键的表服务,用于通过删除较旧的文件版本来回收空间,这些版本是为时间旅行和回滚等功能而保留的。Hudi 使用多版本并发控制 (MVCC) 运行,从而在读取器和写入器之间实现快照隔离。虽然这允许存储多个文件版本,有助于查询回滚和历史数据访问,但保留过多版本会显著增加存储成本。
为了在保留历史记录和最大限度地减少存储膨胀之间取得平衡,Hudi 采用了自动清理服务。默认情况下,每次提交后立即触发清理以删除较旧的文件切片,从而确保元数据和数据的增长保持有限。此自动清理过程有助于保持表精简,防止过时文件的堆积。
为了获得更大的灵活性,用户可以使用 hoodie.clean.max.commits 配置设置来调整清理频率,允许清理进程在指定数量的提交后运行,而不是在每次提交后运行。这确保了可以根据工作负载要求以及历史记录保留和存储成本之间的预期权衡来定制清洁过程。
Hudi 提供不同的清洁政策,例如:
• 基于版本的清理:保留一定数量的最近文件版本,同时删除较旧的文件版本。
• 基于提交的清理:保留一定数量的提交(例如,最后 10 个)。
• 基于时间的清理:删除已超过指定期限(以小时为单位)的文件,确保仅保留最近的数据。
结论
优化数据湖仓一体架构中的性能对于管理不断增长的数据集和确保高效的查询执行至关重要。通过以符合查询模式的方式组织数据,减少小文件造成的开销,并利用元数据来最大限度地减少不必要的数据扫描,Apache Hudi 提供了快速、经济高效的查询。同时定期维护流程可确保清除过时的数据,防止存储膨胀。这些优化技术协同工作,确保随着数据的增长,数据架构保持可扩展性和高效性,从而能够在不影响性能的情况下满足不断变化的分析需求。