Java集合框架面试指南
文章目录
- Java集合框架面试指南
- ArrayList特点:
- LinkedList特点:
- ArrayDeque特点:
- PriorityQueue特点:
- HashMap特点:
- HashSet特点:
- LinkedHashMap特点
- LinkedHashMap经典用法
- TreeMap特点
- ConcurrentHashMap
- JDK7中的ConcurrentHashMap是怎么保证并发安全的?
- JDK7中的ConcurrentHashMap的底层原理
- JDK8中的ConcurrentHashMap是怎么保证并发安全的?
- JDK7和JDK8中的ConcurrentHashMap的不同点
人生的艰难困苦无法选择,但是可以自己无坚不摧,星光不问赶路人,时间不复有心人
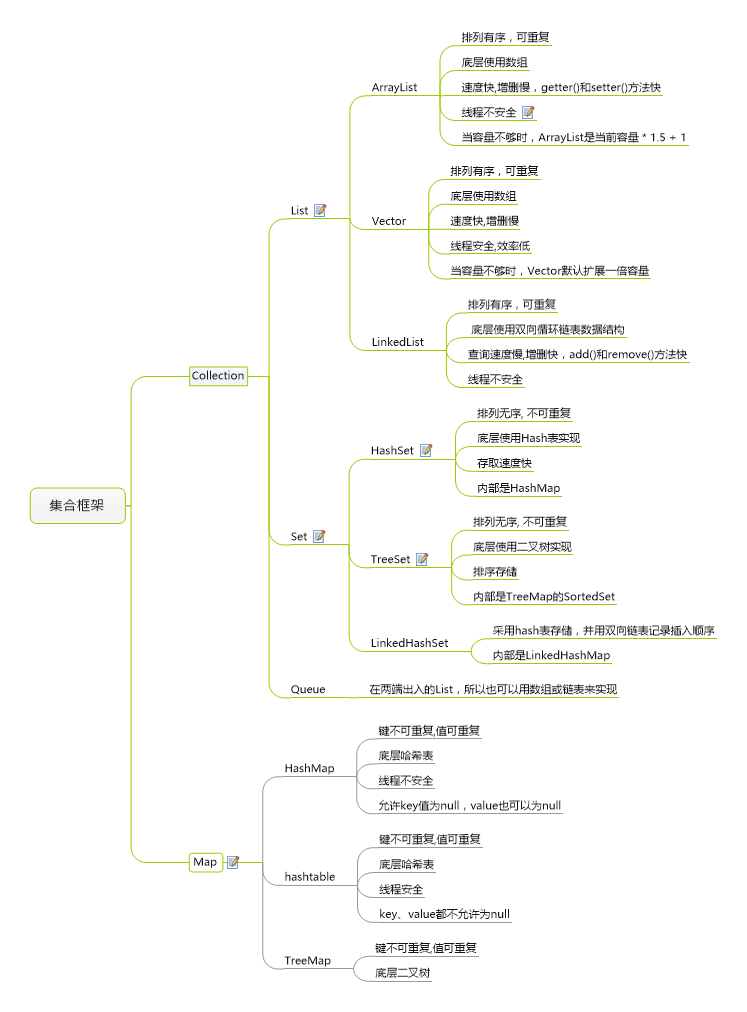
Java集合类之间的关系
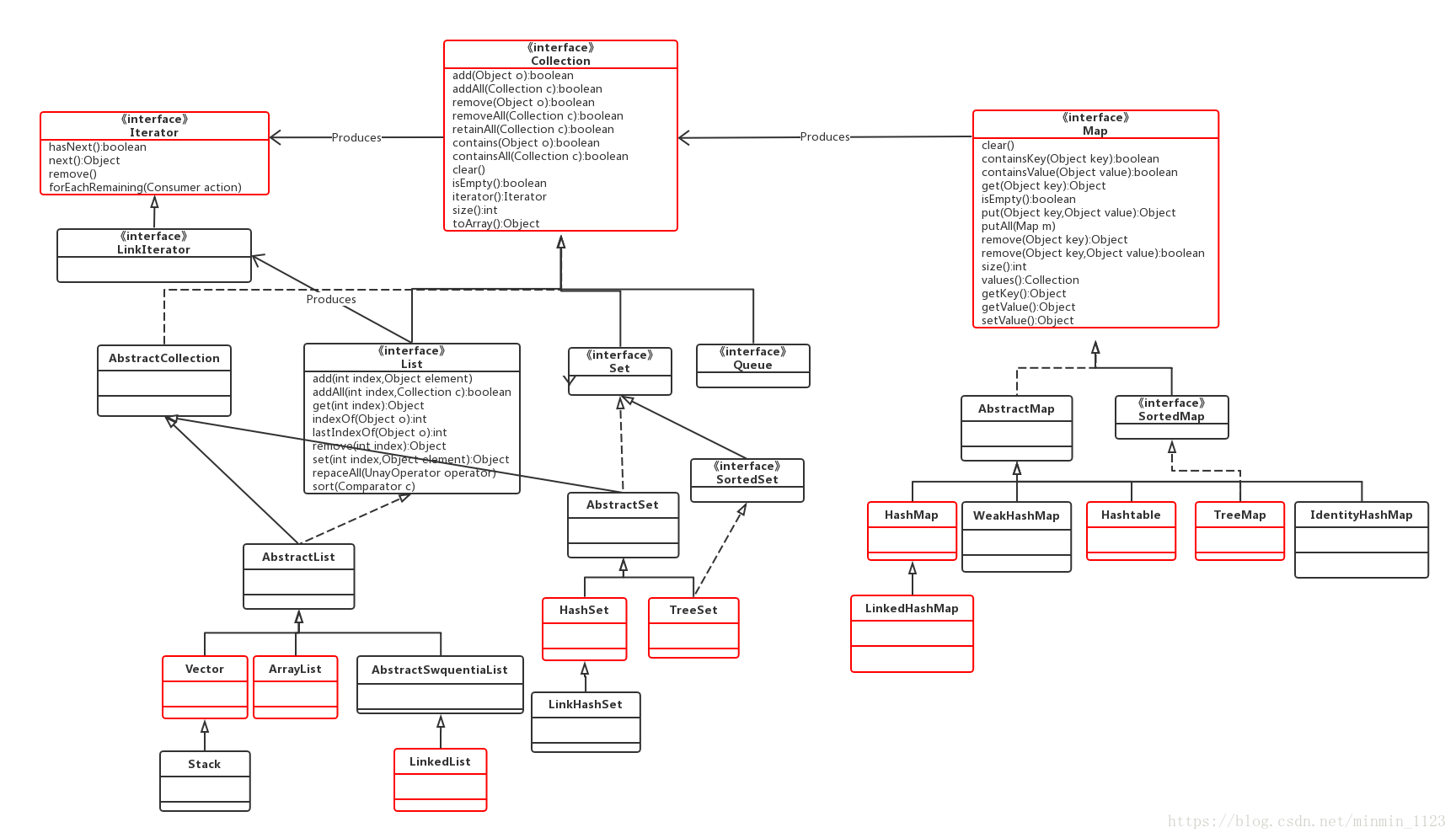
Collection接口
- 是List,Set,Queue接口的父接口
- 常用方法:添加对象add(),删除对象remove(),清空容器clear(),判断容易是否为空isEmpty()等
常见的一些集合类
ArrayList特点:
1. 底层是数组,数组里面是object对象,可以通过数组下标随机查重,是顺序容器,允许null元素
2. **非线程安全** ,建议在单线程中使用ArrayList,而在多线程中选择Vector或者CopyOnWriteArrayList
3. 是动态数组,可以实现动态增长,默认初始容量为10,每次扩容都是原来的1.5倍,数组扩容时会将老数组的元素重新拷贝到新的数组中
4. ArrayList没有push_back()方法,对应的方法是add(E e),ArrayList也没有insert()方法,对应的方法是add(int index, E e),set(int index, E element)对数组指定位置赋值。get(int index)获取指定位置的值。
5. remove()方法也有两个版本,一个是remove(int index)删除指定位置的元素,另一个是remove(Object o)删除第一个满足o.equals(elementData[index])的元素。
6. indexOf(Object o)获取元素的第一次出现的index,lastIndexOf(Object o)获取元素的最后一次出现的index
LinkedList特点:
1. 底层结构是**链表**,增删速度快
2. **非线程安全**
3. 是一个**双向**链表,也可以被当作堆栈、队列或双端队列,关于栈和队列首选ArrayDeque
4. 包含一个非常重要的内部类 Node<E>,是双向链表节点所对应的数据结构,其包括的属性有『当前节点所包含的值』、『上一个节点』、『下一个节点』
5. getFrist() 和 getLast() 获取第一个元素和获取最后一个元素
6. removeFrist() ,removeLast(),romove(e) ,remove(index) remove()方法也有两个版本,一个是删除跟指定元素相等的第一个元素remove(Object o),另一个是删除指定下标处的元素remove(int index)。
7. add() 一个是add(E e),该方法在LinkedList的末尾插入元素,因为有last指向链表末尾,在末尾插入元素的花费是常数时间。只需要简单修改几个相关引用即可;另一个是add(int index, E element),该方法是在指定下表处插入元素,需要先通过线性查找找到具体位置,然后修改相关引用完成插入操作。
8. indexOf(Object o)查找第一次出现的index, 如果找不到返回-1;
ArrayDeque特点:
1. ArrayDeque底层是通过循环数组实现的,非线程安全的,该容器不能放入null元素
2. addFirst(E e)的作用是在Deque的首端插入元素,也就是在head的前面插入元素,扩容函数doubleCapacity(),其逻辑是申请一个更大的数组(原数组的两倍),然后将原数组复制过去,addLast(E e)的作用是在Deque的尾端插入元素,也就是在tail的位置插入元素。
3. pollFirst()的作用是删除并返回Deque首端元素,也即是head位置处的元素。pollLast()的作用是删除并返回Deque尾端元素,也即是tail位置前面的那个元素。
4. peekFirst()的作用是返回但不删除Deque首端元素,也即是head位置处的元素,peekLast()的作用是返回但不删除Deque尾端元素,也即是tail位置前面的那个元素。
PriorityQueue特点:
1. 优先队列的作用是能保证每次取出的元素都是队列中权值最小的(Java的优先队列每次取最小元素,C++的优先队列每次取最大元素)。
2. <font style="color:rgb(44, 62, 80);">不</font>允许放入null元素;其通过堆实现,具体说是通过完全二叉树(complete binary tree)实现的小顶堆(任意一个非叶子节点的权值,都不大于其左右子节点的权值),**通过数组来作为PriorityQueue的底层实现。**
3. leftNo = parentNo*2+1 rightNo = parentNo*2+2 parentNo = (nodeNo-1)/2
4. PriorityQueue的peek()和element操作是常数时间,add(), offer(), 无参数的remove()以及poll()方法的时间复杂度都是log(N)。
5. add(E e)和offer(E e)的语义相同,都是向优先队列中插入元素,只是Queue接口规定二者对插入失败时的处理不同,前者在插入失败时抛出异常,后则则会返回false,新加入的元素x可能会破坏小顶堆的性质,因此需要进行调整。调整的过程为: 从k指定的位置开始,将x逐层与当前点的parent进行比较并交换,直到满足x >= queue[parent]为止。
6. element()和peek()的语义完全相同,都是获取但不删除队首元素,也就是队列中权值最小的那个元素,二者唯一的区别是当方法失败时前者抛出异常,后者返回null。根据小顶堆的性质,堆顶那个元素就是全局最小的那个;由于堆用数组表示,根据下标关系,0下标处的那个元素既是堆顶元素。**所以直接返回数组0下标处的那个元素即可。**
7. remove()和poll()方法的语义也完全相同,都是获取并删除队首元素,区别是当方法失败时前者抛出异常,后者返回null。由于删除操作会改变队列的结构,为维护小顶堆的性质,需要进行必要的调整,**从k指定的位置开始,将x逐层向下与当前点的左右孩子中较小的那个交换,直到x小于或等于左右孩子中的任何一个为止。**
HashMap特点:
1. 实现了Map、Cloneable(能被克隆)、Serializable(支持序列化)接口,**无序,**非线程安全,允许存在一个**为null的key和任意个为null的value**
2. 采用**链表和红黑树**实现,初始容量为16,填充因子默认是0.75 , 扩容时是当前容量翻倍,当链表长度大于8会树化,当树的节点小于6会进行链表化
3. get(object key) 首先通过hash() 函数得到对应的bucket的下标,然后通过key.equals(k) 方法判断是否是想要找的那个entry
4. put(K key, V value) 该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则直接覆盖,如果是树节点则调用树的插入,否则遍历链表,**尾插法**,之后判断链表长度是否大于8,大于8则直接树化
5. 数组扩容,resize() 方法用于初始化数组或数组扩容,每次扩容后,容量为原来的 2 倍,并进行数据迁移。
HashSet特点:
1. HashSet是基于HasMap实现的,**是一个没有重复元素的集合,不保证元素的顺序,而且HashSet允许使用null元素,非同步的**
2. Set只使用到了HashMap的key,所以定义一个静态的常量Object类,来充当HashMap的value
3. add(E e) 添加指定元素,clear() 移除set中所有的元素 clone() 返回HashSet实例的浅表副本,并没有复制这些元素本身 contains(Object o) 若此set包含指定元素则返回true isEmpty() set若为空则返回true iterator() set中元素的迭代器 remove(Object o) 移除指定元素 size() 返回set元素的数量
LinkedHashMap特点
1. LinkedHashMap实现了Map接口,即允许放入key为null的元素,也允许插入value为null的元素。从名字上可以看出该容器是linked list和HashMap的混合体
2. 直接继承HashMap,唯一的区别是在HashMap的基础上,采用双向链表,将所有的entry连接起来了,保证元素的迭代顺序就是entry的插入顺序
3. put(K key,V value) 1. 从table的角度看,新的entry需要插入到对应的bucket里,当有哈希冲突时,采用头插法将新的entry插入到冲突链表的头部。2. 从header的角度看,新的entry需要插入到双向链表的尾部。
4. romove()1. 从table的角度看,需要将该entry从对应的bucket里删除,如果对应的冲突链表不空,需要修改冲突链表的相应引用。2. 从header的角度来看,需要将该entry从双向链表中删除,同时修改链表中前面以及后面元素的相应引用。
LinkedHashMap经典用法
LinkedHashMap除了可以保证迭代顺序外,还有一个非常有用的用法: 可以轻松实现一个采用了LRUCache替换策略的缓存。具体说来,LinkedHashMap有一个子类方法protected boolean removeEldestEntry(Map.Entry<K,V> eldest),该方法的作用是告诉Map是否要删除“最老”的Entry,所谓最老就是当前Map中最早插入的Entry,如果该方法返回true,最老的那个元素就会被删除。在每次插入新元素的之后LinkedHashMap会自动询问removeEldestEntry()是否要删除最老的元素。这样只需要在子类中重载该方法,当元素个数超过一定数量时让removeEldestEntry()返回true,就能够实现一个固定大小的LRUCache策略的缓存。示例代码如下:
class LRUCache extends LinkedHashMap {private int cap;public LRUCache(int capacity) {super(capacity,0.75f,true);cap = capacity;}public int get(int key) {return (int) super.getOrDefault(key,-1);}public void put(int key, int value) {super.put(key,value);}@Overrideprotected boolean removeEldestEntry(Map.Entry eldest) {return size()>cap;}
}
TreeMap特点
- 是SortedMap接口的实现类
- 有序,根据key对节点进行排序
- 支持两种排序方法:自然排序和定制排序。前者所有key必须实现Comparable接口且所有key应该是一个类的对象;后者通过传入一个Comparator接口对象负责对多有key进行排序。
- 非线程安全
- 采用红黑树的数据结构
ConcurrentHashMap
JDK7中的ConcurrentHashMap是怎么保证并发安全的?
主要利用Unsafe操作+ReentrantLock+分段思想。主要使用了Unsafe操作中的:
- compareAndSwapObject: 通过cas的方式修改对象的属性2 . putOrderedObject:并发安全的给数组的某个位置赋值3 . getObjectVolatile:并发安全的获取数组某个位置的元素分段思想是为了提高ConcurrentHashMap的并发量,
分段数越高则支持的最大并发量越高,程序员可以通过concurrencyLevel参数来指定并发量ConcurrentHashMap的内部类Segment就是用来表示某一个段的。每个Segment就是一个小型的HashMap的, 当调用ConcurrentHashMap的put方法是,最终会调用到Segment的put方法, 而Segment类继承了ReentrantLock, 所以Segment自带可重入锁, 当调用到Segment的put方法时,会先利用可重入锁加锁, 加锁成功后再将待插入的key ,value插入到小型HashMap中,插入完成后解锁。
JDK7中的ConcurrentHashMap的底层原理
ConcurrentHashMap底层是由两层嵌套数组来实现的:1. ConcurrentHashMap对象中有一个属性segments, 类型为Segment[];
2 . Segment对象中有一个属性table, 类型为HashEntry[];
当调用ConcurrentHashMap的put方法时,先根据key计算出对应的Segment[]的数组下标j,确定好当前key ,value应该插入到哪个Segment对象中,如果segments[j]为空,则利用自旋锁的方式在j位置生成一个 Segment对象。然后调用Segment对象的put方法。
Segment对象的put方法会先加锁, 然后也根据key计算出对应的HashEntry[]的数组下标i,然后将 key ,value封装为HashEntry对象放入该位置, 此过程和JDK7的HashMap的put方法一样, 然后解锁。 在加锁的过程中逻辑比较复杂, 先通过自旋加锁, 如果超过一 定次数就会直接阻塞等等加锁。
JDK8中的ConcurrentHashMap是怎么保证并发安全的?
主要利用Unsafe操作+synchronized关键字。Unsafe操作的使用仍然和JDK7中的类似,主要负责并发安全的修改对象的属性或数组某个位置的值。
synchronized主要负责在需要操作某个位置时进行加锁 (该位置不为空) , 比如向某个位置的链表进行插入结点,向某个位置的红黑树插入结点。JDK8中其实仍然有分段锁的思想,只不过JDK7中段数是可以控制的,而JDK8中是数组的每一个位置都有 一把锁。
当向ConcurrentHashMap中put一 个key ,value时,
1.首先根据key计算对应的数组下标i, 如果该位置没有元素, 则通过自旋的方法去向该位置赋值。
2.如果该位置有元素, 则synchronized会加锁
3.加锁成功之后, 在判断该元素的类型a. 如果是链表节点则进行添加节点到链表中b. 如果是红黑树则添加节点到红黑树
4.添加成功后,判断是否需要进行树化
5.addCount,这个方法的意思是ConcurrentHashMap的元素个数加1, 但是这个操作也是需要并发安全的,并且元素个数加1成功后,会继续判断是否要进行扩容, 如果需要,则会进行扩容,所以这个方法很重要。
6 . 同时一个线程在put时如果发现当前ConcurrentHashMap正在进行扩容则会去帮助扩容。
JDK7和JDK8中的ConcurrentHashMap的不同点
这两个的不同点太多了 . . ., 既包括了HashMap中的不同点, 也有其他不同点, 比如:
- JDK8中没有分段锁了, 而是使用synchronized来进行控制
2 . JDK8中的扩容性能更高, 支持多线程同时扩容, 实际上JDK7中也支持多线程扩容, 因为JDK7中的扩 容是针对每个Segment的, 所以也可能多线程扩容, 但是性能没有JDK8高, 因为JDK8中对于任意一个线程都可以去帮助扩容
3 . JDK8中的元素个数统计的实现也不一 样了, JDK8中增加了CounterCell来帮助计数, 而JDK7中没有, JDK7中是put的时候每个Segment内部计数, 统计的时候是遍历每个Segment对象加锁统计。
推荐阅读:Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析
整理一下: