前端单元测试实战:如何开始?
实战:如何开始单元测试
1.安装依赖
npm install --save-dev jest
2.简单的例子
首先,创建一个 sum.js 文件
./sum.js
function sum(a, b) {return a + b;
}module.exports = sum;
创建一个名为 sum.test.js 的文件,这个文件包含了实际测试内容:
./test/sum.test.js
const sum = require('../sum');test('adds 1 + 2 to equal 3', () => {expect(sum(1, 2)).toBe(3);
});
将下面的配置部分添加到你的 package.json 里面
{"scripts": {"test": "jest"},
}
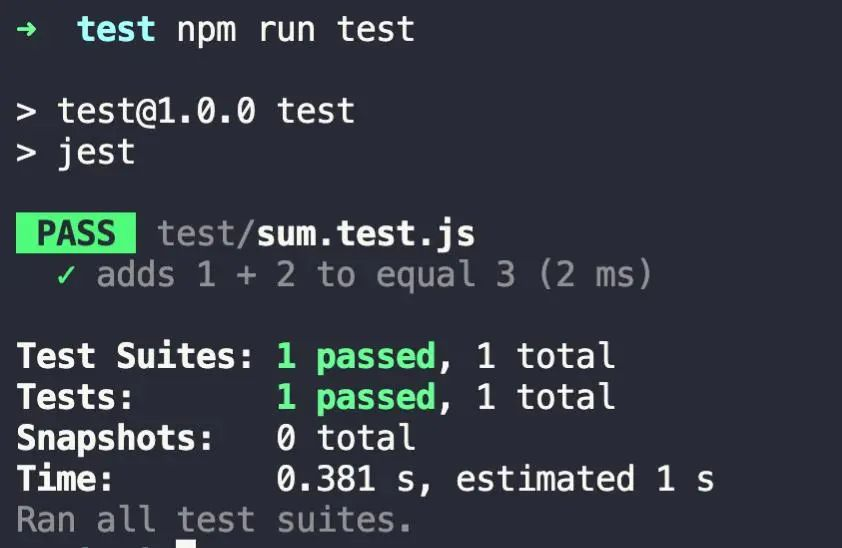
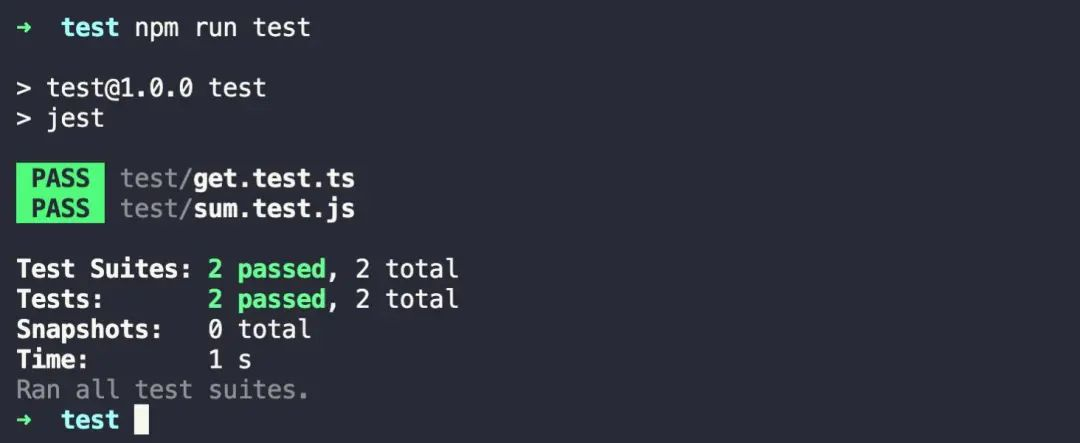
运行 npm run test ,jest 将打印下面这个消息,如下图所示:
3.不支持部分 ES6 语法
nodejs 采用的是 CommonJS 的模块化规范,使用 require 引入模块;而 import 是 ES6 的模块化规范关键字。想要使用 import,必须引入 babel 转义支持,通过 babel 进行编译,使其变成 node 的模块化代码
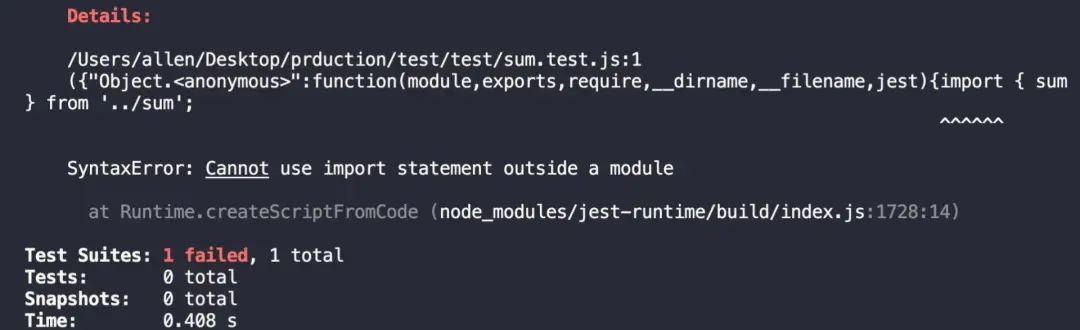
如以下文件改写成 ES6 写法后,运行 npm run test将会报错
./sum.js
export function sum(a, b) {return a + b;
}
./test/sum.test.js
import { sum } from '../sum';test('adds 1 + 2 to equal 3', () => {expect(sum(1, 2)).toBe(3);
});
报错
为了能使用这些新特性,我们就需要使用 babel 把 ES6 转成 ES5 语法
解决办法
安装依赖
npm install --save-dev @babel/core @babel/preset-env
根目录加入.babelrc
{ "presets": ["@babel/preset-env"] }
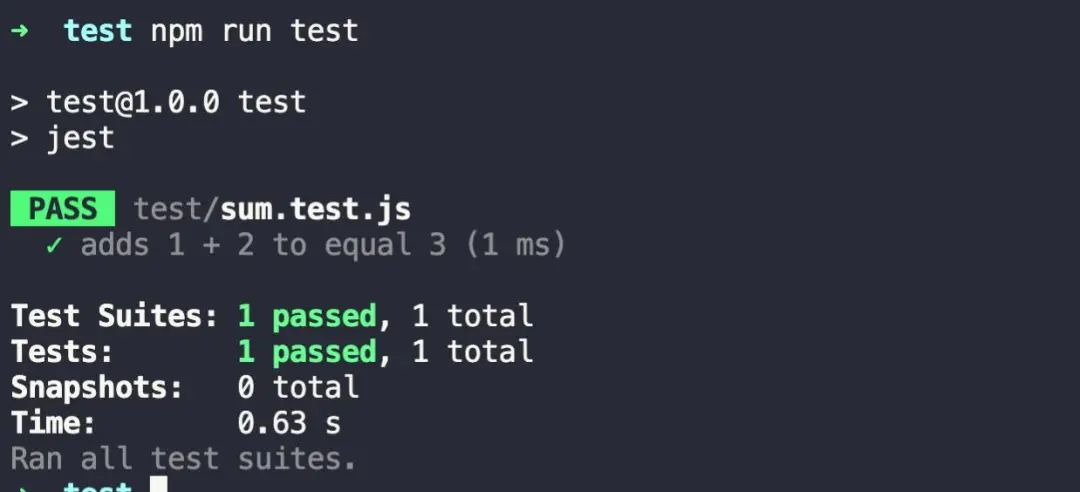
再次运行 npm run test ,问题解决
原理
jest 运行时内部先执行( jest-babel ),检测是否安装 babel-core,然后取 .babelrc 中的配置运行测试之前结合 babel 先把测试用例代码转换一遍然后再进行测试
4.测试 ts 文件
jest 需要借助 .babelrc 去解析 TypeScript 文件再进行测试
安装依赖
npm install --save-dev @babel/preset-typescript
**改写 **.babelrc
{ "presets": ["@babel/preset-env", "@babel/preset-typescript"] }
为了解决编辑器对 jest 断言方法的类型报错,如 test、expect 的报错,你还需要安装
npm install --save-dev @types/jest
./get.ts
/*** 访问嵌套对象,避免代码中出现类似 user && user.personalInfo ? user.personalInfo.name : null 的代码*/
export function get<T>(object: any, path: Array<number | string>, defaultValue?: T) : T {const result = path.reduce((obj, key) => obj !== undefined ? obj[key] : undefined, object);return result !== undefined ? result : defaultValue;
}
./test/get.test.ts
import { get } from './get';test('测试嵌套对象存在的可枚举属性 line1', () => {expect(get({id: 101,email: 'jack@dev.com',personalInfo: {name: 'Jack',address: {line1: 'westwish st',line2: 'washmasher',city: 'wallas',state: 'WX'}}}, ['personalInfo', 'address', 'line1'])).toBe('westwish st');
});
运行 npm run test
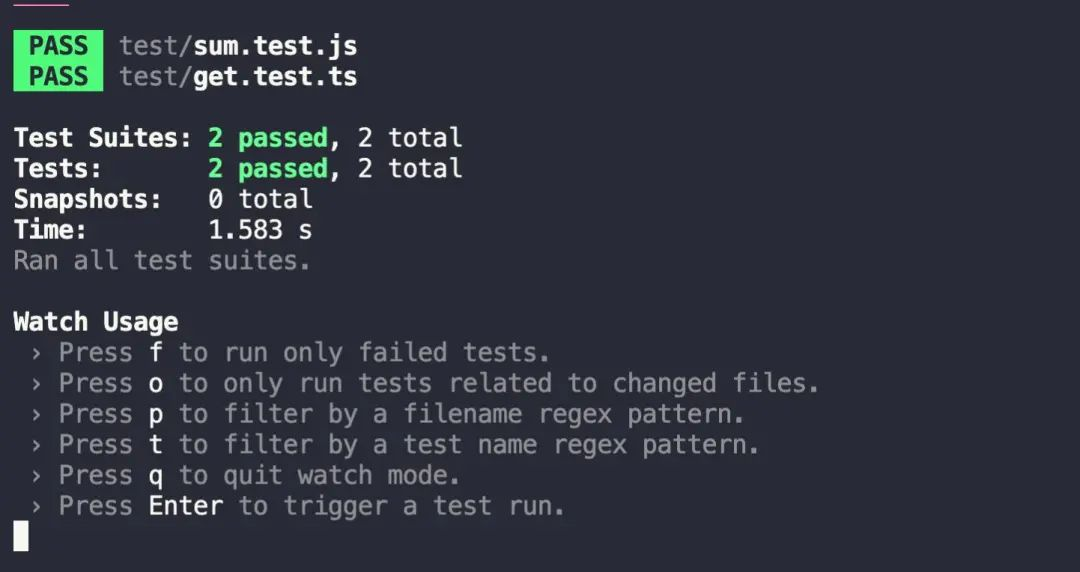
5.持续监听
为了提高效率,可以通过加启动参数的方式让 jest 持续监听文件的修改,而不需要每次修改完再重新执行测试用例
改写 package.json
"scripts": { "test": "jest --watchAll" },
效果
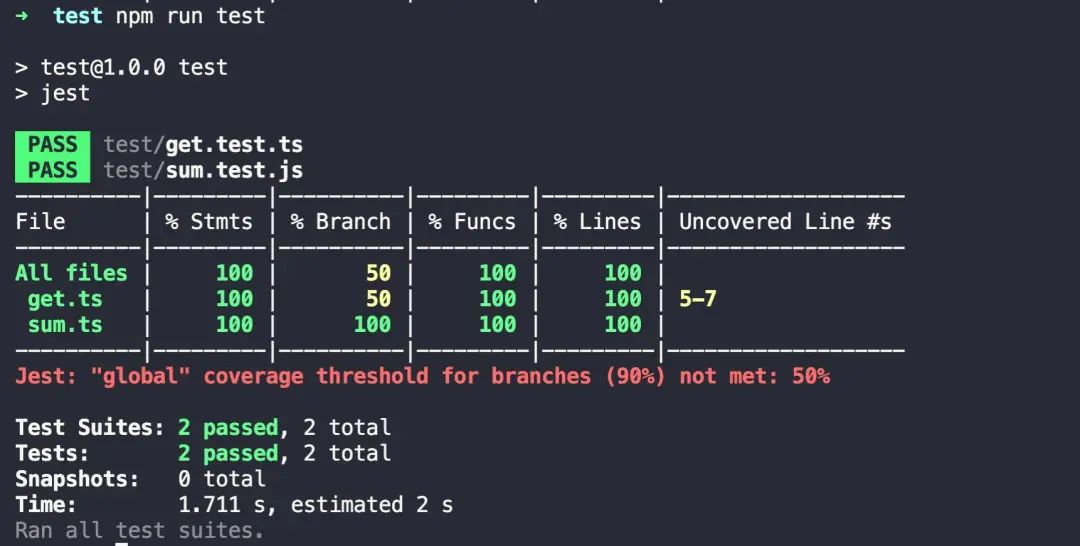
5.生成测试覆盖率报告
什么是单元测试覆盖率?
单元测试覆盖率是一种软件测试的度量指标,指在所有功能代码中,完成了单元测试的代码所占的比例。有很多自动化测试框架工具可以提供这一统计数据,其中最基础的计算方式为:
单元测试覆盖率 = 被测代码行数 / 参测代码总行数 * 100%
如何生成?
加入 jest.config.js 文件
module.exports = {// 是否显示覆盖率报告collectCoverage: true,// 告诉 jest 哪些文件需要经过单元测试测试collectCoverageFrom: ['get.ts', 'sum.ts', 'src/utils/**/*'],
}
再次运行效果
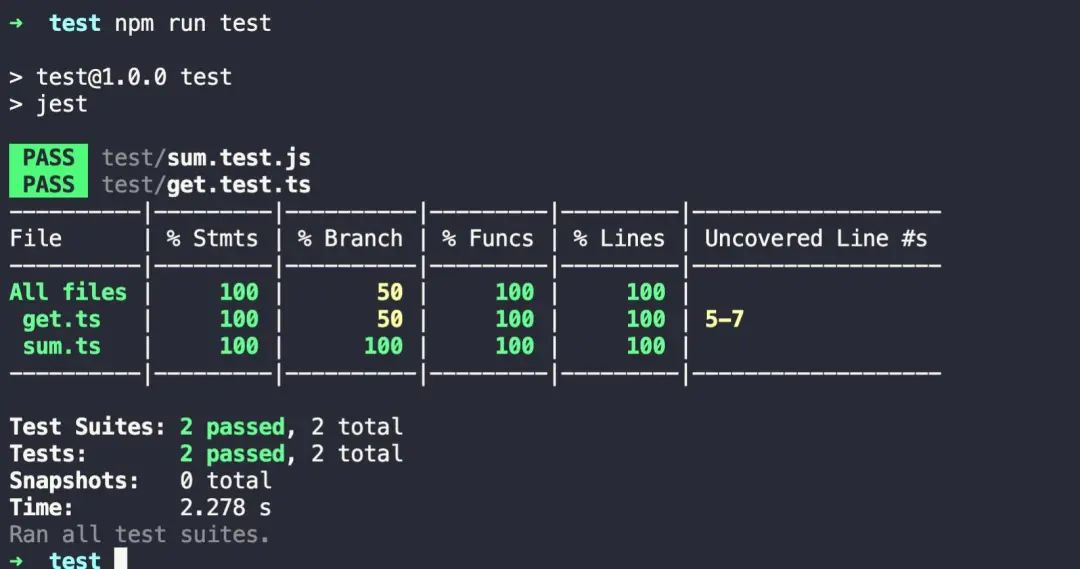
参数解读
| 参数名 | 含义 | 说明 |
|---|---|---|
| % stmts | 语句覆盖率 | 是不是每个语句都执行了? |
| % Branch | 分支覆盖率 | 是不是每个 if 代码块都执行了? |
| % Funcs | 函数覆盖率 | 是不是每个函数都调用了? |
| % Lines | 行覆盖率 | 是不是每一行都执行了? |
设置单元测试覆盖率阀值
个人认为既然在项目中集成了单元测试,那么非常有必要关注单元测试的质量,而覆盖率则一定程度上客观的反映了单测的质量,同时我们还可以通过设置单元测试阀值的方式提示用户是否达到了预期质量。
jest.config.js 文件
module.exports = {collectCoverage: true, // 是否显示覆盖率报告collectCoverageFrom: ['get.ts', 'sum.ts', 'src/utils/**/*'], // 告诉 jest 哪些文件需要经过单元测试测试coverageThreshold: {global: {statements: 90, // 保证每个语句都执行了functions: 90, // 保证每个函数都调用了branches: 90, // 保证每个 if 等分支代码都执行了},},
上述阀值要求我们的测试用例足够充分,如果我们的用例没有足够充分,则下面的报错将会帮助你去完善