leetcode0145. 二叉树的后序遍历-easy
1 题目:二叉树的后序遍历
官方标定难度:易
给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 。
示例 1:
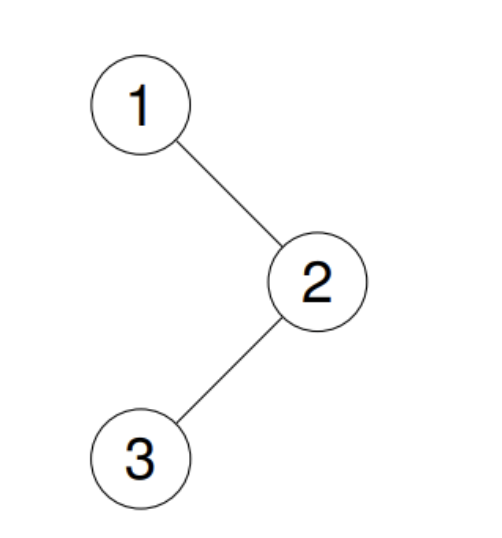
输入:root = [1,null,2,3]
输出:[3,2,1]
解释:
示例 2:
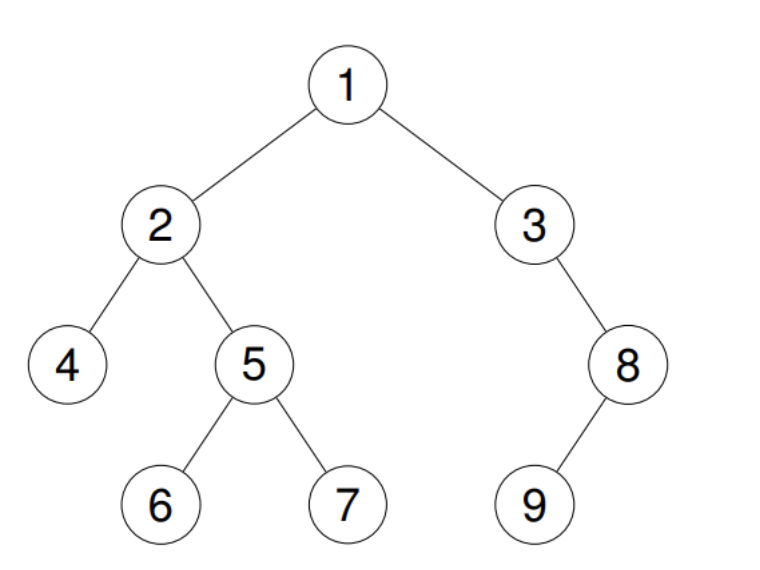
输入:root = [1,2,3,4,5,null,8,null,null,6,7,9]
输出:[4,6,7,5,2,9,8,3,1]
解释:
示例 3:
输入:root = []
输出:[]
示例 4:
输入:root = [1]
输出:[1]
提示:
树中节点的数目在范围 [0, 100] 内
-100 <= Node.val <= 100
进阶:递归算法很简单,你可以通过迭代算法完成吗?
2 solution
递归输出很简单,按照先左子树,再右子树,再根节点的顺序就行
代码
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:
void postorderTraversal(TreeNode *root, vector<int> &result){if(!root) return;postorderTraversal(root->left, result);postorderTraversal(root->right, result);result.push_back(root->val);
}vector<int> postorderTraversal(TreeNode *root) {vector<int> result;postorderTraversal(root, result);return result;
}
};
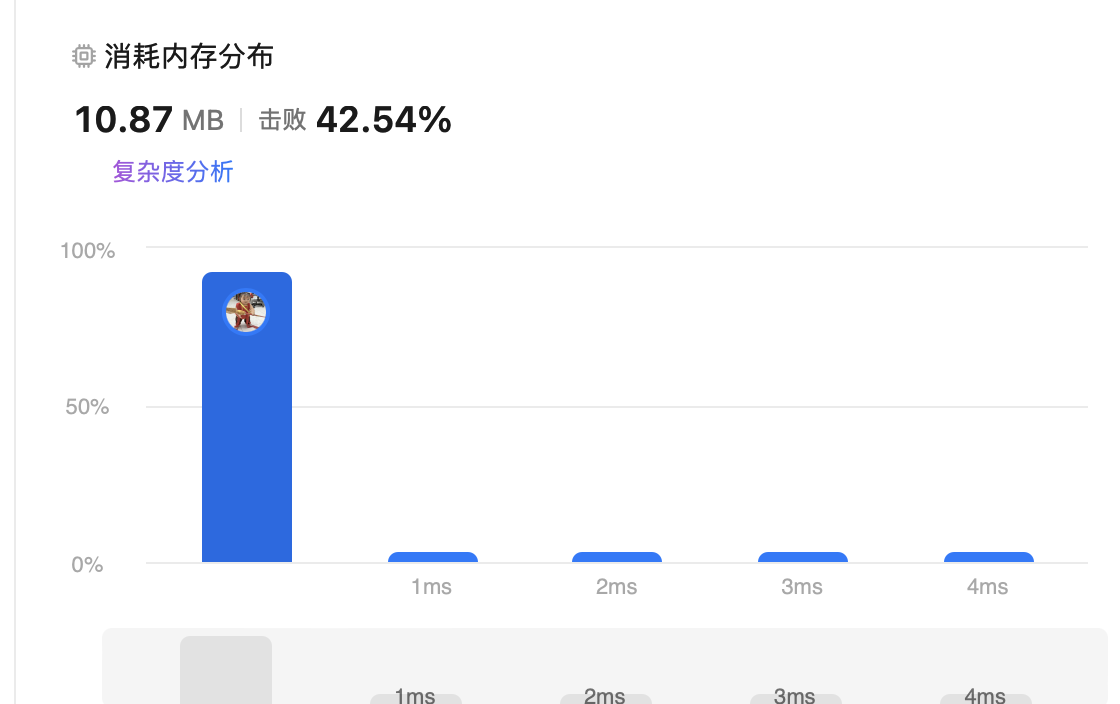
结果
3 进阶
借助栈可以进行深度优先遍历,先将逆序保存下来,然后再反转过来
代码
class Solution {
public:vector<int> postorderTraversal(TreeNode *root) {if(!root) return {};vector<int> result;stack<TreeNode *> s;s.push(root);while (!s.empty()){auto x = s.top();result.push_back(x->val);s.pop();if(x->left) s.push(x->left);if(x->right) s.push(x->right);}std::reverse(result.begin(), result.end());return result;}
};
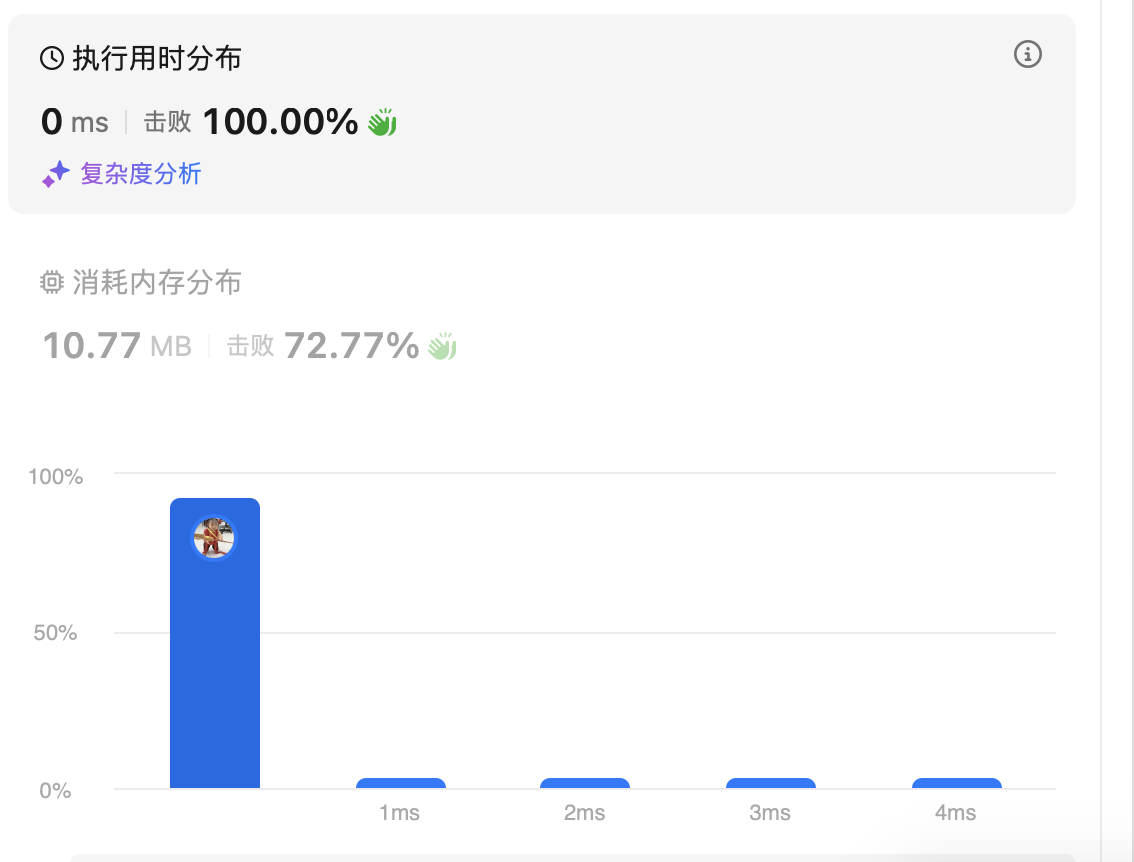
结果