强化学习(RL)全新里程碑!RL之父Richard Stutton团队,提出一种奖励聚中思想,能大幅增强所有RL算法!也即:通过从观察到的奖励中减去平均奖励,来提高连续强化学习问题中折扣方法的性能!
除此以外,在Science、NeurIps等顶会顶刊上,也都涌现了不少研究。像是性能飙升60%的CMTA;吞吐量提升10倍的SACD-A……
其热度可见一斑!主要在于,强化学习在大模型等的发展中,无可替代,更是实现通用人工智能(AGI)的关键路径之一;且在游戏AI、自动驾驶、机器人控制等领域,都有着广泛应用!但也面临样本获取成本高、可解释性差、学习过程慢等问题,对其的改进成为了迫切需求。
目前热门方向主要有:与其他技术结合,像是Attention、Transformer、LLM等;以及对其自身修改,比如层次化RL等。为方便大家研究的进行,我给大家梳理了27种创新思路和源码,一起来看!
强化学习+注意力机制
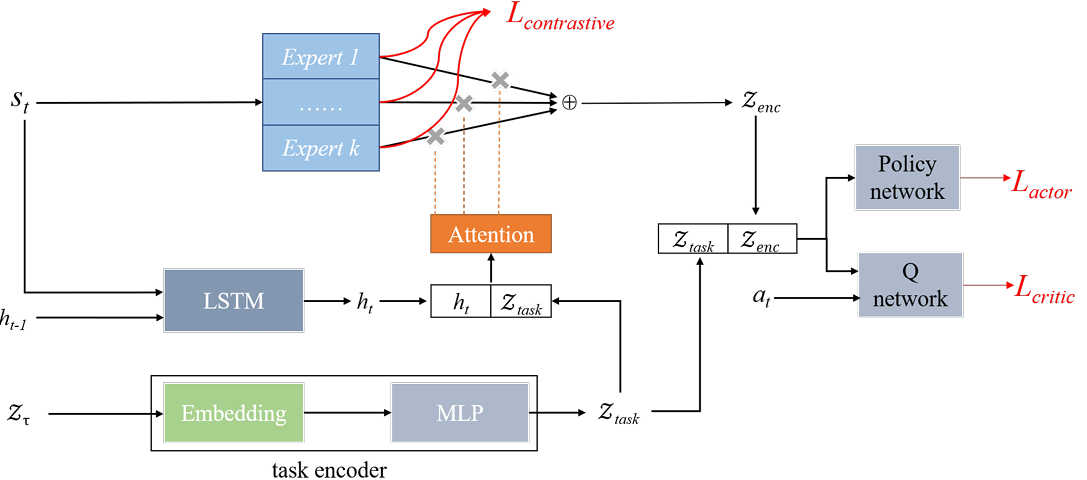
Contrastive Modules with Temporal Attention for Multi-Task Reinforcement Learning
内容:论文提出了一种名为Contrastive Modules with Temporal Attention (CMTA)的新方法,用于解决多任务强化学习中的负迁移问题。CMTA通过对比学习使模块彼此不同,并使用时间注意力在比任务级别更细的粒度上组合共享模块,从而减轻了任务内的负迁移,并提高了多任务强化学习的泛化能力和性能。实验结果表明,CMTA在Meta-World基准测试中的表现优于单独学习每个任务,并且在基线上取得了显著的性能提升。
强化学习+Transformer
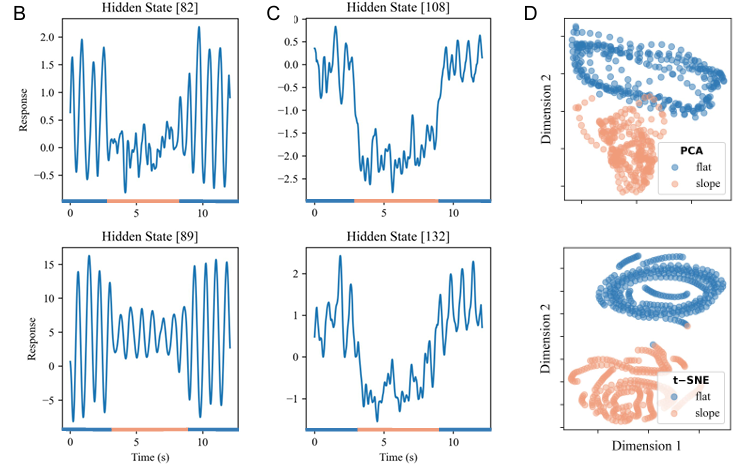
[Science 子刊 ]Real-World Humanoid Locomotion with Reinforcement Learning
内容:论文介绍了一种基于强化学习的全学习型方法,用于实现双足机器人在现实世界中的行走。研究者们提出了一个因果变换器(causal transformer)控制器,该控制器接收机器人的本体感受观察和动作的历史作为输入,并预测下一个动作。通过在模拟环境中大规模无模型强化学习训练,并在现实世界中零样本部署,该控制器能够适应不同的户外地形,对抗外部干扰,并且能够根据上下文进行适应性调整。
强化学习+LLM
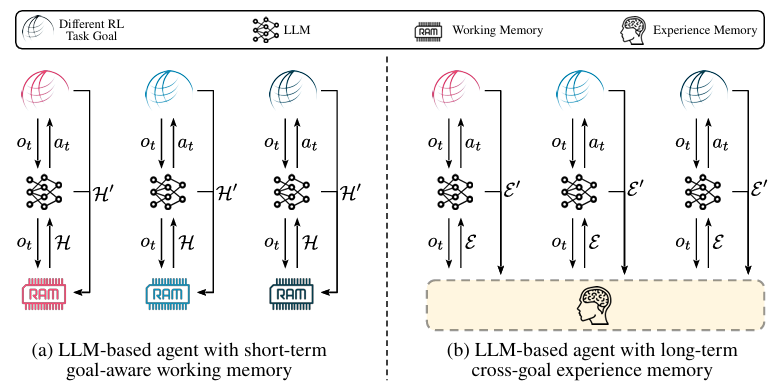
Large Language Models Are Semi-Parametric Reinforcement Learning Agents
内容:论文提出了一个名为REMEMBERER的新型大型语言模型(LLM)基础智能体框架,该框架通过为LLM配备长期经验记忆,使其能够在不同的任务目标中利用过去的经验,从而在复杂决策过程中优化策略。REMEMBERER引入了一种名为经验记忆强化学习(RLEM)的方法来更新记忆,使得系统能够在不微调LLM参数的情况下,通过成功和失败的经验学习并提升能力。
奖励机制改进
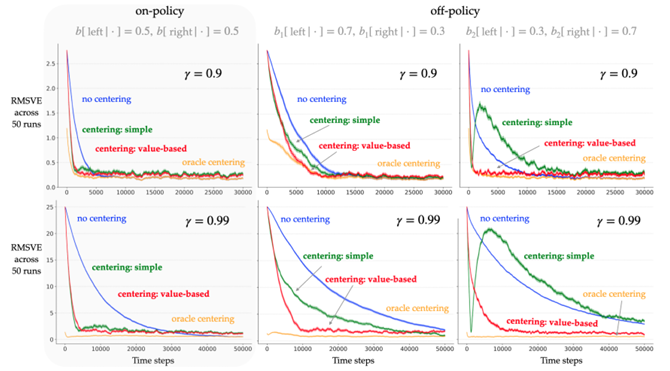
Reward Centering
内容:论文提出了一种名为“奖励中心化”(Reward Centering)的方法,用于解决连续强化学习问题。该方法通过减去奖励的实证平均值来调整奖励,从而显著提高了使用折扣方法的性能,尤其是在接近1的折扣因子下。此外,该方法还增强了算法对于奖励常数偏移的鲁棒性。论文展示了奖励中心化如何通过简化值函数逼近器的负担,使其专注于状态和动作之间的相对差异,从而提高学习效率,并讨论了这一概念的理论基础及其在不同强化学习算法中的应用潜力。
多智能体强化学习
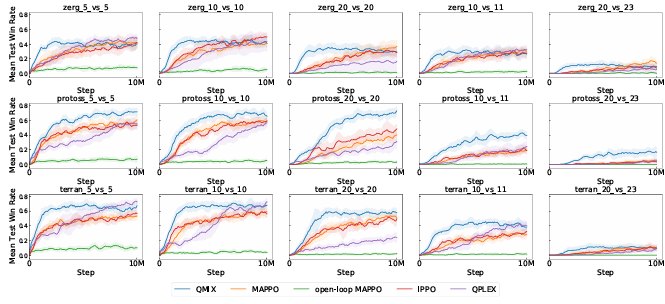
SMACv2: AnImproved Benchmark for Cooperative Multi-Agent Reinforcement Learning
内容:文章一个改进版的基准测试,用于评估合作型多智能体强化学习(MARL)算法的性能。SMACv2在原有的StarCraft Multi-Agent Challenge(SMAC)基础上进行了扩展和改进,增加了新的环境、任务和评估指标,旨在提供一个更加全面和挑战性的测试平台,以便更好地理解和比较不同MARL算法在复杂、动态的多人合作场景中的表现。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【27RL】获取完整论文
👇
![[含文档+PPT+源码等]精品基于springboot实现的原生Andriod广告播放系统](https://img-blog.csdnimg.cn/img_convert/9712d05a587aeaa0c4375e907275109d.jpeg)















![[含文档+PPT+源码等]精品基于Nodejs实现的物流管理系统的设计与实现](https://img-blog.csdnimg.cn/img_convert/6ce4ae5fc4086b147a6c43c0b41a752b.png)
