数据集介绍
【数据集】口罩佩戴检测数据集 1971 张,目标检测,包含YOLO/VOC格式标注。
数据集中包含1种分类:{'0': 'face_mask'},佩戴口罩。
数据集来自国内外图片网站和视频截图。
检测场景为城市街道、医院、商场、机场、车站、办公大楼、施工地等人员密集的场所人员口罩佩戴检测,可用于智慧城市、智慧园区、智慧医疗等,服务于保护人员安全、疫情防控工作。
数据集当中含有626张负样本数据,内容是不戴口罩的人脸图像数据,方便模型进行区分识别。






负样本:

一、数据概述
口罩佩戴检测的重要性
在当前的公共卫生和安全领域,口罩佩戴识别技术具有广泛的应用需求。随着全球疫情的持续影响,口罩已成为日常生活中不可或缺的防护用品。在公共场所(如机场、车站、商场等)、医疗保健环境以及执法和安全场景中,准确识别和监测口罩佩戴情况对于保障公众健康和安全具有重要意义。因此,开发一种高效、准确的口罩佩戴识别算法显得尤为重要。
实现原理
基于YOLO的口罩佩戴识别算法利用卷积神经网络提取图像中的特征,并通过单次前向传播预测图像中是否存在口罩以及佩戴方式是否正确。算法首先将图像划分为网格单元,然后为每个网格单元分配多个锚框,通过预测每个锚框的置信度和偏移量来确定图像中是否存在口罩以及其位置。
基于YOLO的口罩佩戴识别算法
实现口罩佩戴识别,数据集包含佩戴口罩和不佩戴口罩人员的图像数据集。数据集包含足够的样本以覆盖不同的面部特征、口罩类型以及佩戴方式。然后,使用YOLO算法对数据集进行训练,以学习口罩佩戴的特征和模式。
该数据集含有1971张图片,包含Pascal VOC XML格式和YOLO TXT格式,用于训练和测试城市街道、医院、商场、机场、车站、办公大楼、施工地等人员密集的场所人员口罩佩戴检测。
图片格式为jpg格式,标注格式分别为:
YOLO:txt
VOC:xml
数据集均为手工标注,保证标注精确度。
二、数据集文件结构





face_mask/
——Annotations/
——images/
——labels/
——data.yaml
- Annotations文件夹为Pascal VOC格式的XML文件 ;
- images文件夹为jpg格式的数据样本;
- labels文件夹是YOLO格式的TXT文件;
- data.yaml是数据集配置文件,包含口罩检测的目标分类和加载路径。
三、数据集适用范围
- 目标检测场景
- yolo训练模型或其他模型
- 城市街道、医院、商场、机场、车站、办公大楼、施工地等人员密集的场所人员口罩佩戴检测
- 智慧城市、智慧园区、智慧医疗等,服务于保护人员安全、疫情防控工作
四、数据集标注结果






1、数据集内容
- 多角度场景:包含人脸自拍视角、监控视角等;
- 标注内容:names: ['face_mask'],总计1个分类;
- 负样本:数据集当中含有626张负样本数据,内容是不戴口罩的人脸图像数据,方便模型进行区分识别;
- 图片总量:1971张图片数据;
- 标注类型:含有Pascal VOC XML格式和yolo TXT格式;
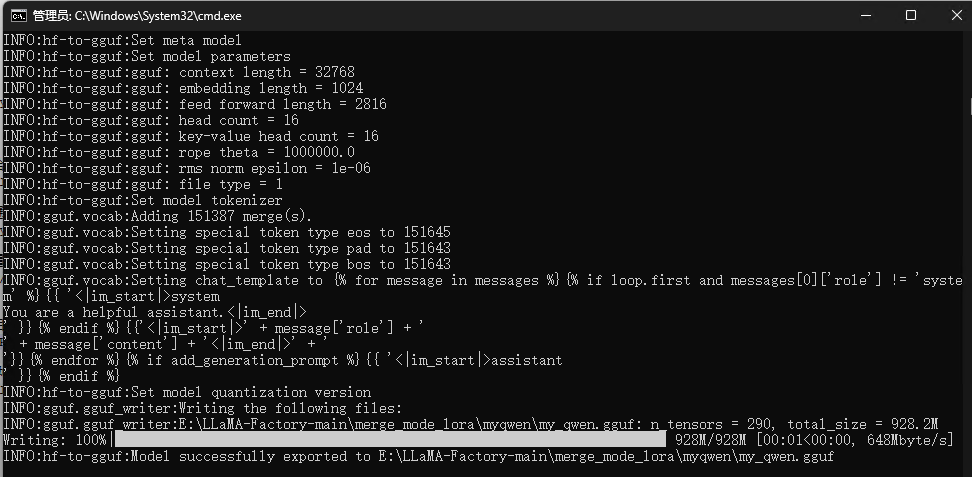
五、训练过程
1、导入训练数据
下载YOLOv8项目压缩包,解压在任意本地workspace文件夹中。
下载YOLOv8预训练模型,导入到ultralytics-main项目根目录下。

在ultralytics-main项目根目录下,创建data文件夹,并在data文件夹下创建子文件夹:Annotations、images、imageSets、labels,其中,将pascal VOC格式的XML文件手动导入到Annotations文件夹中,将JPG格式的图像数据导入到images文件夹中,imageSets和labels两个文件夹不导入数据。
data目录结构如下:
data/
——Annotations/ //存放xml文件
——images/ //存放jpg图像
——imageSets/
——labels/
整体项目结构如下所示:

2、数据分割
首先在ultralytics-main目录下创建一个split_train_val.py文件,运行文件之后会在imageSets文件夹下将数据集划分为训练集train.txt、验证集val.txt、测试集test.txt,里面存放的就是用于训练、验证、测试的图片名称。
import os
import randomtrainval_percent = 0.9
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')for i in list:name = total_xml[i][:-4] + '\n'if i in trainval:ftrainval.write(name)if i in train:ftrain.write(name)else:fval.write(name)else:ftest.write(name)ftrainval.close()
ftrain.close()
fval.close()
ftest.close()3、数据集格式化处理
这段代码是用于处理图像标注数据,将其从XML格式(通常用于Pascal VOC数据集)转换为YOLO格式。
convert_annotation函数
-
这个函数读取一个图像的XML标注文件,将其转换为YOLO格式的文本文件。
-
它打开XML文件,解析树结构,提取图像的宽度和高度。
-
然后,它遍历每个目标对象(
object),检查其类别是否在classes列表中,并忽略标注为困难(difficult)的对象。 -
对于每个有效的对象,它提取边界框坐标,进行必要的越界修正,然后调用
convert函数将坐标转换为YOLO格式。 -
最后,它将类别ID和归一化后的边界框坐标写入一个新的文本文件。
import xml.etree.ElementTree as ET
import os
from os import getcwdsets = ['train', 'val', 'test']
classes = ['face_mask'] # 根据标签名称填写类别
abs_path = os.getcwd()
print(abs_path)def convert(size, box):dw = 1. / (size[0])dh = 1. / (size[1])x = (box[0] + box[1]) / 2.0 - 1y = (box[2] + box[3]) / 2.0 - 1w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn x, y, w, hdef convert_annotation(image_id):in_file = open('data/Annotations/%s.xml' % (image_id), encoding='UTF-8')out_file = open('data/labels/%s.txt' % (image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text),float(xmlbox.find('xmax').text),float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))b1, b2, b3, b4 = b# 标注越界修正if b2 > w:b2 = wif b4 > h:b4 = hb = (b1, b2, b3, b4)bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')wd = getcwd()
for image_set in sets:if not os.path.exists('data/labels/'):os.makedirs('data/labels/')image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()list_file = open('data/%s.txt' % (image_set), 'w')for image_id in image_ids:list_file.write(abs_path + '/data/images/%s.jpg\n' % (image_id))convert_annotation(image_id)list_file.close()4、修改数据集配置文件
train: ./images/train/
val: ./images/valid/# number of classes
nc: 1# class names
names: ['face_mask']5、执行命令
执行train.py
model = YOLO('yolov8s.pt')
results = model.train(data='data.yaml', epochs=200, imgsz=640, batch=16, workers=0)也可以在终端执行下述命令:
yolo train data=data.yaml model=yolov8s.pt epochs=200 imgsz=640 batch=16 workers=0 device=06、模型预测
你可以选择新建predict.py预测脚本文件,输入视频流或者图像进行预测。
代码如下:
import cv2
from ultralytics import YOLO# Load the YOLOv8 model
model = YOLO("./best.pt") # 自定义预测模型加载路径# Open the video file
video_path = "./demo.mp4" # 自定义预测视频路径
cap = cv2.VideoCapture(video_path) # Get the video properties
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)# Define the codec and create VideoWriter object
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # Be sure to use lower case
out = cv2.VideoWriter('./outputs.mp4', fourcc, fps, (frame_width, frame_height)) # 自定义输出视频路径# Loop through the video frames
while cap.isOpened():# Read a frame from the videosuccess, frame = cap.read()if success:# Run YOLOv8 inference on the frame# results = model(frame)results = model.predict(source=frame, save=True, imgsz=640, conf=0.5)results[0].names[0] = "道路积水"# Visualize the results on the frameannotated_frame = results[0].plot()# Write the annotated frame to the output fileout.write(annotated_frame)# Display the annotated frame (optional)cv2.imshow("YOLOv8 Inference", annotated_frame)# Break the loop if 'q' is pressedif cv2.waitKey(1) & 0xFF == ord("q"):breakelse:# Break the loop if the end of the video is reachedbreak# Release the video capture and writer objects
cap.release()
out.release()
cv2.destroyAllWindows()也可以直接在命令行窗口或者Annoconda终端输入以下命令进行模型预测:
yolo predict model="best.pt" source='demo.jpg'六、获取数据集
戳我头像获取数据,或者主页私聊博主哈~
基于QT的目标检测可视化界面
一、环境配置
# 安装torch环境
pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装PySide6依赖项
pip install PySide6 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装opencv-python依赖项
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple二、使用说明

界面功能介绍:
- 原视频/图片区:上半部分左边区域为原视频/图片展示区;
- 检测区:上半部分右边区域为检测结果输出展示区;
- 文本框:打印输出操作日志,其中告警以json格式输出,包含标签框的坐标,标签名称等;
- 加载模型:下拉框绑定本地文件路径,按钮加载路径下的模型文件;
- 置信度阈值:自定义检测区的置信度阈值,可以通过滑动条的方式设置;
- 文件上传:选择目标文件,包含JPG格式和MP4格式;
- 开始检测:执行检测程序;
- 停止:终止检测程序;
三、预测效果展示
1、图片检测

切换置信度再次执行:

上图左下区域可以看到json格式的告警信息,用于反馈实际作业中的管理系统,为管理员提供道路养护决策 。
2、视频检测

3、日志文本框

四、前端代码
class MyWindow(QtWidgets.QMainWindow):def __init__(self):super().__init__()self.init_gui()self.model = Noneself.timer = QtCore.QTimer()self.timer1 = QtCore.QTimer()self.cap = Noneself.video = Noneself.file_path = Noneself.base_name = Noneself.timer1.timeout.connect(self.video_show)def init_gui(self):self.folder_path = "model_file" # 自定义修改:设置文件夹路径self.setFixedSize(1300, 650)self.setWindowTitle('目标检测') # 自定义修改:设置窗口名称self.setWindowIcon(QIcon("111.jpg")) # 自定义修改:设置窗口图标central_widget = QtWidgets.QWidget(self)self.setCentralWidget(central_widget)main_layout = QtWidgets.QVBoxLayout(central_widget)# 界面上半部分: 视频框topLayout = QtWidgets.QHBoxLayout()self.oriVideoLabel = QtWidgets.QLabel(self)# 界面下半部分: 输出框 和 按钮groupBox = QtWidgets.QGroupBox(self)groupBox.setStyleSheet('QGroupBox {border: 0px solid #D7E2F9;}')bottomLayout = QtWidgets.QHBoxLayout(groupBox)main_layout.addWidget(groupBox)btnLayout = QtWidgets.QHBoxLayout()btn1Layout = QtWidgets.QVBoxLayout()btn2Layout = QtWidgets.QVBoxLayout()btn3Layout = QtWidgets.QVBoxLayout()# 创建日志打印文本框self.outputField = QtWidgets.QTextBrowser()self.outputField.setFixedSize(530, 180)self.outputField.setStyleSheet('font-size: 13px; font-family: "Microsoft YaHei"; background-color: #f0f0f0; border: 2px solid #ccc; border-radius: 10px;')self.detectlabel = QtWidgets.QLabel(self)self.oriVideoLabel.setFixedSize(530, 400)self.detectlabel.setFixedSize(530, 400)self.oriVideoLabel.setStyleSheet('border: 2px solid #ccc; border-radius: 10px; margin-top:75px;')self.detectlabel.setStyleSheet('border: 2px solid #ccc; border-radius: 10px; margin-top: 75px;')topLayout.addWidget(self.oriVideoLabel)topLayout.addWidget(self.detectlabel)main_layout.addLayout(topLayout)五、代码获取
YOLO可视化界面
戳我头像获取数据,或者主页私聊博主哈~
注:以上均为原创内容,转载请私聊!!!



![[Docker#1] 专栏前言 | 亿级高并发架构演进之路](https://img-blog.csdnimg.cn/img_convert/0faf4618eb9e17d6072224bb282eb0fb.jpeg)