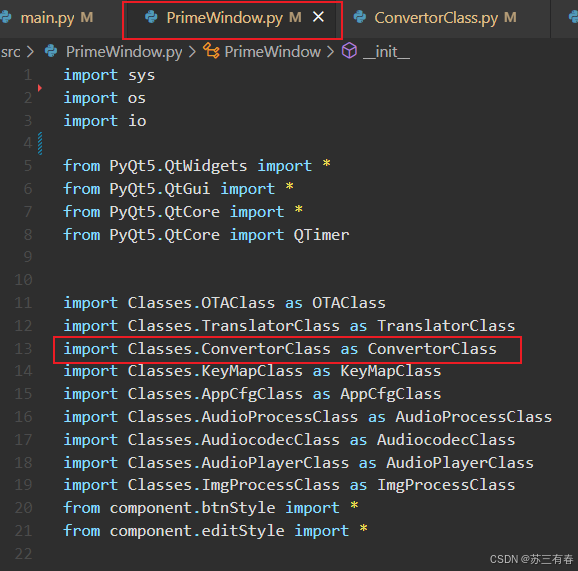
五、torchvision
5.1 torchvision中的Datasets
5.1.1 下载数据集
torchvision 文档列出了很多科研或者毕设常用的一些数据集,如入门数据集MNIST,用于手写文字。这些数据集位于torchvision.datasets模块,可以通过该模块对数据集进行下载,转换等操作。
例如下载CIFAR10数据集:
CIFAR-10数据集由10个类别的60000张32x32彩色图像组成,每个类别有6000张图像。有50000个训练图像和10000个测试图像。
root:表明下载数据集所在的根目录
train:True表明从训练集创建数据集,否则则从测试集创建
transform:接收PIL图像并返回转换后的版本。
download:如果为true,则从互联网下载数据集并将其放入根目录,如果数据集已经下载,则不会再次下载

通过test_set.classes可以看出整个数据集对应的tag。
数字3表明第一张照片的tag是cat,用img.show()查看图片。
5.1.2 transforms的使用
由于数据集图片的类型是PIL Image,在torch中无法使用,我们使用transforms将PIL Image转换成tensor类型,然后用tensorbord查看
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
writer = SummaryWriter("p10")
for i in range(10):img, target = test_set[i]writer.add_image("test_set", img, i)
writer.close()5.2 torchvision中的Dataloader
5.2.1 简介和各个参数说明
DataLoadr是Pytorch中数据读取的一个重要的接口,该接口的目的:将自定义的Dataset根据batch_size大小,是否shuffle等封装成一个Batch_Size大小的Tensor,用于后面的训练。
DataLoader(object)的参数
dataset(Dataset): 传入的数据集
batch_size(int, optional): 每个batch有多少个样本
shuffle(bool, optional): 在每个epoch开始的时候,对数据进行重新排序
sampler(Sampler, optional): 自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False
batch_sampler(Sampler, optional): 与sampler类似,但是一次只返回一个batch的indices(索引),需要注意的是,一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再制定了(互斥——Mutually exclusive)
num_workers (int, optional): 这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程。(默认为0)
collate_fn (callable, optional): 将一个list的sample组成一个mini-batch的函数
pin_memory (bool, optional): 如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中.
drop_last (bool, optional): 如果设置为True:这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch只有100个样本,那么训练的时候后面的36个就被扔掉了…
如果为False(默认),那么会继续正常执行,只是最后的batch_size会小一点。
timeout(numeric, optional): 如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。默认为0
worker_init_fn (callable, optional): 每个worker初始化函数 If not None, this will be called on each
worker subprocess with the worker id (an int in [0, num_workers - 1]) as
input, after seeding and before data loading. (default: None)5.2.1 Dataloader的使用

由此可得:单个数据读取时,输出是 torch.Size([3,32,32]) 3即图片为RGB三个通道,像素大小为32*32,tag为3;采用dataloader(batch_size=4)读取时torch.Size([4,3,32,32]) tensor([1,7,9,2]) 即dataloader会将4个图片和4个target分别打包,得到一个四维的tensor以及长度为4的一维tensor
5.2.2 通过tensorboard显示抓取结果
(1) drop_last=False
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
dataloader=DataLoader(test_set,batch_size=64, shuffle=True, num_workers=0, drop_last=False)
writer=SummaryWriter("animals")
step=0
for data in dataloader:imgs,targets=datawriter.add_images("test_data_drop_last", imgs, step)step+=1
writer.close()这里每次抓取64个数据,用 add_images 函数写入到 SummaryWriter实例化对象中,再进行显示: 这里当 DataLoader 的输入 drop_last设置为True时,最后一次抓取的数据若不满64,则会被丢弃。为Flase时则不会,如上图的上半部分所示,最后一次抓取了16个数据,不满64,没有丢弃。
(2)shuffle=True

六、卷积操作
6.1 搭建网络
搭建神经网络常用的工具在torch.nn模块,Containers为骨架,往骨架中添加下面各层就可以构成一个神经网络。

其中torch.nn.Module是神经网络所有模块的基类。
官方定义的Mode就是所要搭建的网络,继承了torch.nn.Module类。定义了forward函数(神经网络前向传播),将数据输入到网络,通过前向传播,输出处理后的数据。
搭建一个自己的网络。

在Pytorch 官网文档左侧,有 torch.nn和 torch.nn.fuctional,torch.nn 是对 torch.nn.fuctional进行了一个封装,方便用户使用。想细致的了解一些nn模块中的函数可以从 torch.nn.fuctional 入手。
6.2 卷积操作
torch.nn.functional.conv2d()
conv2d需要的参数有:输入input,卷积核weight,偏置bias,步长stride,填充padding
6.2.1 Stride和padding
①Stride=1 padding=0

②Stride=1 padding=1
由此可知padding在input外围补几圈0,默认是0,不进行填充。
stride是用来控制便移的步数。
6.2.2 input
import torch
import torch.nn.modules as F
input = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1], [1, 2, 1, 0, 0], [5, 2, 3, 1, 1], [2, 1, 0, 1, 1]])kernel = torch.tensor([[1, 2, 1], [0, 1, 0], [2, 1, 0]])
print(input.shape)
print(kernel.shape)input = torch.reshape(input, (1, 1, 5, 5)) # F.conv2d()中的input和output需要一个4维的张量
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape)6.3 卷积层
作用:提取特征
torch.nn.functional.conv2d()
-
in_channels (int) – 输入图像的通道数(如RGB图像就是三个通道)
-
out_channels (int)
-
kernel_size (int or tuple) – 卷积核的大小
-
stride (int or tuple, optional) – 卷积操作的移动步长默认为1
-
padding (int, tuple or str, optional) – 像输入的四周进行填充填充. Default: 0
-
padding_mode (string, optional) – ‘zeros’, ‘reflect’, ‘replicate’ or ‘circular’. Default: ‘zeros’
-
dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1
-
groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1
-
bias (bool, optional) – If True, adds a learnable bias to the output. Default: True
import torch
import torch.nn as nn
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
dataset_transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
class Module(nn.Module):def __init__(self):super(Module, self).__init__()self.conv1 = nn.Conv2d(in_channels = 3, out_channels = 6, kernel_size = 3, stride = 1, padding = 0)
def forward(self, x):x = self.conv1(x)return x
dataloader=DataLoader(test_set,batch_size=64, shuffle=True, num_workers=0, drop_last=False)
writer=SummaryWriter("conv")
writer = SummaryWriter("logs")
module=Module()
step = 0
for data in dataloader:imgs, targets = dataoutput = module(imgs) # torch.Size([64, 6, 30, 30]), 通道数为6,writer不会读writer.add_images("input", imgs, step)output = torch.reshape(output, (-1, 3, 30, 30)) # 为了让变化后的图片能直观显示,这里强行让通道数为3。-1的地方会根据其他维数自动调整writer.add_images("output", output, step)step += 1
writer.close()
输出的相关参数计算公式:
七、池化层
7.1 MaxPool2d
7.1.1 相关参数介绍
kernel_size:窗口的大小。
dilation:改变窗口的间隔。如下图所示,蓝色是输入,灰色是窗口,可以看到窗口是3*3大小,且间隔即dilation为1。一般情况下不需要进行设置。
cell_mode::当cell_mode为 True时,将用 cell 模式代替 floor 模式去计算输出。简单解释下 cell 模式和 floor 模式:
cell模式:向上取整,如2.31->3
floor模式:向下取整,如2.9->2
在最大池化操作中,当为cell模式时,如果窗口和输入未完全重合,也会进行一次计算;为floor模式就会放弃计算。
7.2池化操作
7.2.1 cell_model=True
7.2.2 cell_model=False

7.3 示例
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]], dtype=torch.float32)
input = torch.reshape(input, (-1, 1, 5, 5))
class module(nn.Module):def __init__(self):super(module, self).__init__()self.maxpool=nn.MaxPool2d(kernel_size=3,ceil_mode=True)def forward(self,x):x=self.maxpool(x)return x
net1 = module()
output = net1(input)
print(output)

import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]], dtype=torch.float32)
input = torch.reshape(input, (-1, 1, 5, 5))
class module(nn.Module):def __init__(self):super(module, self).__init__()self.maxpool=nn.MaxPool2d(kernel_size=3,ceil_mode=False)def forward(self,x):x=self.maxpool(x)return x
net1 = module()
output = net1(input)
print(output)八、非线性层
8.1 作用
使得神经网络能够模拟和学习各种非线性关系和复杂函数。
常见的非线性层包括激活函数、卷积层、池化层。
非线性层主要增强模型的表达能力,捕捉复杂特征,泛化能力。
8.2 常用的非线性层
8.2.1 ReLU

参数:inplace=True时,会修改input为非线性激活后的结果;
inplace=False时,则不会修改input,input仍为原值(常用)。
①inplace=True:
import torch.nn as nn
import torch
input=torch.tensor(-11)
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.relu1 = nn.ReLU(inplace=True)def forward(self, input):output = self.relu1(input)return output
net=Net()
output=net(input)
print(input)#tensor(0)
print(output)#tensor(0)②:inplace=Fasle
import torch.nn as nn
import torch
input=torch.tensor(-11)
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.relu1 = nn.ReLU(inplace=False)def forward(self, input):output = self.relu1(input)return output
net=Net()
output=net(input)
print(input) #tensor(-11)
print(output) #tensor(0)8.2.2 Sigmod

import torch.nn as nn
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
transforms=torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
train_datasets=torchvision.datasets.CIFAR10("./dataset",train=True,transform=transforms,download=True)
test_datasets=torchvision.datasets.CIFAR10("./dataset",train=False,transform=transforms,download=True)
dataloader=DataLoader(dataset=test_datasets,batch_size=64)
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.Sig = nn.Sigmoid()
def forward(self, input):output = self.Sig(input)return output
net=Net()
writer=SummaryWriter("Sigmod")
step=0
step = 0
for data in dataloader:imgs, targets = datawriter.add_images("input", imgs, global_step=step)output = net(imgs)#output变量是经过Sigmoid激活函数处理后的张量,其值在0到1之间writer.add_images("output", output, step)step += 1
writer.close()可以看到非线性激活主要目的就是给网络增加非线性特征。

九、线性层
十、Sequential
10.1 Sequential
作用:是一个序列容器,把各种层按照网络模型的顺序进行放置,简化代码的编写。
10.2 CIFAR10网络模型搭建

卷积 -> 最大池化 -> 卷积 -> 最大池化 -> 卷积 -> 最大池化 -> 展平 -> 全连接
import torch
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader
import time
from torch.utils.tensorboard import SummaryWriter
trans=torchvision.transforms.Compose([torchvision.transforms.ToTensor()
])
train_dataset=torchvision.datasets.CIFAR10("./dataset",train=True,transform=trans,download=True)
test_dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=trans,download=True)
dataloader=DataLoader(train_dataset,batch_size=64)
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 32, 5, padding=2)self.maxpool1 = nn.MaxPool2d(2)self.conv2 = nn.Conv2d(32, 32, 5, padding=2)self.maxpool2 = nn.MaxPool2d(2)self.conv3 = nn.Conv2d(32, 64, 5, padding=2)self.maxpool3 = nn.MaxPool2d(2)self.flatten = nn.Flatten()self.linear1 = nn.Linear(1024, 64)self.linear2 = nn.Linear(64, 10)
def forward(self, x):x = self.conv1(x)x = self.maxpool1(x)x = self.conv2(x)x = self.maxpool2(x)x = self.conv3(x)x = self.maxpool3(x)x = self.flatten(x)x = self.linear1(x)x = self.linear2(x)return x
net = Net()
writer = SummaryWriter("CIFAR10")
step = 0
# 定义设备、优化器和损失函数
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 遍历数据加载器中的所有批次
for epoch in range(256): # 确保epochs定义了running_loss = 0.0count = 0startTime = time.time()for i, data in enumerate(dataloader, 0):# get the inputsinputs, labels = data# zero the parameter gradientsoptimizer.zero_grad()
# forward + backward + optimizeoutputs = net(inputs) # 使用net而不是classifyNetloss = criterion(outputs, labels)loss.backward()optimizer.step()
# print statisticsrunning_loss += loss.item()count = count + 1totalTime = time.time() - startTimeprint('Epoch: %d, Loss: %.3f, Time: %.3f' % (epoch + 1, running_loss / count, totalTime))
print('Finished Training')十一、损失函数与反向传播
11.1 损失函数
1、计算实际输出与目标之间的差距的函数。是模型的性能指标。
常见的损失函数:
MSE(均方误差):通常用于回归问题,计算模型的预测值和真实值的平均平方差。
CrossEntropy(交叉熵):处理二分类或多分类问题,在分类问题中,模型的预测通常是各个类别的可能性,交叉熵能够有效度量模型预测的可能性分布与真实分布之间的差异。
11.1.1 L1Loss
预测值和目标值之间的绝对差值的平均数,reduction='sum’时为绝对差值的和。
nn.L1Loss是一种在PyTorch库中实现的损失函数,它计算的是预测值和目标值之间的绝对差值的平均数,或者叫做L1范数。在数学上,给定两个n维向量x和y,它们之间的L1范数定义为每个维度上差的绝对值的和:
L1(x, y) = 1/n * Σ|xi - yi|
当我们在深度学习模型中使用L1Loss时,上述公式会在每一个数据点(即每一个xi和yi)上进行计算,然后将所有数据点上的结果求平均,从而得到最终的损失值。
此损失函数在回归问题中使用较多,尤其是当你关心预测值与目标值之间的实值差距(而非平方差)时,L1损失能非常有效。此外,与L2损失相比,L1损失对于异常值(outliers)的敏感性较低。
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
# loss = L1Loss(reduction='sum')
loss = L1Loss()
res = loss(inputs, targets)
print(res)11.1.2 MSELoss
均方误差,对于两个向量(比如预测标签和真实标签向量),MSELoss 计算的是这两个向量之间的均方误差。每一个元素误差的平方和然后再平均。数学上的表达如下:
假设 y 是真实值,f(x) 是预测值,则 MSE = 1/n * Σ(yi - f(xi))^2。
在这个表达式中,
-
yi 表示真实向量中的元素,
-
f(xi) 表示预测向量中的元素,
-
Σ 表示对向量中所有元素求和,
-
n 是元素的总数。

import torch
from torch.nn import L1Loss, MSELoss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
# loss = L1Loss(reduction='sum')
loss = L1Loss()
res = loss(inputs, targets)
loss_mse = MSELoss()
res_mse = loss_mse(inputs, targets)
print(res)
print(res_mse)11.1.3 CrossEntropyLoss
nn.CrossEntropyLoss是在PyTorch库中实现的一种损失函数,它被广泛用于处理多分类问题。具体来说,它的工作原理是对网络的输出先进行softmax操作,然后计算这个softmax概率分布与真实标签之间的交叉熵。
-
Softmax操作:将每个类别的输出转换成概率值,所有类别概率和为1。这样,每个类别的输出值都介于0-1之间,且所有类别的概率和为1。
-
交叉熵(Cross Entropy): 是一个衡量两个概率分布之间差异的量。在分类问题中,真实的标签通常使用one-hot编码表示,比如对于三分类问题,类别1, 2, 3可能分别被表示为[1, 0, 0],[0, 1, 0],[0, 0, 1]。然后我们计算的是模型预测的概率分布和真实概率分布之间的交叉熵。
import torch
from torch.nn import L1Loss, MSELoss, CrossEntropyLoss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
# loss = L1Loss(reduction='sum')
loss = L1Loss()
res = loss(inputs, targets)
loss_mse = MSELoss()
res_mse = loss_mse(inputs, targets)
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = CrossEntropyLoss()
res_cross = loss_cross(x, y)
print(res)
print(res_mse)
print(res_cross)
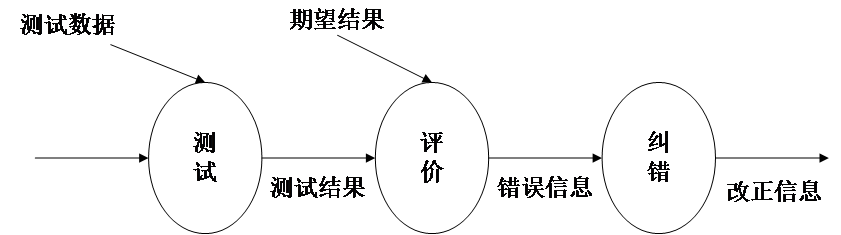
11.2 反向传播
损失函数为更新输出提供一定的依据(反向传播)
用于计算损失函数对模型每一个参数的梯度,在优化模型参数的过程中,我们需要知道模型的每一项参数的梯度方向,以此来更新参数。
11.2.1 工作流程
-
前向传播:数据沿着输入层至输出层的方向传播,经过每一层的操作,最终在输出层产生预测值。
-
损失计算:根据模型的预测值和真实值,使用损失函数计算损失。
-
反向传播:根据链式法则,从输出层开始,沿着网络的结构向反方向(输入层方向)回传,计算计算函数对每一层参数的梯度。这使得我们可以通过梯度下降法更新模型的参数,从而训练我们的模型。
11.2.2 res_loss.backward()的深层实现
①计算梯度:backward()方法首先计算 res_loss 的梯度。这是通过遍历从res_loss 到输入变量的计算图并应用链式规则完成的。计算图是许多函数(即PyTorch操作)的有向无环图,这些函数创建当前的Tensor变量。 ②累计梯度:然后,它将这些计算的梯度累积到各个张量的 .grad 属性中。累积是必要的,因为在许多情况下,如RNN之类的网络结构,一个张量可能会被计算图中的多个路径访问,因此其.grad 携带的是对整个计算图的梯度贡献的总和。 ③处理非叶节点:注意,PyTorch默认只保存并计算叶节点(即直接用户创建和需要梯度的节点)的梯度,而非叶节点(即通过某些操作从其他张量获取的张量)的 .grad 属性通常为None。这是为了节省内存,因为保存整个计算图的梯度非常昂贵。然而,如果您需要非叶节点的梯度,可以通过使用 retain_graph=True 在 backward() 中进行设置。 ④删除计算图:除非设置 retain_graph = True,否则backward函数会默认删除计算图以释放内存。在这种情况下,如果您想要进行另一次反向传播操作,您需要重新进行前向传播,因为计算图已经不存在了。
11.3 神经网络一般流程
①初始化网络权重:首先,我们需要初始化神经网络的权重(连接不同神经元的参数)。这些权重通常是从随机分布(如正态分布或均匀分布)中抽取的。偏置通常初始化为零或很小的值。 ②输入和前向传播:在每次训练迭代中,我们将一批训练数据输入至网络的输入层,并通过所有隐藏层至输出层。隐藏层和输出层的每一层都包含一个线性变换和一个非线性激活函数。在每一层中,我们先根据当前层的权重和偏置对输入进行线性变换,然后将结果输入至非线性激活函数以得到该层的输出(也称为激活)。 ③计算损失:一旦数据通过了网络并得到了输出,我们可以对比网络的预测和实际的标签来计算一个损失值。这个损失值对于回归任务通常是均方误差(MSE),对于分类任务则常用交叉熵损失。损失值越小,表明模型的预测越接近实际标签,模型的性能越好。 ④反向传播和更新权重:在计算了损失后,我们需要计算损失关于每个权重和偏置的梯度,这就是反向传播过程。反向传播算法根据链式法则,从输出层回到输入层,计算并存储每个参数的梯度。然后使用这些梯度和一个步长(也称为学习率)来更新每一个权重和偏置。 ⑤重复迭代:以上的过程会持续进行,每一次都使用新的一批数据,直到达到了预设的迭代次数,或者模型的性能满足设定的标准为止。
十二、优化器
常见的优化器API函数:
①torch.optim.SGD 随机梯度下降
②torch.optim.ASGD 随机平均梯度下降
③torch.optim.Rprop
④torch.optim.Adagrad自适应梯度
import torch
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader
import time
from torch.utils.tensorboard import SummaryWriter
trans=torchvision.transforms.Compose([torchvision.transforms.ToTensor()
])
train_dataset=torchvision.datasets.CIFAR10("./dataset",train=True,transform=trans,download=True)
test_dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=trans,download=True)
dataloader=DataLoader(train_dataset,batch_size=64)
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 32, 5, padding=2)self.maxpool1 = nn.MaxPool2d(2)self.conv2 = nn.Conv2d(32, 32, 5, padding=2)self.maxpool2 = nn.MaxPool2d(2)self.conv3 = nn.Conv2d(32, 64, 5, padding=2)self.maxpool3 = nn.MaxPool2d(2)self.flatten = nn.Flatten()self.linear1 = nn.Linear(1024, 64)self.linear2 = nn.Linear(64, 10)
def forward(self, x):x = self.conv1(x)x = self.maxpool1(x)x = self.conv2(x)x = self.maxpool2(x)x = self.conv3(x)x = self.maxpool3(x)x = self.flatten(x)x = self.linear1(x)x = self.linear2(x)return x
net = Net()
writer = SummaryWriter("CIFAR10")
step = 0
# 定义设备、优化器和损失函数
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 遍历数据加载器中的所有批次
for epoch in range(256): # 确保epochs定义了running_loss = 0.0count = 0startTime = time.time()for i, data in enumerate(dataloader, 0):# get the inputsinputs, labels = data# zero the parameter gradientsoptimizer.zero_grad()
# forward + backward + optimizeoutputs = net(inputs) # 使用net而不是classifyNetloss = criterion(outputs, labels)loss.backward()optimizer.step()
# print statisticsrunning_loss += loss.item()count = count + 1totalTime = time.time() - startTimeprint('Epoch: %d, Loss: %.3f, Time: %.3f' % (epoch + 1, running_loss / count, totalTime))
print('Finished Training')
十三、完整的模型训练、验证
1.准备数据集
2.利用dataloader来加载数据集
3.搭建神经网络
4.记录训练的次数,测试的次数,训练的轮数
import torch
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader
import time
from torch.utils.tensorboard import SummaryWriter
trans=torchvision.transforms.Compose([torchvision.transforms.ToTensor()
])
train_dataset=torchvision.datasets.CIFAR10("./dataset",train=True,transform=trans,download=True)
test_dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=trans,download=True)
train_dataloader=DataLoader(train_dataset,batch_size=64)
test_dataloader=DataLoader(test_dataset,batch_size=64)
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 32, 5, padding=2)self.maxpool1 = nn.MaxPool2d(2)self.conv2 = nn.Conv2d(32, 32, 5, padding=2)self.maxpool2 = nn.MaxPool2d(2)self.conv3 = nn.Conv2d(32, 64, 5, padding=2)self.maxpool3 = nn.MaxPool2d(2)self.flatten = nn.Flatten()self.linear1 = nn.Linear(1024, 64)self.linear2 = nn.Linear(64, 10)
def forward(self, x):x = self.conv1(x)x = self.maxpool1(x)x = self.conv2(x)x = self.maxpool2(x)x = self.conv3(x)x = self.maxpool3(x)x = self.flatten(x)x = self.linear1(x)x = self.linear2(x)return x
net = Net()
"""记录训练的次数"""
total_train_step = 0
"""记录测试的次数"""
total_test_step = 0
"""训练的轮数"""
epoch = 10
# 定义设备、优化器和损失函数
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
loss_fn = nn.CrossEntropyLoss()
# 遍历数据加载器中的所有批次
# 添加tensorboard
writer = SummaryWriter("logs_train")
for i in range(epoch):print("-------第{}轮训练开始-------".format(i+1))# 训练步骤开始for data in train_dataloader:imgs, targets = dataoutputs = net(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step += 1if total_train_step % 100 == 0:# 减少显示量print("训练次数:{}, Loss:{}".format(total_train_step, loss.item())) # 这里的loss.item()可以返回非tensor的正常数字,方便可视化writer.add_scalar("train_loss", loss.item(), total_train_step)# 测试步骤开始
# tudui.eval() #仅对dropout层和BatchNorm层有作用total_test_loss = 0total_accuracy = 0test_data_size=len(test_dataset)with torch.no_grad():# 这部分用于测试不用于训练所以不计算梯度for data in test_dataloader:imgs, targets = dataoutputs = net(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item()accuracy = (outputs.argmax(1) == targets).sum() #(1)是指对每一行搜索最大total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)writer.add_scalar("test_loss", total_test_loss, total_test_step)total_test_step = total_test_step + 1torch.save(net, "tudui_{}.pth".format(i))
# torch.save(tuidui.state_dict(), "tudui_{}.pth".format(i))print("模型已保存")
writer.close()跟着小土堆把pytorch基础过了一遍,对pytorch和深度学习有了一个基础的认识,总体来说这个视频很适合入门,就是环境会难配一点,后面的只要有一点基础知识还是很好入门的。 视频链接:【完结】看看开源项目_哔哩哔哩_bilibili