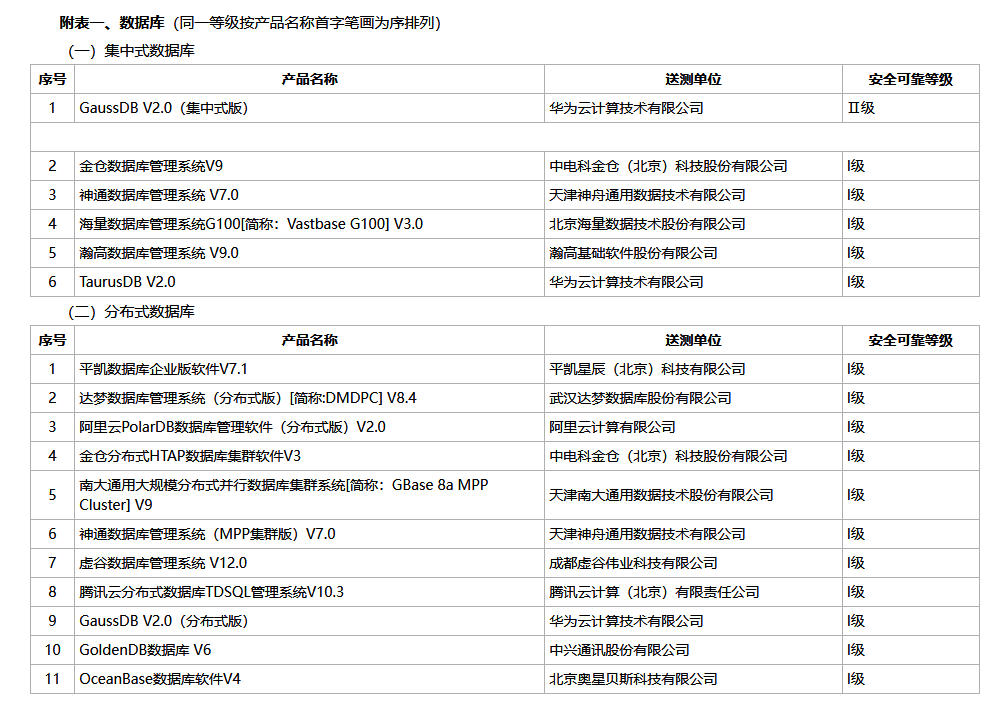
前面介绍的二元、多分类、有序Logistic回归都属于非条件Logistic回归,每个个案均是相互独立关系。在实际研究中,还有另外一种情况,即个案间存在配对关系,比如医学研究中配对设计的病例对照研究,此时违反了个案相互独立的条件,这种数据资料的分析,可采用条件Logistic回归。
1. 基本概念介绍
条件Logistic回归又称配对Logistic回归,其主要用于配对资料的多因素分析,常见的包括1:1、1:M配对Logistic回归。常见的应用场景,比如在个案匹配或倾向性评分匹配形成匹配数据后,通过条件Logistic回归完成分析。
两组数据采取配对的形式,或通过匹配方法得到的两组数据,突出的优势是可排除某些混杂因素的干扰,两组数据达到均衡,从而有利于研究特定因素对结局变量的影响,这也正是条件Logistic的特点。
条件Logistic回归假设自变量的回归系数与配对组无关,对参数的估计是建立在条件概率之上,所以它采用“条件似然函数”进行参数估计建立模型。
2. 配对数据录入格式
(1)在使用条件Logistic回归时,配对数据的录入格式如表 5-36所示。
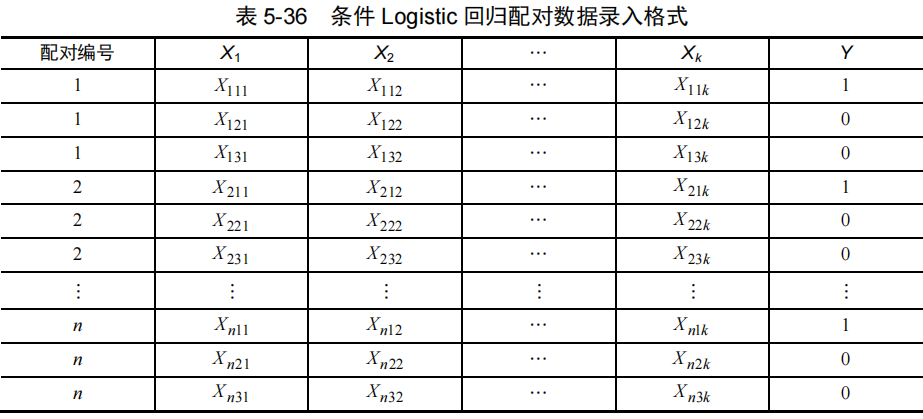
因变量Y为两种结局的分类变量,数字编码必须指定为0和1,0表示对照,1表示干预或病例,如果不是该编码形式,可通过SPSSAU【数据处理】→【数据编码】模块进行设置。
(2) 数据文档中须有一个记录配对编号的变量,比如1:2的配对,假设共配对20组,则配对编号从1~20,每个编号均有3个相同数字,共有20×3行数据。
3. 条件Logistic回归实例分析
【例5-11】某北方城市研究喉癌发病的危险因素,使用1:2匹配的病例对照研究方法进行调查,共获得25组配伍数据(每组3个,即25*3=75行数据)。现欲研究咽炎、吸烟量、摄食新鲜蔬菜、摄食新鲜水果四个可能的因素对喉癌的影响,部分数据见表 5-37。案例数据来源于孙振球,徐勇勇(2014),数据文档见“例5-11.xls”。

1) 数据与案例分析
咽炎编码1~3表示病情等级、吸烟量编码1~5表示吸烟量多少、摄食蔬菜编码1~3、摄食水果1~3表示摄入量多少,均属于有序分类变量。本例视等级资料为定量数据,不做哑变量处理(仅用于方法操作示范)。是否患喉癌:数字1表示病例组即患喉癌,数字0表示对照组即没有患喉癌。
这是1:2的配对数据资料,适合采用条件Logistic回归进行分析。
2) 建立条件Logistic回归模型
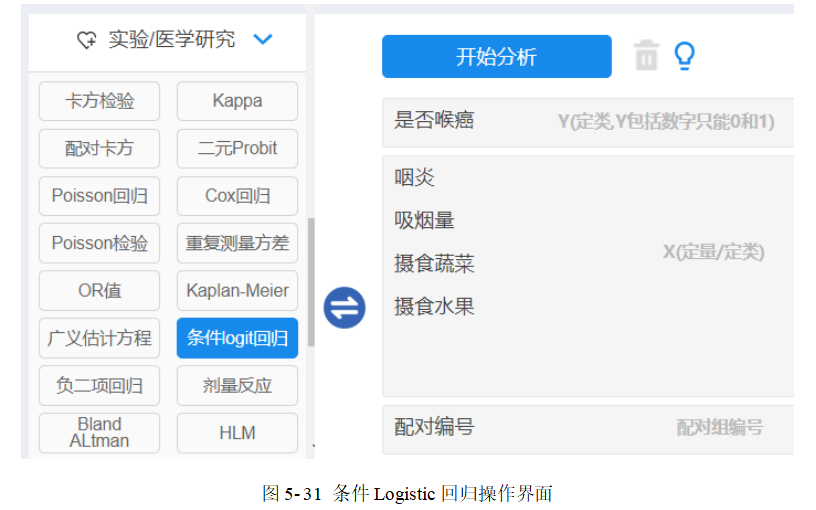
依次选择【实验/医学研究】→【条件logit回归】,将“是否喉癌”拖拽至【Y(定类)】,“咽炎”、“吸烟量”、“摄食蔬菜”、“摄食水果”拖拽至【X(定量/定类)】,“配对编号”拖拽至【配对组编号】框内,最后单击【开始分析】,操作设置界面见图 5-31。
3) 结果综合分析
① 模型总体显著性检验
模型总体显著性检验结果见下表5-38。

经检验,卡方值=28.308,p=0.000﹤0.05,认为模型总体上有统计学意义,模型有效。反之如果p值大于0.05则提示模型无效。
②模型偏回归系数与RR值
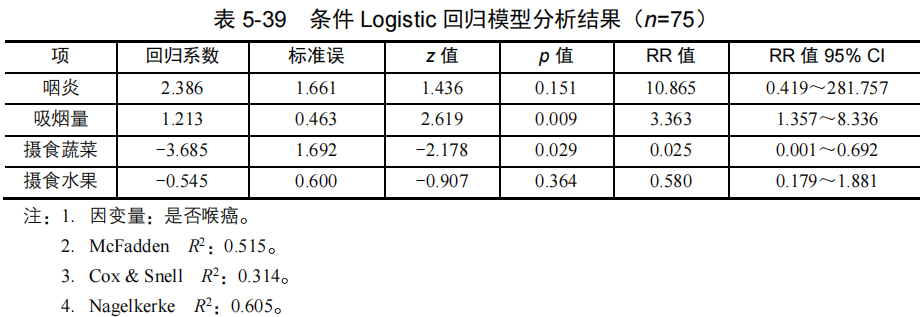
如表539所示,经Wald卡方检验,吸烟量(z=2.619,p=0.009﹤0.05)、摄食蔬菜(z=-2.178,p﹤0.05),吸烟量、摄食蔬菜对是否患喉癌的影响有统计学意义。吸烟量RR=3.363﹥1,摄食蔬菜RR=0.025﹤1,表明吸烟量是喉癌的危险因素,经常摄食新鲜蔬菜是喉癌的保护因素。咽炎、摄食新鲜水果对喉癌结局的影响无统计学意义(均p﹥0.05)。
以上内容摘自《SPSSAU科研数据分析方法与应用》第5章——相关影响关系研究,书中不仅涵盖了数据清理、统计分析和模型构建等内容,还提供了丰富的案例,以便于读者在实际研究中应用。