Java 正则表达式元字符
Java正则表达式教程 - Java正则表达式元字符
元字符是在Java正则表达式中具有特殊含义的字符。
Java中的正则表达式支持的元字符如下:
( ) [ ] { } \ ^ $ | ? * + . < > - = !
字符类
元字符 [和] 指定正则表达式中的字符类。
字符类是一组字符。正则表达式引擎将尝试匹配集合中的一个字符。
字符类“[ABC]"将匹配字符A,B或C.例如,字符串“woman"或“women"将匹配正则表达式“wom [ae] n"。
我们可以使用字符类指定一个字符范围。
范围使用连字符 - 字符表示。
例如, [A-Z] 表示任何大写英文字母;“[0-9]"表示0和9之间的任何数字。
^ 表示不是。
例如, [^ ABC] 表示除A,B和C以外的任何字符。
字符类 [^ A-Z] 表示除大写字母之外的任何字符。
如果 ^ 出现在字符类中,除了开头,它只匹配一个 ^ 字符。
例如,“[ABC ^]"将匹配A,B,C或^。
您还可以在一个字符类中包含两个或多个范围。例如, [a-zA-Z] 匹配任何字符a到z和A到Z.
[a-zA-Z0-9] 匹配任何字符a到z(大写和小写)和任何数字0到9。
下表列出了字符类的示例
字符a到z
| 字符类 | 含义 |
|---|---|
| [abc] | 字符a,b或c |
| [^xyz] | 除x,y和z以外的字符 |
| [a-z] | |
| [a-cx-z] | 字符a到c或x到z,其将包括a,b,c,x,y或z。 |
| [0-9&&[4-8]] | 两个范围(4,5,6,7或8)的交叉, |
| [a-z&&[^aeiou]] | 所有小写字母减元音 |
预定义字符类
下表列出了一些常用的预定义字符类。
预定义
字符
类
| 含义 | |
|---|---|
| . | 任何字符 |
| \d | 数字。 与[0-9]相同 |
| \D | 非数字。 与[^ 0-9]相同 |
| \s | 空格字符。 包括与[\\ t \\ n \\ x0B \\ f \\ r]相同。
|
| \S | 非空白字符。 与[^ \\ s]相同 |
| \w | 一个字符。 与[a-zA-Z_0-9]相同。 |
| \W | 非字字符。 与[^ \ w]相同。 |
例子
以下代码使用 \d 匹配所有数字。
\\d 在字符串中用于转义 \ 。
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Main { public static void main(String args[]) { Pattern p = Pattern.compile("Java \\d"); String candidate = "Java 4"; Matcher m = p.matcher(candidate); if (m != null) System.out.println(m.find()); }
}
上面的代码生成以下结果。
![]()
例2
以下代码 \w+ 匹配任何单词。
双斜杠用于转义 \ 。
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Main { public static void main(String args[]) { String regex = "\\w+"; Pattern pattern = Pattern.compile(regex); String candidate = "asdf Java2s.com"; Matcher matcher = pattern.matcher(candidate); if (matcher.find()) { System.out.println("GROUP 0:" + matcher.group(0)); } }
}
上面的代码生成以下结果。
![]()
Java 正则表达式模式
Java正则表达式教程 - Java正则表达式模式
包 java.util.regex 包含三个类,以支持正则表达式的完整版本。
- 模式
- 匹配
- PatternSyntaxException
Pattern 保存正则表达式的编译形式。
Matcher 将要匹配的字符串与模式相关联,并执行实际匹配。
PatternSyntaxException 表示格式错误的正则表达式中的错误。
编译正则表达式
没有公共构造函数的模式是不可变的,可以共享。
Pattern 类包含一个静态compile()方法,它返回一个 Pattern 对象。
compile()方法是重载的。
static Pattern compile(String regex) static Pattern compile(String regex, int flags)
以下代码将正则表达式编译为Pattern对象:
import java.util.regex.Pattern;public class Main {public static void main(String[] args) {// Prepare a regular expressionString regex = "[a-z]@.";// Compile the regular expression into a Pattern objectPattern p = Pattern.compile(regex);}
}
compile()方法的第二个版本设置修改模式匹配方式的标志。
flags参数是一个位掩码,并在Pattern类中定义为int常量。
| Flag | 描述 |
|---|---|
| Pattern.CANON_EQ | 启用规范等效。 |
| Pattern.CASE_INSENSITIVE | 启用不区分大小写的匹配。 |
| Pattern.COMMENTS | 启用不区分大小写的匹配。... |
| Pattern.DOTALL | 允许在模式中的空格和注释。 忽略以#开头的空格和嵌入的注释,直到行的结尾。 |
| Pattern.LITERAL | 启用模式的文字解析。 这个标志使元字符和转义序列作为正常字符。 |
| Pattern.MULTILINE | 启用多行模式。 默认情况下,^和$匹配输入序列的开始和结束。 此标志使模式仅逐行匹配或输入序列的末尾。 |
| Pattern.UNICODE_CASE | 启用支持Unicode的大小写。 与CASE_INSENSITIVE标志一起,可以根据Unicode标准执行不区分大小写的匹配。 |
| Pattern.UNICODE_ CHARACTER_CLASS | 启用预定义字符类和POSIX字符类的Unicode版本。 设置此标志时,预定义字符类和POSIX字符类符合Unicode技术标准。 |
| Pattern.UNIX_LINES | 启用Unix行模式。 设置此标志时,只有\ n字符被识别为行终止符。 |
例子
以下代码编译设置CASE_INSENSTIVE和DOTALL标志的正则表达式。
import java.util.regex.Pattern;public class Main {public static void main(String[] args) {String regex = "[a-z]@.";Pattern p = Pattern.compile(regex, Pattern.CASE_INSENSITIVE|Pattern.DOTALL);}
}
例2
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Main {public static void main(String args[]) {Pattern p = Pattern.compile("java", Pattern.CASE_INSENSITIVE);String candidateString = "Java. java JAVA jAVA";Matcher matcher = p.matcher(candidateString);// display the latter matchSystem.out.println(candidateString);matcher.find(11);System.out.println(matcher.group());// display the earlier matchSystem.out.println(candidateString);matcher.find(0);System.out.println(matcher.group());}
}
上面的代码生成以下结果。

Java 正则表达式匹配
Java正则表达式教程 - Java正则表达式匹配
Matcher 类对字符序列执行匹配通过解释在 Pattern 对象中定义的编译模式。
Pattern 类的 matcher()方法创建一个实例的 Matcher 类。
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Main {public static void main(String[] args) {String regex = "[a-z]@.";Pattern p = Pattern.compile(regex);String str = "abc@yahoo.com,123@cnn.com,abc@google.com";Matcher m = p.matcher(str);}
}
匹配器的以下方法执行匹配。
- find() method
- start() method
- end() method
- group() method
find()方法
find()方法找到输入中的模式的匹配。
如果find成功,它返回true。否则,它返回false。
第一次调用 find()在输入的开始处开始搜索。下一个调用将在上一次匹配后开始搜索。
我们可以使用while循环与 find()方法来查找所有的匹配。
find()方法是一个重载的方法。find()方法的另一个版本接受一个整数参数,这是开始查找匹配的偏移量。
start()方法
find()方法返回上一次匹配的开始索引。 它在成功的find()方法调用之后使用。
end()方法
end()方法返回匹配字符串中最后一个字符的索引加一。
匹配后, str.substring(m.start(),m.end())给出匹配的字符串。
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Main {public static void main(String[] args) {String regex = "[a-z]@.";Pattern p = Pattern.compile(regex);String str = "abc@yahoo.com,123@cnn.com,abc@google.com";Matcher m = p.matcher(str);if (m.find()) {String foundStr = str.substring(m.start(), m.end());System.out.println("Found string is:" + foundStr);}}
}
上面的代码生成以下结果。
![]()
group()方法
group()方法通过前一个成功的find()方法调用返回找到的字符串。
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Main {public static void main(String[] args) {String regex = "[a-z]@.";Pattern p = Pattern.compile(regex);String str = "abc@yahoo.com,123@cnn.com,abc@google.com";Matcher m = p.matcher(str);if (m.find()) {String foundStr = m.group();System.out.println("Found text is:" + foundStr);}}
}
上面的代码生成以下结果。
![]()
例子
import java.util.regex.Pattern;
import java.util.regex.Matcher;public class Main {public static void main(String[] args) {String regex = "[abc]@.";String source = "abc@example.com";findPattern(regex, source);}public static void findPattern(String regex, String source) {Pattern p = Pattern.compile(regex);Matcher m = p.matcher(source);System.out.println("Regex:" + regex);System.out.println("Text:" + source);while (m.find()) {System.out.println("Matched Text:" + m.group() + ", Start:" + m.start()+ ", " + "End:" + m.end());}}
}
上面的代码生成以下结果。
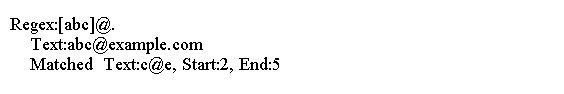
Java 正则表达式量词
Java正则表达式教程 - Java正则表达式量词
我们可以指定正则表达式中的字符的次数可以匹配字符序列。
为了使用正则表达式表达一个数字或更多的模式,我们可以使用量词。
下表列出了量词及其含义。
| 量词 | 含义 |
|---|---|
| * | 零次或更多次 |
| + | 一次或多次 |
| ? | 一次或根本不 |
| {m} | 正好m次 |
| {m,} | 至少m次 |
| {m,n} | 至少m,但不超过n次 |
量词必须遵循字符或字符类。
例子
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Main {public static void main(String[] args) {// A group of 3 digits followed by 7 digits.String regex = "\\b(\\d{3})\\d{7}\\b";// Compile the regular expressionPattern p = Pattern.compile(regex);String source = "12345678, 12345, and 9876543210";// Get the Matcher objectMatcher m = p.matcher(source);// Start matching and display the found area codeswhile (m.find()) {String phone = m.group();String areaCode = m.group(1);System.out.println("Phone: " + phone + ", Area Code: " + areaCode);}}
}
上面的代码生成以下结果。
![]()
例2
* 匹配零个或多个 d 。
import java.util.regex.Pattern;public class Main {public static void main(String args[]) {String regex = "ad*";String input = "add";boolean isMatch = Pattern.matches(regex, input);System.out.println(isMatch);}
}
上面的代码生成以下结果。
![]()
Java 正则表达式边界
Java正则表达式教程 - Java正则表达式边界
要匹配一行的开头,或匹配整个单词,不是任何单词的一部分,我们必须为匹配器设置边界。
下表列出了正则表达式中的边界匹配器
| 边界匹配 | 含义 |
|---|---|
| ^ | 一行的开始 |
| $ | 一行的结束 |
| \b | 字边界 |
| \B | 非字边界 |
| \A | 输入的开始 |
| \G | 上一次匹配的结束 |
| \Z | 输入的结束,但是对于最终终止符,如果有的话 |
| \z | 输入的结束 |
例子
以下代码演示了如何使用正则表达式匹配字边界。
public class Main {public static void main(String[] args) {// \\b to get \b inside the string literal.String regex = "\\bJava\\b";String replacementStr = "XML";String inputStr = "Java and Javascript";String newStr = inputStr.replaceAll(regex, replacementStr);System.out.println("Regular Expression: " + regex);System.out.println("Input String: " + inputStr);System.out.println("Replacement String: " + replacementStr);System.out.println("New String: " + newStr);}
}
上面的代码生成以下结果。

Java 正则表达式组
Java正则表达式教程 - Java正则表达式组
我们可以通过括号将多个字符组合为一个单位。例如,(ab)。
正则表达式中的每个组都有一个组号,从1开始。
Matcher类中的方法groupCount()返回与Matcher实例相关联的模式中的组数。
组0引用整个正则表达式和不由groupCount()方法报告。
正则表达式中的每个左括号标记新组的开始。
我们可以在正则表达式中返回引用组号。
假设我们要匹配以“abc"开头,后跟“xyz"的文本,后跟“abc"。
我们可以写一个正则表达式为“abcxyzabc"。
我们可以使用反向引用将正则表达式重写为“(abc)xyz \\ 1"。 \1 指第1组,即(abc)。
\2 引用组2, \3 引用组3,依此类推。
以下代码显示如何显示格式化的电话号码。在正则表达式 \b(\d{3})(\d{3})(\d{4})\b \b 表示我们感兴趣的是仅在字边界匹配十个数字。
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Main {public static void main(String[] args) {String regex = "\(\\d{3})(\\d{3})(\\d{4})\";Pattern p = Pattern.compile(regex);String source = "1234567890, 12345, and 9876543210";Matcher m = p.matcher(source);while (m.find()) {System.out.println("Phone: " + m.group() + ", Formatted Phone: ("+ m.group(1) + ") " + m.group(2) + "-" + m.group(3));}}
}
上面的代码生成以下结果。

例子
以下代码显示如何引用替换文本中的组。
$n ,其中 n 是组编号,替换文本内部是指组 n 的匹配文本。
例如, $1 是指第一个匹配的组。要重新格式化电话号码,我们将使用($1) $2- $3 。
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Main {public static void main(String[] args) {String regex = "\(\\d{3})(\\d{3})(\\d{4})\";String replacementText = "($1) $2-$3";String source = "1234567890, 12345, and 9876543210";Pattern p = Pattern.compile(regex);Matcher m = p.matcher(source);String formattedSource = m.replaceAll(replacementText);System.out.println("Text: " + source);System.out.println("Formatted Text: " + formattedSource);}
}
上面的代码生成以下结果。
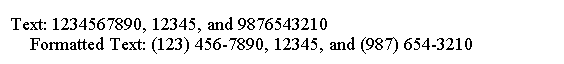
命名组
我们可以在正则表达式中使用命名组。
我们可以命名一个组,然后使用他们的名字来引用参考组。
我们可以在替换文本中引用组名称,并使用组名称获取匹配的文本。
定义命名组的格式为
(?<groupName>pattern)
一对括号标记一个组。开始括号后面跟着一个?和放在尖括号中的组名称。
组名称只能包含字母和数字,且只能以字母开头。
以下正则表达式具有三个命名组。
- areaCode
- prefix
- postPhoneNumber
正则表达式匹配10位数的电话号码。
(?<areaCode>\d{3})(?<prefix>\d{3})(?<postPhoneNumber>\d{4})
以下代码显示如何使用命名组。
String replacementText = "(${areaCode}) ${prefix}-${postPhoneNumber}";
我们可以混合组号和组名。
上述正则表达式可以重写如下。
String replacementText = "(${areaCode}) ${prefix}-$3";
以下代码显示如何在正则表达式中使用组名称以及如何在替换文本中使用名称。
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Main {public static void main(String[] args) {String regex = "\(?<areaCode>\\d{3})(?<prefix>\\d{3})(?<postPhoneNumber>\\d{4})\";String replacementText = "(${areaCode}) ${prefix}-$3";String source = "1234567890 and 9876543210";Pattern p = Pattern.compile(regex);Matcher m = p.matcher(source);String formattedSource = m.replaceAll(replacementText);System.out.println("Text: " + source);System.out.println("Formatted Text: " + formattedSource);}
}
上面的代码生成以下结果。
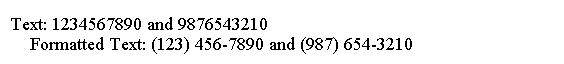
组边界
我们可以使用 start()和 end()方法来获取组的匹配边界。 这些方法重载:
int start() int start(int groupNumber) int start(String groupName) int end() int end(int groupNumber) int end(String groupName)
方法返回上一次匹配的开始和结束。
以下代码显示如何匹配10位电话号码,并为每个成功匹配打印每个组的开始。
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Main {public static void main(String[] args) {String regex = "\(?<areaCode>\\d{3})(?<prefix>\\d{3})(?<postPhoneNumber>\\d{4})\";String source = "1234567890, 12345, and 9876543210";Pattern p = Pattern.compile(regex);Matcher m = p.matcher(source);while (m.find()) {String matchedText = m.group();int start1 = m.start("areaCode");int start2 = m.start("prefix");int start3 = m.start("postPhoneNumber");System.out.println("Matched Text:" + matchedText);System.out.println("Area code start:" + start1);System.out.println("Prefix start:" + start2);System.out.println("Line Number start:" + start3);}}
}
上面的代码生成以下结果。

Java 正则表达式查找/替换
Java正则表达式教程 - Java正则表达式查找/替换
我们可以找到一个模式,并用一些文本替换,替换的文本取决于匹配的文本。
在Java中,我们可以在Matcher类中使用以下两个方法来完成这个任务。
Matcher appendReplacement(StringBuffer sb, String replacement) StringBuffer appendTail(StringBuffer sb)
例子
假设我们有以下文本。
We have 7 tutorials for Java, 2 tutorials for Javascript and 1 tutorial for Oracle.
我们想在以下规则中将数字更改为文本。
- 如果多于5,更换多
- 如果小于5,请更换少量
- 如果是1,替换为“只有一个”
更换后,上面的句子是
We have many tutorials for Java, a few tutorials for Javascript and only one tutorial for Oracle.
要找到所有数字,我们可以使用 \b\d+\b。 \b 标记单词边界。
以下代码显示如何使用正则表达式和appendReplacement()和appendTail()方法
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Main {public static void main(String[] args) {String regex = "\\d+";StringBuffer sb = new StringBuffer();String replacementText = "";String matchedText = "";String text = "We have 7 tutorials for Java, 2 tutorials for Javascript and 1 tutorial for Oracle.";Pattern p = Pattern.compile(regex);Matcher m = p.matcher(text);while (m.find()) {matchedText = m.group();int num = Integer.parseInt(matchedText);if (num == 1) {replacementText = "only one";} else if (num < 5) {replacementText = "a few";} else {replacementText = "many";}m.appendReplacement(sb, replacementText);}m.appendTail(sb);System.out.println("Old Text: " + text);System.out.println("New Text: " + sb.toString());}
}上面的代码生成以下结果。




















