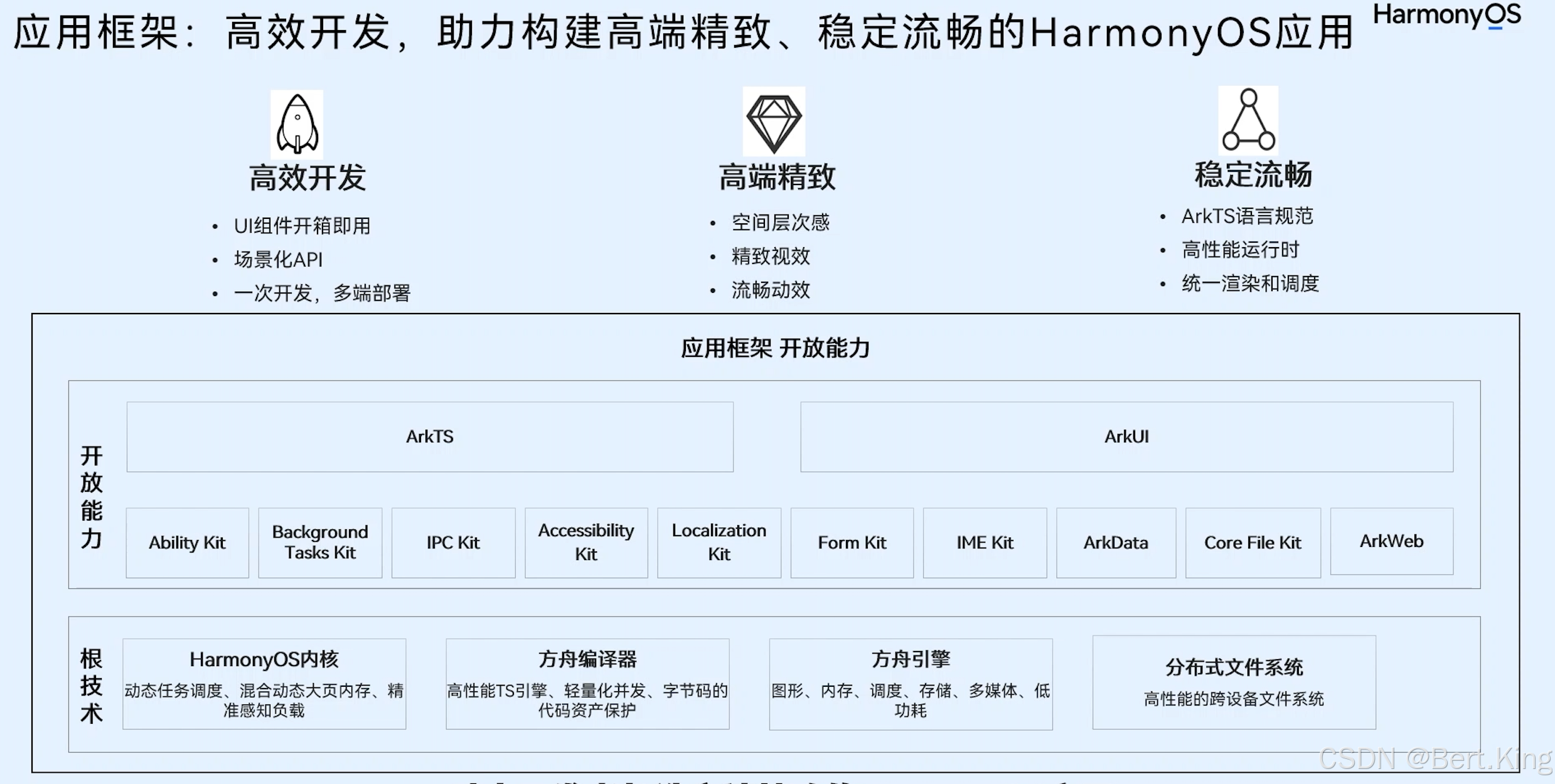
目录
1. 均方误差(Mean Squared Error, MSE)
2. 平均绝对误差(Mean Absolute Error, MAE)
3. Huber 损失
4. 交叉熵损失(Cross-Entropy Loss)
5. KL 散度(Kullback-Leibler Divergence)
6. Hinge 损失
7. 对比损失(Contrastive Loss)
8. 三元损失(Triplet Loss)
9. Focal loss损失
损失函数在深度学习模型训练中起着核心作用,它度量模型的预测输出与真实值的差距,并指导模型更新权重以缩小误差,从而实现更好的拟合。不同任务(如分类、回归、生成)常用不同的损失函数,以适应特定需求。
1. 均方误差(Mean Squared Error, MSE)
定义:

其中,y_i 表示真实值,![]() 表示模型的预测值,N 为样本数。
表示模型的预测值,N 为样本数。
推导与解释:
- MSE 通过平方的方式将每个样本的预测误差放大,使得较大误差的影响更显著。这样做的目的是让模型在更新参数时优先关注误差较大的数据点,从而尽可能减少大误差。
- MSE 具有凸性,因此有利于使用梯度下降等优化算法找到全局最小值。
应用场景: MSE 常用于回归任务(如房价预测),适用于误差服从正态分布的数据。由于对较大误差敏感,因此对异常值多的场景效果不佳。
2. 平均绝对误差(Mean Absolute Error, MAE)
定义:

推导与解释:
- MAE 直接对误差取绝对值,避免了平方的操作。因此,MAE 相比 MSE 对异常值的敏感性更低,更关注整体误差的平均水平。
- MAE 损失函数的优化不如 MSE 简便,因为它的导数在 y_i =
 处不可导,造成优化算法收敛相对缓慢。
处不可导,造成优化算法收敛相对缓慢。
应用场景: MAE 同样用于回归任务,尤其是误差分布中含有异常值的场景。
3. Huber 损失
Huber 损失结合了 MSE 和 MAE 的优点,使模型对误差具有一定的鲁棒性。
定义:

其中 $\delta$ 是超参数。
推导与解释:
- 当误差小于
 时,Huber 损失与 MSE 相同,这时候我们主要关注小误差的细致调整;
时,Huber 损失与 MSE 相同,这时候我们主要关注小误差的细致调整; - 当误差大于
 时,Huber 损失与 MAE 相似,减少了异常值对模型的影响,使得损失函数更鲁棒。
时,Huber 损失与 MAE 相似,减少了异常值对模型的影响,使得损失函数更鲁棒。
应用场景: Huber 损失常用于回归问题且数据中含有异常值,它的鲁棒性使其在异常值较多的数据集上效果良好。需要通过交叉验证选择合适的![]() 参数。
参数。
4. 交叉熵损失(Cross-Entropy Loss)
二分类交叉熵:

多分类交叉熵:

其中 C 为类别数,![]() 为真实标签(1 表示第 i 个样本属于第 j 类,0 表示不属于),
为真实标签(1 表示第 i 个样本属于第 j 类,0 表示不属于),![]() 为预测的概率分布。
为预测的概率分布。
推导与解释:
- 交叉熵计算的是模型输出分布与真实分布的距离,当模型预测越接近真实分布时,交叉熵值越小。
- 通过 softmax 函数将模型的原始输出转化为概率分布,使得该损失函数适用于分类任务。
应用场景: 交叉熵广泛应用于分类任务(如图像分类、文本分类)。它通过最大化模型预测的概率使模型学到更具区分性的特征。
5. KL 散度(Kullback-Leibler Divergence)
定义:

推导与解释:
- KL 散度度量两个概率分布 P 和 Q 的差异性,值越小说明两个分布越接近。
- KL 散度在生成模型中用于度量生成分布和真实分布的相似性,通过最小化 KL 散度可以生成与真实分布更接近的数据。
应用场景: 常用于生成模型(如 VAE)或对抗学习中,通过最小化模型分布和真实分布的距离提升生成效果。
6. Hinge 损失
Hinge 损失用于支持向量机中,特别适合二分类任务。
定义:

推导与解释:
- Hinge 损失会对错误分类的样本产生较大惩罚,使得支持向量机学习到一个能够分隔不同类别的最大边界。
- 该损失强调的是分类边界的宽度,通过“拉开”分类边界增强模型的鲁棒性。
应用场景: 用于支持向量机的训练,能够有效区分两个类别的边界。由于对类别间隔的强调,也在一些深度学习模型中用于分类任务。
7. 对比损失(Contrastive Loss)
对比损失常用于度量学习和孪生网络中。
定义:

其中 y_i 表示样本对的标签(1 表示相似,0 表示不相似),d_i 是样本对的距离,m 是边界阈值。
推导与解释:
- 当样本对相似时(y_i = 1),损失度量的是距离的平方 d_i^2,鼓励相似样本对的距离越小越好。
- 当样本对不相似时,损失函数度量样本对是否超出距离阈值 m,使得不相似样本的距离更大。
应用场景: 用于图像检索、人脸识别等领域,通过度量样本间的相似度优化模型的特征学习能力。
8. 三元损失(Triplet Loss)
三元损失用于度量学习,利用 Anchor、Positive、Negative 样本的相对距离关系来优化模型。
定义:

其中 x_i^a 为 Anchor 样本,x_i^p 为 Positive 样本,x_i^n 为 Negative 样本,![]() 为 margin。
为 margin。
推导与解释:
- 三元损失将相似样本(Anchor 和 Positive)拉近,将不相似样本(Anchor 和 Negative)推远,形成更明显的区分度。
 是一个距离间隔的超参数,确保相似样本对距离小于不相似样本对。
是一个距离间隔的超参数,确保相似样本对距离小于不相似样本对。
应用场景: 广泛用于人脸验证、图像检索,通过距离度量的方式获得更具区分度的特征空间。
9. Focal loss损失
Focal 损失是对交叉熵损失的改进,专门应对类别不平衡问题。
定义:
![]()
其中 ![]() 是平衡因子,gamma是聚焦因子。
是平衡因子,gamma是聚焦因子。
推导与解释:
- Focal 损失通过调整权重因子 和聚焦因子 gamma 来平衡不同类别样本的贡献。对难以分类的样本增加损失权重。
- 该损失有助于模型从稀有样本中学习更多特征,减少简单样本的影响。
应用场景: 用于目标检测和极度不平衡数据集下的分类任务,使模型对难样本(如小目标)有更好的检测效果。







![[OS] Assignment3_Prerequisite_mmap()_1](https://i-blog.csdnimg.cn/direct/5211b768918546df8c86fb480816d05a.png)