14.解码器的Mask
从入门AI到手写Transformer-14.解码器的Mask
- 14.解码器的Mask
- 代码
整理自视频 老袁不说话 。
14.解码器的Mask
解码器与编码器不同的地方如下图:
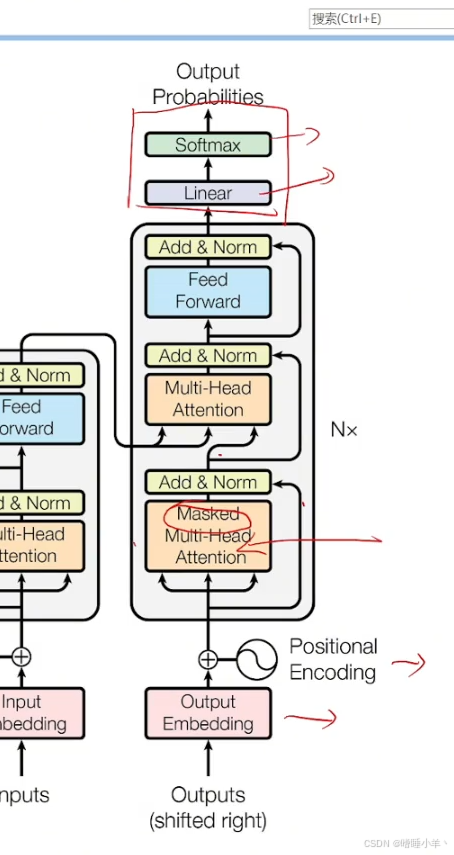
在之前的操作中,需要对填充字符 [pad] 进行掩码mask,消失填充字符的影响。对 Q K ⊤ d \frac{QK^\top}{\sqrt{d}} dQK⊤的 n − m n-m n−m行或 n − m n-m n−m列进行mask,修改为 − 1 0 6 -10^{6} −106。
而在编码器端,语义信息都是已知的, Q K ⊤ {QK^\top} QK⊤计算时, [ x 1 x 2 ⋮ x n ] [ x 1 x 2 ⋯ x n ] = [ x 11 x 12 ⋯ x 1 n x 21 x 22 … x 2 n ⋮ x n 1 x n 2 … x n n ] \begin{bmatrix}x_{1}\\x_{2}\\\vdots\\{x_{n}}\end{bmatrix}\begin{bmatrix}x_{1}&x_{2}&\cdots&x_{n}\end{bmatrix}=\begin{bmatrix}x_{11}&x_{12}&\cdots&x_{1n}\\x_{21}&x_{22}&\dots&x_{2n} \\\vdots\\{x_{n1}}&x_{n2}&\dots&x_{nn}\end{bmatrix} ⎣⎢⎢⎢⎡x1x2⋮xn⎦⎥⎥⎥⎤[x1x2⋯xn]=⎣⎢⎢⎢⎡x11x21⋮xn1x12x22xn2⋯……x1nx2nxnn⎦⎥⎥⎥⎤
在解码器端,已知信息不足,只能计算到当前词语, [ x 1 x 2 ⋮ x n ] [ x 1 x 2 ⋯ x n ] = [ x 11 x 21 x 22 ⋮ x n 1 x n 2 … x n n ] \begin{bmatrix}x_{1}\\x_{2}\\\vdots\\{x_{n}}\end{bmatrix}\begin{bmatrix}x_{1}&x_{2}&\cdots&x_{n}\end{bmatrix}=\begin{bmatrix}x_{11}\\x_{21}&x_{22}\\\vdots\\{x_{n1}}&x_{n2}&\dots&x_{nn}\end{bmatrix} ⎣⎢⎢⎢⎡x1x2⋮xn⎦⎥⎥⎥⎤[x1x2⋯xn]=⎣⎢⎢⎢⎡x11x21⋮xn1x22xn2…xnn⎦⎥⎥⎥⎤,是一个下三角矩阵,需要对原始矩阵的上三角矩阵掩码。
编码实现中,替换填充字符的掩码时,假设 b = 3 , n = 5 b=3,n=5 b=3,n=5,批量为3,句子长度为5,每个句子有效长度分别是 [ 4 , 2 , 3 ] [4,2,3] [4,2,3],则将比较矩阵设置为 [ 4 , 4 , 4 , 4 , 4 , 2 , 2 , 2 , 2 , 2 , 3 , 3 , 3 , 3 , 3 ] [4,4,4,4,4,2,2,2,2,2,3,3,3,3,3] [4,4,4,4,4,2,2,2,2,2,3,3,3,3,3],会将右侧字符判别为True,替换掉,详见这个链接
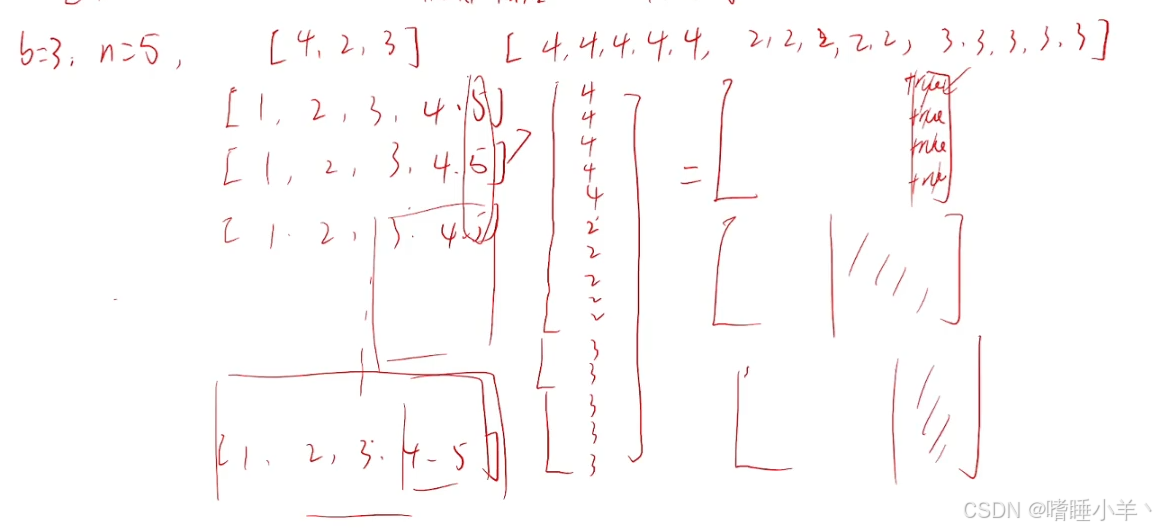
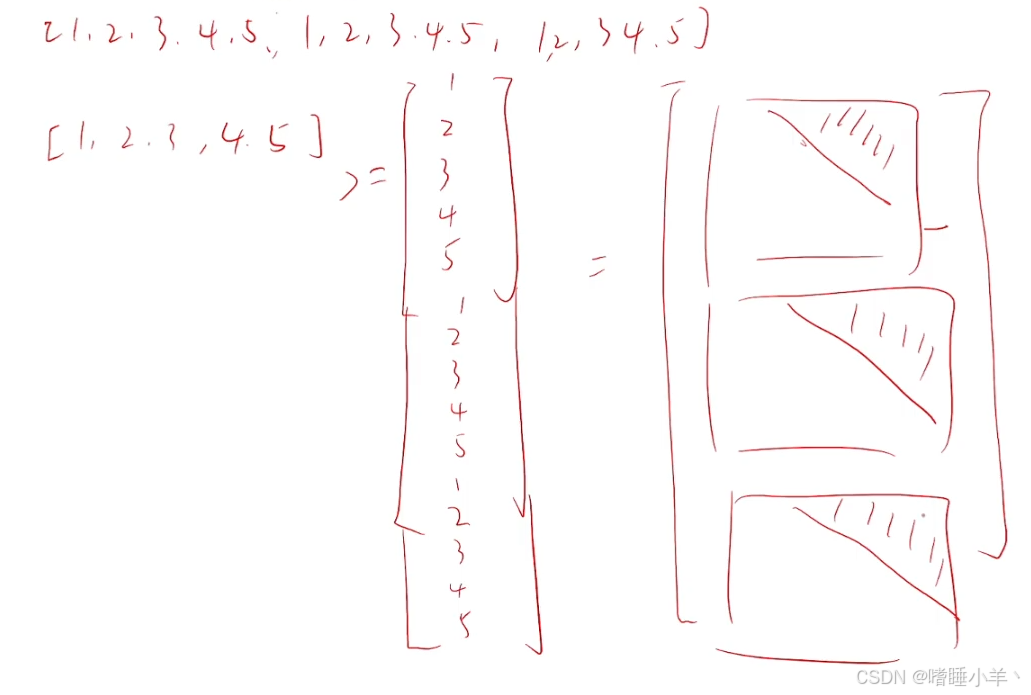
而替换上三角需要将矩阵设置为 [ 1 , 2 , 3 , 4 , 5 , 1 , 2 , 3 , 4 , 5 , 1 , 2 , 3 , 4 , 5 ] [1,2,3,4,5,1,2,3,4,5,1,2,3,4,5] [1,2,3,4,5,1,2,3,4,5,1,2,3,4,5],比较后得到上三角矩阵。
代码
import torch# 定义批次大小b和序列长度n
b = 1 # 批次大小(batch size)
n = 5 # 序列长度(sequence length)# 方法1:生成有效长度(每个样本使用相同长度)
# 随机生成b个1~n的数字,每个数字重复n次
valid_len1 = torch.randint(1, n+1, (b,)).repeat_interleave(n)
print(valid_len1) # 示例输出(当b=3): tensor([2,2,2,2,2, 3,3,3,3,3, 4,4,4,4,4])# 方法2:生成有效长度(每个位置使用递增长度)
# 生成1~n的序列,并重复b次
valid_len2 = torch.arange(1, n+1).repeat(b)
print(valid_len2) # 示例输出(当b=3): tensor([1,2,3,4,5, 1,2,3,4,5, 1,2,3,4,5])# 创建基础位置序列 [0,1,2,...,n-1]
a = torch.arange(n)
print(a) # 输出: tensor([0, 1, 2, 3, 4])# 生成掩码(mask)
# mask1: 每个样本统一长度限制(广播比较)
mask1 = a[None, :] < valid_len1[:, None] # 形状: (b*n, n)
# mask2: 每个位置独立长度限制(如填充位置)
mask2 = a[None, :] < valid_len2[:, None] # 形状: (b*n, n)
print(mask1)
print(mask2)# 创建随机输入张量(形状: b*n × n)
X = torch.randn(b, n, n).reshape(b*n, n)# 应用mask2:将无效位置(mask=False)的值设为极小值
# 这通常在注意力机制中用于屏蔽无效位置(如填充位置)
X[~mask2] = -1e6 # ~表示逻辑取反
print(X)
输出结果
tensor([5, 5, 5, 5, 5])
tensor([1, 2, 3, 4, 5])
tensor([0, 1, 2, 3, 4])
tensor([[True, True, True, True, True],[True, True, True, True, True],[True, True, True, True, True],[True, True, True, True, True],[True, True, True, True, True]])
tensor([[ True, False, False, False, False],[ True, True, False, False, False],[ True, True, True, False, False],[ True, True, True, True, False],[ True, True, True, True, True]])
tensor([[-1.3461e+00, -1.0000e+06, -1.0000e+06, -1.0000e+06, -1.0000e+06],[-1.9000e+00, -2.1507e+00, -1.0000e+06, -1.0000e+06, -1.0000e+06],[ 1.3339e+00, -7.1440e-01, 4.6307e-01, -1.0000e+06, -1.0000e+06],[-1.1387e+00, -1.7289e+00, -1.1892e+00, -1.1285e+00, -1.0000e+06],[ 2.0739e-01, -1.3382e+00, 1.9721e-01, 2.8529e-01, -8.7918e-01]])