一、介绍
图书管理与推荐系统。使用Python作为主要开发语言。前端采用HTML、CSS、BootStrap等技术搭建界面结构,后端采用Django作为逻辑处理,通过Ajax等技术实现数据交互通信。在图书推荐方面使用经典的协同过滤算法作为推荐算法模块。主要功能有:
- 角色分为普通用户和管理员
- 普通用户可注册、登录、查看图书、发布评论、收藏图书、对图书评分、借阅图书、归还图书、查看个人借阅、个人收藏、猜你喜欢(针对当前用户个性化推荐图书)
- 管理员可以管理图书以及用户信息
二、系统效果图片展示
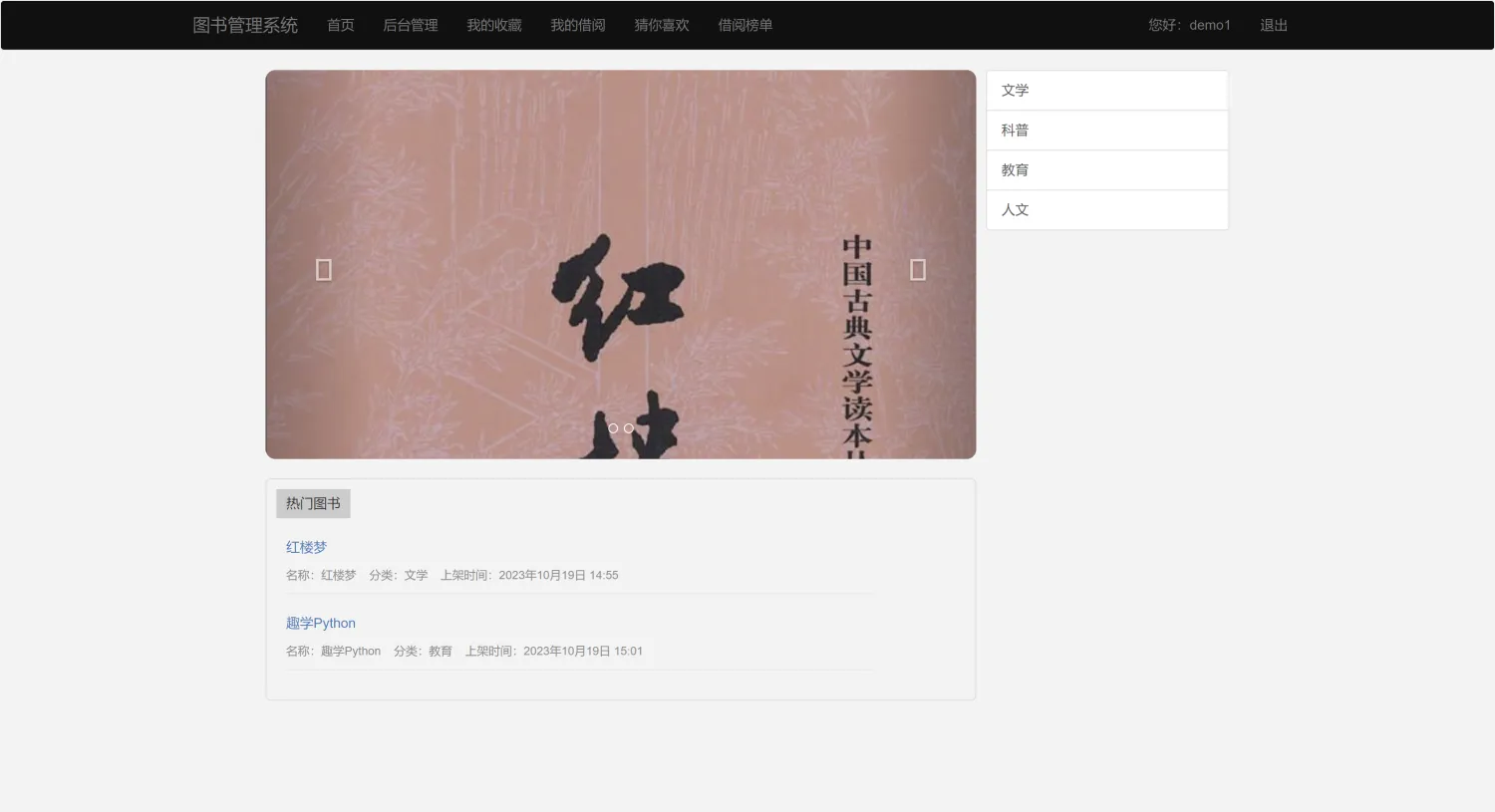
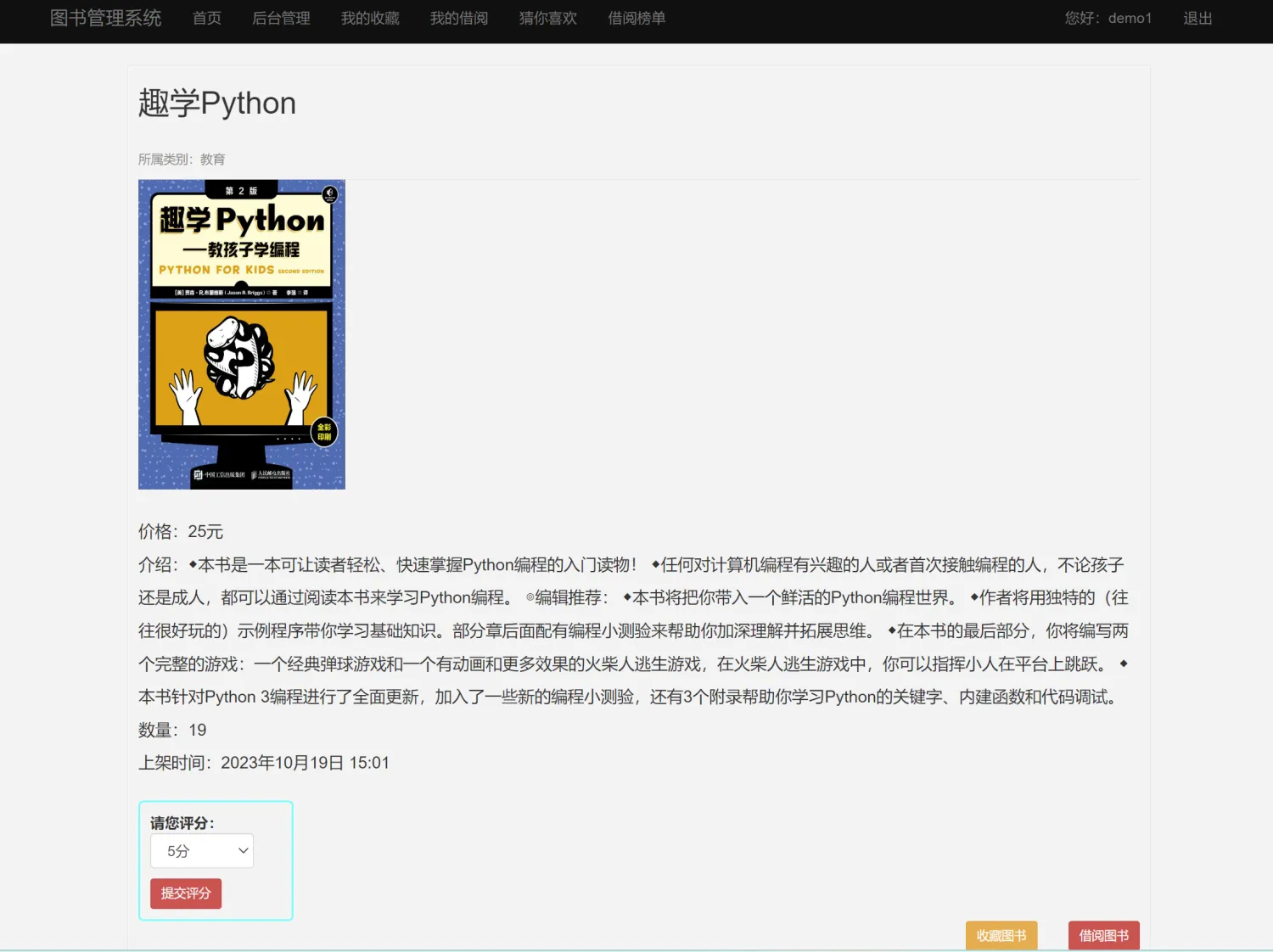
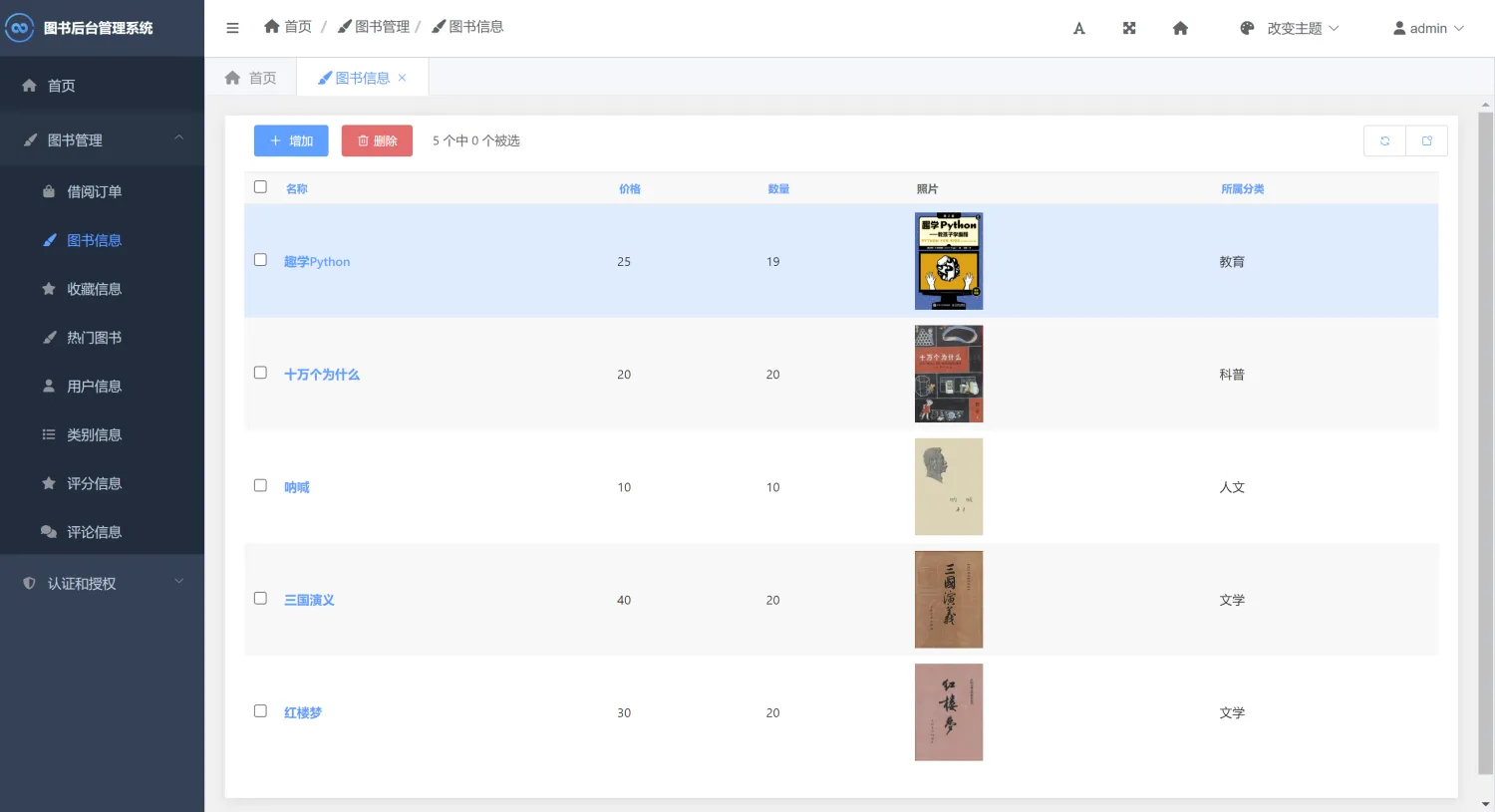
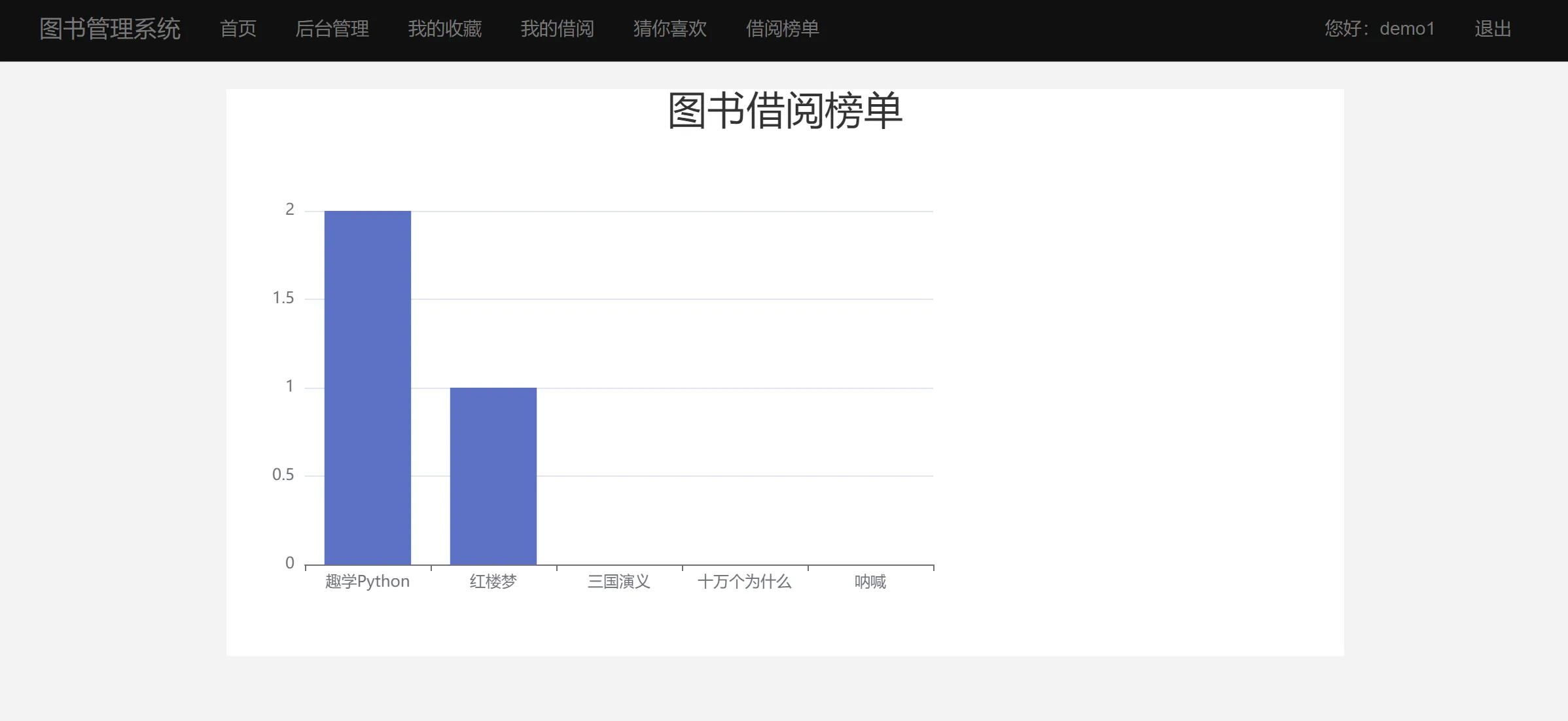
三、演示视频 and 完整代码 and 安装
视频+代码+介绍:https://www.yuque.com/ziwu/yygu3z/kpq3wsbzgif4vkpi
四、协同过滤推荐算法介绍
协同过滤推荐算法是一种基于用户行为数据的推荐系统算法,其核心思想是利用用户之间的相似性来预测用户可能喜欢的物品。它主要有两个方向:基于用户的协同过滤(User-Based Collaborative Filtering)和基于物品的协同过滤(Item-Based Collaborative Filtering)。
-
基于用户的协同过滤:找出与目标用户兴趣相似的其他用户,然后推荐这些相似用户喜欢的物品。这种方法的优点是能够发现用户的潜在兴趣,但计算成本较高,因为需要频繁计算用户之间的相似度。
-
基于物品的协同过滤:直接基于物品之间的相似度来推荐。如果用户喜欢某个物品,系统会找出与该物品相似的其他物品推荐给用户。这种方法的计算效率较高,但可能不如基于用户的协同过滤那样能够发现用户的新兴趣。
协同过滤推荐算法的优点包括能够提供个性化推荐,并且不需要物品内容信息,仅依赖用户的历史行为数据。缺点是可能存在冷启动问题(新用户或新物品难以推荐),以及稀疏性问题(用户和物品之间的交互数据可能非常稀疏)。
以下是一段简单的基于物品的协同过滤推荐算法的Python示例代码:
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np# 假设有一个用户-物品评分矩阵
ratings = np.array([[5, 3, 0, 1],[4, 0, 0, 1],[1, 1, 0, 5],[1, 0, 5, 4],[0, 1, 5, 4],
])# 计算物品之间的余弦相似度
item_similarity = cosine_similarity(ratings.T)# 将相似度矩阵转换为相似度评分
item_similarity[item_similarity < 0.5] = 0# 为用户4推荐物品
user_id = 4
scores = np.dot(item_similarity, ratings) / np.array([np.abs(item_similarity).sum(axis=1)])
recommended_items = np.argsort(-scores[user_id])[:2] # 取分数最高的两个物品print(f"Recommended items for user {user_id}: {recommended_items}")
这段代码首先计算了物品之间的余弦相似度,然后根据相似度和用户的历史评分来预测用户对未评分物品的评分,并推荐分数最高的两个物品。