第 4 期:DDPM中的损失函数——为什么只预测噪声?
—— 从变分下界到噪声预测
回顾:我们到底在做什么?
在第 3 期中,我们介绍了扩散模型的逆过程建模。简而言之,目标是通过神经网络学习从噪声 x_t 中恢复图像 x_0,并且我们通过预测噪声 ϵ来完成这个任务。
今天,我们将深入解析为什么我们仅仅关注噪声预测,以及如何通过损失函数来指导模型的训练。更重要的是,我们将从变分推导的角度,揭示这一做法的理论基础。
损失函数的直观理解
在DDPM中,损失函数的核心是均方误差(MSE)。它是计算网络预测的噪声 ϵ_θ(x_t,t)与真实噪声 ϵ 之间差异的度量。
损失函数表达式
假设给定原图像x_0,我们通过正向扩散过程获得图像在第t步的版本x_t:
![]()
其中,ϵ 是标准正态分布噪声。
逆过程目标是通过神经网络 ϵ_θ(x_t,t) 来估计 ϵ。损失函数则是通过计算网络输出与真实噪声之间的均方误差来进行优化:
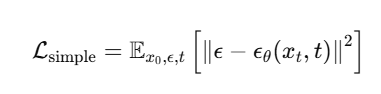
这个损失函数为什么如此简单且有效?接下来,我们从变分下界(ELBO)的角度来理解。
为什么预测噪声而不是直接预测图像?
1. 简化建模问题
考虑到我们每次只需要预测一个特定的时间步(t)的噪声,网络的目标变得更加明确且简单。直接预测图像 x_0 的像素值,则意味着模型需要从噪声中恢复整个图像结构,这在高维空间中是一个非常复杂的问题。
然而,预测噪声本质上是一个去噪过程,这个过程相对更加容易拟合和收敛。
2. 稳定性和收敛性
在扩散模型中,噪声是添加到每个像素上的随机扰动。通过学习从噪声中恢复出原始图像的噪声成分,网络本质上是在学习图像的细节,而不是整个图像结构。因此,通过减少噪声的预测误差,模型能够更加稳定地训练。
从变分下界(ELBO)看损失函数的推导
🧠 变分推导的基础
假设我们有一个潜在的生成过程 p_θ(x_(0:T)),其由正向过程和逆向过程组成。在最大似然学习中,我们希望最大化数据分布 p_θ(x_0):
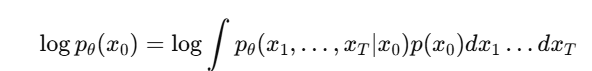
这个积分通常无法直接计算,因此我们通过变分下界(ELBO)来近似:
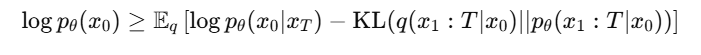
其中,KL表示Kullback-Leibler散度,用于衡量两个分布的差异。通过对 KL 散度的优化,我们可以逼近最优的逆向过程。
具体推导
在DDPM中,逆过程建模为:
![]()
为了简化,假设 Σ_θ(x_t,t)为固定值(通常为单位矩阵)。因此,模型仅需预测均值 μ_θ(x_t,t)。
通过对KL散度进行优化,我们得到最终的损失函数:
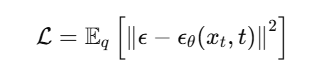
这个损失函数实际上就是模型预测噪声 ϵ_θ(x_t,t)与真实噪声 ϵ\epsilonϵ 之间的均方误差。
代码演示:噪声预测与损失函数
为了更好地理解这个过程,我们来实现一个简单的训练循环,展示如何通过损失函数来训练模型。
import torch
import torch.nn as nn
import matplotlib.pyplot as plt# 定义网络
class DenoiseModel(nn.Module):def __init__(self):super(DenoiseModel, self).__init__()self.conv1 = nn.Conv2d(1, 64, kernel_size=3, padding=1)self.relu = nn.ReLU()self.conv2 = nn.Conv2d(64, 1, kernel_size=3, padding=1)def forward(self, x):x = self.relu(self.conv1(x))return self.conv2(x)# 损失函数
def noise_loss(x_t, noise, model):predicted_noise = model(x_t) # 预测噪声return nn.MSELoss()(predicted_noise, noise) # 计算损失# 示例训练过程
def train(model, dataloader, optimizer):model.train()for x_0, _ in dataloader:t = torch.randint(0, T, (x_0.size(0),), device="cuda")noise = torch.randn_like(x_0)x_t = q_sample(x_0, t, noise) # 通过正向扩散生成带噪图像optimizer.zero_grad()loss = noise_loss(x_t, noise, model) # 计算噪声预测损失loss.backward()optimizer.step()print(f"Loss: {loss.item():.4f}")
可视化:损失函数与训练效果
在训练过程中,损失函数会随着时间逐渐下降。我们可以使用以下代码可视化训练过程中预测噪声与真实噪声的差异。
def plot_loss_progression(losses):plt.plot(losses)plt.xlabel('Iterations')plt.ylabel('Loss')plt.title('Training Loss Progression')plt.show()
小结
| 关键点 | 内容 |
|---|---|
| 损失函数 | 通过均方误差(MSE)计算预测噪声和真实噪声之间的差异 |
| 目标 | 学习从噪声中恢复原始图像细节 |
| 变分下界 | 通过优化KL散度来推导损失函数 |
| 网络设计 | 仅需预测噪声 ϵ 而非图像 x_0 |
下一期预告(第 5 期):
我们将进入实战部分,介绍如何训练第一个DDPM模型。我们将基于MNIST数据集,带领大家一步步实现从数据加载到训练的完整流程,并展示生成的效果!