驱动-自旋锁
前面原子操作进行了讲解, 并使用原子整形操作对并发与竞争实验进行了改进,但是原子操作只能对整形变量或者位进行保护, 而对于结构体或者其他类型的共享资源, 原子操作就力不从心了, 这时候就轮到自旋锁的出场了。
两个 app 应用程序之间对共享资源的竞争访问引起了数据传输错误, 而在 Linux 内核中, 提供了四种处理并发与竞争的常见方法:
分别是原子操作、 自旋锁、 信号量、 互斥体, 这里了解下原子操作
文章目录
- 自旋锁概念
- 工作原理
- 特点
- 常用API
- 参考资料
- 驱动-原子操作实验
- 实验源码 spinlock.c
- 部分源码解读
- Makefile 编译文件
- 测试程序 app.c
- 加载驱动 insmod
- 查看 dev 下生成的字符设备
- ./app 执行程序 验证
- 总结
自旋锁概念
自旋锁是一种低级的同步原语,用于在多处理器系统中保护共享资源。与互斥锁不同,当一个线程尝试获取已被占用的自旋锁时,它不会阻塞或睡眠,而是会在一个循环中不断检查锁的状态(即"自旋"),直到锁变为可用状态。
工作原理
-
尝试获取锁:线程尝试通过原子操作获取锁
-
锁可用:获取成功,线程继续执行临界区代码
-
锁被占用:线程进入忙等待循环,不断检查锁状态
-
锁释放:当锁持有者释放锁后,等待线程可以获取锁
特点
-
忙等待:不放弃CPU,持续检查锁状态
-
短临界区:适合保护执行时间很短的代码段
-
无上下文切换:避免了线程切换的开销
-
多处理器有效:在单处理器系统上可能浪费CPU周期
常用API
#include <linux/spinlock.h>// 定义和初始化
spinlock_t my_lock;
spin_lock_init(&my_lock);// 获取锁
spin_lock(&my_lock); // 获取锁,禁用本地 CPU 中断
spin_lock_irq(&my_lock); // 获取锁并禁用硬件中断
spin_lock_irqsave(&my_lock, flags); // 保存中断状态并获取锁// 释放锁
spin_unlock(&my_lock); // 释放锁
spin_unlock_irq(&my_lock); // 释放锁并恢复中断
spin_unlock_irqrestore(&my_lock, flags); // 释放锁并恢复之前的中断状态// 尝试获取锁
int spin_trylock(&my_lock); // 非阻塞尝试获取锁,成功返回非零参考资料
接下来还是以前面字符设备 动态参数传递实验为基础,打开访问字符设备实验。 所以以前知识点 建议了解
在字符设备这块内容,所有知识点都是串联起来的,需要整体来理解,缺一不可,建议多了解一下基础知识
驱动-申请字符设备号
驱动-注册字符设备
驱动-创建设备节点
驱动-字符设备驱动框架
驱动-杂项设备
驱动-内核空间和用户空间数据交换
驱动-文件私有数据
Linux驱动之 原子操作
Linux驱动—原子操作
驱动-原子操作实验
实验源码 spinlock.c
#include <linux/init.h>
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/kdev_t.h>
#include <linux/cdev.h>
#include <linux/uaccess.h>
#include <linux/delay.h>
#include <linux/atomic.h>
#include <linux/errno.h>static spinlock_t spinlock_test;//定义spinlock_t类型自旋变量
static int flag=1;static int open_test(struct inode *inode,struct file *file){spin_lock(&spinlock_test); //自旋枷锁if(flag!=1){ //判断标志位flag 的值是否等于1 spin_unlock(&spinlock_test); return -EBUSY;}flag=0; //将标志位的值设置为0spin_unlock(&spinlock_test); //自旋锁解锁printk("\n this is open_test \n");return 0;};static ssize_t read_test(struct file *file,char __user *ubuf,size_t len,loff_t *off)
{int ret;char kbuf[10] = "topeet";//定义char类型字符串变量kbufprintk("\nthis is read_test \n");ret = copy_to_user(ubuf,kbuf,strlen(kbuf));//使用copy_to_user接收用户空间传递的数据if (ret != 0){printk("copy_to_user is error \n");}printk("copy_to_user is ok \n");return 0;
}
static char kbuf[10] = {0};//定义char类型字符串全局变量kbuf
static ssize_t write_test(struct file *file,const char __user *ubuf,size_t len,loff_t *off)
{int ret;ret = copy_from_user(kbuf,ubuf,len);//使用copy_from_user接收用户空间传递的数据if (ret != 0){printk("copy_from_user is error\n");}if(strcmp(kbuf,"topeet") == 0 ){//如果传递的kbuf是topeet就睡眠四秒钟ssleep(4);}else if(strcmp(kbuf,"itop") == 0){//如果传递的kbuf是itop就睡眠两秒钟ssleep(2);}printk("copy_from_user buf is %s \n",kbuf);return 0;
}
static int release_test(struct inode *inode,struct file *file)
{//printk("\nthis is release_test \n");spin_lock(&spinlock_test);//自旋锁加锁flag = 1;spin_unlock(&spinlock_test);//自旋锁解锁 return 0;
}struct chrdev_test
{dev_t dev_num; //定义dev_t类型变量来表示设备号int major,minor; //定义int 类型的主设备号和次设备号struct cdev cdev_test; //定义字符设备struct class *class_test; //定义结构体变量class 类
};struct chrdev_test dev1; //创建chardev_test类型结构体变量static struct file_operations fops_test = {.owner=THIS_MODULE,//将owner字段指向本模块,可以避免在模块的操作正在被使用时卸载该模块.open = open_test,//将open字段指向chrdev_open(...)函数.read = read_test,//将open字段指向chrdev_read(...)函数.write = write_test,//将open字段指向chrdev_write(...)函数.release = release_test,//将open字段指向chrdev_release(...)函数
};//定义file_operations结构体类型的变量cdev_test_opsstatic int __init chrdev_fops_init(void)//驱动入口函数
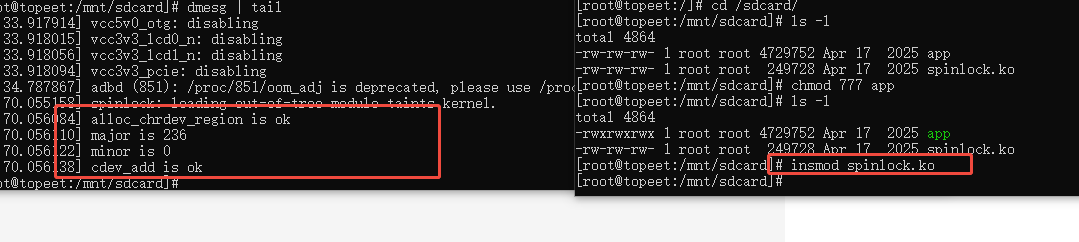
{if(alloc_chrdev_region(&dev1.dev_num,0,1,"chrdev_name") < 0){printk("alloc_chrdev_region is error\n");} printk("alloc_chrdev_region is ok\n");dev1.major=MAJOR(dev1.dev_num);//通过MAJOR()函数进行主设备号获取dev1.minor=MINOR(dev1.dev_num);//通过MINOR()函数进行次设备号获取printk("major is %d\n",dev1.major);printk("minor is %d\n",dev1.minor);使用cdev_init()函数初始化cdev_test结构体,并链接到cdev_test_ops结构体cdev_init(&dev1.cdev_test,&fops_test);dev1.cdev_test.owner = THIS_MODULE;//将owner字段指向本模块,可以避免在模块的操作正在被使用时卸载该模块 cdev_add(&dev1.cdev_test,dev1.dev_num,1);printk("cdev_add is ok\n");dev1.class_test = class_create(THIS_MODULE,"class_test");//使用class_create进行类的创建,类名称为class_testdevice_create(dev1.class_test,NULL,dev1.dev_num,NULL,"device_test");//使用device_create进行设备的创建,设备名称为device_testreturn 0;
}
static void __exit chrdev_fops_exit(void)//驱动出口函数
{cdev_del(&dev1.cdev_test);//使用cdev_del()函数进行字符设备的删除unregister_chrdev_region(dev1.dev_num,1);//释放字符驱动设备号 device_destroy(dev1.class_test,dev1.dev_num);//删除创建的设备class_destroy(dev1.class_test);//删除创建的类printk("module exit \n");}
module_init(chrdev_fops_init);//注册入口函数
module_exit(chrdev_fops_exit);//注册出口函数
MODULE_LICENSE("GPL v2");//同意GPL开源协议
MODULE_AUTHOR("wang fang chen "); //作者信息部分源码解读
- 上面测试源码demo,完全还是基于之前字符设备的一套,和 原子操作实验代码完全一样,唯一区别是没有用原子操作来防止竞争,用了自旋锁来防止资源竞争
- 可以简要看一下 自旋锁这里是一堆一堆出现的。 spin_lock(&spinlock_test); //自旋枷锁 spin_unlock(&spinlock_test); //自旋锁解锁
就是枷锁 设置flag,然后解锁。 恢复flag 状态时候 就枷锁->设置flag 的值->解锁。
Makefile 编译文件
#!/bin/bash
export ARCH=arm64
export CROSS_COMPILE=aarch64-linux-gnu-
obj-m += spinlock.o
KDIR :=/home/wfc123/Linux/rk356x_linux/kernel
PWD ?= $(shell pwd)
all:make -C $(KDIR) M=$(PWD) modulesclean:make -C $(KDIR) M=$(PWD) clean测试程序 app.c
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>int main(int argc,char *argv[])
{int fd;//定义int类型的文件描述符char str1[10]={0};//定义读取缓冲区str1fd=open(argv[1],O_RDWR,0666);//调用open函数,打开输入的第一个参数文件,权限为可读可写//fd=open("/dev/device_test",O_RDWR,0666);//调用open函数,打开输入的第一个参数文件,权限为可读可写if(fd<0){printf("open is error\n");return -1;}printf("open is ok\n");if(strcmp(argv[2],"topeet")==0){write(fd,"topeet",sizeof(str1)); }else if(strcmp(argv[2],"itop")==0){write(fd,"itop",sizeof(str1)); }close(fd);//调用close函数,对取消文件描述符到文件的映射return 0;
}编译 测试程序 app
aarch64-linux-gnu-gcc -o app app.c -static加载驱动 insmod
执行命令,测试结果如下:
查看 dev 下生成的字符设备
ls /dev/device_test
[root@topeet:/mnt/sdcard]# ls /dev/device_test
/dev/device_test
[root@topeet:/mnt/sdcard]#
./app 执行程序 验证
root@topeet:/mnt/sdcard]# ./app /dev/device_test topeet &
de[root@topeet:/mnt/sdcard]# ./app /dev/device_test itopopen is okopen is error
这个就验证了 自旋锁 起作用了的,保护了 变量 flag
总结
这里简单介绍了自旋锁的应用场景,需要了解原理和使用api 即可。