初探RAG
源码
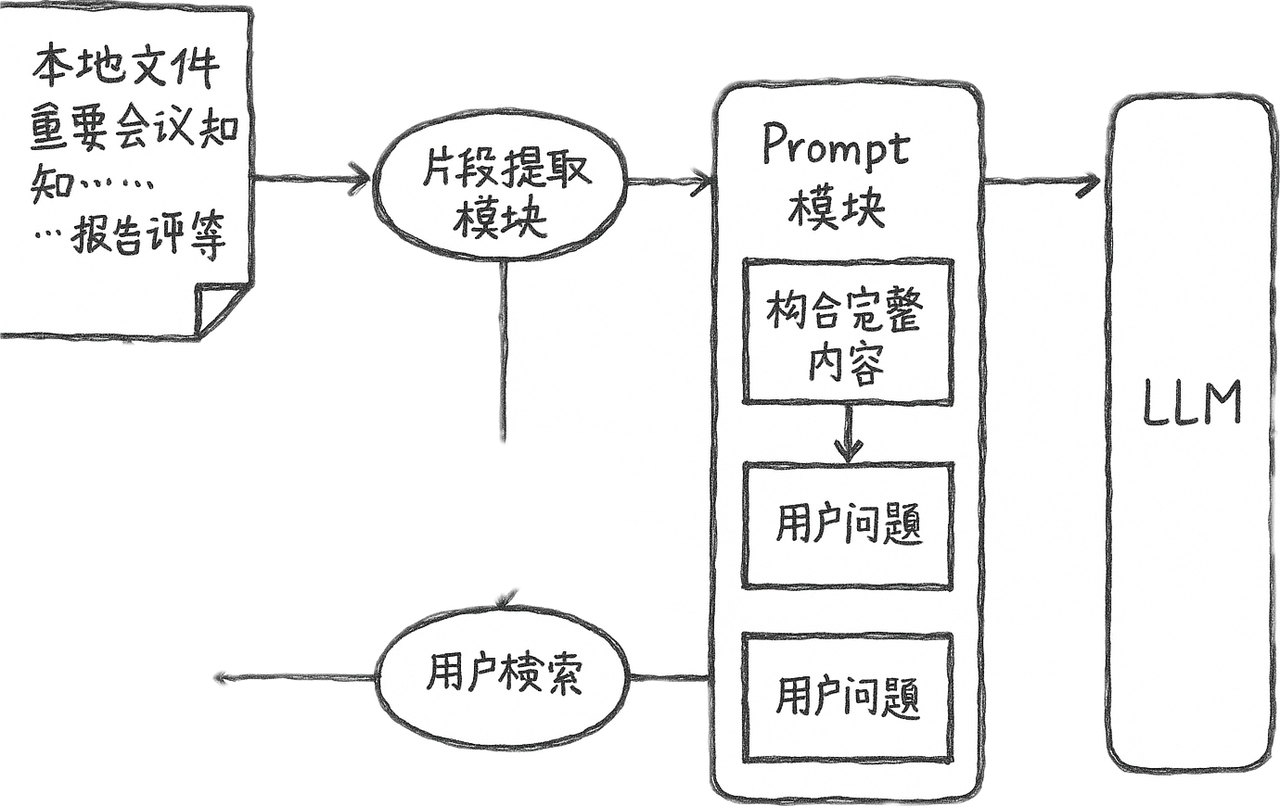
核心工作流程
- 读取文件的内容
- 将内容保存在向量数据库
- 检索向量数据库用户的问题
- 用户问题 + 上下文【向量数据】 => LLM
读取文件内容【pdf为例】
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainerclass PDFFileLoader():def __init__(self, file) -> None:self.paragraphs = self.extract_text_from_pdf(file)# i = 1# for para in self.paragraphs[:10]:# print(f"========= 第{i}段 ==========")# print(para+"\n")# i += 1def getParagraphs(self):return self.paragraphs################################# 文档的加载与切割 ############################def extract_text_from_pdf(self, filename, page_numbers=None):'''从 PDF 文件中(按指定页码)提取文字'''paragraphs = []buffer = ''full_text = ''# 提取全部文本for i, page_layout in enumerate(extract_pages(filename)):# 如果指定了页码范围,跳过范围外的页if page_numbers is not None and i not in page_numbers:continuefor element in page_layout:if isinstance(element, LTTextContainer):full_text += element.get_text() + '\n'# 段落分割lines = full_text.split('。\n')for text in lines:buffer = text.replace('\n', ' ')if buffer:paragraphs.append(buffer)buffer = ''row_count = 0if buffer:paragraphs.append(buffer)return paragraphs
向量数据
在保存到向量数据库的时候,需要对文件的内容处理。这可以使用OpenAI、以及开源的模型做处理。本文是用开源的模型。
# from openai import OpenAI
from langchain.embeddings import HuggingFaceBgeEmbeddings
import os
# 加载环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # 读取本地 .env 文件,里面定义了 OPENAI_API_KEY# client = OpenAI()# 加载中文embedding模型 开源模型
bge_embeddings = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-large-zh-v1.5")def get_embeddings(texts, model="text-embedding-3-small"):'''封装 OpenAI 的 Embedding 模型接口'''# print(texts)# print(model)'''open ai 提供的embedding 接口'''# data = client.embeddings.create(input=texts, model=model).data# return [x.embedding for x in data]'''huggingface 提供的embedding 接口'''data = bge_embeddings.embed_documents(texts)# print(data)return data
这样处理会得到一堆向量的数组。就可以入库了
import chromadb
from chromadb.config import Settingsclass MyVectorDBConnector:def __init__(self, collection_name, embedding_fn):chroma_client = chromadb.Client(Settings(allow_reset=True))# 为了演示,实际不需要每次 reset()chroma_client.reset()# 创建一个 collectionself.collection = chroma_client.get_or_create_collection(name=collection_name)self.embedding_fn = embedding_fndef add_documents(self, documents):'''向 collection 中添加文档与向量'''self.collection.add(embeddings=self.embedding_fn(documents), # 每个文档的向量documents=documents, # 文档的原文ids=[f"id{i}" for i in range(len(documents))] # 每个文档的 id)def search(self, query, top_n):'''检索向量数据库'''results = self.collection.query(query_embeddings=self.embedding_fn([query]),n_results=top_n)return results
结合LLM + RAG
import chromadb
from chromadb.config import Settingsclass MyVectorDBConnector:def __init__(self, collection_name, embedding_fn):chroma_client = chromadb.Client(Settings(allow_reset=True))# 为了演示,实际不需要每次 reset()chroma_client.reset()# 创建一个 collectionself.collection = chroma_client.get_or_create_collection(name=collection_name)self.embedding_fn = embedding_fndef add_documents(self, documents):'''向 collection 中添加文档与向量'''self.collection.add(embeddings=self.embedding_fn(documents), # 每个文档的向量documents=documents, # 文档的原文ids=[f"id{i}" for i in range(len(documents))] # 每个文档的 id)def search(self, query, top_n):'''检索向量数据库'''results = self.collection.query(query_embeddings=self.embedding_fn([query]),n_results=top_n)return results
以上就是初探RAG的代码。
参考:
Embedding模型的选择
RAG教程