排序算法详解笔记(二)
归并排序
#include <vector>
#include <iostream>
#include <algorithm> // For std::inplace_merge in optimization// Helper function to merge two sorted subarrays
void merge(std::vector<int>& arr, int left, int mid, int right) {int n1 = mid - left + 1;int n2 = right - mid;// Create temporary arraysstd::vector<int> L(n1);std::vector<int> R(n2);// Copy data to temp arrays L[] and R[]for (int i = 0; i < n1; ++i)L[i] = arr[left + i];for (int j = 0; j < n2; ++j)R[j] = arr[mid + 1 + j];// Merge the temp arrays back into arr[left..right]int i = 0; // Initial index of first subarrayint j = 0; // Initial index of second subarrayint k = left; // Initial index of merged subarraywhile (i < n1 && j < n2) {if (L[i] <= R[j]) {arr[k] = L[i];i++;} else {arr[k] = R[j];j++;}k++;}// Copy the remaining elements of L[], if there are anywhile (i < n1) {arr[k] = L[i];i++;k++;}// Copy the remaining elements of R[], if there are anywhile (j < n2) {arr[k] = R[j];j++;k++;}
}// Main function that sorts arr[left..right] using merge()
void mergeSortRecursive(std::vector<int>& arr, int left, int right) {if (left >= right) { // Base case: single element or empty arrayreturn;}int mid = left + (right - left) / 2; // Avoid potential overflowmergeSortRecursive(arr, left, mid);mergeSortRecursive(arr, mid + 1, right);merge(arr, left, mid, right);
}// Wrapper function
void mergeSort(std::vector<int>& arr) {if (arr.empty()) return;mergeSortRecursive(arr, 0, arr.size() - 1);
}// --- Example Usage ---
// int main() {
// std::vector<int> data = {12, 11, 13, 5, 6, 7};
// mergeSort(data);
// std::cout << "Sorted array: ";
// for (int x : data) std::cout << x << " ";
// std::cout << std::endl; // Output: Sorted array: 5 6 7 11 12 13
// return 0;
// }
缺点
- 空间复杂度高:标准的归并排序需要 O ( n ) O(n) O(n) 的额外空间来存储临时合并数组。
- 对于小数组,递归开销和合并操作的常数因子可能比插入排序等简单算法更大。
优化方案
- 原地归并(In-place Merge):尝试在 O ( 1 ) O(1) O(1) 额外空间内完成合并。C++ 标准库提供了
std::inplace_merge。虽然空间复杂度降低,但时间复杂度可能会增加,且实现复杂。 - 混合排序:对于小于某个阈值(例如 16 或 32 个元素)的小子数组,切换到插入排序,因为插入排序在小数据集上通常更快,且空间开销小。
- 迭代实现(自底向上):避免递归调用栈的开销,通过迭代的方式从小到大合并子数组。
边界问题
- 空数组:需要处理输入为空的情况(如
arr.empty()检查)。 - 单元素数组:递归的基准条件
if (left >= right)正确处理了这种情况,直接返回。 - 索引计算:计算
mid时使用left + (right - left) / 2可以防止left + right可能产生的整数溢出。确保left,mid,right索引在数组范围内。
快速排序
#include <vector>
#include <iostream>
#include <algorithm> // For std::swap, std::partition
#include <random> // For random pivot optimization// Partition function (using Lomuto partition scheme as an example)
int partition(std::vector<int>& arr, int low, int high) {int pivot = arr[high]; // Choose the last element as the pivotint i = (low - 1); // Index of smaller elementfor (int j = low; j <= high - 1; ++j) {// If current element is smaller than or equal to pivotif (arr[j] <= pivot) {i++; // Increment index of smaller elementstd::swap(arr[i], arr[j]);}}std::swap(arr[i + 1], arr[high]); // Place pivot in its correct positionreturn (i + 1); // Return the partition index
}// --- Optimization: Random Pivot ---
int partition_random(std::vector<int>& arr, int low, int high) {// Generate a random index between low and highstd::random_device rd;std::mt19937 gen(rd());std::uniform_int_distribution<> distrib(low, high);int randomIndex = distrib(gen);// Swap the random element with the last elementstd::swap(arr[randomIndex], arr[high]);// Use the standard partition logicreturn partition(arr, low, high);
}// --- Optimization: Three-way partition (for handling duplicates) ---
// Partitions arr[l..r] into three parts: < pivot, == pivot, > pivot
void partition3Way(std::vector<int>& arr, int l, int r, int& i, int& j) {if (r <= l) return;i = l; // arr[l..i-1] < pivotj = r; // arr[j+1..r] > pivotint p = l; // scan pointer arr[i..p-1] == pivotint pivot = arr[l]; // Choose first element as pivotwhile (p <= j) {if (arr[p] < pivot) {std::swap(arr[i++], arr[p++]);} else if (arr[p] > pivot) {std::swap(arr[p], arr[j--]);} else { // arr[p] == pivotp++;}}// Now arr[l..i-1] < v, arr[i..j] == v, arr[j+1..r] > v// 'i' is the start index of the equal part, 'j' is the end index
}// Main recursive function for Quick Sort
void quickSortRecursive(std::vector<int>& arr, int low, int high) {if (low < high) {// Choose a partition scheme:// int pi = partition(arr, low, high); // Standard Lomutoint pi = partition_random(arr, low, high); // Randomized PivotquickSortRecursive(arr, low, pi - 1); // Sort elements before partitionquickSortRecursive(arr, pi + 1, high); // Sort elements after partition// --- Using 3-way partition ---// int i, j;// partition3Way(arr, low, high, i, j);// quickSortRecursive(arr, low, i - 1);// quickSortRecursive(arr, j + 1, high);}
}// Wrapper function
void quickSort(std::vector<int>& arr) {if (arr.empty()) return;quickSortRecursive(arr, 0, arr.size() - 1);
}// --- Example Usage ---
// int main() {
// std::vector<int> data = {10, 7, 8, 9, 1, 5};
// quickSort(data);
// std::cout << "Sorted array: ";
// for (int x : data) std::cout << x << " ";
// std::cout << std::endl; // Output: Sorted array: 1 5 7 8 9 10
// return 0;
// }
缺点
- 最坏情况性能:当 pivot 选择不佳(如每次都选到最大或最小值)时,时间复杂度退化到 O ( n 2 ) O(n^2) O(n2),特别是在输入已排序或反向排序时。
- 递归深度:在最坏情况下,递归深度可达 O ( n ) O(n) O(n),可能导致栈溢出。
- 不稳定排序:相等元素的相对顺序可能改变。
优化方案
- 随机化 Pivot:如
partition_random所示,随机选择 pivot 可以大大降低出现最坏情况的概率,使期望时间复杂度为 O ( n log n ) O(n \log n) O(nlogn)。 - 三数取中(Median-of-Three):选择数组首、中、尾三个元素的中位数作为 pivot,能更好地避免极端 pivot。
- 切换到插入排序:对于小子数组(例如元素少于 10-20 个),递归调用切换到插入排序可以提高效率,因为它在小数据集上常数因子小。
- 三向切分(3-Way Partitioning):如
partition3Way所示,特别适用于处理包含大量重复元素的数组,将数组分为小于、等于、大于 pivot 的三部分,可以显著提高效率。 - 尾递归优化:对两次递归调用中的较大子数组进行递归,较小子数组进行尾递归(或迭代),可以限制栈深度至 O ( log n ) O(\log n) O(logn)。
边界问题
- 空数组或单元素数组:基准条件
if (low < high)处理了这种情况。 - 分区索引:确保分区函数返回的索引
pi是有效的,并且递归调用quickSortRecursive(arr, low, pi - 1)和quickSortRecursive(arr, pi + 1, high)的范围是正确的,避免无限循环或越界。 - 重复元素:标准的 Lomuto 或 Hoare 分区在处理大量重复元素时可能效率不高或导致不平衡分区。三向切分是更好的选择。
堆排序
#include <vector>
#include <iostream>
#include <algorithm> // For std::swap, std::make_heap, std::pop_heap, std::sort_heap// Function to heapify a subtree rooted with node i which is an index in arr[]
// n is size of heap
void heapify(std::vector<int>& arr, int n, int i) {int largest = i; // Initialize largest as rootint left = 2 * i + 1; // left child indexint right = 2 * i + 2; // right child index// If left child is larger than rootif (left < n && arr[left] > arr[largest])largest = left;// If right child is larger than largest so farif (right < n && arr[right] > arr[largest])largest = right;// If largest is not rootif (largest != i) {std::swap(arr[i], arr[largest]);// Recursively heapify the affected sub-treeheapify(arr, n, largest);}
}// Main function to do heap sort
void heapSort(std::vector<int>& arr) {int n = arr.size();if (n <= 1) return; // Handle empty or single-element array// Build heap (rearrange array) - O(n)// Start from the last non-leaf node and heapify downfor (int i = n / 2 - 1; i >= 0; i--)heapify(arr, n, i);// One by one extract an element from heap - O(n log n)for (int i = n - 1; i > 0; i--) {// Move current root (max element) to endstd::swap(arr[0], arr[i]);// call max heapify on the reduced heap// The size of the heap decreases by 1 in each iterationheapify(arr, i, 0);}
}// --- Alternative using C++ Standard Library ---
void heapSortSTL(std::vector<int>& arr) {if (arr.size() <= 1) return;// Build a max heapstd::make_heap(arr.begin(), arr.end());// Repeatedly extract the max element (moves it to the end)// and restores heap property on the remaining range.std::sort_heap(arr.begin(), arr.end());
}// --- Example Usage ---
// int main() {
// std::vector<int> data = {12, 11, 13, 5, 6, 7};
// // heapSort(data); // Using custom implementation
// heapSortSTL(data); // Using STL
// std::cout << "Sorted array: ";
// for (int x : data) std::cout << x << " ";
// std::cout << std::endl; // Output: Sorted array: 5 6 7 11 12 13
// return 0;
// }
缺点
-
常数因子较大:虽然最坏、平均和最好时间复杂度都是 O ( n log n ) O(n \log n) O(nlogn),但实际运行中的比较和交换次数可能比快速排序(平均情况)多,常数因子更大。
-
不稳定排序:不保证相等元素的原始相对顺序。
-
缓存不友好:堆的操作(特别是
heapify)涉及跳跃式的内存访问(访问父节点和子节点),这可能导致缓存未命中率较高,尤其是在大数据集上。
优化方案
-
使用 C++ STL:
std::make_heap,std::pop_heap,std::sort_heap通常经过高度优化,可能比手动实现更快。 -
底层优化
heapify:可以通过减少比较次数或优化交换逻辑来微调heapify函数,但这通常收益有限。 -
d 叉堆(d-ary heap):使用 d > 2 的堆可以减少堆的高度(变为 log d n \log_d n logdn),可能改善缓存性能,但会增加每个节点的孩子数量,使得
heapify中的比较次数增多。需要权衡。
边界问题
-
空数组或单元素数组:需要显式检查并直接返回,因为
n / 2 - 1对于空数组或单元素数组会是负数或无效索引。 -
索引计算:确保子节点索引
2 * i + 1和2 * i + 2不会越界(left < n和right < n检查)。 -
Heapify 范围:在排序阶段,调用
heapify(arr, i, 0)时,第二个参数i表示当前堆的大小,必须正确传递,否则会访问已排序部分的元素。
内存访问问题
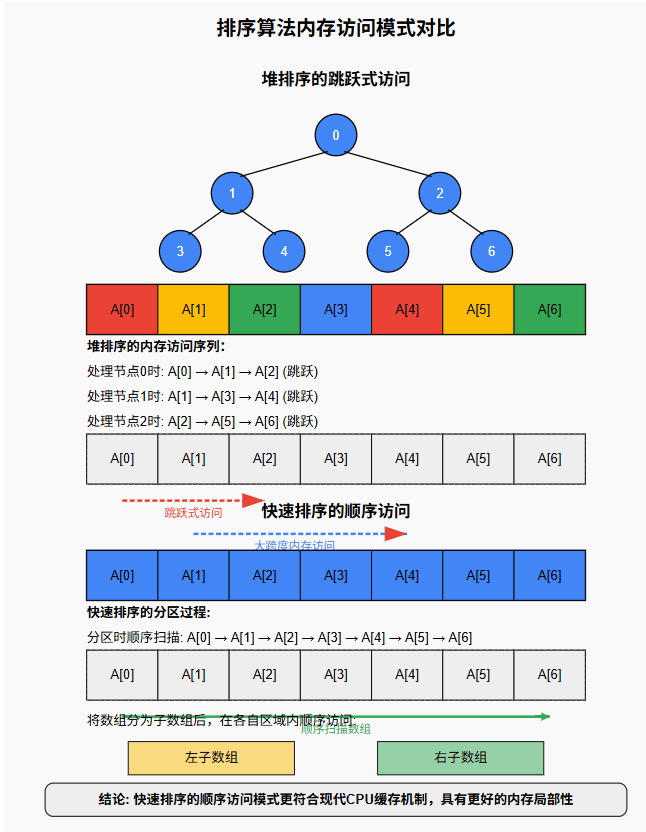
快速排序的内存局部性优势
-
顺序访问模式:
- 快速排序在分区过程中主要是从左到右顺序扫描数组
- 这种顺序访问模式更符合现代计算机的缓存预取机制
-
分治策略的局部性:
- 快速排序将数组分割成子数组后,在每个子数组内完成所有操作
- 这意味着数据访问集中在一个较小的内存区域,提高了缓存命中率
-
内存引用距离小:
- 在处理一个分区时,快速排序操作的元素通常彼此相邻或相距不远
- 这与堆排序中父子节点间的大跨度跳跃形成鲜明对比
堆排序的内存局部性劣势
-
跳跃式访问:
- 堆排序基于完全二叉树,父节点i的子节点在2i+1和2i+2
- 这种访问模式导致大范围的内存跳跃
-
缓存未命中率高:
- 当处理大型数组时,堆的不同层级间的元素可能相距很远
- 这会导致频繁的缓存未命中,增加内存访问延迟
-
访问模式不可预测:
- 堆排序中的元素交换和堆调整涉及的位置不容易被硬件预测
- 这降低了预取机制的效率
性能影响
尽管堆排序和快速排序都具有O(n log n)的平均时间复杂度,但在实际应用中:
-
快速排序通常更快:
- 对于相同规模的随机数据,快速排序常常比堆排序快2-3倍
- 这主要是因为更好的内存局部性和更简单的内部循环
-
随着数据规模增大,差距可能更显著:
- 当数据无法完全装入CPU缓存时,内存局部性的影响变得更为重要
- 在这种情况下,快速排序的优势更加明显
代码示例对比
如果我们比较快速排序和堆排序的核心操作:
// 快速排序的分区操作 - 顺序访问
int partition(int arr[], int low, int high) {int pivot = arr[high];int i = low - 1;for (int j = low; j < high; j++) { // 顺序扫描if (arr[j] <= pivot) {i++;swap(arr[i], arr[j]);}}swap(arr[i + 1], arr[high]);return i + 1;
}// 堆排序的堆调整操作 - 跳跃访问
void heapify(int arr[], int n, int i) {int largest = i;int left = 2 * i + 1; // 跳跃访问int right = 2 * i + 2; // 跳跃访问if (left < n && arr[left] > arr[largest])largest = left;if (right < n && arr[right] > arr[largest])largest = right;if (largest != i) {swap(arr[i], arr[largest]);heapify(arr, n, largest); // 递归可能导致更大的跳跃}
}
实际应用考量
-
标准库实现选择:
- 许多语言的标准库排序实现选择快速排序或其变体,而非堆排序
- 例如,C++的
std::sort通常是快速排序的一种变体
-
适用场景区别:
- 堆排序在需要稳定的O(n log n)性能时有优势(最坏情况也是O(n log n))
- 快速排序在平均情况下更快,但存在O(n²)最坏情况的风险
尾递归
什么是尾递归(Tail Recursion)?
尾递归是一种特殊的递归形式。当一个函数的最后一个动作是调用自身(递归调用),并且该调用的返回值直接被当前函数返回,没有任何后续计算或操作时,这个调用就称为尾递归调用。这个函数就是尾递归函数。
关键特征:
-
递归调用是函数的最后一步。
-
递归调用的结果直接返回,不参与任何其他计算。
示例:
非尾递归(计算阶乘):
int factorial_non_tail(int n) {if (n <= 1) {return 1;} else {// *** 不是尾递归 ***// 递归调用 factorial_non_tail(n - 1) 后,// 还需要执行乘法 n * ... 操作return n * factorial_non_tail(n - 1);}
}
在 n * factorial_non_tail(n - 1) 中,递归调用 factorial_non_tail(n - 1) 返回后,还需要将结果与 n 相乘,所以这不是尾递归。
尾递归(计算阶乘,使用辅助函数):
// 辅助函数,带有累加器 accumulator
int factorial_tail_helper(int n, int accumulator) {if (n <= 1) {return accumulator; // 基本情况:返回累加结果} else {// *** 是尾递归 ***// 递归调用是最后一步,其返回值直接被返回return factorial_tail_helper(n - 1, n * accumulator);}
}// 主函数
int factorial_tail(int n) {return factorial_tail_helper(n, 1); // 初始累加器为 1
}
在 factorial_tail_helper 中,factorial_tail_helper(n - 1, n * accumulator) 是函数的最后一个操作,它的返回值被直接返回。
尾递归优化(Tail Call Optimization - TCO)
尾递归的主要优势在于编译器可以对其进行尾递归优化 (TCO)。
- 原理:由于尾递归调用的结果直接返回,当前函数的调用帧(call frame,包含局部变量、返回地址等信息)在进行尾递归调用之前就不再需要了。编译器可以复用当前的栈帧,而不是创建新的栈帧。
- 效果:优化后的尾递归函数在执行时,其行为类似于迭代(循环)。它不会消耗额外的栈空间,避免了普通递归可能导致的栈溢出问题(Stack Overflow)。
- 转换:编译器(如果支持并启用 TCO)会将尾递归调用转换为一个简单的**跳转(goto)**指令,跳转回函数开头,并更新函数参数。
示例(尾递归阶乘优化后的伪代码):
factorial_tail_helper(n, accumulator):
start:if (n <= 1) {return accumulator;} else {// 更新参数accumulator = n * accumulator;n = n - 1;// 跳转回函数开头,而不是创建新栈帧goto start;}
这实际上等价于一个循环:
int factorial_iterative(int n) {int accumulator = 1;while (n > 1) {accumulator *= n;n--;}return accumulator;
}
优点:
- 避免栈溢出:对于深度递归,可以像迭代一样运行,不受调用栈深度限制。
- 效率提升:减少了函数调用和返回的开销(创建和销毁栈帧)。
限制和注意事项:
- 编译器支持:TCO 是一种优化,不是 C++ 标准强制要求的。GCC、Clang 等主流编译器在开启优化选项(如
-O2,-O3)时通常会执行 TCO。但 Visual Studio (MSVC) 对 C++ 的 TCO 支持有限(尤其是在 x64 架构下)。 - 必须是严格的尾调用:如上所述,递归调用必须是函数的最后一步,且结果直接返回。任何后续操作(如
+ 1,* n)都会阻止 TCO。 - 调试困难:优化后的代码可能没有清晰的调用栈信息,使得调试递归逻辑变得困难。
在实践中,虽然尾递归是一个优雅的概念,但在 C++ 中依赖 TCO 需要谨慎,要了解目标编译器的行为。如果担心栈溢出或追求极致性能,显式地将递归转换为迭代通常是更可靠的方法。
模拟递归栈
系统栈的作用
栈帧的组成
每次函数调用都会在系统栈上创建一个新的栈帧,包含:
- 局部变量
- 返回地址
- 参数值
- 函数执行的上下文信息
栈的LIFO特性
栈遵循"后进先出"(Last-In-First-Out)原则,这与递归的执行顺序直接相关。
递归的栈模拟过程
递归转换为栈操作
显式栈的创建
使用数据结构(如数组或链表)模拟系统栈的行为。
递归状态的保存
将递归函数的状态信息封装为对象或结构体压入栈中。
#include <iostream>
#include <vector>
#include <stack>
#include <string>// 用于展示栈帧的结构体
struct StackFrame {int left;int right;std::string function;int depth;
};// 打印当前栈的状态
void printStack(const std::stack<StackFrame>& stackCopy, const std::string& title) {std::cout << "\n===== " << title << " =====" << std::endl;std::cout << "栈底";std::stack<StackFrame> tempStack = stackCopy;std::vector<StackFrame> frames;while (!tempStack.empty()) {frames.push_back(tempStack.top());tempStack.pop();}for (int i = frames.size() - 1; i >= 0; i--) {std::cout << " <- [" << frames[i].function << "(" << frames[i].left << "," << frames[i].right << ") 深度:" << frames[i].depth << "]";}std::cout << " <- 栈顶" << std::endl;std::cout << "栈深度: " << frames.size() << std::endl;
}// 模拟快速排序的递归栈
void simulateQuicksortStack(int arraySize) {std::cout << "\n\n模拟快速排序递归栈 (数组大小: " << arraySize << ")" << std::endl;std::stack<StackFrame> recursionStack;int maxDepth = 0;// 初始调用recursionStack.push({0, arraySize - 1, "quicksort", 1});maxDepth = 1;printStack(recursionStack, "初始状态");// 模拟递归过程while (!recursionStack.empty()) {StackFrame current = recursionStack.top();recursionStack.pop();// 基本情况if (current.left >= current.right) {printStack(recursionStack, "处理基本情况后");continue;}// 假设我们选择中间元素作为pivot并完成分区int mid = (current.left + current.right) / 2;// 模拟最坏情况:极度不平衡的分区(如已排序数组)// 右侧分区 - 会先处理 (栈是LIFO)recursionStack.push({mid + 1, current.right, "quicksort", current.depth + 1});// 左侧分区recursionStack.push({current.left, mid, "quicksort", current.depth + 1});if (current.depth + 1 > maxDepth) {maxDepth = current.depth + 1;}printStack(recursionStack, "分区后");}std::cout << "\n快速排序最大栈深度: " << maxDepth << std::endl;std::cout << "最坏情况下空间复杂度: O(n),平均情况: O(log n)" << std::endl;
}// 归并排序中的合并操作(简化版)
void merge(std::vector<int>& arr, int left, int mid, int right) {// 实际合并操作(简化表示)std::cout << " 合并区间 [" << left << "," << mid << "] 和 [" << (mid + 1) << "," << right << "]" << std::endl;
}// 模拟归并排序的递归栈
void simulateMergesortStack(int arraySize) {std::cout << "\n\n模拟归并排序递归栈 (数组大小: " << arraySize << ")" << std::endl;std::stack<StackFrame> recursionStack;std::vector<int> dummyArray(arraySize, 0); // 用于merge演示int maxDepth = 0;// 初始调用recursionStack.push({0, arraySize - 1, "mergesort", 1});maxDepth = 1;printStack(recursionStack, "初始状态");// 模拟递归过程while (!recursionStack.empty()) {StackFrame current = recursionStack.top();recursionStack.pop();// 基本情况if (current.left >= current.right) {printStack(recursionStack, "处理基本情况后");continue;}int mid = (current.left + current.right) / 2;// 注意:归并排序与快排不同,需要先处理完所有分割,再执行合并// 这意味着栈帧包含了"待合并"的信息// 合并操作(在子问题解决后)StackFrame mergeFrame = {current.left, current.right, "merge", current.depth};mergeFrame.depth = current.depth;// 右侧分区StackFrame rightFrame = {mid + 1, current.right, "mergesort", current.depth + 1};// 左侧分区StackFrame leftFrame = {current.left, mid, "mergesort", current.depth + 1};// 注意入栈顺序:先合并,再右子数组,最后左子数组(这样左子数组会先处理)recursionStack.push(mergeFrame);recursionStack.push(rightFrame);recursionStack.push(leftFrame);if (current.depth + 1 > maxDepth) {maxDepth = current.depth + 1;}printStack(recursionStack, "分割后");}std::cout << "\n归并排序最大栈深度: " << maxDepth << std::endl;std::cout << "空间复杂度: O(log n) 用于递归栈,额外O(n)用于合并操作" << std::endl;
}// 模拟迭代式归并排序
void simulateIterativeMergesort(int arraySize) {std::cout << "\n\n模拟迭代式归并排序 (数组大小: " << arraySize << ")" << std::endl;std::vector<int> dummyArray(arraySize, 0); // 用于merge演示// 自底向上归并for (int size = 1; size < arraySize; size *= 2) {std::cout << "\n合并大小为 " << size << " 的子数组:" << std::endl;for (int left = 0; left < arraySize - size; left += 2 * size) {int mid = left + size - 1;int right = std::min(left + 2 * size - 1, arraySize - 1);merge(dummyArray, left, mid, right);}}std::cout << "\n迭代式归并排序使用O(1)栈空间和O(n)辅助数组空间" << std::endl;
}int main() {// 模拟一个小数组用于演示int smallSize = 8;simulateQuicksortStack(smallSize);simulateMergesortStack(smallSize);simulateIterativeMergesort(smallSize);// 模拟一个较大的数组(仅显示栈深度)int largeSize = 1000000000; // 10亿元素std::cout << "\n\n===== 大数据集分析 =====" << std::endl;std::cout << "数组大小: " << largeSize << " 元素" << std::endl;std::cout << "快速排序最坏情况栈深度: " << largeSize << " (如果数组已排序)" << std::endl;std::cout << "快速排序平均情况栈深度: 约 " << static_cast<int>(log2(largeSize)) << std::endl;std::cout << "归并排序栈深度: 约 " << static_cast<int>(log2(largeSize)) << std::endl;std::cout << "如果每个栈帧使用100字节,最大栈空间需求: " << static_cast<int>(log2(largeSize)) * 100 << " 字节(约 " << (static_cast<int>(log2(largeSize)) * 100) / 1024 << " KB)" << std::endl;return 0;
}
附录
测试代码
#include <iostream>
#include <vector>
#include <algorithm>
#include <random>
#include <chrono>
#include <iomanip>
#include <functional>using namespace std;
using namespace std::chrono;// ================ 归并排序及其优化 ================// 标准归并排序的合并操作 - 需要额外空间
void merge(vector<int>& arr, int left, int mid, int right) {int n1 = mid - left + 1;int n2 = right - mid;// 创建临时数组vector<int> L(n1), R(n2);// 复制数据到临时数组for (int i = 0; i < n1; i++)L[i] = arr[left + i];for (int j = 0; j < n2; j++)R[j] = arr[mid + 1 + j];// 合并临时数组int i = 0, j = 0, k = left;while (i < n1 && j < n2) {if (L[i] <= R[j]) {arr[k] = L[i];i++;} else {arr[k] = R[j];j++;}k++;}// 复制剩余元素while (i < n1) {arr[k] = L[i];i++;k++;}while (j < n2) {arr[k] = R[j];j++;k++;}
}// 标准归并排序
void mergeSort(vector<int>& arr, int left, int right) {// 边界条件处理:空数组或单元素数组if (left >= right) return;int mid = left + (right - left) / 2;mergeSort(arr, left, mid);mergeSort(arr, mid + 1, right);merge(arr, left, mid, right);
}// 优化1:小数组使用插入排序
void insertionSort(vector<int>& arr, int left, int right) {for (int i = left + 1; i <= right; i++) {int key = arr[i];int j = i - 1;while (j >= left && arr[j] > key) {arr[j + 1] = arr[j];j--;}arr[j + 1] = key;}
}// 优化2:混合归并排序(小数组使用插入排序)
void hybridMergeSort(vector<int>& arr, int left, int right, int threshold = 10) {if (right - left <= threshold) {insertionSort(arr, left, right);return;}int mid = left + (right - left) / 2;hybridMergeSort(arr, left, mid, threshold);hybridMergeSort(arr, mid + 1, right, threshold);merge(arr, left, mid, right);
}// 优化3:原地归并排序(减少空间使用,但增加时间复杂度)
void mergeInPlace(vector<int>& arr, int start, int mid, int end) {int start2 = mid + 1;// 如果已经有序if (arr[mid] <= arr[start2]) {return;}// 合并两个有序子数组while (start <= mid && start2 <= end) {// 如果第一个子数组的元素小于或等于第二个子数组的元素if (arr[start] <= arr[start2]) {start++;} else {int value = arr[start2];int index = start2;// 将第二个子数组的元素移动到正确位置while (index != start) {arr[index] = arr[index - 1];index--;}arr[start] = value;// 更新位置start++;mid++;start2++;}}
}void mergeSortInPlace(vector<int>& arr, int left, int right) {if (left < right) {int mid = left + (right - left) / 2;mergeSortInPlace(arr, left, mid);mergeSortInPlace(arr, mid + 1, right);mergeInPlace(arr, left, mid, right);}
}// ================ 快速排序及其优化 ================// 标准分区函数
int partition(vector<int>& arr, int low, int high) {// 使用最后一个元素作为pivotint pivot = arr[high];int i = low - 1;for (int j = low; j < high; j++) {if (arr[j] <= pivot) {i++;swap(arr[i], arr[j]);}}swap(arr[i + 1], arr[high]);return i + 1;
}// 标准快速排序
void quickSort(vector<int>& arr, int low, int high) {// 边界条件处理if (low >= high) return;int pi = partition(arr, low, high);quickSort(arr, low, pi - 1);quickSort(arr, pi + 1, high);
}// 优化1:三数取中选择pivot
int medianOfThree(vector<int>& arr, int low, int high) {int mid = low + (high - low) / 2;// 对三个元素排序if (arr[low] > arr[mid])swap(arr[low], arr[mid]);if (arr[low] > arr[high])swap(arr[low], arr[high]);if (arr[mid] > arr[high])swap(arr[mid], arr[high]);// 将中值放到倒数第二个位置swap(arr[mid], arr[high - 1]);return arr[high - 1];
}int partitionMedian(vector<int>& arr, int low, int high) {// 使用三数取中法选择pivotint pivot = medianOfThree(arr, low, high);int i = low;int j = high - 1;while (true) {while (arr[++i] < pivot);while (arr[--j] > pivot);if (i >= j)break;swap(arr[i], arr[j]);}// 将pivot放回正确位置swap(arr[i], arr[high - 1]);return i;
}// 优化2:混合快速排序(小数组使用插入排序)
void hybridQuickSort(vector<int>& arr, int low, int high, int threshold = 10) {if (high - low <= threshold) {insertionSort(arr, low, high);return;}int pi = partitionMedian(arr, low, high);hybridQuickSort(arr, low, pi - 1, threshold);hybridQuickSort(arr, pi + 1, high, threshold);
}// 优化3:随机化选择pivot
int randomizedPartition(vector<int>& arr, int low, int high) {// 随机选择pivotint random = low + rand() % (high - low + 1);swap(arr[random], arr[high]);return partition(arr, low, high);
}void randomizedQuickSort(vector<int>& arr, int low, int high) {if (low < high) {int pi = randomizedPartition(arr, low, high);randomizedQuickSort(arr, low, pi - 1);randomizedQuickSort(arr, pi + 1, high);}
}// 优化4:三向分区处理重复元素
void threeWayQuickSort(vector<int>& arr, int low, int high) {if (low >= high) return;// 随机选择pivotint random = low + rand() % (high - low + 1);swap(arr[random], arr[low]);int pivot = arr[low];int lt = low; // 小于pivot的元素右边界int gt = high; // 大于pivot的元素左边界int i = low + 1; // 当前处理的元素while (i <= gt) {if (arr[i] < pivot) {swap(arr[lt], arr[i]);lt++;i++;} else if (arr[i] > pivot) {swap(arr[i], arr[gt]);gt--;} else {i++;}}// 递归处理小于和大于pivot的部分threeWayQuickSort(arr, low, lt - 1);threeWayQuickSort(arr, gt + 1, high);
}// ================ 堆排序及其优化 ================// 堆调整函数
void heapify(vector<int>& arr, int n, int i) {int largest = i;int left = 2 * i + 1;int right = 2 * i + 2;if (left < n && arr[left] > arr[largest])largest = left;if (right < n && arr[right] > arr[largest])largest = right;if (largest != i) {swap(arr[i], arr[largest]);heapify(arr, n, largest);}
}// 标准堆排序
void heapSort(vector<int>& arr) {int n = arr.size();// 构建最大堆for (int i = n / 2 - 1; i >= 0; i--)heapify(arr, n, i);// 逐个提取元素for (int i = n - 1; i > 0; i--) {swap(arr[0], arr[i]);heapify(arr, i, 0);}
}// 优化1:非递归堆调整
void heapifyIterative(vector<int>& arr, int n, int i) {int largest = i;int index = i;while (true) {int left = 2 * index + 1;int right = 2 * index + 2;if (left < n && arr[left] > arr[largest])largest = left;if (right < n && arr[right] > arr[largest])largest = right;if (largest == index)break;swap(arr[index], arr[largest]);index = largest;}
}// 优化2:自底向上构建堆(更高效)
void buildHeapBottomUp(vector<int>& arr) {int n = arr.size();// 从最后一个非叶节点开始向上调整for (int i = n / 2 - 1; i >= 0; i--)heapifyIterative(arr, n, i);
}void optimizedHeapSort(vector<int>& arr) {int n = arr.size();// 使用自底向上的方法构建堆buildHeapBottomUp(arr);// 逐个提取元素for (int i = n - 1; i > 0; i--) {swap(arr[0], arr[i]);heapifyIterative(arr, i, 0);}
}// ================ 内存访问模式演示 ================// 测量不同算法的缓存行为
void analyzeCacheBehavior() {const int SIZE = 1000000; // 大数组以突显缓存效果vector<int> data(SIZE);// 填充随机数据random_device rd;mt19937 gen(rd());uniform_int_distribution<> dis(1, SIZE);for (int i = 0; i < SIZE; i++) {data[i] = dis(gen);}cout << "内存访问模式分析 (大数组大小: " << SIZE << ")" << endl;cout << "------------------------------------------------" << endl;// 测量排序算法的执行时间vector<pair<string, function<void(vector<int>&)>>> sortingAlgorithms = {{"归并排序", [](vector<int>& arr) { mergeSort(arr, 0, arr.size() - 1); }},{"快速排序", [](vector<int>& arr) { quickSort(arr, 0, arr.size() - 1); }},{"堆排序", heapSort},{"优化归并排序", [](vector<int>& arr) { hybridMergeSort(arr, 0, arr.size() - 1); }},{"优化快速排序", [](vector<int>& arr) { hybridQuickSort(arr, 0, arr.size() - 1); }},{"三向快速排序", [](vector<int>& arr) { threeWayQuickSort(arr, 0, arr.size() - 1); }},{"优化堆排序", optimizedHeapSort}};for (const auto& algorithm : sortingAlgorithms) {vector<int> testData = data; // 复制原始数据auto start = high_resolution_clock::now();algorithm.second(testData);auto end = high_resolution_clock::now();duration<double, milli> time_ms = end - start;cout << setw(15) << algorithm.first << ": " << fixed << setprecision(2) << time_ms.count() << " ms" << endl;}// 分析不同数据分布对内存访问的影响cout << "\n不同数据分布的影响:" << endl;cout << "------------------------------------------------" << endl;// 创建不同分布的数据vector<pair<string, vector<int>>> distributions;// 随机分布distributions.push_back({"随机数据", data});// 已排序数据vector<int> sortedData = data;sort(sortedData.begin(), sortedData.end());distributions.push_back({"已排序数据", sortedData});// 逆序数据vector<int> reversedData = sortedData;reverse(reversedData.begin(), reversedData.end());distributions.push_back({"逆序数据", reversedData});// 大量重复数据vector<int> duplicateData(SIZE);uniform_int_distribution<> limitedDis(1, SIZE / 100);for (int i = 0; i < SIZE; i++) {duplicateData[i] = limitedDis(gen);}distributions.push_back({"重复数据", duplicateData});// 测试快速排序和堆排序在不同数据分布下的性能for (const auto& dist : distributions) {cout << "\n" << dist.first << ":" << endl;// 测试快速排序vector<int> testData = dist.second;auto start = high_resolution_clock::now();hybridQuickSort(testData, 0, testData.size() - 1);auto end = high_resolution_clock::now();duration<double, milli> quickTime = end - start;// 测试堆排序testData = dist.second;start = high_resolution_clock::now();optimizedHeapSort(testData);end = high_resolution_clock::now();duration<double, milli> heapTime = end - start;cout << setw(15) << "快速排序" << ": " << fixed << setprecision(2) << quickTime.count() << " ms" << endl;cout << setw(15) << "堆排序" << ": " << fixed << setprecision(2) << heapTime.count() << " ms" << endl;}
}// ================ 主函数和测试 ================// 验证排序算法是否正确
bool isSorted(const vector<int>& arr) {for (size_t i = 1; i < arr.size(); i++) {if (arr[i] < arr[i-1]) return false;}return true;
}// 测试排序算法的正确性
void testSortingCorrectness() {const int SIZE = 1000;vector<int> data(SIZE);// 填充随机数据random_device rd;mt19937 gen(rd());uniform_int_distribution<> dis(1, SIZE);for (int i = 0; i < SIZE; i++) {data[i] = dis(gen);}// 测试所有排序算法vector<pair<string, function<void(vector<int>&)>>> sortingAlgorithms = {{"归并排序", [](vector<int>& arr) { mergeSort(arr, 0, arr.size() - 1); }},{"原地归并排序", [](vector<int>& arr) { mergeSortInPlace(arr, 0, arr.size() - 1); }},{"混合归并排序", [](vector<int>& arr) { hybridMergeSort(arr, 0, arr.size() - 1); }},{"快速排序", [](vector<int>& arr) { quickSort(arr, 0, arr.size() - 1); }},{"优化快速排序", [](vector<int>& arr) { hybridQuickSort(arr, 0, arr.size() - 1); }},{"随机化快速排序", [](vector<int>& arr) { randomizedQuickSort(arr, 0, arr.size() - 1); }},{"三向快速排序", [](vector<int>& arr) { threeWayQuickSort(arr, 0, arr.size() - 1); }},{"堆排序", heapSort},{"优化堆排序", optimizedHeapSort}};cout << "排序算法正确性验证" << endl;cout << "------------------------------------------------" << endl;for (const auto& algorithm : sortingAlgorithms) {vector<int> testData = data; // 复制原始数据algorithm.second(testData);bool correct = isSorted(testData);cout << setw(15) << algorithm.first << ": " << (correct ? "正确" : "错误") << endl;}
}int main() {// 设置随机种子srand(time(nullptr));cout << "排序算法分析与优化" << endl;cout << "================================================" << endl;// 测试排序算法的正确性testSortingCorrectness();cout << "\n======================\n" << endl;// 分析内存访问模式analyzeCacheBehavior();return 0;
}