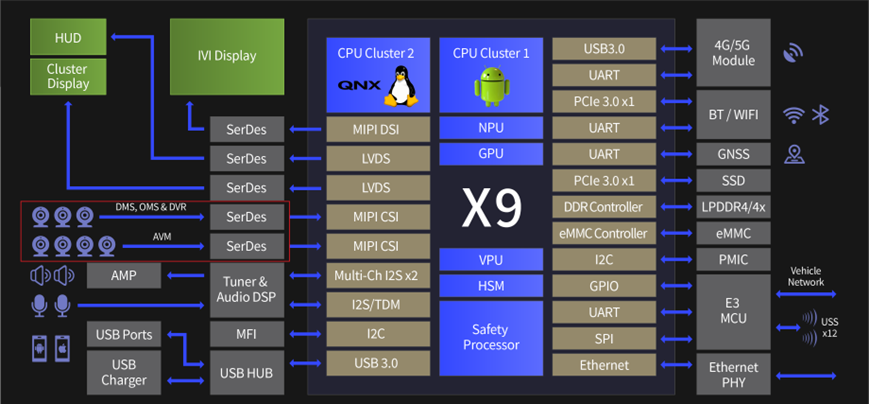
概括
我们介绍了 LLM 的各种缩放定律,研究了模型损失如何随着训练数据和参数数量的增加而变化。讨论包括对用于解释 LLM 缩放定律的 IsoLoss 轮廓和 IsoFLOPs 切片的解释,从而为优化计算资源提供了见解。
最后,我们讨论了 FLOP 和 FLOPS 的概念,它们分别衡量计算量和速度。以 GPT-4 或 Llama3 为例,我们阐明了训练 LLM 所涉及的复杂性。在我们的下一篇博客文章中,我们将探讨使用模型并行或数据并行等技术以及微调 LLM 的缩放定律来大规模训练 LLM 的策略,从而进一步深入了解高效的大规模训练技术。
目录:
- 缩放定律简介
- OpenAI 和 DeepMind 的实证
- Sample-Efficient LLMs
- Appendix
一 缩放定律
论文:《Scaling Laws for Neural Language Models》
https://arxiv.org/pdf/2001.08361
各大云服务提供商和众多公司正在大力投资收购数十万个 GPU 集群并利用海量训练数据来开发大型语言模型 (LLM),这已不足为奇。为什么模型越大越好?对于 LLM 而言,下一个 token(1 个 token 约为 0.75 个单词)预测的丢失是可预测且平稳的。事实证明,您只需要知道两个关键变量即可估计其准确性:
模型中的参数总数 (N) 和用于训练模型的文本 token 的大小 (D)。
参数数量反映了模型学习和表示数据中复杂关系的能力,而训练数据量则使模型能够从更多种类的示例和上下文中学习。
仅使用这两个变量(即 N 和 D),我们就可以预测 LLM 在下一个标记预测任务中的损失。随着我们在更多数据上训练更大的模型,我们继续看到准确性的提高。然而,Transformer 的神经网络架构在过去 7 年中进行了适度修改。我们希望未来的研究能够提出更优化的架构,因为 LLM 以耗能和耗数据而闻名。
LLM 的缩放定律揭示了模型质量如何随着其规模、训练数据量和计算资源的增加而变化。这些见解对于应对训练大型模型的复杂性以及做出明智的资源分配决策至关重要。
因此,了解这些扩展规律对于优化 LLM 的开发和部署是必需的,以确保有效利用资源来实现所需的性能水平。
此外,过度拟合的风险与模型大小与数据集大小的比例密切相关,建议 D ≥ 5 x 10³ N^(0.74) 以避免模型过度拟合(参见 OpenAI论文中的公式 4.4 )。训练曲线往往遵循可预测的幂律模式,允许根据当前的训练进度粗略预测未来的表现。
二 OpenAI 和 DeepMind 的实证实验
从根本上说,研究人员正在试图回答 LLM 缩放定律的问题:
在以 FLOP、浮点运算衡量的受限计算预算的情况下,模型大小N和训练数据大小D(以令牌数量衡量)的最佳组合是什么,以实现最低损失?
计算预算有多种形式:PF-天(10¹⁵ FLOP/秒 x 24 小时 x 3600 秒/小时,总计 8.64x10¹⁹ FLOP)是最常见的单位之一。有关 FLOP 的更多详细信息,请参阅附录 1。

人们进行了各种实验来研究语言模型的缩放规律,涉及不同的模型大小、数据集大小和其他因素,例如:
- 模型大小(N): 范围从 768 到 15 亿个非嵌入参数。
- 数据集大小(D):从 2200 万到 230 亿个标记不等。
- 模型形状: 包括深度、宽度、注意力头数量和前馈维度的变化。
- 上下文长度:
- 主要为 1024,一些实验使用较短的长度。请注意,人们可能会从各种论文或代码实现中看到上下文长度、上下文窗口大小或块大小。它们都指的是同一件事,即转换器在训练期间看到的最长的连续标记序列,并且可以一次推理。本博客文章中的代码使用块大小。
训练变量:
- 测试交叉熵损失(L):表示模型的性能。
- 计算(C):用于训练模型的计算资源。
尽管这些实验已有近 4 年历史,但它提供了对 LLM 培训要求的深刻理解。当 OpenAI 研究人员研究 LLM 时,有两个重要发现引人注目:

首先: 规模对模型损失的影响比模型架构的影响更为明显。规模是指用于训练的参数数量(N)、数据集的大小(D)和计算资源(C,以 FLOP 为单位,如附录 1 中所述)。这些因素共同对模型损失的降低程度产生的影响比架构细节(即改变前馈比、长宽比、注意头尺寸等)更大,如图 2 所示。这意味着增加模型的大小、使用更广泛的数据集和分配更多的计算能力可能会比仅仅调整模型的结构产生更好的结果。
其次: 如图1所示,当各个缩放因子( N, D , C )不受彼此制约时,模型性能与各个缩放因子( N, D , C )之间存在幂律关系,
如Eq1表中的三种情况所示:
- 情况 1:参数 = Nopt(计算高效的模型大小),数据 = Dopt(计算高效的数据令牌大小),计算 = Cmin(计算高效的计算预算)
- 情况 2:参数 = 无穷大,数据 = D,计算 = 提前停止
- 情况 3:参数 = N,数据 = 无穷大,计算 = 无穷大
这种关系适用于很多种,表明了一种一致的模式,即随着这些因素的增加,性能会可预测地提高。换句话说,随着模型大小、数据集大小或计算资源的扩大,我们可以预期模型性能会得到相应且可预测的改善,遵循幂律趋势。


经验上,OpenAI 的研究人员拟合了 Eq1(即 N,D 为有限,提前停止,固定 batch size 的情况),估计 Nc = 8.8x10¹³,AlphaN = 0.076,AlphaD = 0.095,Dc = 5.4x1⁰¹³。以Llama 3为例,它有 70B 参数和 15T token,因此损失为 L(70x10⁹,15x10¹²)= 1.72。
三 Sample-Efficient LLMs
论文 Training Compute-Optimal Large Language Models
https://arxiv.org/pdf/2203.15556

大型模型比小型模型具有更高的样本效率,以更少的优化步骤和更少的数据点达到相同的性能水平。很明显,对于给定的处理的 token,较大的模型实现较低的测试损失,如图 3 所示

DeepMind 发表了另一篇论文,详细介绍了训练计算优化 LLM 的缩放定律的各种方法,这些方法与 OpenAI 的方法不同。他们进行了 400 多次 LLM 训练,发现对于计算优化训练,模型大小和数据集大小(token 数量)应该相等缩放。
他们应用了三种方法来计算缩放定律,并将他们的发现与 OpenAI 的结果叠加,如图 4 右侧所示。他们发现,为了实现相同的模型性能,这三种方法都建议使用小得多的模型尺寸。也就是说,在给定的计算预算和训练数据的情况下,可以用较小的模型尺寸实现相同的模型性能,如图 4 左侧所示。

当 DeepMind 的研究人员将损失建模为模型大小和 token 数量的函数,并使用OpenAI研究人员建议的约束 FLOPs (N, D) ~ 6ND 时,一种有趣的 LLM 缩放定律解释方式就出现了:
绘制出 IsoLoss 轮廓或 IsoFLOPs 切片,如图 5 所示。为了理解左侧的 IsoLoss 轮廓图,让我们使用第一原理来掌握情况。对于给定的 IsoLoss(黑线),我们的目标是拥有最少的计算能力,这意味着最少的 FLOP。当你追踪所有代表所有 IsoLosses 的最少 FLOP 的点时,这些点可以连接成一条蓝线。这条线被称为有效前沿,这个概念对于在金融或商学院学习过运筹学的人来说很熟悉。
可以使用蓝线推断在计算预算较大(即训练 FLOP 较多)的情况下,最佳模型大小和预测损失可能是多少。例如,在 Gopher 模型中,给定预算的最佳模型大小为 40B 个参数。

为了实现最佳的计算效率训练,DeepMind 建议每 1 个模型参数有 ≥ 20 个训练 token,如图 6 所示。为了便于理解, Meta 发布的Llama 3的 token 与参数比例为 215:1。

与 OpenAI 的缩放定律方程不同,DeepMind 的科学家使用了不同的缩放方程,并根据经验拟合了 Eq2。他们了解到 E = 1.69,A = 406.4,B = 410.7。以 Llama 3 为例,它是一个具有 70B 参数和 15T 标记的模型。损失为 L(70x10⁹,15x10¹²)= 1.86,比使用 Eq1 的估计值(即 1.72)略高。
四 Appendix
以 FLOP(浮点运算)衡量的计算预算
模型的计算资源或计算复杂度以 FLOP 或浮点运算来衡量。它们用于估计训练和运行模型所需的计算资源量,如图 7 的 y 轴所示。
从更直观的角度来看,据估计,OpenAI 使用了 1330 亿 petaFLOP 来训练 GPT4。在计算大型语言模型的 FLOP 时,重要的是要考虑训练过程中涉及的所有操作,包括与嵌入矩阵相关的操作。以下是 Transformer 模型前向传递的 FLOP 计算的细分:
# 参考:https://github.com/Lightning-AI/litgpt/blob/410a7126f82ea550d4a43dab89367547b073b5a3/litgpt/utils.py#L321 def flops_per_param ( max_seq_length: int , n_layer: int , n_embd: int , n_params: int ) -> int : flops_per_token = 2 * n_params # 每个参数用于每个网络操作的 MAC(2 FLOPS)# 假设所有样本都有等于块大小的固定长度# 这在微调期间很可能是错误的flops_per_seq = flops_per_token * max_seq_length attn_flops_per_seq = n_layer * 2 * 2 * (n_embd * (max_seq_length** 2 )) return flops_per_seq + attn_flops_per_seq def assess_flops ( model: "GPT" , training: bool ) -> int : """测量 MFU 的估计 FLOP。参考:* https://ar5iv.labs.arxiv.org/html/2205.05198#A1 * https://ar5iv.labs.arxiv.org/html/2204.02311#A2 """ # 使用所有参数是一种简单的高估,因为并非所有模型参数实际上都有助于# 这个 FLOP 计算(例如嵌入、范数)。因此,与测量的 FLOP 相比,结果将高出固定百分比#(~10%),使结果更低但更现实。 # 为了进行正确的估计,这需要更细粒度的计算,如论文附录 A 中所示。 n_trainable_params = num_parameters(model, require_grad= True ) trainable_flops = flops_per_param( model.max_seq_length, model.config.n_layer, model.config.n_embd, n_trainable_params ) # 前向 + 后向 + 梯度 (假设没有梯度积累) ops_per_step = 3 if training else 1 n_frozen_params = num_parameters(model, require_grad= False ) freeze_flops = flops_per_param(model.max_seq_length, model.config.n_layer, model.config.n_embd, n_frozen_params) # 前向 + 后向 freeze_ops_per_step = 2 if training else 1 return ops_per_step * trainable_flops + freeze_ops_per_step * freeze_flops要注意的是,此计算仅涵盖前向传递。对于训练,还需要考虑后向传递,这通常涉及类似量的计算。
如果这变得太复杂,经验法则是分布式训练的计算要求(C)约为 6 ND 或 8 ND,其中 N 是 Transformer 的参数数量,D 是训练数据大小,以 token 为单位。C 前向约为 2 ND;C 后向约为 4 ND。

附录 2:以 FLOPS(每秒浮点运算次数)为单位的计算速度
FLOPS,即每秒浮点运算次数,是计算的速度。下面是 Nvidia A100和H100 GPU 性能表,如图 8 所示。
可以根据表格和计算需求(即 6 ND 估计)估算训练 LLM 所需的 GPU 数量。例如,GPT4 需要 1330 亿petaFLOPs,即 1.33 x 10²⁶ FLOPs(或 1.7 万亿个参数并使用 13 万亿个 token,从而产生 6 x 1.7 x 10¹² x 13 x 10¹²,1.33 x 10²⁶ FLOPs)。假设计算使用稀疏的 FP16 Tensor Core 运行,A100 将提供 624TFLOPS(每秒 6.24 x 10¹⁴ 浮点运算)。据报道,OpenAI 使用了 25,000 台 A100。因此,1.33x10²⁶/(6.24x10¹⁴ x 25,000) = 8525641 秒或 98.67 天,这与报告和帖子一致。很好,计算正确!:)

翻译
https://medium.com/sage-ai/demystify-transformers-a-comprehensive-guide-to-scaling-laws-attention-mechanism-fine-tuning-fffb62fc2552