JVM调优
文章目录
- JVM调优
- 理论
- JVM内存结构
- 堆
- 栈
- 方法区(逻辑上的划分,不同版本略有区别)
- 类加载过程
- 编译与反编译
- 类加载过程
- 编译器优化机制
- 字节码如何运行
- Hotspot的即时编译器
- 分层编译
- 找热点方法
- Hospot 内置的两类计数器
- 方法内联
- 逃逸分析
- 垃圾回收
- 前置知识
- 垃圾回收算法
- 基础垃圾回收算法
- 标记-清除(Mark-Sweep)
- 标记-整理(Mark-Compact)
- 复制(Copy)
- 综合垃圾回收算法
- 分代收集算法
- 增量算法
- 垃圾收集器
- 新生代收集器
- Serial收集器
- ParNew 收集器
- Parallel Scavenge 收集器
- 老年代收集器
- Serial Old 收集器
- Parallel Old 收集器
- CMS 收集器
- G1 收集器
- 工具
- 监控类工具
- jps
- jstat
- 故障排查工具
- jinfo
- jmap
- jstack
- jhat
- jcmd
- jhsdb
- jconsole
- VisuaIVM
- JMC
- MAT
- JITWatch
- jhsdb
- jconsole
- VisuaIVM
- JMC
- MAT
- JITWatch
理论
JVM内存结构

堆
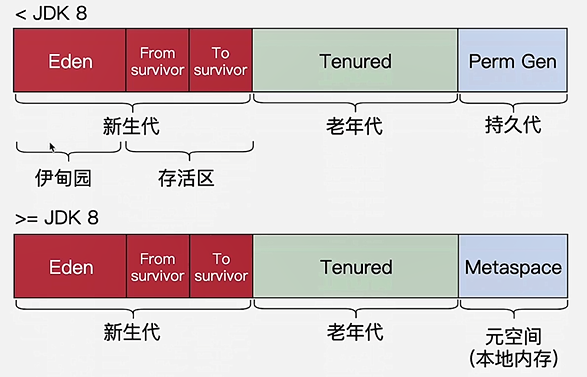
- 不同项目,perm gen要设置的大小不一样,容易溢出;所以移除
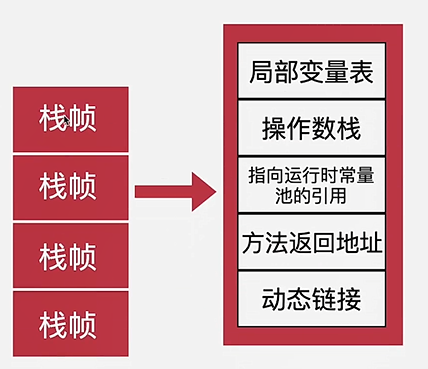
栈
方法区(逻辑上的划分,不同版本略有区别)

- 静态常量池(堆)
- 也叫class文件常量池,主要存放:
- 字面量:例如文本字符串、final修饰的常亮
- 符号引用:例如类和接口的全限定名、字段的名称和描述符、方法的名称和描述符
- 运行时常量池(元空间)
- 当类加载到内存中后,JVM就会将静态常量池的内容存放到运行时的常量池中;运行时常量池里面存储的主要是编译期间生成的字面量、符号引用等等
- 字符串常量池(堆)
- 可以理解成运行时常量池分出来的一部分,类加载到内存的时候,字符串,会存到字符串常量池里面
类加载过程
编译与反编译
- class
public class JVMTest {private static final String CONST_FIELD="A";private static String staticField;private String field;public String add(){return staticField+field+CONST_FIELD;}public static void main(String[] args) {new JVMTest().add();}
}
-
编译命令
javacjavac JVMTest.java -
反编译命令
javac
javap --help
用法: javap <options> <classes>
其中, 可能的选项包括:-help --help -? 输出此用法消息-version 版本信息-v -verbose 输出附加信息-l 输出行号和本地变量表-public 仅显示公共类和成员-protected 显示受保护的/公共类和成员-package 显示程序包/受保护的/公共类和成员 (默认)-p -private 显示所有类和成员-c 对代码进行反汇编-s 输出内部类型签名-sysinfo 显示正在处理的类的系统信息 (路径, 大小, 日期, MD5 散列)-constants 显示最终常量-classpath <path> 指定查找用户类文件的位置-cp <path> 指定查找用户类文件的位置-bootclasspath <path> 覆盖引导类文件的位置
javap -v -p JVMTest > test.txt
//类描述信息
Classfile /E:/demo/algorithm/src/main/java/math/JVMTest.classLast modified 2024-11-11; size 644 bytesMD5 checksum d52c5f49aa273d295a9e7a9390844a2eCompiled from "JVMTest.java"
//类描述信息
public class math.JVMTestminor version: 0major version: 52flags: ACC_PUBLIC, ACC_SUPER
// 常量池
Constant pool:#1 = Methodref #12.#28 // java/lang/Object."<init>":()V#2 = Class #29 // java/lang/StringBuilder#3 = Methodref #2.#28 // java/lang/StringBuilder."<init>":()V#4 = Fieldref #7.#30 // math/JVMTest.staticField:Ljava/lang/String;#5 = Methodref #2.#31 // java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;#6 = Fieldref #7.#32 // math/JVMTest.field:Ljava/lang/String;#7 = Class #33 // math/JVMTest#8 = String #34 // A#9 = Methodref #2.#35 // java/lang/StringBuilder.toString:()Ljava/lang/String;#10 = Methodref #7.#28 // math/JVMTest."<init>":()V#11 = Methodref #7.#36 // math/JVMTest.add:()Ljava/lang/String;#12 = Class #37 // java/lang/Object#13 = Utf8 CONST_FIELD#14 = Utf8 Ljava/lang/String;#15 = Utf8 ConstantValue#16 = Utf8 staticField#17 = Utf8 field#18 = Utf8 <init>#19 = Utf8 ()V#20 = Utf8 Code#21 = Utf8 LineNumberTable#22 = Utf8 add#23 = Utf8 ()Ljava/lang/String;#24 = Utf8 main#25 = Utf8 ([Ljava/lang/String;)V#26 = Utf8 SourceFile#27 = Utf8 JVMTest.java#28 = NameAndType #18:#19 // "<init>":()V#29 = Utf8 java/lang/StringBuilder#30 = NameAndType #16:#14 // staticField:Ljava/lang/String;#31 = NameAndType #38:#39 // append:(Ljava/lang/String;)Ljava/lang/StringBuilder;#32 = NameAndType #17:#14 // field:Ljava/lang/String;#33 = Utf8 math/JVMTest#34 = Utf8 A#35 = NameAndType #40:#23 // toString:()Ljava/lang/String;#36 = NameAndType #22:#23 // add:()Ljava/lang/String;#37 = Utf8 java/lang/Object#38 = Utf8 append#39 = Utf8 (Ljava/lang/String;)Ljava/lang/StringBuilder;#40 = Utf8 toString{
// 字段信息private static final java.lang.String CONST_FIELD;descriptor: Ljava/lang/String;flags: ACC_PRIVATE, ACC_STATIC, ACC_FINALConstantValue: String Aprivate static java.lang.String staticField;descriptor: Ljava/lang/String;flags: ACC_PRIVATE, ACC_STATICprivate java.lang.String field;descriptor: Ljava/lang/String;flags: ACC_PRIVATE// 方法信息public math.JVMTest();descriptor: ()Vflags: ACC_PUBLICCode:stack=1, locals=1, args_size=10: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: returnLineNumberTable:line 4: 0public java.lang.String add();descriptor: ()Ljava/lang/String;flags: ACC_PUBLICCode:stack=2, locals=1, args_size=10: new #2 // class java/lang/StringBuilder3: dup4: invokespecial #3 // Method java/lang/StringBuilder."<init>":()V7: getstatic #4 // Field staticField:Ljava/lang/String;10: invokevirtual #5 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;13: aload_014: getfield #6 // Field field:Ljava/lang/String;17: invokevirtual #5 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;20: ldc #8 // String A22: invokevirtual #5 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;25: invokevirtual #9 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;28: areturnLineNumberTable:line 10: 0public static void main(java.lang.String[]);descriptor: ([Ljava/lang/String;)Vflags: ACC_PUBLIC, ACC_STATICCode:stack=2, locals=1, args_size=10: new #7 // class math/JVMTest3: dup4: invokespecial #10 // Method "<init>":()V7: invokevirtual #11 // Method add:()Ljava/lang/String;10: pop11: returnLineNumberTable:line 14: 0line 15: 11
}
SourceFile: "JVMTest.java"类加载过程
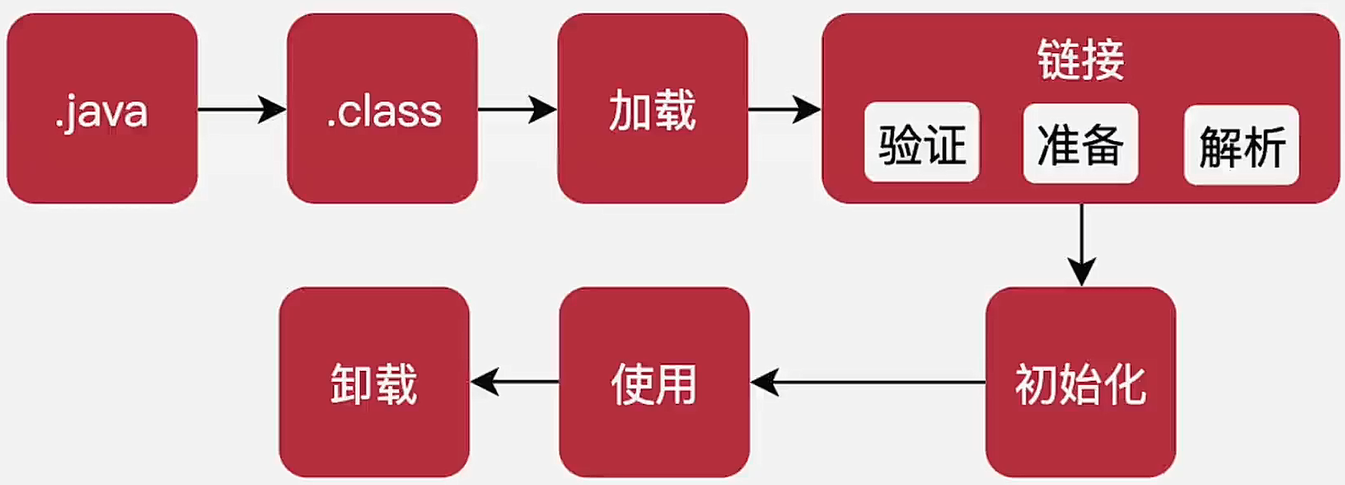
-
加载
- 读取类的二进制流
- 转为方法区数据结构,并存放到方法区
- 在Java堆中产生java.lang.Class对象
-
链接
- 验证
- 作用:验证class文件是不是符合规范
- 文件格式验证
- 是否以0XCAFEBABE开头
- 版本号是否合理
- 元数据验证
- 是否有父类
- 是否继承了final类(final类不能被继承,如果有继承就有问题)
- 非抽象类实现了所有抽象方法
- 字节码验证
- 运行检查
- 栈数据类型和操作码参数吻合(比如:栈空间只有2字节,但其实却需要大于2字节,此时就认为这个字节码是有问题的)
- 跳转指令指向合理的位置
- 符号引用验证
- 常量池描述类是否存在
- 访问的方法或字段是否存在且有足够的权限
- 如果可以保证类没有问题,可使用
-Xverify:none关闭验证
- 准备
- 作用:为类的静态变量分配内存,初始化为系统的初始值
final static修饰的变量:直接赋值为用户定义的值;比如private final static int value =123;直接赋值 123- private static int value=123;该阶段的值依然为0
- 解析
- 作用:符号引用转换成直接引用
- 验证
-
初始化
-
执行
<clinit>方法,clinit方法有编译器自动收集类里面的所有静态变量的赋值动作及静态语句块合并而成,也叫类构造方法 -
初始化的顺序和源文件中的顺序一致
public class JVMTest1 {static int a = 0;static {a=1;b=1;}static int b = 0;public static void main(String[] args) {System.out.println("a:"+a);//a:1System.out.println("b:"+b);//b:0} } -
子类的
clinit被调用前,会先调用父类的clinit -
JVM会保证
clinit方法的线程安全 -
初始化时,如果实例化一个新对象,会调用
<init>方法对实例变量进行初始化,并执行对应的构造方法内的代码public class JVMTest2 {static {System.out.println("JVMTest2 静态块");}{System.out.println("JVMTest2 构造块");}public JVMTest2(){System.out.println("JVMTest2 构造方法");}public static void main(String[] args) {System.out.println("main");new JVMTest2();} } /* JVMTest2 静态块 main JVMTest2 构造块 JVMTest2 构造方法 */
-
编译器优化机制
字节码如何运行
-
解释执行:有解释器一行一行翻译执行
- 优势在于没有编译的等待时间
- 性能相对较差
-
编译执行:把字节码编译成机器码,直接执行机器码
- 运行效率会高很多,一般认为比解释执行快一个数量级
- 带来了额外的开销
-
查询运行模式
java -version-Xint:设置解释模式-Xcomp:设置编译优先,不能编译的,已解释模式运行-Xmixed:混合模式运行
设置成解释执行:java -Xint -version java version "1.8.0_241" Java(TM) SE Runtime Environment (build 1.8.0_241-b07) Java HotSpot(TM) 64-Bit Server VM (build 25.241-b07, interpreted mode)设置成编译优先:java -Xcomp -version java version "1.8.0_241" Java(TM) SE Runtime Environment (build 1.8.0_241-b07) Java HotSpot(TM) 64-Bit Server VM (build 25.241-b07, compiled mode)设置成混合模式:java -Xmixed -version java version "1.8.0_241" Java(TM) SE Runtime Environment (build 1.8.0_241-b07) Java HotSpot(TM) 64-Bit Server VM (build 25.241-b07, mixed mode) -
一般情况下
- 一开始一般由解释器解释执行
- 当虚拟机发现某个方法或代码块的运行特别频繁的时候,就会认为这些代码是“热点代码”。为了提高热点代码的执行效率,会用即时编译器(JIT),把这些热点代码编译成与本地平台相关的机器码,并进行各层次的优化
Hotspot的即时编译器
- C1编译器
- 一个简单快速的编译器
- 主要关注局部性的优化
- 适用于执行时间短或对启动性能有要求的程序。例如,GUI应用对界面启动速度就有一定要求
- 也被成为 Client Compiler
- C2 编译器
- 是为长期运行的服务器端应用程序做性能调优的编译器
- 适用于执行时间较长或对峰值性能有要求的程序
- 也被成为 Servcer Compiler
分层编译
-
0:解释执行
-
1:简单C1编译:会用C1编译器进行一些简单的优化,不开启 Profiling
-
2:受限的C1编译:仅执行带方法调用次数以及循环回边执行次数 Profiling 的C1 编译
-
3:完全C1编译:会执行带有所有 Profiling 的C1 代码
-
4:C2编译:使用C2编译器进行优化,该级别会启用一些编译耗时较长的优化,一些情况下会根据性能监控信息进行一些非常激进的性能优化
一般来说级别越高,应用启动越慢,优化的开销越高,峰值性能也越高
-
JVM参数配置示例
- 只想开启C2:
-XX:-TieredCompilation禁用中间编译层123层 - 只想开启C1:
-XX:-TieredCompilation -XX:TieredStopAtLevel=1
- 只想开启C2:
找热点方法
- 基于采样的热点探测
- 基于计数器的热点探测(Hotspot)
Hospot 内置的两类计数器
- 方法调用计数器(Invocation Counter)
- 用于统计方法被调用的次数,在不开启分层编译的情况下,在C1编译器下的默认阈值是1500次,在C2模式下是10 000 次。也可用
-XX:CompileThreshold=X指定阈值 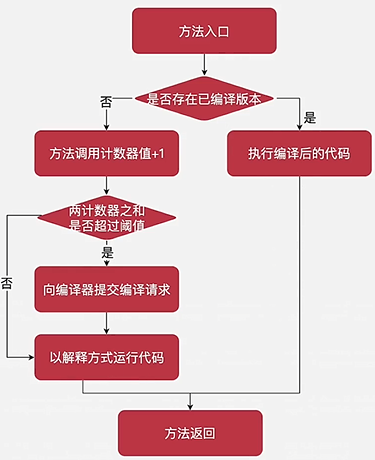
- 如果不做任何设置,方法调用计数器统计的并不是方法被调用的绝对次数,而是一个相对的执行频率,即一段时间之内被调用的次数。当超过一定的时间限度,如果方法的调用次数仍然不足以让它提交给即时编译器,那这个方法的调用计数器就会减半,这个过程称为方法调用计数器热度的衰减,而这段时间称为此方法统计的半衰周期。进行热度衰减的动作是在虚拟机进行垃圾回收顺便进行的,可以使用虚拟机参数
-XX:UseCounnterDecay来关闭热度衰减,让方法计数器统计方法调用的绝对次数,这样,只要系统运行时间足够长,绝大部分方法都会被编译成本地代码。另外,可以使用-XX:CounterHalfLifeTime参数设置半衰周期的时间,单位是秒
- 用于统计方法被调用的次数,在不开启分层编译的情况下,在C1编译器下的默认阈值是1500次,在C2模式下是10 000 次。也可用
- 回边计数器(Back Edge Counter)
- 用于统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令成为“回边”(Back Edge)。在不开启分层编译的情况下,C1编译器的默认阈值 13995,C2编辑器默认阈值 10700,可使用
-XX:OnStackReplacePercentage=X指定阈值 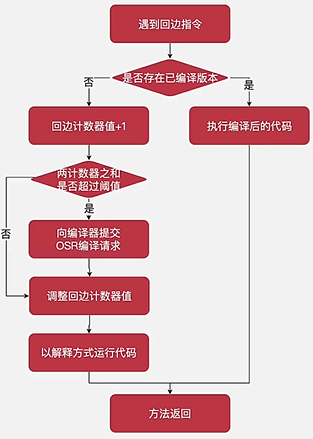
- 用于统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令成为“回边”(Back Edge)。在不开启分层编译的情况下,C1编译器的默认阈值 13995,C2编辑器默认阈值 10700,可使用
- 当开启分层编译时,JVM会根据当前编译的方法数以及编译线程数来动态调整阈值,
-XX:CompileThreshold、-XX:OnStackReplacePercentage都会失效
方法内联
public class InlineTest1 {private static int add1(int a,int b,int c,int d){return add2(a,b)+add2(c,d);}private static int add2(int a, int b) {return a+b;}//内联后private static int add3(int a,int b,int c,int d){return a+b+c+d;}
}
- 把目标方法的代码复制到发起调用的方法中,避免发生真实的方法调用,减少入栈出栈耗时
- 内联条件
- 方法体足够小
- 热点方法:如果方法体小于325字节会尝试内联,可用
-XX:FreqInlineSize修改大小 - 非热点方法:如果方法体小于35字节,会尝试内联,可用
-XX:MaxInlineSize修改大小
- 热点方法:如果方法体小于325字节会尝试内联,可用
- 被调用方法运行时的实现被可以唯一确定
- static方法、private方法、final方法,JIT可以唯一确定具体的实现代码
- public的实例方法,指向的实现可能是自身、父类、子类的代码,当且仅当JIT能够唯一确定方法的具体实现时,才有可能完成内联
- 方法体足够小
- 方法内联注意点
- 尽量让方法体小一些
- 尽量使用
final、private、static关键字修饰方法,避免因为多态,需要对方法做额外的检查 - 一些场景下,可通过JVM参数修改阈值,从而让更多方法内联
- 方法内联可能带来的问题
- 本质是空间换时间
CodeCache(热点代码缓存区,JDK8默认240M)的溢出,导致JVM退化成解释执行模式
| 参数名 | 默认 | 说明 |
|---|---|---|
-XX:+PrintInlining | - | 打印内联详情,该参数需要和-XX:+UnlockDiagnosticVMOptions配合使用 |
-XX:+UnlockDiagnosticVMOptions | - | 打印JVM诊断相关信息 |
-XX:MaxInlineSize=n | 35 | 如果非热点方法的字节码超过该值,则无法内联,单位字节 |
-XX:FreqInlineSize=n | 325 | 如果热点方法的字节码超过该值,则无法内联,单位字节 |
-XX:InlineSmallCode=n | 1000 | 目标编译后生成的机器码花销大于该值则无法内联,单位字节 |
-XX:MaxInlineLevel=n | 9 | 内联方法的最大调用帧数(嵌套调用的最大内联深度) |
-XX:MaxTrivialSize=n | 6 | 如果方法的字节码少于该值,则直接内联,单位字节 |
-XX:MinInliningThreahold=n | 250 | 如果目标方法的调用次数低于该值,则不去内联 |
-XX:LiveNodeCountInliningCutoff=n | 40000 | 编译过程中最大活动节点数(IR节点)上限,仅对C2编译器有效 |
-XX:LiveNodeCountInliningCutoff=n | 100 | 如果方法的调用点(call site)的执行次数超过该值,则触发内联 |
-XX:MaxRecursiveInlineLevel=n | 1 | 递归调用大于这么多次就不内联 |
-XX:+InlineSynchronizedMethods | 开启 | 是否允许内联同步方法 |
public class InlineTest2 {private static final Logger LOGGER = LoggerFactory.getLogger(InlineTest2.class);public static void main(String[] args) {long cost = compute();
// -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining
// 方法内联 469ms add2 (4 bytes) add1 (12 bytes)// -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining -XX:FreqInlineSize=1
// 方法不内联 627msLOGGER.info("执行花费了{}ms",cost);}private static long compute(){long start = System.currentTimeMillis();int result =0;Random random = new Random();for (int i = 0; i < 10000000; i++) {int a = random.nextInt();int b = random.nextInt();int c = random.nextInt();int d = random.nextInt();result = add1(a,b,c,d);}return System.currentTimeMillis()-start;}private static int add1(int a,int b,int c,int d){return add2(a,b)+add2(c,d);}private static int add2(int a, int b) {return a+b;}
}
JVM参数:-XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining
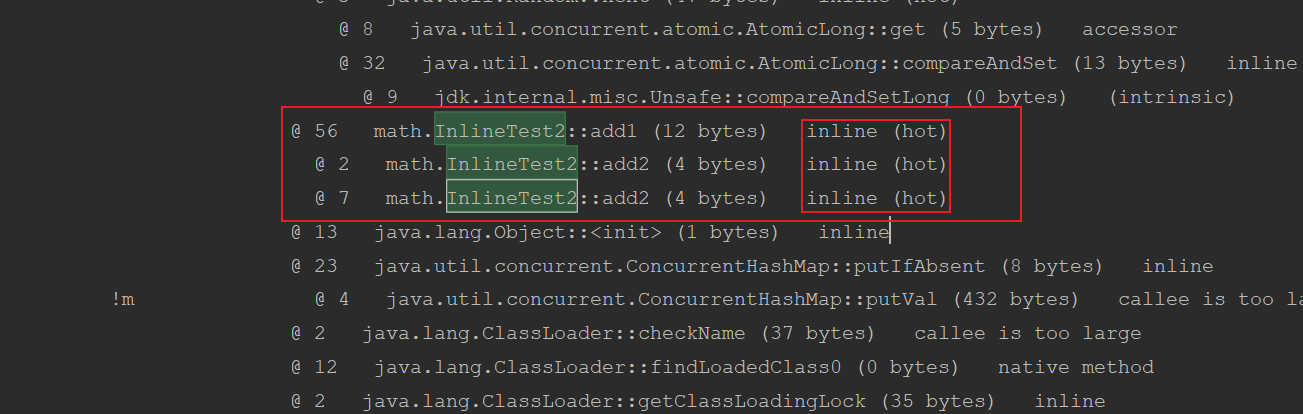
JVM参数:-XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining -XX:FreqInlineSize=1

逃逸分析
- 分析变量能否逃出它的作用域
- 全局变量赋值逃逸(赋值给全局变量)
- 方法返回值逃逸(作为返回值返回)
- 实例引用逃逸(作为入参传递)
- 线程逃逸(赋值给类变量或可以在其他线程中访问的实例变量)
- 逃逸状态标记
- 全局级别逃逸:一个对象可能从方法或者当前线程中逃逸
- 对象被作为方法的返回值
- 对象作为静态字段或者成员变量
- 如果重写了某个类的finalize()方法,那么这个类的对象都会被标记为全局逃逸状态并且一定会放在堆内存中
- 参数级别逃逸
- 对象被作为参数传递给一个方法,但是在这个方法之外无法访问/对其他线程不可见
- 无逃逸:一个对象不会逃逸
- 全局级别逃逸:一个对象可能从方法或者当前线程中逃逸
- 标量替换
- 不能被进一步分解的量
- 基础数据类型
- 对象引用
- 通过逃逸分析确定该对象不会被外部访问,并且对象可以被进一步分解时,JVM不会创建该对象,而是创建它的成员变量来替代
-XX:+EliminateAllocations开启标量替换(JDK8默认开启)
- 不能被进一步分解的量
public void test() {Some some = new Some();some.id = 1;some.age = 10;}public void test() {int id = 1;int age = 10;}
- 栈上分配
- 通过逃逸分析,确认对象不会被外部访问,就在栈上分配对象
| 参数 | 默认值(JDK8) | 作用 |
|---|---|---|
-XX:+DosEscapeAnalysis | 开启 | 是否开启逃逸分析 |
-XX:+EliminateAllocations | 开启 | 是否开启标量替换 |
-XX:+EliminateLocks | 开启 | 是否开启锁消除 |
垃圾回收
前置知识
-
什么场景下该使用什么垃圾回收策略
- 在对内存要求苛刻的场景:想办法提高对象回收效率,多回收掉一些对象,腾出更多内存
- 在CPU使用率高的情况下:降低高并发时垃圾回收评率,让CPU更多地去执行你的业务而不是垃圾回收
-
垃圾回收发生在那些区域
- 堆(对象)
- 方法区(常量。类)
-
对象在什么时候能够被回收
-
引用计数法
- 通过对象的引用计数器来判断该对象是否被引用
- 有循环引用问题
-
可达性分析
-
以根对象(GC Roots)作为起点向下搜索,走过的路径被称为引用链,如果某个对象到跟对象没有引用链时,就认为这个对象是不可达的,可以回收
-
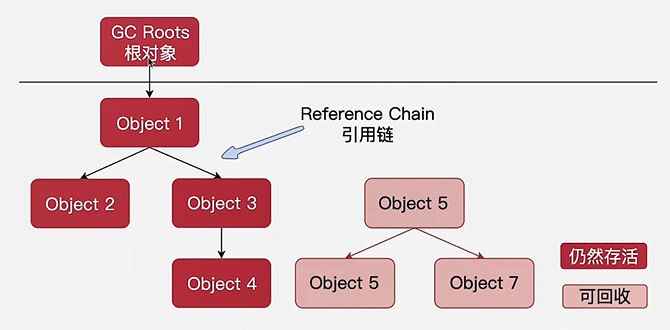
-
根对象
- 栈中引用对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
-
注意点
-
一个对象即便不可达,也不一定会被回收
-
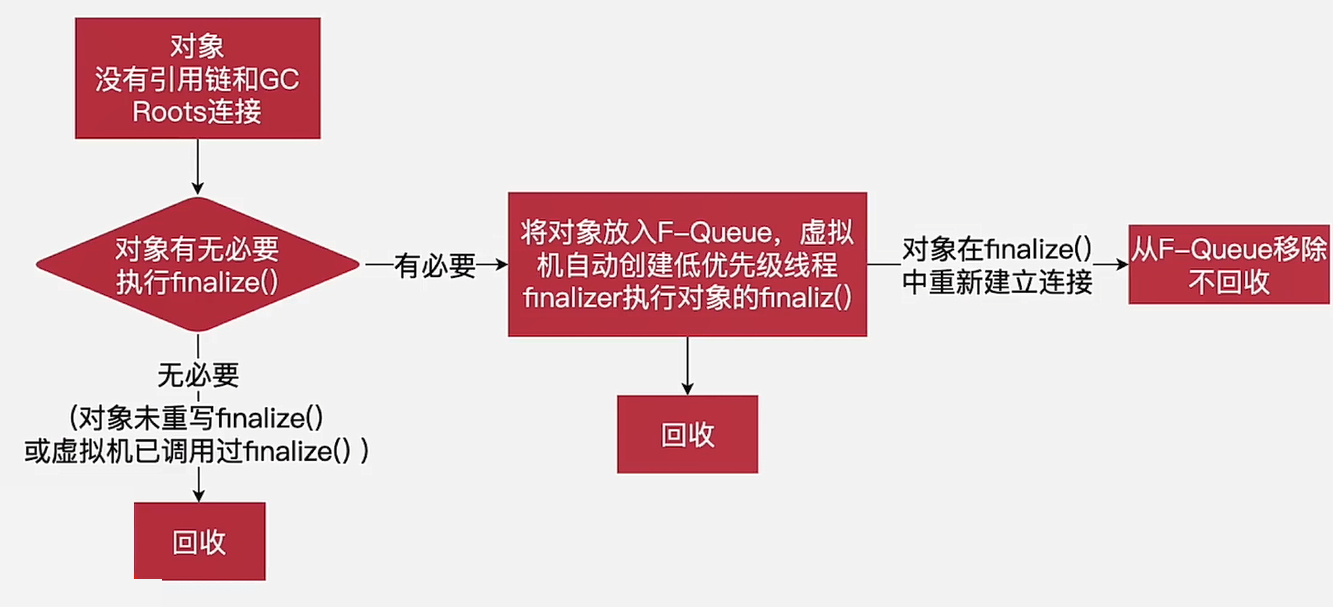
-
避免使用
finalize()方法,操作不当可能会导致问题 -
finalize()优先级低,何时会被调用无法确定,因为什么时间发生GC不确定 -
使用
try...catch...finally来替代finalize()
-
-
-
-
引用
- 强引用(Strong Reference)
- x形如
Object obj = new Object()的引用 - 只要强引用在,永远不会回收被引用的对象
- x形如
- 软引用(Soft Reference)
- 形如
SoftReference<string> sr = new SoftReference<>("a"); - 是用来描述一些有用但非必须得对象
- 软引用关联的对象,只有在内存不足的时候才会回收
- 形如
- 弱引用(Weak Reference)
- 形如
WeaReference<String> sr = new WeakReference<>("aa"); - 弱引用也是用来描述非必须对象的
- 无论内存是否充足,都会回收被弱引用关联的对象
- 形如
- 虚引用(Phantom Reference)
- 形如
ReferenceQueue<String> queue = new ReferenceQueue<>();PhantomReference<String> pr = new PhantomReference<>("aa"); - 不影响对象的生命周期,如果一个对象只有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。虚引用主要用来跟踪对象被垃圾回收器回收的活动,必须和引用队列(ReferenceQueue)配合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。如果程序发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动
- 形如
- 强引用(Strong Reference)
垃圾回收算法
基础垃圾回收算法
| 回收算法 | 优点 | 缺点 |
|---|---|---|
| 标记-清除 | 实现简单 | 存在内存碎片,分配内存速度会受影响 |
| 标记-整理 | 无碎片 | 整理存在开销 |
| 复制 | 性能好、无碎片 | 内存利用率低 |
标记-清除(Mark-Sweep)
- 标记需要回收的对象,清理需要回收的对象
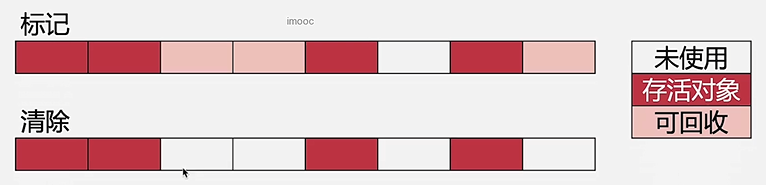
标记-整理(Mark-Compact)
- 标记需要回收的对象,把所有的存活对象压缩到内存的一端,清理掉边界外的所有空间
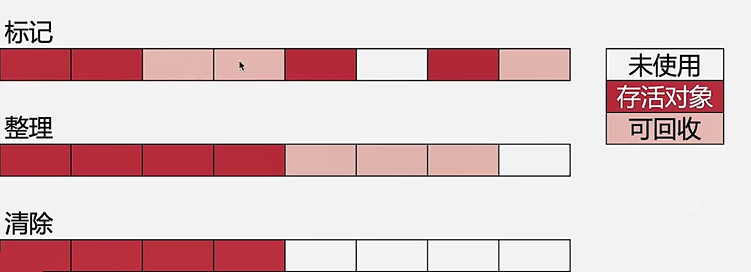
复制(Copy)
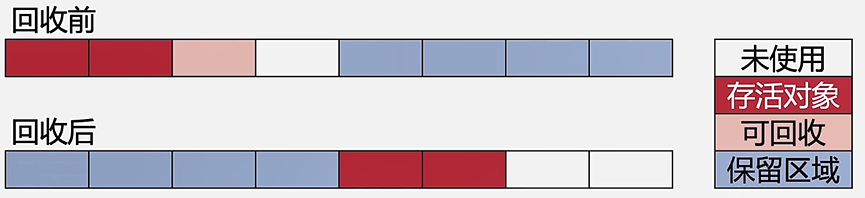
- 把内存分为两块,每次只使用一块,将正在使用的内存中的存活对象复制到未使用的内存中去,然后清除掉正在使用的内存中的所有对象,交换两个内存的角色,等待下次回收
综合垃圾回收算法
分代收集算法
-
把内存分成多个区域,不同区域使用不同的回收算法
-
根据对象的存活周期,把内存分成多个区域,不同区域使用不同的回收算法回收对象
-
回收类型
- 新生代回收(Minor GC | Younng GC)
- 老年代回收(Major GC)
- 清理整个堆(Full GC)
- Major GC = Full GC
-
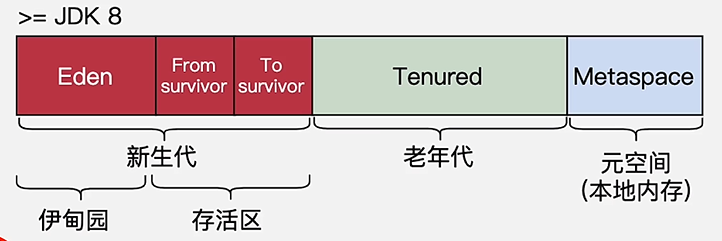
对象创建时一般存放到Eden区,当Eden满了的时候就会触发垃圾回收,把Eden区存活对象复制到From Survivor 区,Form Survivor 区满了就会把存活对象复制到 To Survivor 区,From 和 To 之间每次拷贝,存活对象年龄加1,年龄大于15的对象,拷贝到老年代
-
新建对象不一定分配到Eden区
- 对象大于
-XX:PretenureSizeThreshold,就会直接分配到老年代,默认不做限制 - 对象过大,Eden区空间不足
- 对象大于
-
对象不一定要达到年龄才进入老年代
- 动态年龄:如果Survivor空间中所有相同年龄对象大小的总和大于Survivor空间的一半,那么年龄大于等于该年龄的对象就可以直接进老年代
-
新生代(Minor GC)触发垃圾回收条件:Eden空间不足
-
老年代(Full GC)触发垃圾回收条件:
- 老年代空间不足
- 真的空间不足
- 内存碎片化
- 元空间不足
- 要晋升到老年代的对象所占用的空间大于老年代的剩余空间
- 显示调用
System.gc()
- 老年代空间不足
-
分代收集算法调优原则
- 合理设置Survivor区域的大小,避免内存浪费
- 让GC尽量发生在新生代,尽量减少Full GC的发生
增量算法
- 每次只收集一小片区域的内存空间的垃圾,减少系统停顿
| 参数 | 作用 | 默认值 |
|---|---|---|
-XX:NewRatio=n | 老年代:新生代内存大小比值 | 2 |
-XX:SurvivorRatio=n | Eden:Servivor区内存大小比值 | 8 |
-XX:PretenureSizeThreshold=n | 对象大于该值就直接分配到老年代,0表示不做限制 | 0 |
-Xms | 最小堆内存 | |
-Xmx | 最大堆内存 | |
-Xmn | 新生代大小 | |
-XX:+DisableExplicitGC | 忽略掉System.gc()的调用 | 启用 |
-XX:NewSize=n | 新生代初始内存大小 | |
-XX:MaxNewSize=n | 新生代最大内存 |
垃圾收集器
- Stop The World
- 简写 STW,全局停顿,Java代码停止运行,native代码继续运行,但不能与JVM进行交互
- 原因:多半由于垃圾回收导致;也可能有Dump线程、死锁检查、Dump堆等导致
- 危害:服务停止、没有响应;主从切换、危害生产环境
- 并行收集
- 指多个垃圾回收线程并行工作,但是收集过程中,用户线程还是处于等待状态
- 并发收集
- 用户线程由于垃圾收集线程同时工作
- 吞吐量
- CPU用于运行用户代码的时间与CPU总消耗时间的比值
- 公式:运行用户代码时间/(运行用户代码时间 + 垃圾收集时间)
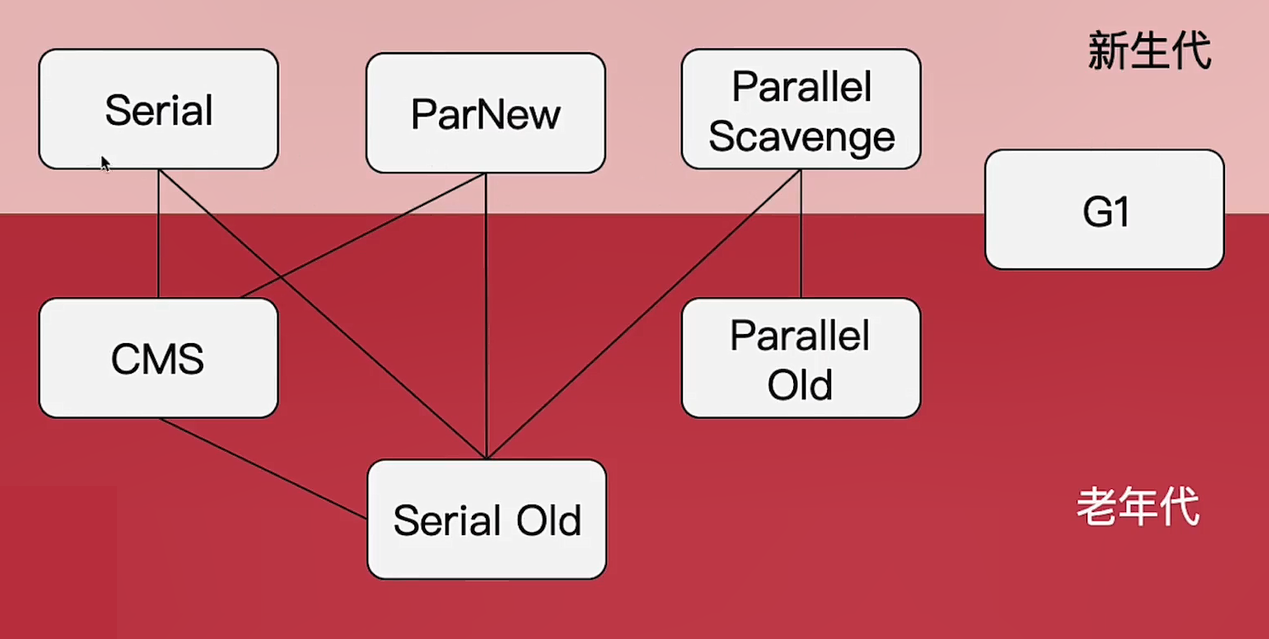
新生代收集器
Serial收集器
- 最基本、最悠久的收集器
- 复制算法
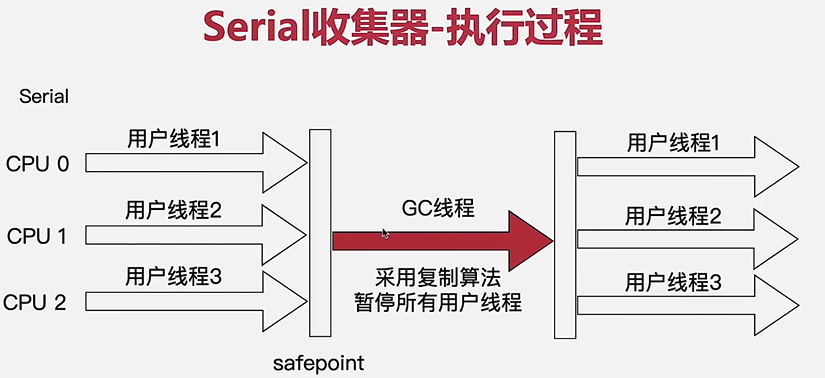
- 特点
- 单线程
- 简单、高效
- 收集过程全程STW
- 适用场景
- 客户端程序,应用以
java -client -jar xx.jar模式运行时,默认使用的就是Serial - 单核机器上
- 客户端程序,应用以
ParNew 收集器
- Serial收集器的多线程版本,处使用了多线程以外,其他和Serial收集器一样,包扣:JVM参数、STW表现、垃圾收集算法都是一样的
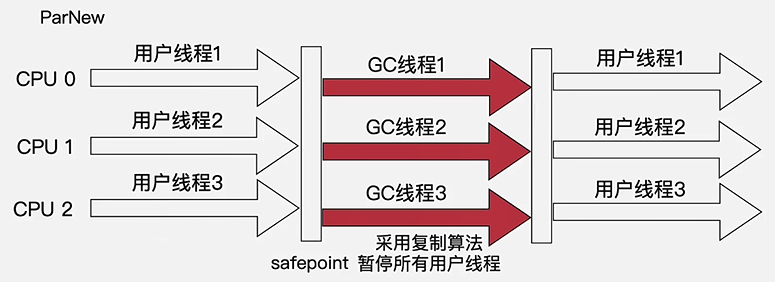
- 适用场景
- 主要用来和CMS收集器配合使用
Parallel Scavenge 收集器
- 也叫吞吐量优先收集器
- 复制算法
- 并行的多线程收集器
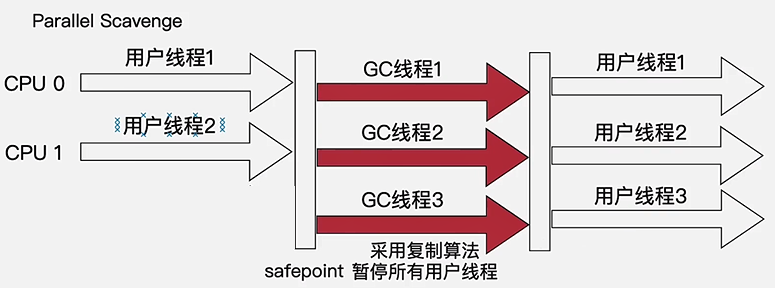
- 特点
- 可以达到一个可控的吞吐量
-XX:MaxGCPauseMillis控制最大的垃圾收集停顿时间(尽力)-XX:GCTimeRatio设置吞吐量的大小,取值0-100,系统花费不超过1/(1+n)的时间用于垃圾收集
- 自适应GC策略
- 可用
-XX:+UseAdptiveSizePolicy打开 - 打开自适应策略后,无需手动设置新生代的大小(-Xmn)、Eden与Survivor区的比例等参数
- 虚拟机会自动根据系统的运行状况收集性能监控信息,动态调整这些参数,从而达到最优的停顿时间以及最高的吞吐量
- 可用
- 可以达到一个可控的吞吐量
- 适用场景
- 注重吞吐量的场景
老年代收集器
Serial Old 收集器
- Serial收集器的老年代版
- 标记-整理算法
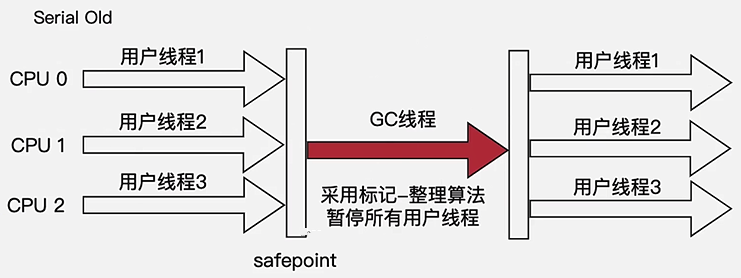
- 适用场景
- 可以和Serial、ParNew、Parallel Scavenge 这三个新生代的垃圾收集器配合使用
- CMS收集器出现故障时,会使用 Serial Old作为后备
Parallel Old 收集器
- Parallel Scavenge 收集器的老年代版本
- 标记-整理算法
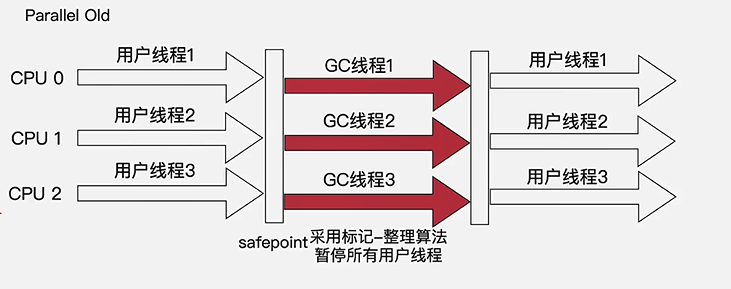
- 特点
- 只能和 Parallel Scavenge 配合使用
- 适用场景
- 关注吞吐量的场景
CMS 收集器
- CMS: Concurrent Mark Sweep
- 并发收集器
- 标记-清除
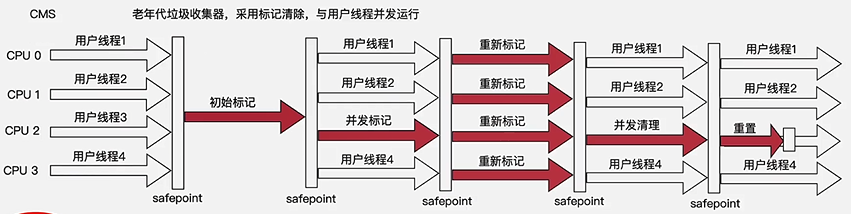
- 执行过程
- 1、初始标记(initial mark)
- 标记GC Roots 能直接关联到的对象
- Stop The World
- 2、并发标记(Concurrent mark)
- 找出所有 GC Roots 能关联到的对象
- 标记线程和用户线程并发执行,无STW
- 3、并发预清理(concurrent-preclean)
- 重新标记那些在并发标记阶段,引用被更新的对象,从而减少后面重新标记阶段的工作量
- 并发执行,无STW
- 可使用
-XX:-CMSPrecleaningEnabled关闭并发预清理阶段,默认打开
- 4、并发可中止的预清理阶段(concurrent-abortable-preclean)
- 和并发预清理做的事情一样,并发执行,无STW
- 当Eden的使用量大于CMSScheduleRemarkEdenSizeThreshold 的阈值(默认2M)时,才会执行该阶段
- 主要作用:允许我们能控制预清理阶段的结束时机,比如扫描多长时间(CMSMaxAbortablePrecleanTime,默认5秒)或者Eden区使用占比达到一定阈值(CMSScheduleRemarkEdwnPenetration,默认50%)就结束本阶段
- 5、重新标记(remark)
- 修正并发标记期间,因为用户程序继续运行,导致标记发生变动的那些对象的标记
- 一般来说,重新标记花费的时间会比初始标记阶段长一些,但比并发标记的时间短
- 存在STW
- 6、并打清除(concurrent sweep)
- 基于标记结果,清除掉要前面标记出来的垃圾
- 并发执行,无STW
- 7、并发重置(concurrent reset)
- 清理本次CMS GC的上下文信息,为下一次GC做准备
- 1、初始标记(initial mark)
- 优点
- STW 的时间比较短
- 大多数过程并发执行
- 缺点
- CPU资源比较敏感
- 并发阶段可能导致应用吞吐量的降低
- 无法处理浮动垃圾
- 不能等到老年代几乎满了才开始收集
- 预留的内存不够 -> concurrent Mode Failure -> Serial Old 作为后备
- 可使用
CMSInitiatingOccupancyFraction设置老年代占比达到多少就触发垃圾收集,默认68%
- 内存碎片
- 标记-清除导致碎片产生
UseCMSCompactAtFullCollection在完成Full GC 后是否要进行内存碎片整理,默认开启CMSFullGCBeforeCompaction进行几次Full GC 就进行一次内存碎片整理,默认 0
- CPU资源比较敏感
- 适用场景
- 希望系统停顿时间短,响应速度快的场景,比如各种服务器应用程序
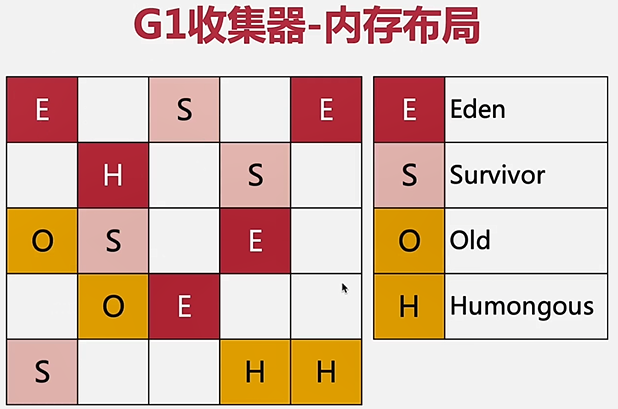
G1 收集器
- 用于新生代和老年代
- 堆内存分为多个Region
- 通过参数
-XX:G1HeapRegionSize指定Region的大小 - 取值范围为1-32MB,应为2的N次幂
- Humongous用于存放大对象
- 通过参数
- 设计思想
- 内存分块 Region
- 跟踪每个Region 里面的垃圾堆积的价值大小
- 构建一个优先列表,根据允许的收集时间,优先回收价值高的Region
- 垃圾收集机制
- Young GC
- 所有Eden Region都满了的时候,就会触发 Young GC
- Eden里面的对象转移到Survivor里面
- 原先Survivor中的对象转移到新的Survivor中,或者晋升到Old
- 空闲Region会被放入空闲列表中,等待下次被使用
- Mixed GC
- 老年代大小占整个堆的百分比达到一定阈值(可用
-XX:InitiatingHeapOccupancyPercent指定,默认45%),就会触发 - Mixed GC会回收所有Young ,同时回收部分Old
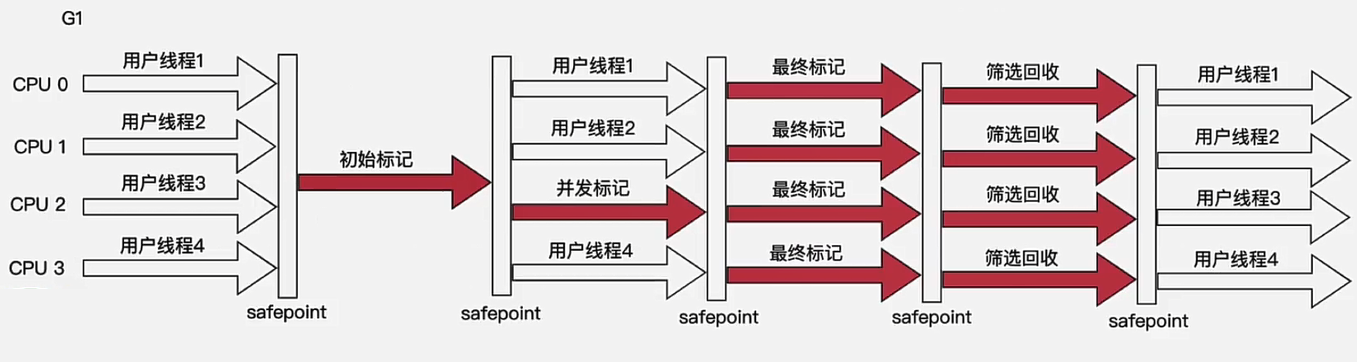
- 初始标记
- 标记GC Roots能直接关联到的对象,和CMS类似
- 存在 STW
- 并发标记
- 同CMS的并发标记
- 并发执行,没有STW
- 最终标记
- 修正并发标记期间引起的变动
- 存在STW
- 筛选回收
- 对各个Region 的回收价值和成本进行排序
- 根据用户所期望的停顿时间来制定回收计划,并选择一些Region回收
- 选择一系列Region构成一个回收集
- 把决定回收的Region中的存活对象复制到空的Region中
- 删除掉需要回收的Region -> 无内存碎片
- 存在STW
- 初始标记
- 老年代大小占整个堆的百分比达到一定阈值(可用
- Full GC
- 复制对象内存不够,或者无法分配足够内存时,会触发
- Full GC 模式下,适用 Serial Old 模式
- G1优化原则,尽量减少Full GC的发生
- Young GC
- 减少Full GC的思路
- 增加预留内存(增大
-XX:G1ReservePercent,默认堆的10%) - 更早的回收垃圾(减少
-XX:InitatingHeapOccupancyPercent,老年代达到该值就会触发Mixed GC,默认45%) - 增加并发阶段使用的线程数(增大
-XX:ConcGCThreads)
- 增加预留内存(增大
- 特点
- 可以作用在整个堆
- 可控的停顿
MaxGCPauseMillis=200 - 无内存碎片
- 适用场景
- 6G以上内存的应用
- 替换CMS垃圾收集器
- G1 or CMS
- 对于JDK8:都可以
- 内存<= 6G,用CMS;内存 > 6G,考虑用G1
- JDK > 8 ,用G1,CMS废弃了
- 对于JDK8:都可以
垃圾收集器相关参数https://chriswhocodes.com/
工具
- 基于JDK11
监控类工具
jps
- 实验性工具
- 用以查看JVM进程状态
jps -husage: jps [-help]jps [-q] [-mlvV] [<hostid>]Definitions:<hostid>: <hostname>[:<port>]
-
参数:
-q只显示进程号-m显示传递给main方法的参数-l输出Java进程的完整类名或JAR文件的路径名-v输出Java进程的JVM参数,包括-Xms、-Xmx等-V通过flags文件输出传递给JVM的参数
-
hostid :想要查看的主机的标识符,格式为:
[protocol:][[//]hostname][:port][/servername]protocol:通信协议,默认 rmihostname:目标主机的主机名或IP地址port:通信端口,对于默认rmi协议,该参数用来指定rmiregistry远程主机上的端口servername:服务名称,取值取决于实现方式,对于rmi协议,此参数代表远程主机上RMI远程对象的名字
-
使用示例
jps jps -m jps -ml jps -mlv # 查看remote.domain这台服务器中JVM进程的信息,使用rmi协议,端口1099 jps -l remote.domain# 查看remote.domain这台服务器中JVM进程信息,使用rmi协议,端口1231 jps -l rmi://remote.domain:1231
jstat
- 实验性工具
- 用于监控JVM的各种运行状态
jstat -hUsage: jstat -help|-optionsjstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]]Definitions:<option> An option reported by the -options option<vmid> Virtual Machine Identifier. A vmid takes the following form:<lvmid>[@<hostname>[:<port>]]Where <lvmid> is the local vm identifier for the targetJava virtual machine, typically a process id; <hostname> isthe name of the host running the target Java virtual machine;and <port> is the port number for the rmiregistry on thetarget host. See the jvmstat documentation for a more completedescription of the Virtual Machine Identifier.<lines> Number of samples between header lines.<interval> Sampling interval. The following forms are allowed:<n>["ms"|"s"]Where <n> is an integer and the suffix specifies the units asmilliseconds("ms") or seconds("s"). The default units are "ms".<count> Number of samples to take before terminating.-J<flag> Pass <flag> directly to the runtime system.- option 取值
- -class:显示加载的class数量及所占空间等信息
- -compiler:显示Java HotSpot VM即时编译器行为的统计信息
- -gc:显示垃圾回收(GC)的次数及时间等信息,包括young GC和full GC的次数和时间。
- **-gccapacity**:显示VM内存中三代(young、old、perm)对象的使用和占用大小。
- **-gccause**:显示最近一次GC统计和原因。
- -gcnew:显示年轻代对象的信息。
- -gcnewcapacity:显示年轻代对象的信息及其占用量。
- **-gcold**:显示老年代对象的信息。
- -gcoldcapacity:显示老年代对象的信息及其占用量。
- -gcmetacapacity:显示元数据空间统计。
- -gcutil:统计GC信息的百分比。
- -printcompilation:显示JVM编译方法的统计信息
- jstat的基本命令格式如下:
jstat [generalOption | outputOptions vmid [interval[s|ms] [count]]]generalOption是单个的常用命令行选项,如-help、-options或-version;outputOptions是一个或多个输出选项,由单个的statOption选项组成,可以与-t、-h和-J等选项配合使用
故障排查工具
jinfo
- 实验性工具,对于JDK 9以及更高版本,部分功能可使用
jhsdb jinfo代替,也可用jcmd代替 - 主要用来查看与调整JVM参数
jinfo -h
Usage:jinfo [option] <pid>(to connect to running process)jinfo [option] <executable <core>(to connect to a core file)jinfo [option] [server_id@]<remote server IP or hostname>(to connect to remote debug server)where <option> is one of:-flag <name> 打印制定参数的值-flag [+|-]<name> 启用/关闭制定参数-flag <name>=<value> 将指定的参数设置为指定的值-flags 打印VM参数-sysprops 打印系统属性(打印的是System.getProperties()的结果)<no option> 打印VM参数以及系统属性-h | -help to print this help message
- 使用示例
在应用启动时,指定-XX:+PrintFlagsFinal这样会在启动时将JVM参数打印到日志
查看参数:打印42342 这个进程的VM参数及JAVA系统属性
jinfo 42342打印42342 这个进程的JAVA系统属性
jinfo -sysprops 42342打印42342 这个进程的VM参数
jinfo -flags 42342打印42342 这个进程的ConcGCThreads参数的值
jinfo -flags ConcGCThreads 42342动态修改参数:
将42342 这个进程的PrintClassHistogram设置为false
jinfo -flag -PrintClassHistogram 42342将42342这个进程的MaxHeapFreeRatio设置为80
jinfo -flag MaxHeapFreeRatio=80 42342jinfo动态修改VM参数,并非所有参数都支持修改,如果修改不支持参数,会报如下异常
Exception in thread "main" com.sum.tools.attach.AttachOperationFailedException使用如下命令显示出来的参数,基本都支持动态修改:
java -XX:+PrintFlagsInitial | grep manageable
jmap
- 实验性工具,对于JDK 9以及更高版本,部分功能可使用
jhsdb jmap代替,也可用jcmd代替 - 展示对象内存映射或堆内存详细信息
jmap -h
Usage:jmap [option] <pid>(to connect to running process)jmap [option] <executable <core>(to connect to a core file)jmap [option] [server_id@]<remote server IP or hostname>(to connect to remote debug server)where <option> is one of:<none> to print same info as Solaris pmap-heap to print java heap summary-histo[:live] to print histogram of java object heap; if the "live"suboption is specified, only count live objects-clstats to print class loader statistics-finalizerinfo to print information on objects awaiting finalization-dump:<dump-options> to dump java heap in hprof binary formatdump-options:live dump only live objects; if not specified,all objects in the heap are dumped.format=b binary formatfile=<file> dump heap to <file>Example: jmap -dump:live,format=b,file=heap.bin <pid>-F force. Use with -dump:<dump-options> <pid> or -histoto force a heap dump or histogram when <pid> does notrespond. The "live" suboption is not supportedin this mode.-h | -help to print this help message-J<flag> to pass <flag> directly to the runtime system
- 命令格式
jmap [options] pid options的可选项如下:-clstats:连接到正在运行的进程,并打印java堆的类加载器统计信息-finalizerinfo:连接到正在运行的进程,并打印等待finallization的对象的信息-histo[:live]:连接到正在运行的进程,并打印java堆的直方。如果指定了live子选项,则仅统计活动对象-dump:dump_options:连接到正在运行的进程,并转储java堆。其中dump_options的取值为- live:指定时,仅dump活动对象,如果未指定,则转储堆中所有的对象
- format=b:以hprof格式dump堆
- file=filename:将堆dump到filename
- 使用示例
# 展示63120进程的类加载统计信息
jmap -clstats 63120# 展示63120进程中等待finalization的对象信息
jmap -finalizerinfo 63120# 展示63120进程中堆的直方图
jmap -histo 63120# 展示63120进程堆中存活对象的直方图
jmap -histo:live 63120# Dump 63120进程中存活对象到堆的dump.hprof 文件
jmap -dump:live,format=b,file=dump.hprof 63120
- 想要获取java堆Dump,除使用jmap外,还有以下方法
- 使用
-XX:+HeapDumpOnOutOfMemoryError,让虚拟机在OOM异常出现后自动生成堆Dump文件 - 使用
-XX:+HeapDumpOnCtrBreak,可使用[Ctrl]+[Break],让虚拟机生成堆Dump文件 - 对于Spring Boot应用,也可以使用Spring Boot Actuator提高的
/actuatorr/heapdump实现堆Dump
- 使用
jstack
- 实验性工具,部分功能可用
jhsdb jstack代替 - 用于打印当前虚拟机的线程快照
- 不同版本参数不同(jdk 8 有 -m、-F 参数等,JDK 11都没有了)
jstack -h
Usage:jstack [-l] <pid>(to connect to running process)jstack -F [-m] [-l] <pid>(to connect to a hung process)jstack [-m] [-l] <executable> <core>(to connect to a core file)jstack [-m] [-l] [server_id@]<remote server IP or hostname>(to connect to a remote debug server)Options:-F to force a thread dump. Use when jstack <pid> does not respond (process is hung)-m to print both java and native frames (mixed mode)-l 显示有关锁的额外信息-e 显示有关线程的额外信息(分配了多少内存、定义了多少个类等等)-h or -help to print this help message
- 使用示例
jstack 63120jstack -l 63120jstack -l -e 63120
jhat
-
实验性
-
功能不强,VisualVM、Eclips Memory Analyzer等都比jhat强大,建议优先使用替代工具
-
分析jmap生成的对Dump
-
jdk 11 已废弃
-
使用说明
# 命令格式
jhat [options] heap-dump-fileoptions的可选项-stack false|true :开启或关闭跟踪对象分配的调用栈,默认 true-refs false|true:开启过关闭对对象引用的跟踪,默认true-port port-number:指定jhat HTTP Server的端口,默认7000-exclude exclude-file:指定一个文件,该文件列出了应从可达性对象查询中排除的数剧成员。例如,如果文件包含java.lang.String.value,则对于指定对象o,不管对象列表针对o是否可达,都不会考虑涉及java.lang.String.value的引用路径-baseline exclide-file:指定基线堆Dump文件。两个对Dump中,具有相同对象ID的对象都会被标记为不是新对象,其他对象被标记为新对象。这对于比较两个不同的堆转储很有用-debug inrSets:指定该工具的debug级别。设置为0,则不会有debug输出。数值越高,日志越详细-version:显示版本
- 适用示例
#分析1.hprof,并开启对象分配调用栈的分析
jhat -stack true 1.hprof#分析1.hprof,开启对象调用栈的分析,关闭对象引用的分析
jhat -stack true -refs false 1.hprof等待片刻之后,访问http://localhost:7000/即可查看分析结果
jcmd
-
用于将诊断命令请求发送到正在运行的java虚拟机,从JDK 7开始提供
-
适用说明
jcmd -h
Usage: jcmd <pid | main class> <command ...|PerfCounter.print|-f file>or: jcmd -lor: jcmd -hcommand must be a valid jcmd command for the selected jvm.Use the command "help" to see which commands are available.If the pid is 0, commands will be sent to all Java processes.The main class argument will be used to match (either partiallyor fully) the class used to start Java.If no options are given, lists Java processes (same as -p).PerfCounter.print display the counters exposed by this process-f 从文件读取并执行命令-l 列出本机上所有的JVM进程-h this help
- 参数说明
- pid:接收诊断命令请求的进程ID。
- command:接收诊断命令请求的进程的main类。匹配进程时,main类名称中包含指定子字符串的任何进程均是匹配的。如果多个正在运行的Java进程共享同一个main类,诊断命令请求将会发送到所有的这些进程中。 注意: 如果任何参数含有空格,你必须使用英文的单引号或双引号将其包围起来。 此外,你必须使用转义字符来转移参数中的单引号或双引号,以阻止操作系统shell处理这些引用标记。当然,你也可以在参数两侧加上单引号,然后在参数内使用双引号(或者,在参数两侧加上双引号,在参数中使用单引号)。
- Perfcounter.print:打印目标Java进程上可用的性能计数器。性能计数器的列表可能会随着Java进程的不同而产生变化。
- -f file:从文件file中读取命令,然后在目标Java进程上调用这些命令。在file中,每个命令必须写在单独的一行。以"#"开头的行会被忽略。当所有行的命令被调用完毕后,或者读取到含有stop关键字的命令,将会终止对file的处理。
- 使用示例
# 查看所有JVM进程
jcmd -l# 打印制定继承上的可用的性能计数器
jcmd 26089 Perfcounter.print# 打印所有启动类为com.Application的应用上可用的性能计数器
jcmd com.Application Perfcounter.print# 打印指定进程的代码缓存的布局和边界
jcmd 26089 Compiler.codecache
-
支持的命令
-
1.help [options] [arguments]
-
作用:查看指定命令的帮助信息
-
arguments:想查看帮助的命令(STRING,无默认值)
-
options:选项,必须使用key或者key=value的语法指定,可用的options如下:
- -all:(可选)查看所有命令的帮助信息(BOOLEAN,false)
-
# 获得指定进程可用的命令列表 jcmd <pid> help # 获取指定进程、指定命令的帮助信息,如果参数包含空格,需要用 ' 或者 " 引起来 jcmd <pid> help <command>
-
-
2.Compiler.codecache
- 作用:打印code cache(代码缓存)的布局和边界
- 影响:低
- 所需权限:java.lang.management.ManagementPermission(monitor)
-
3.Complier.codelist
- 作用:打印代码缓存中所有仍在运行的已编译方法
- 影响:中
- 所需权限:java.lang.management.ManagementPermission(monitor)
-
4.Compiler.queue
- 作用:打印排队等待编译的方法
- 影响:低
- 所需权限:java.lang.management.ManagementPermission(monitor)
-
5.Compiler.directives_add filename arguments
- 作用:从文件添加编译器指令
- 影响:低
- 所需权限:java.lang.management.ManagementPermission(monitor)
- filename:指令文件的名称(STRING,无默认值)
-
6.Compiler.directives_clear
- 作用:删除所有编译器指令
- 影响:低
- 所需权限:java.lang.management.ManagementPermission(monitor)
-
7.Compiler.directives_print
- 作用:打印所有活动的编译器指令
- 影响:低
- 所需权限:java.lang.management.ManagementPermission(monitor)
-
8.Compiler.directives_remove
- 作用:删除最新添加的编译器指令。
- 影响:低
- 所需权限:java.lang.management.ManagementPermission(monitor)
-
9.GC.class_histogram [options]
- 作用:提供有关Java堆使用情况的统计信息
- 影响:高 (取决于Java堆的大小和内容)
- 所需权限:java.lang.management.ManagementPermission(monitor)
- options:选项,必须使用key或者key=value的语法指定,可用的options如下:
- -all:(可选)检查所有对象,包括不可达的对象(BOOLEAN,false)
-
10.GC.class_stats [options] [arguments]
-
作用:展示有关Java类元数据的统计信息
-
影响:高(取决于Java堆的大小和内容)
-
options:选项,必须使用key或者key=value的语法指定,可用的options如下:
- -all:(可选)显示所有列(BOOLEAN,false)
- -csv:(可选)以CSV格式打印电子表格(BOOLEAN,false)
- help:(可选)显示所有列的含义(BOOLEAN,false)
-
arguments:参数,可选参数如下:
- columns:(可选)要显示的列,以逗号分隔。如果不指定,则显示以下列:
- InstBytes
- KlassBytes
- CpAll
- annotations
- MethodCount
- Bytecodes
- MethodAll
- ROAll
- RWAll
- Total
- columns:(可选)要显示的列,以逗号分隔。如果不指定,则显示以下列:
-
# 展示指定进程类的元数据的所有统计信息 jcmd 12737 GC.class_stats -all # InstBytes、KlassBytes等列的含义 jcmd 12737 GC.class_stats -help # 显示InstBytes,KlassBytes这两列,并生成csv jcmd 12737 GC.class_stats -cvs InstBytes,KlassBytes > t.csv
-
-
jhsdb
- Hostpot进程调试器,可用于从崩溃的JVM附加到Java进程或核心转储
- jdk 9,才正式引入
#图形化模式,和clhsdb功能对标
jhsdb hsdb --pid 81033
jconsole
- 可视化监控、管理工具
VisuaIVM
-
强大的监控及故障处理程序
-
JDK 9及更高版本,不是内置,需要手动下载
JMC
- 作为JMX控制台,监控虚拟机MBean提供数据
- 可持续收集数据的JFR,并作为JFR的可视化分析工具
- 需手动下载
MAT
- java堆内存分析器,查找内存泄漏并减少内存消耗
JITWatch
- JIT编译器的日志分析器与可视化工具,可用来检查内联决策、热点方法、字节码以及汇编的各种细节
key或者key=value的语法指定,可用的options如下:
- -all:(可选)检查所有对象,包括不可达的对象(BOOLEAN,false)
-
10.GC.class_stats [options] [arguments]
-
作用:展示有关Java类元数据的统计信息
-
影响:高(取决于Java堆的大小和内容)
-
options:选项,必须使用key或者key=value的语法指定,可用的options如下:
- -all:(可选)显示所有列(BOOLEAN,false)
- -csv:(可选)以CSV格式打印电子表格(BOOLEAN,false)
- help:(可选)显示所有列的含义(BOOLEAN,false)
-
arguments:参数,可选参数如下:
- columns:(可选)要显示的列,以逗号分隔。如果不指定,则显示以下列:
- InstBytes
- KlassBytes
- CpAll
- annotations
- MethodCount
- Bytecodes
- MethodAll
- ROAll
- RWAll
- Total
- columns:(可选)要显示的列,以逗号分隔。如果不指定,则显示以下列:
-
# 展示指定进程类的元数据的所有统计信息 jcmd 12737 GC.class_stats -all # InstBytes、KlassBytes等列的含义 jcmd 12737 GC.class_stats -help # 显示InstBytes,KlassBytes这两列,并生成csv jcmd 12737 GC.class_stats -cvs InstBytes,KlassBytes > t.csv
-
jhsdb
- Hostpot进程调试器,可用于从崩溃的JVM附加到Java进程或核心转储
- jdk 9,才正式引入
#图形化模式,和clhsdb功能对标
jhsdb hsdb --pid 81033
jconsole
- 可视化监控、管理工具
VisuaIVM
-
强大的监控及故障处理程序
-
JDK 9及更高版本,不是内置,需要手动下载
JMC
- 作为JMX控制台,监控虚拟机MBean提供数据
- 可持续收集数据的JFR,并作为JFR的可视化分析工具
- 需手动下载
MAT
- java堆内存分析器,查找内存泄漏并减少内存消耗
JITWatch
- JIT编译器的日志分析器与可视化工具,可用来检查内联决策、热点方法、字节码以及汇编的各种细节