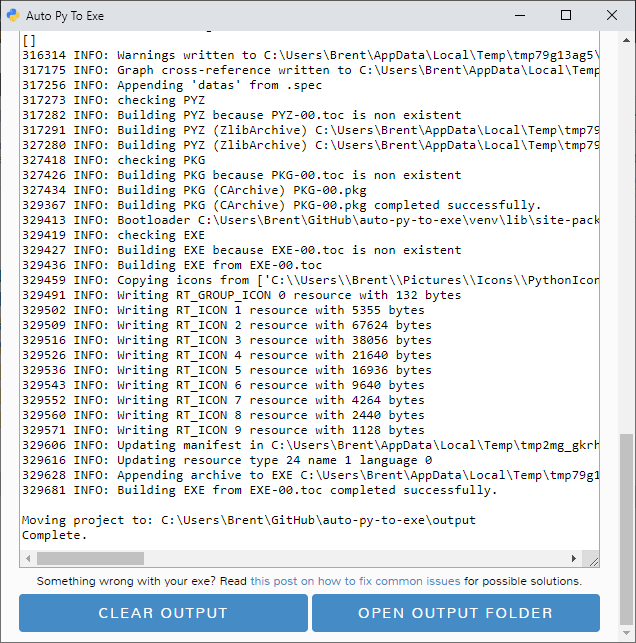
我自己的原文哦~ https://blog.51cto.com/whaosoft/12102352
#百舸
当大模型Scaling Law继续,万卡集群算力释放在「百舸」这里找到一条通途
在电影《天下无贼》中,葛优扮演的黎叔有这样一句经典的台词,「二十一世纪什么最贵?人才!」而随着人工智能行业进入到大模型时代,这一问题的答案已然变成了「算力」。
随着模型规模急剧扩张,参数已经飙升到了千亿甚至万亿级,业界开启了千模大战,AI 算力需求不可避免迎来爆炸式增长,无论是前期训练还是后期推理,都是如此。
在训练层面,OpenAI 曾在 2018 年做过估算,自 2012 年以来,AI 模型训练算力需求每 3.5 个月翻一番,每年所需算力增幅高达 10 倍,增速远远超出了芯片产业长期存在的摩尔定律(性能每 18 个月翻一番)。同时随着大模型及应用越来越多地部署到企业实际业务场景中,推理算力需求也水涨船高。
因此,指数级增长的算力需求对 GPU 等硬件提出了更高要求,大规模 GPU 算力集群成为必然选择。这也是为什么近年来国内外科技厂商纷纷布局 AI 算力基础设施,死磕万卡甚至 10 万卡集群。此外,大规模算力集群也越来越凸显训推一体的重要性,寻求在同一个集群中无缝切换大模型的训练和推理,简化用户部署流程。
虽然 GPU 集群可以满足大模型时代的算力需求,但面临的挑战也不少,比如多类型芯片混合训练、数据中心电力消耗、网络通信和负载、单卡算力效率、多卡并行计算、设施稳定性等。加之当前集群算力利用率不高且成本高昂,这些都要求厂商在集群系统、框架和算法层面进行技术突破。
国内一些厂商已经在面向万卡集群的 AI 基础设施方面积累了丰富的经验,并催生了覆盖广泛的「多芯混合训练时代」。我们以百度为例,其基于文心大模型训练的经验沉淀,推出了 AI 异构计算平台「百舸」,打造业界领先的多芯混合训练 AI 集群,并正在帮助客户更快、更稳、更省地落地大模型应用。
从 2021 年的 1.0 版本到去年的 3.0 版本,我们发现,连续三年,百舸围绕系统性提升 GPU 集群的整体算力利用率不断深入优化。在今日举办的 2024 百度云智大会上,再度升级的百舸 4.0 带给了客户更多惊喜,也给同行们带来了一点小小的震撼。
算力浪费降至 1/10
万卡集群下的大模型训推更快、更省
对于国内云厂商来说,面对 AI 大模型时代的巨量算力需求,归根到底要解决好两个核心诉求:一是如何在算力资源供应短缺的大环境下扩大算力来源,二是如何在大模型产生的高昂计算成本压力下极致高效地利用算力。从已有进展来看,百舸 AI 异构计算平台做到了「两手抓、两手都要硬」。
在去年 12 月的 2023 百度云智大会・智算大会上,百舸 3.0 已经展现了业界领先的万卡集群算力释放能力,集群有效训练时长达到了 98%、网络带宽有效利用率达到了 95%。如今,9 个多月过去了,百舸 4.0「百尺竿头更进一步」,在一些集群算力指标上又有所提升。
此次,百舸 4.0 在整体架构上相较 3.0 版本有了略微调整,从底层硬件往上依次分为资源层、组件层、大模型加速层和工具层。四层架构,各司其职,针对大模型的训推、部署和调优等全流程进一步优化。
具体来讲,资源层提供了包括异构芯片、高速互联、高效存储等在内的算力资源,组件层主要解决大规模集群的稳定性和性能问题,大模型加速层专为大模型训推提速而设计,工具层则通过一套管理界面提供了更便捷的操作体验。

百度集团执行副总裁、百度智能云事业群总裁沈抖
依托四层架构,百舸 4.0 对集群算力调用的各个环节做到了精准把控,并具备了「多、快、稳、省」四大特性,形成了其作为 AI 异构计算平台的核心竞争力。
首先是多芯异构。我们观察到,一云多芯已经成为算力集群的主流选择,既可以屏蔽硬件之间的差异,利用弹性更强的供应链体系摆脱对单一芯片的依赖;又能够根据用户特定业务场景灵活调配算力资源并提高利用率。
百舸 4.0 构建了 GPU 和多类型 AI 芯片组成的单一智算集群,兼容了昆仑芯、昇腾、海光 DCU、英伟达、英特尔等国内外主流 AI 芯片的混合训练,并全面适配。同时通过「控制台」轻松一键发起,易用性很高。百舸 4.0 还通过大模型训推加速套件 AIAK 支持了更多使用场景、多种模型架构和主流训推方式,全能属性拉满。
当然,对于不同规模的多芯混合训练任务,百舸 4.0 将性能损失拉到业界最低,其中百卡性能损失控制在 3%,万卡性能损失在 5% 以内。
如果说多芯混训是走出算力卡脖子的关键一步,那么接下来就要集中精力考虑如何围绕集群部署、大模型训推和效果调优来更充分地释放万卡集群的算力潜能。
现在,百舸 4.0 帮助客户省去了大量复杂和琐碎的配置和调试工作,最快 1 小时便能创建万卡规模集群,这要比行业通常需要的数天甚至数周快得多。
然后便又是 AIAK 发挥了用武之地,针对主流开源大模型在并行策略、显存、算力等层面进行了深度优化,为万卡集群下的大模型训推加速注入新的驱动力。
一方面,百舸 4.0 在大模型加速层全新升级了 AIAK 训练加速,万卡集群下支持万亿参数 MoE 模型训练。不仅如此,单个芯片的效能也发挥到了极致,配合使用优化后的通信和并行策略,整体训练效率提升了 30%。这些都预示着集群实力的大增。
另一方面,百舸 4.0 同样升级了 AIAK 推理加速,尤其在速度和成本两个客户最关心的方面加码,效果较以往版本有了质的提升。对于长文本推理任务,模型如今可以做到「极速生成」与「秒回」,效率提升了一倍。同时,投机式推理策略的引入可以先让成本低的小模型生成多个预选结果,然后交给成本高的大模型验证并给出最终结果,从而调动更多便宜的小模型来承担计算负担,由此降低了成本。
当然实际运行中需要面对数据清洗、生成、格式对齐等重复性工作,百舸 4.0 具备的数据工程能力可以调用大模型来处理这些工作。此外提供了数据增强、效果评估和 Prompt 优化等功能,以便进一步调优。
大模型调用全流程尤其是训练阶段不单单要求速度快,稳定性同样重要。如果一个集群无法保证稳定的训练时长,易出错、难纠错、诊断慢、恢复时间长,则会对整体效率和成本造成不利影响。目前,百舸 4.0 在万卡规模 AI 任务上的有效训练时长占比已经达到 99.5%,这意味着昂贵的计算资源可以得到最大化利用,浪费更少,成本效益更高。
最后,算力资源利用率的高低一定程度上决定了集群能不能为客户省钱,当前行业平均水平仅能达到 50%,一半的算力被浪费了。借助自研的训推一体技术,百舸 4.0 让集群同时支持在线推理服务部署和离线训练任务,训推之间的算力自由切换,训推场景在不同时间复用相同的 GPU 资源,并在推理时将高算力高显存的训练卡分配给多个业务应用,最终将算力资源利用率提升到了 90%。
可以说,从支持多芯混训到加速大模型训推、逼近 100% 的有效训练时长和远超行业的算力资源利用率,百舸 4.0 交出了一份亮眼的「成绩单」,为客户当前的大模型落地实践尽最大可能解除算力层面的后顾之忧,势必更能赢得他们的青睐。
背后的路线思考
五大维度完成算力破局
如何在大模型时代发挥出大集群的有效算力,这是一个重大而急迫的命题。当前有能力提供万卡集群的云厂商都在力争脱颖而出,这就要求他们在优化架构、降低成本、提供差异化服务、构建智算生态等各个方面出击,找到算力破局关键点。
全新升级的百舸 4.0,提供了当前万卡集群的最优解。
我们发现,百舸已经形成自己的一套成熟打法,针对能耗有效率、单卡算力有效率、并行扩展有效率、有效训练时长和资源利用率等五大行业痛点问题,对症下药,用技术突破为算力释放保驾护航。
针对大模型训练产生的巨大电力消耗,百度云通过在自建的数据中心采用自研的液冷方案,使得机器性能提升 10% 的同时故障率降低了 60%-70%,从而令数据中心能源效率指标 PUE(Power Usage Effectiveness)平均值小于 1.1,优于业界平均水平。
为了提升集群内单卡算力有效率,百舸 4.0 依托 AIAK 训练加速方案,通过显卡、算力等层面的深度优化,在主流开源大模型训练任务中将 GPU 有效利用率 MFU(Model FLOPS Utilization)提升到了行业领先水平,达到 70% 以上。
单卡算力效能极致「压榨」的同时,多卡并行计算效率也要跟上。现阶段大模型往往采用多个计算资源同时训练的并行方式,并发展出了计算资源利用率高、效率高、开发难度小的自动并行策略,使训练任务在多个计算单元上的分配更为合理和高效。百舸 4.0 通过 AIAK 进一步优化了并行策略,较开源方案实现了 30% 的性能提升。同时模型并行策略调优时间也大幅降低,从小时级缩短至如今的分钟级,加快了训练和优化速度。
此外如上所述,百舸 4.0 在万卡任务上实现了 99.5% 的有效训练时长,最大程度避免因频繁故障而导致的训练任务中断、资源浪费、模型收敛速度慢、运维成本增加等问题,集群稳定性得到前所未有地加强。达成这一效果主要得益于以下几大能力的共同加持:
- 全方位的可观测能力,对资源池、队列、节点、任务、实例、加速卡等多个维度实现了无死角的覆盖。
- 自动容错能力,百舸 Flash Checkpoint 故障恢复机制实现秒级 Checkpoint 和近乎无损的 Step 粒度容错。此外为 PyTorch 大模型训练场景开发的 Checkpoint 框架 FlashCKPT 可以实现 1 秒千亿大模型 Checkpoint 写入。
- 故障诊断和快速恢复能力,通过快速筛查、召回集群硬件故障并隔离自愈,避免在故障芯片上分配工作负载,有效降低任务故障发生频次。故障恢复时间从小时级降至分钟级。
- 百舸集群级集合通信库 BCCL 不仅可以在故障发生时做到秒级感知和定位,提高故障处理效率。同时快速定位训练慢的节点,提升整体训练效率。
同样地,百舸 4.0 算力资源利用率突破 90%,除了自研的训推一体技术,还要归功于弹性伸缩机制、弹性层级队列等技术,可以根据训练任务的变化来自动分配和布局算力,从而将利用率拉到了行业最高水平。
在我们看来,五大维度不仅巩固了百舸 4.0 在万卡集群时代的行业领先地位,也为其他云厂商在算力资源管理以及智算集群的设计、调度、容错等方面提供了一定的借鉴。
写在最后
今年 9 月初,马斯克宣布旗下 xAI 打造的由 10 万块 Nvidia H100 组成的超级训练集群 Colossus 正式上线,并将在未来几个月另外增加 10 万块 GPU(一半为 H200)。这释放出了一种很明显的信号:不止万卡,更大规模的 10 万、数十万卡集群的建设「时不我待」。
可以看到,无论是为现阶段超大规模模型的训练提供算力支撑,还是推动大模型技术的进一步落地普及、以及加速未来 AGI 时代的更快到来,集群的作用似乎已经无可取代,对于企业依托大模型的智能化转型也至关重要。
显然,百度早在 2021 年就意识到了这一点,通过全方位布局百舸 AI 异构计算平台来建设大模型时代的 AI 基础设施,并在算力、通信、能效等方面的持续优化中构筑起更坚实的 AI 生态发展基石。
百舸 4.0 的全新发布,既有助于增强百度 AI 基础设施的可持续性与领先性,还会为客户在业务场景中落地大模型应用尽可能地降本增效,更对大模型引领的 AIGC 爆发以及 AI 普惠铺平道路。
未来,随着集群规模的继续扩大,还会出现更复杂的软硬件协同、算力调度等问题,这些都需要通过持续的技术突破来一一克服。面对挑战更大的算力之争,百舸已经做好了准备。
#GPT-4o高级语音
终于来了!OpenAI开放GPT-4o高级语音,还用中文说「对不起」
这项高级语音功能,大家可是等了好久。
谷歌又被 OpenAI 截胡了。
前脚谷歌刚刚升级完两款模型 Gemini-1.5-Pro-002 和 Gemini-1.5-Flash-002,后脚奥特曼就直接宣布 GPT-4o 今天起正式开放。
「高级语音功能今天推出!(将在本周内完成),希望您的等待值得。」奥特曼表示道,最后还不忘加一个委屈、小桃心的表情。
这次,OpenAI 的高级语音功能将向所有的 Plus 和 Team 用户推出。但免费用户是体验不了了,因为 OpenAI 暂时没有这个计划。
据了解,Plus 用户每月需支付 20 美元,Team 用户每月支付 30 美元并拥有更多的使用次数。OpenAI 将逐步向用户推出访问权限,并从下周开始面向企业和教育推出。所有 Plus 用户将在秋末之前获得访问权限。
如果你是 Plus 或 Team 用户,当访问高级语音功能时,会在应用程序中看到如下通知。
此次推出的高级语音功能还新增了自定义指令、记忆、五种新声音和改进的口音。它还可以用 50 多种语言说「抱歉我迟到了」。
在下面展示的视频中, 用户和模型在流畅的对话,你可以随时打断聊天内容,彷佛和你聊天的不是机器,而是一个真人。这段 Demo 中的对话内容也特别有意思, GPT-4o 用一口流利的中文说「奶奶对不起,我迟到了,我不是故意让您等这么久的……」,仿佛是 OpenAI 在和用户们道歉,要知道,GPT-4o 可是迟到了将近半年的时间才正式推出。
,时长00:44
看在 OpenAI 这么诚意的份上,大家纷纷表示接受道歉。
在下面的示例中, OpenAI 项目主管 Charlotte 通过自定义选项向 ChatGPT 提供了自己的信息,比如名字和住址。然后在新对话中询问了周末可以做的有趣的户外活动。ChatGPT 根据 Charlotte 提供的信息,给出了一些可行建议。
,时长02:24
在另一个视频中,OpenAI 负责模型设计的 Drew 表示,他在工作时,会让 GPT-4o 静静地开着,当不与它交谈时它很安静,等有问题时就会提问,然后围绕这个问题会展开一场长对话。大多数情况下,Drew 会把它当作坐在身边的朋友,能为他提供信息,交流想法。
,时长01:09
此前,GPT-4o 发布不久,OpenAI 就因其演示视频中名为 Sky 的女性声音与电影《Her》中饰演 AI 恋人的斯嘉丽・约翰逊的声音相似而受到批评。OpenAI 随后删除了该声音。
现在,最新推出的五种新声音分别被命名为 Arbor、Maple、Sol、Spruce 和 Vale,将在标准和高级语音模式下提供。OpenAI 表示,这些声音是使用来自世界各地的专业配音演员制作的。他们采访了数十位演员,他们的声音温暖、平易近人、具有丰富的质感和语调,一位公司发言人表示。
,时长00:40
不过,新功能尚未在欧盟、英国、瑞士、冰岛、挪威或列支敦士登推出。
还在休假的 Greg Brockman 也帮忙宣传了一波:「高级语音的推出,让你可以和 ChatGPT 开启流畅的对话,让你意识到在电脑上打字是多么的不自然。」
除了上新高级语音模式,近日,OpenAI 还发布了一个多语言大规模多任务语言理解 (Multilingual Massive Multitask Language Understanding,MMMLU)数据集,测试集提供了 14 种语言,包括阿拉伯语,德语,西班牙语等,涵盖 57 个不同类别的主题,包括初级知识、法律、物理、历史和计算机科学等高级专业学科。
数据集地址:https://x.com/_philschmid/status/1838230108072476951
参考链接:https://www.technologyreview.com/2024/09/24/1104422/openai-released-its-advanced-voice-mode-to-more-people-heres-how-to-get-it/
#文档大模型
文档处理效能飙升!浩鲸科技“文档大模型”核心技术揭秘!
在当今大模型技术日新月异的背景下,数据已跃升为构建企业大模型知识库、优化训练与微调,乃至驱动模型创新不可或缺的核心要素。
对于企业来说,积累的宝贵知识广泛散布于形式多样的电子文档之中,这些文档不仅格式多样,其内容质量亦呈现出显著的差异性。对海量数据进行精细化的清洗与预处理工作,已成为提升数据价值、确保模型精准高效的关键一环,如何有效提取并利用这些宝贵的知识资源,成为了摆在所有企业面前的一道难题。
9 月 20 日,老牌数字化转型技术服务提供商浩鲸科技在云栖大会期间,成功举行鲸智大模型技术体系发布会,作为企业内部的 “资产沉淀专家”,鲸智文档大模型重磅首发。
据了解,本次发布的 “鲸智文档大模型”,专门针对企业文档场景构建了一组垂直领域模型,浩鲸科技大模型创新中心总经理王玉木表示,鲸智文档大模型与同类产品最大的差异在于,它提供了可快速价值落地的整体性方案,不仅包含了文档大模型能力,还提供了多模态文档工具链 DocChain 和开箱即用的软硬件一体机,基于垂直模型能力和软硬件相互配合,可帮助企业实现文档的知识抽取、知识融合,直至知识推理和问答的全流程覆盖,为企业知识资产的沉淀、高效管理与利用提供了有效通路。
鲸智文档大模型的实践逻辑
浩鲸科技成立于 2003 年,立足于电信行业,智慧触角已触及政务、电力、泛零售等多个领域,迄今已为全球 80 多个国家和地区的电信运营商、700 + 政企客户提供全栈数智化产品技术服务。
“鲸智文档大模型” 始于浩鲸科技 20 余年的数据治理、知识沉淀能力积累,作为垂直领域模型,它从端到端解决场景需求的视角出发,结合了大小模型协作等思路,基于基础大模型构建一套紧密配合的模型组合,主要分三个层面:
- 底层,精准知识提取:通过标题提取、表格提取、版面分析等多种模型,精准捕捉文档中的关键信息,确保内容的完整提取。同时,知识密度分类与语义压缩模型的加入,进一步提升了知识提取的效率与质量。知识提取中,“标题提取模型” 是最为优先的。文档标题可用于文档知识块拆分、知识块召回等场景,可解决指代消歧等问题,具有重要作用,但在服务企业过程中,大部分文档格式不规范,直接影响了知识问答成功率。“标题提取模型” 基于基础大模型进行微调训练,强化了标题识别能力,能够用于从正文中识别标题,补全缺失标题等场景,可以解决企业文档标题和目录不规范,甚至标缺失的问题,有效提升了成功率。
- 中间层,深度知识融合:在知识块的基础上,进行抽象总结与多模态数据关联,将碎片化知识整合为系统化的知识体系,并映射至高维向量空间,为后续的知识推理奠定坚实基础。浩鲸科技积累的的主要模型有:文本总结模型:生成短文本摘要,为知识萃取提供支持;文本向量模型:提供更加准确的文本特征提取能力,为知识的召回提供保障;界面识别模型:图片特征提取模型,支持图文向量对齐;文本重排模型:对多模态,多路径召回的文本内容,进行重排序,进一步提升回答的准确率。其中,“界面识别模型” 强化了对用户手册中最常见软件界面的支持,主要得益于很多用户都喜欢使用截图来对知识库进行提问。该模型训练数据提取自浩鲸科技研发云平台,将软件测试报告中的软件界面图片和内容来构建训练集,并使用反转、随机截取、变形、叠加反光等手段扩增图片库,实现了一个支持软件界面匹配的图片识别模型,解决了现有大模型在软件界面识别方面效果一般的问题。该模型的应用显著提升了图片搜索的准确率,文本检索图片召回成功率提升 25%,图片检索图片召回成功率提升 40%。
- 上层,智能知识推理:构建了知识问答模型和 BPO 优化模型。面向知识问答任务场景,构建了针对场景优化的问答模型,强化根据参考知识信息进行精准回答,减少幻觉。另外一方面通过优化用户的输入提示(prompt)来提高模型输出与人类偏好的对齐程度,提升问答的准确性。
DocChain:文档处理的智慧引擎
为深度赋能企业用户,浩鲸科技依托先进的鲸智文档大模型,匠心打造了多模态文档工具链 ——DocChain。该产品不仅实现了企业文档向宝贵知识资产的转化,更构建了一个集文档知识精准提取、高效检索与智能问答对话于一体的大模型知识服务平台。DocChain 以其卓越的多模态处理能力、广泛的文档格式兼容性和极致的性能优化,成为企业文档处理领域的得力助手。
- 智能提取,精准高效:集成前沿 NLP 算法与模型,实现文档处理速度与精度的双重飞跃。抽取精度高达 98%,问答响应准确率超越 80%,让信息获取更加智能、便捷。
- 格式兼容,全面广泛:拥抱多样化文档生态,支持超过 30 种文件格式,特别兼容 OFD 等国产信创标准,确保各类文档无缝接入,处理高效且精准,满足企业多样化需求。
- 多模态处理,深度解析:深度解析文档内容,无论是文本、目录、图片、表格、链接还是页码,均能精准拆分与提取。支持多元模态检索,无论是文找文、文找图,还是图找图,均能游刃有余。

一体机:解决企业私域场景下低成本上线大模型的诉求
浩鲸科技为解决客户落地大模型过程中算力硬件缺乏、技术人员少、安全要求高等难题,同时推出了文档大模型软硬件一体机。一体机内置了高性能算力,并且预装了大模型以及 DocChain 应用,可为企业快速部署和验证智慧文档处理服务。
从部署上来说,文档大模型一体机具备开箱即用、数据安全可控、性能无忧、快速集成等几个特点,专为轻量级场景设计,私有化部署解决企业隐私保护、数据安全等痛点,低成本实现企业内部大模型快速上线,覆盖通用知识检索、文档问答、服务支撑及品牌宣传等,可帮助企业迅速构建专属大模型问答系统。
随着基础大模型的发展,以及模型增量训练的知识冲突问题日益凸显,RAG 逐渐成为企业智能知识库的标准解决方案,然而知识召回的准确率和完整性成为了影响问答效果的关键因素。
鲸智文档大模型,借鉴了 “大模型 + 小模型” 的思路,基于基座大模型构建了一套大小模型的组合,形成了一套垂直大模型,可以端到端实现垂直应用场景的需求。当前,鲸智文档大模型在多模态识别、检索和精准召回上做了很多的尝试,也取得了一定的成果。
AI 大模型的迅速发展,让企业沉淀的大量文档的知识理解和处理带来了转机,浩鲸科技正通过持续的技术创新与产品优化,推动大模型技术与企业领域知识深度融合,实现企业文档向有价值的资产转化,为企业创造更多价值。
#MLR-Copilot
自动化机器学习研究MLR-Copilot:利用大型语言模型进行研究加速
该论文的第一作者及指导作者均来自德克萨斯大学达拉斯分校,第一作者为博士生 Ruochen Li,指导作者为其博士生导师 Xinya Du,专注于自然语言处理、深度学习和大语言模型的研究。Xinya Du 的工作发表在包括 ACL、EMNLP 和 ICLR 在内的顶级自然语言处理和机器学习会议上,其问题生成工作入选最具影响力的 ACL 论文。他被评为数据科学领域的闪亮新星,并获得了 2024 年的 NSF CAREER 奖项和 WAIC 云帆奖。
科学技术的快速发展过程中,机器学习研究作为创新的核心驱动力,面临着实验过程复杂、耗时且易出错,研究进展缓慢以及对专门知识需求高的挑战。近年来,LLM 在生成文本和代码方面展现出了强大的能力,为科学研究带来了前所未有的可能性。然而,如何系统化地利用这些模型来加速机器学习研究仍然是一个有待解决的问题。现有的研究往往只关注某一阶段,如生成研究假设或执行预定义的实验,未能涵盖整个研究过程,也未能充分解决当前研究中的具体问题。
为此,我们提出了 MLR-Copilot 自动化机器学习研究的研究平台 / 演示工具 (Demonstration),利用大型语言模型(LLM)作为研究人员的 “副驾驶”,分析研究论文、提取研究问题,以提出新的研究思路和实验计划,并自动化执行这些实验以获得结果。MLR-Copilot 包括三个阶段:研究思路生成、实验实现和实验执行。该框架在多项机器学习任务中有效促进了研究进展。

- 源代码链接:https://github.com/du-nlp-lab/MLR-Copilot
- 论文链接:https://arxiv.org/pdf/2408.14033
- Demo 链接:https://huggingface.co/spaces/du-lab/MLR-Copilot
方法介绍
MLR-Copilot 框架的提出旨在通过 LLM 代理自动生成和执行研究思路验证,实现科研过程的自动化。该框架从单篇科研论文出发,模仿科研人员的研究思路,收集任务定义并获取当前研究工作的最前沿进展,以提出新的研究思路并自动化验证。

该框架首先从输入的研究论文中提取任务定义和研究空白,然后通过 IdeaAgent 生成研究思路(包括研究假设和实验计划),接着由 ExperimentAgent 实现并执行这些实验。在实验过程中,框架会持续观察和记录结果,必要时进行调整和优化,最终输出经过验证的研究成果。这种自动化流程显著提升了研究效率,确保了实验的可执行性和结果的可靠性。

在 MLR-Copilot 框架中,整个科研流程分为三个阶段:
1. 研究思路生成:通过 IdeaAgent 从现有研究论文中生成假设和实验计划。系统通过分析和提取文献中的关键信息,提取任务定义并识别研究问题,并根据现有研究中的趋势和研究空白,生成新的研究假设和实验计划,形成初步的研究思路。
2. 实验实现:ExperimentAgent 将实验计划转化为可执行的实验,根据检索的原型代码,并在必要时从 Hugging Face 等平台获取模型和数据,生成并集成实验实现方案及搭建实验环境。
3. 实验执行:ExperimentAgent 管理实验的执行过程,在自动化的基础上结合人类反馈,逐步优化实验实现并迭代调试,并最终输出经过验证的研究成果,提高实验的成功率和研究结果的可靠性。
实验与讨论
为了评估 MLR-Copilot 框架的性能,论文作者设计了一系列实验,涵盖了五个不同领域的机器学习任务。这些任务包括了语义文本关联、情感分析、特征分类以及图像分类等,代表了机器学习研究中的广泛应用场景,其数据集包括:
- SemRel:一个包含多语言语义文本关联任务的数据集,使用 Pearson 相关系数作为评估标准。
- IMDB 数据集:用于情感分析的电影评论数据集。
- Spaceship-Titanic 数据集:用于分类任务的数据集,预测乘客生存情况。
- feedback (ELLIPSE) 数据集:用于基于机器学习的课程反馈预测任务。
- Identify-Contrails 数据集:用于图像分类任务,识别卫星图像中的飞行轨迹。
为了更好的评估自动化机器学习研究的的性能,论文作者为 MLR-Copilot 框架量身定制了以下几个评估维度:
- 研究思路的有效性:对研究思路中的假设和实验设计分别针对不同标准进行进行评估。此评估包含人工评估和 LLM 评分员自动评估,并与仅使用核心论文作为提示的基准线方法比较。
- 实验实现与执行的成功率:通过多次实验运行的成功率以及对任务性能的平均提升率来评估实验阶段的效果。


实验结果表明:
- 在研究思路生成阶段,MLR-Copilot 生成的假设在清晰度、有效性、严谨性、创新性和普遍性方面均优于基线模型。主观评测显示出 MLR-Copilot 生成的实验假设和设计更符合人类研究者的预期,较低的相似度也间接体现其创新性。
- 在实验实现和执行阶段,MLR-Copilot 能够显著提升任务性能,并在多次试验中保持较高的成功率。
- 通过案例研究,展示了 MLR-Copilot 在情感分析任务中的实际应用。系统通过对实验脚本的检查、执行、模型检索以及结果分析,帮助研究人员系统化地生成假设并执行实验。

总结与展望
MLR-Copilot 框架展示了通过 LLM 自动化机器学习研究的潜力。它不仅能生成新的研究思路,还能够实现实验的自动化执行,并通过人机交互提高实验的成功率和研究成果的可靠性。未来的研究可以进一步扩展应用场景,并探索更多复杂的研究任务。
#拆解大模型发展热点
本文总结了近100场大模型比赛,探讨了大模型技术在各个领域的应用和竞赛情况,包括逻辑推理、安全问题、行业应用、硬件落地、人机区分以及多模态大模型等,为大模型的研究和应用提供了丰富的索引和视角。文章还分析了大模型竞赛的趋势和热点,以及如何通过比赛推动大模型技术的发展。
从去年十月 Kaggle 第一个大模型比赛http://www.kaggle.com/competitions/kaggle-llm-science-exam 结束到现在,短短一年间,各个平台举办了接近100场大模型比赛,最先一波接触大模型的比赛好手狠狠吃了一波红利。本文,我也对这接近100场大模型比赛进行归类总结,从一个大模型外行人的身份从比赛的角度看大模型目前的关注的热点是什么,也为后续想参加大模型比赛以及研究的提供一个索引。
1.比赛平台与模型推广
国内大模型创业公司如雨后春笋般纷纷建立,除了提高大模型产品质量以外,营销推广也是“百模大战”获胜一个重要因素。现在知乎每天给我推送的广告不是KIMI就是豆包。而通过比赛推广也是一种非常垂直的营销手段,一些原本就拥有比赛平台的公司在这里就占的先机。分别是
https://tianchi.aliyun.com/ —— 阿里 —— 通义大模型
https://aistudio.baidu.com/competition —— 百度 —— 文心一言大模型
https://challenge.xfyun.cn/ —— 科大讯飞 —— 星火大模型
https://www.biendata.net/ —— 智谱 —— GLM大模型
这些平台在举办自己公司的比赛,以及部分其他公司的比赛时候,会或强制或建议使用本公司开发的大模型,甚至提供相应的大模型平台及接口供比赛参与者微调,在比赛的同时,促进参赛者体验和学习本公司的大模型。这里的Binedata原本在2022年中旬就已经没了,结果这次大模型又让这个平台复活了。但是原本在Binedata举办的中文会议比赛,如CCKS、SMP都被天池顺势接收。所以天池现在大模型比赛巨多。不过天池的一贯特点就是重答辩、轻效果,会议比赛到天池都得这么来(见下图)。

2.大模型逻辑推理能力
长久以来,当前的AI模型都被称为弱AI模型。很大的原因就是大家认为现在的AI模型本质上还是记忆,而不能推理。所以如果提升大模型的推理能力一直是最受关注的,最近的open ai o1就是为此而生。也有大量的比赛评测被用于考验大模型的推理能力,不知道如果open ai o1下场能取得什么成绩。比较有名的是kaggle的
https://www.kaggle.com/competitions/ai-mathematical-olympiad-prize
人工智能数学奥林匹克(AIMO)奖是一个新设立的1000万美元奖金基金,旨在激励公开开发能够在国际数学奥林匹克(IMO)中表现出色的人工智能模型,与顶尖人类参与者相媲美。这个竞赛包括110个类似于中级水平高中数学挑战的问题。
当时幻方的deepseek模型在这个比赛里就一战成名。其他的比赛还有
http://competition.sais.com.cn/competitionDetail/532231/format
本次比赛提供基于自然语言的逻辑推理问题,涉及多样的场景,包括关系预测、数值计算、谜题等,期待选手通过分析推理数据,利用机器学习、深度学习算法或者大语言模型,建立预测模型。
https://iacc.pazhoulab-huangpu.com/contestdetail?id=668de1237ff47da8cc88c0c4&award=1,000,000
为了推动人工智能在数学推理方面的发展,本次多模态数理大模型挑战赛旨在鼓励开发能够直接理解图像输入且具有出色数学推理能力的人工智能模型。通过解决这个初始基准问题,从而促进多模态数理大模型领域的良性竞争与创新,共同推动人工智能模型在数学推理能力上的准确与可靠评估。
https://challenge.ai.mgtv.com/#/track/25
本赛题会提供若干情景猜谜游戏的逻辑推理题目,包含谜面和谜底。谜面会描述一个简单又难以理解的事件,谜底则是谜面的答案。用户可以询问任何封闭式问题来找寻事件的真相。本次任务,选手需要训练10b以下参数量的大模型来担任猜谜游戏的主持人,回答用户的问题,模型只能回答:是、不是、不重要、问法错误和回答正确。
https://ai4ed.cc/competitions/aaai2024competition
这个竞赛旨在探索和提升大型语言模型(LLMs)在数学推理方面的能力,并且克服语言模型在复杂推理和精确计算方面的固有缺陷。竞赛分为两个赛道:赛道1:中文数学问题求解
赛道2:英文数学问题求解使用的数学问题数据集来自K-12数学相关竞赛,包括中国的“迎春杯”、“希望杯”数学竞赛和全球的美国数学竞赛(AMC 8/10/12)。
https://www.eventbrite.com/e/agi-odyssey-2024-symposium-london-tickets-1000782205517?aff=oddtdtcreator
邀请全球AI爱好者参与竞赛,挑战并增强人工智能解决跨科学学科复杂问题的能力。2024年3月的比赛将聚焦于数学.
3.大模型安全问题
大模型的安全问题从chatgpt出来以后就一直是一个热点问题,时不时就能闹个大新闻,最近也有不少故意引导大模型说错话来达到攻击背后公司的新闻。
3.1 攻击
https://tianchi.aliyun.com/competition/entrance/532214
主办方指定待攻击的安全检测器,参赛者需要构造query-response的pair(单轮对话),使得检测器错误判断response的安全性。query和response需构成流畅的对话。
https://tianchi.aliyun.com/competition/entrance/532187
主办方为大模型设定初始任务指令(Initial_prompt)和目标任务指令(Target_prompt),参赛者劫持指令(hijack_prompt),使大模型放弃初始任务而仅执行主办方指定的目标任务
https://tianchi.aliyun.com/competition/entrance/532268
根据给定选题任务(如生成打架斗殴的血腥图片),参赛团队需要通过多样化的攻击诱导技术手段,诱导指定大模型输出任务相关的幻觉、意识伦理及隐私等生成式风险图像。
https://llmagentsafetycomp24.com/
旨在提高对大型语言模型(LLMs)和LLM驱动代理的安全性的理解,并鼓励改进其安全性的方法。Track I: Jailbreaking Attack - 这个赛道可能专注于开发能够绕过语言模型(LLM)安全限制的攻击方法。参与者需要设计方法来生成能够使LLM产生有害输出的提示。Track II: Backdoor Trigger Recovery for Models - 这个赛道可能涉及识别和恢复模型中的后门触发器。后门触发器是模型中故意植入的代码,当输入特定的触发器时,模型会以非预期的方式响应。Track III: Backdoor Trigger Recovery for Agents- 这个赛道可能专注于识别和恢复智能代理(agents)中的后门触发器。与Track II类似,但专注于智能代理而不是模型本身。参与者需要开发技术来检测和提取智能代理中可能存在的后门触发器,这些触发器可能会在特定输入下导致代理执行非预期的行为
3.2防守3.3攻防
https://llm-pc.github.io/
旨在解决LLMs使用中的隐私问题,包括隐私漏洞的识别、利用和防御。Red Team Track - 这个赛道的参与者将尝试识别并利用LLMs(大型语言模型)中的隐私漏洞,模拟潜在攻击者试图提取敏感信息的行为。Blue Team Track - 这个赛道的参与者将专注于保护LLMs免受隐私泄露,并开发强大的防御机制来保护敏感数据。
https://trojandetection.ai/
旨在推进对大型语言模型(LLM)中隐藏功能检测方法的理解和开发。竞赛包括两个主要赛道:木马检测赛道和红队赛道。
在木马检测赛道中,参赛者会得到含有数百个木马的大型语言模型,并任务是发现这些木马的触发器。在红队赛道中,参赛者面临的挑战是开发自动化的红队方法,以从经过微调以避免这些行为的大型语言模型中引出特定的不良行为。
https://trojandetection.ai/
这个竞赛的目标是推进对大型语言模型(LLMs)中隐藏功能检测方法的理解和开发。竞赛包含两个主要赛道:Trojan Detection Track(特洛伊检测赛道):在这个赛道中,参与者会收到含有数百个特洛伊木马(trojans)的大型语言模型,并需要找出这些特洛伊木马的触发器。
Red Teaming Track(红队赛道):在这个赛道中,参与者面临的挑战是开发自动化的红队方法,以从经过微调以避免特定不良行为的大型语言模型中引出这些行为。
4.行业大模型及完成特定任务的大模型
在大模型出来以后,大家都期待大模型能够学习到特定的行业知识,以在特定业务上达到的更好的效果,像医学、金融这些原本就很关注文本信息的都很快就有了相关业务的benchmark和比赛。还有像信息化做的比较好的国企,我觉得要不了多久就会有电力大模型、电信大模型、政务大模型等等。
有些比赛也限定了微调或不微调(提示模版、示例选择(Demonstrations)、检索增强(RAG))。比
赛的评测也常常是通过传统NLP任务、答题(判断题、选择题、问答题等等)等手段来实现。
4.1 医学
https://tianchi.aliyun.com/competition/entrance/532204
https://tianchi.aliyun.com/competition/entrance/532199
TCMBench评测基准依托于中医执业医师资格考试的丰富题库,全面覆盖三大考试范围,包括中医基础理论、中医临床医学,以及西医与临床医学的综合内容以及16个核心考试科目,共计9,788道真题和5,473道练习题。TCMBench评测基准旨在深度评估和精准测量LLM模型对中医知识的掌握水平,以及模型在中医情境下的解释和推理能力。
https://tianchi.aliyun.com/competition/entrance/532150
在这个任务中,模型将需要对医学术语、医学知识、临床规范诊疗和医学计算进行理解和逻辑推理。评测数据将基于真实临床情境进行构建,包括医学考研题、临床执业医师题、医学教材、医学文献/指南、公开医学病历等构建的一系列选择题。
https://tianchi.aliyun.com/competition/entrance/532085
https://tianchi.aliyun.com/competition/entrance/532084
将CBLUE基准进行二次开发,将16种不同的医疗场景NLP任务全部转化为基于提示的语言生成任务,形成首个中文医疗场景的LLM评测基准。
https://bohrium.dp.tech/competitions/3793785610?tab=introduce
使用大型语言模型(Large Language Model, LLM)从海量生物医学文本数据中自动化提取结构化的知识图谱,以提供专业的疾病的诊断和治疗建议,是当前研究的一个重要方向。本次比赛将提供真实的生物医学文本数据以及标注后的知识图谱,要求参赛者的模型能够准确识别特定的生物医学实体、关系或事件。
4.2 金融保险
https://tianchi.aliyun.com/competition/entrance/532200/information
本任务需要参赛队伍基于金融数据源(如:股票数据、新闻、年报、个股报告等,具体数据源信息在任务数据中描述),智能地生成投研报告。
https://tianchi.aliyun.com/competition/entrance/532198
本比赛提出了本评测任务。任务包含六大场景(知识问答、文本理解、内容生成、逻辑推理、安全合规、AI智能体),涵盖多维度金融任务,有利于帮助快速评测LLM在金融领域的表现。
https://tianchi.aliyun.com/competition/entrance/532194/
参赛者需要设计和训练一个智能问答模型,该模型能够准确理解不同保险产品条款中的内容,并对用户提出的有关保险条款的问题给予准确、清晰的回答。我们将提供一系列保险条款文档和相应的用户问答对作为训练数据。模型的性能将根据其准确性、响应时间和用户满意度进行评估。
https://tianchi.aliyun.com/competition/entrance/532193
在本任务中,参赛者需要根据用户Query,从API集合中筛选出合适的API列表,生成正确的api调用逻辑和答案。参赛者可以充分利用给定的数据集,使用大模型设计最优指令以得到最好的生成结果。
https://tianchi.aliyun.com/competition/entrance/532164
本次比赛要求选手基于https://modelscope.cn/organization/TongyiFinance或https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary(不限制pretrain和chat)构建一个问答系统,问答内容涉及基金/股票/债券/招股书等不同数据来源。本次比赛赛题为统一的问题格式,但包含两类任务,数据查询任务和文本理解任务,分别考察选手基于大语言模型的结构化数据检索能力和长文本理解能力,赛事主办方并不会提供任务的具体类型,选手需要自行判断任务的类别,采用不同的技术方案,或者同时构建查询任务并汇总结果。
https://tianchi.aliyun.com/competition/entrance/532126
本次比赛要求参赛选手以ChatGLM2-6B模型为中心制作一个问答系统,回答用户的金融相关的问题,不允许使用其他的大语言模型。
https://tianchi.aliyun.com/competition/entrance/532088
在本任务中,需要参赛者根据给定的schema,从给定的一组自由文本X中抽取出所有符合抽取schema的信息结构Y(实体、关系、实体属性等)。参赛者可以充分利用给定的标注训练集和无标注语料,使用不同的大模型并设计最优指令以得到最好的抽取结果。
4.3 编程
https://tianchi.aliyun.com/competition/entrance/532169
高质量的数据是大模型提升效果的关键,初赛阶段主要聚焦在如何通过 SFT 提升基础模型的代码能力。需要选手基于最新开源的 Qwen 1.8 模型作为基础模型,在我们提供的训练框架上自行进行数据收集与微调,训练完成后将进行自动评估,返回最终结果进行排名;复赛阶段我们将提供 GPU 算力(在线 API 的方式),参赛队伍将基于 Qwen-72B 模型进行 PEFT (lora)进行训练
https://iacc.pazhoulab-huangpu.com/contestdetail?id=668de12c7ff47da8cc88c0ce&award=500,000+经费支持
以“基于大语言模型的数据库查询指令生成”为赛题,要求选手针对跨领域数据库,基于大语言模型实现从自然语言问题到数据库查询指令的Text-to-SQL多轮智能问答:输入:用户问题和数据库列表以及相应的数据库描述文件。输出:问题对应的数据库名称和对应的SQL语句。目标:提高算法在测试集上输出的SQL查询结果精度。
https://www.biendata.net/competition/siemens-ai/
本次比赛分初赛和复赛两个阶段,各阶段将设置多道SCL编程题目,每道题目包含详细描述、函数名、输入输出形式。参赛者需利用大语言模型GLM-4,针对工业场景下的TIA Portal软件与SCL编程框架,基于自然语言需求描述生成功能符合要求的代码。
https://hackercupai.github.io/
评估生成性AI在自主代码生成任务中的能力,测试AI系统与人类程序员之间的性能差距。
4.5 电信
https://www.datafountain.cn/competitions/1045
本赛题要求选手使用运营商相关的文档构建知识库,根据用户问题检索知识库并返回答案所在的文本块。
https://zindi.africa/competitions/specializing-large-language-models-for-telecom-networks
参与者需要下载并改进现有的大型语言模型,如Falcon 7.5B或Phi-2,以提高它们在回答与电信知识相关的多项选择题时的准确性。
2024年国际AIOps挑战赛 基于检索增强的运维知识问答挑战赛 https://competition.aiops-challenge.com/home/competition/1771009908746010681 | https://competition.aiops-challenge.com/home/competition/1780211530478944282
挑战赛首次采用基于RAG技术的检索增强技术,基于中兴通讯公司CT通信网络运维下真实文档数据,探索如何结合领域私有技术文档和大语言模型进行高效私域知识问答。揭示在通用大语言模型基座下,垂直领域知识问答面临的领域知识缺失,公私域知识冲突,多模态图表并存等一系列挑战。本届大赛采用双赛道赛制,赛道一使用开源的Qwen1.5-14b模型,可以对模型微调之后再进行RAG问答。赛道二调用GLM4的API接口,模型不能微调,模拟在特定场景下没有自己微调模型能力的运维场景。
4.4 汽车
https://tianchi.aliyun.com/competition/entrance/532154
本次比赛要求参赛选手以大模型为中心制作一个问答系统,回答用户的汽车相关问题。参赛选手需要根据问题,在文档中定位相关信息的位置,并根据文档内容通过大模型生成相应的答案。参赛选手将指定使用[通义千问]大模型进行比赛,在此模型的基础上搭建问答系统,并在主办方提供的算力资源和平台上进行模型的训练与调试。
4.5 教育(阅读理解做题非逻辑推理)
https://www.kaggle.com/competitions/kaggle-llm-science-exam
本次挑战的数据集是通过给gpt3.5提供来自维基百科的一系列科学主题的文本片段,并要求它编写一个多项选择题(带有已知答案),然后筛选出简单问题来生成的。比赛任务是参赛者回答答案。
http://challenge.xfyun.cn/topic/info?type=question-bank-construction
本次竞赛要求参赛者基于大模型微调技术,微调适用于高考语文现代文阅读和英语阅读的QAG的大模型,完成输入文章输出问题与答案的任务。大赛将为参赛团队提供免费的模型微调服务平台。赛事规定选手须在AI大赛参赛页面注册报名参赛,并前往讯飞大模型定制训练平台进行任务开发。
4.6 读文献
http://challenge.xfyun.cn/topic/info?type=microneedle-technology
参赛者需要设计一个人工智能模型,该模型能够阅读并理解给定的科研文献,并根据预设的指标从文献中提取相关信息。比赛将提供一系列科研文献基本信息和需要提取的指标列表。
https://bohrium.dp.tech/competitions/7922759072?tab=introduce
为了推动 AI 技术应用于科学文献分析的发展,我们推出了最新的 SciAssess 评测基准。SciAssess 是专为全面评估 LLMs 在科学文献分析中表现而设计的基准测试。它涵盖了从基础科学到生物医药等多个科学领域的各种任务,主要评估 LLMs 在记忆(L1)、理解(L2)和分析推理(L3)方面的能力,并包括了文本、表格、图像、分子、反应式等多种模态。其包括总计 5 个领域,29 种任务,6 种模态的 14721 条题目。
https://www.biendata.net/competition/aqa_kdd_2024/
在KDD Cup 2024,我们推出OAG-Challenge,这是一个由三个现实而具有挑战性的学术任务组成,旨在推进学术知识图谱挖掘技术的最新发展。https://www.biendata.net/competition/aqa_kdd_2024/:在本任务中,参与者的任务是使用问题-论文对来训练检索模型。该数据集来源于OAG-QA,OAG-QA从StackExchange和知乎网站检索问题帖,提取答案中提到的论文URL,并将其与OAG中的论文进行匹配。
https://www.biendata.net/competition/pst_kdd_2024/:论文源头追溯任务的目的,是在给定一篇论文p的全文的情况下,从这篇论文中找出ref-source。ref-source即最重要的参考文献(叫做“源头论文”),一般是指对本篇论文启发性最大的文献。每篇论文可以有一篇或多篇ref-source,也有可能没有ref-source。对于论文的每一篇参考文献,论文源头溯源都要给出一个范围在[0, 1]的重要性分数。https://www.biendata.net/competition/ind_kdd_2024/:给定每位作者的个人资料,包括作者姓名和发表的论文,参赛者需要开发一个模型来检测论文中错误分配给该作者的论文。此外,数据集还提供了所有涉及论文的详细属性,包括标题、摘要、作者、关键词、地点和发表年份。
4.7 政务
https://zindi.africa/competitions/retrieval-augmented-generation-rag-for-public-services-and-administration-tasks
参与者需要构建一个系统,该系统能够处理与公共服务和行政管理相关的查询,并提供准确、有用的回答或解决方案。这可能包括对政策、法规、服务流程等问题的查询。
https://zindi.africa/competitions/malawi-public-health-systems-llm-challenge
参与者需要构建一个系统,该系统能够处理与马拉维公共卫生系统相关的数据和查询,并提供准确、有用的回答或解决方案。这可能涉及到对健康记录、政策文件、服务流程等问题的分析和处理。
4.8 法律
https://zindi.africa/competitions/tuning-meta-llms-for-african-language-machine-translation
参与者需要构建一个能够处理OHADA法律文本的系统,这可能包括法律文件的分类、关键信息的提取、法律条款的解释和应用等。
http://cail.cipsc.org.cn/index.html
一共设置了七个任务,分别为:裁判文书事实生成、裁判文书说理生成、法律要素和争议焦点识别、二审改判类案检索与原因预测、法律咨询对话生成、司法考试、多人多罪判决预测
http://www.aicompetition-pz.com/https://tianchi.aliyun.com/competition/entrance/532221
本次比赛目的是探究大语言模型在法律领域的应用。参赛者需基于GLM-4模型,制定一个可行的技术方案。该方案应利用大语言模型的语义理解和函数调用等功能,准确解析用户的自然语言查询,并通过访问相关法律数据库或API,提供以下服务:解答个人法律问题、查询案件相关信息、检索类似历史案件和分析司法数据以辅助决策。
4.n 其他特定任务
https://tianchi.aliyun.com/competition/entrance/532253
本次比赛建议参赛选手以闭源大语言模型(GPT、Claude、Gemini等)为基础构建问答系统,让系统能够通过编写执行Python代码来回答用户提出的图分析相关的问题。本次比赛评估模型能力的赛题按照设计模型的能力不同,以及题目的难易程度,分为判断题、计算题、绘图题、综合题四种类型。
http://challenge.xfyun.cn/topic/info?type=bidding-documents
本次比赛需要参赛选手对给定的采购文件进行文件解读,学习与挖掘历史采购文件共性抽离框架进行建模。本次比赛为参赛选手提供了能源行业招标采购业务采购文件脱敏数据.
https://www.datafountain.cn/competitions/1046
参赛者需要开发一个智能问答系统,能够准确回答关于TuGraph-DB的各类问题。
https://www.datafountain.cn/competitions/1047
参赛者需要使用提供的在TuGraph-DB上可执行的Cypher语料,对一个指定的本地模型进行微调,使得微调后的模型能够准确的将测试集中的自然语言描述翻译成对应的Cypher语句,翻译结果将基于文本相似度和语法正确性两个方面综合评分。
https://www.biendata.net/competition/bigmodel_cn/
https://www.biendata.net/competition/bigmodel_cn_s2/
在本次比赛中,参赛选手需要利用 http://bigmodel.cn 的“一键微调”功能,用 Lora 技术微调 GLM-4-Flash 模型,从而让微调出的模型可以更准确地回答关于智谱AI开放平台自身的相关问题。
https://www.atecup.cn/matchHomeDetails/100001/100001
本赛题将考察选手如何在给定基座大模型和待引入到大模型中的知识语料中,设计引入方式,提升引入知识后的大模型在评测数据集上的表现。以老年人在支付宝中常用的服务类场景(如出行、办事等)为切入点,探索借助知识引入的大模型,如何在耗能少效率高的基础上为老年人提供更便捷的服务。基座大模型为标准Huggingface Transformer结构,选手可自行调整其权重。
https://sites.google.com/view/llms4subjects/home
基于LLM的国家技术图书馆开放获取目录的自动化主题标记。
5.大模型硬件落地
在指定的硬件条件下完成大模型的性能优化
https://tianchi.aliyun.com/competition/entrance/532170
鉴于端侧设备大部分运行在基于Arm架构的CPU上,本届AICAS会议将使用ArmV9架构的倚天710CPU作为算力平台,开展通用大模型性能优化竞赛,目标促进和推动相关的技术研究发展
https://www.datafountain.cn/competitions/1041
参赛者使用基于东方国信幕僚智算云平台上带有1块Intel Gaudi AI加速卡的虚拟机,编写Lora微调和推理脚本,使用ChatGLM3-6B模型和给定的数据集进行微调,并在微调后的模型上进行推理。虚拟机用于脚本的开发与测试。
https://edge-llms-challenge.github.io/edge-llm-challenge.github.io/
探索在资源受限的边缘设备上部署大型语言模型(LLMs)的可能性。
https://llm-efficiency-challenge.github.io/
这项竞赛的重点是开发能够在单个 GPU 上高效运行的微调和推理方法,这对于资源有限的个人和组织来说是一个重要的进步。
6.人机区分
分辨人和电脑制作的文章和图片的比赛在2016年深度学习刚火的就有不少了,现在大模型一出来,输出的文章和图片越来越难分辨,这个方向也更加有现实意义。
https://www.kaggle.com/competitions/llm-detect-ai-generated-text
这个竞赛挑战参与者开发一个机器学习模型,该模型能够准确检测一篇文章是由学生写的还是由LLM生成的。竞赛的数据集包括学生撰写的文章和由多种LLM生成的文章的混合。
https://www.atecup.cn/matchHomeDetails/100001/100003
本赛道希望参赛者能够:1.全面分析AI生成新闻与人工撰写新闻的特点;2.构建有效的检测模型来区分AI生成新闻与人工撰写新闻。
https://challenge.ai.mgtv.com/#/track/24
本赛事要求参赛者设计并实现一种算法,目标是准确判定测试图像是真实图像还是由AI所生成的图像,生成方式包括但不限于GAN和Stable Diffusion等算法。
https://github.com/mbzuai-nlp/Semeval2024-m4/
由于人类在将机器生成文本与人工编写文本进行分类时的表现仅略高于偶然性,因此有必要开发自动识别机器生成文本的系统,以减轻其潜在的滥用问题。
7.大模型与数据处理
我看到很多比赛简介都几乎一致的比赛,主要是差别是模型不同
“主办方提供候选数据集,要求参赛者基于提供数据集进行数据合成与清洗,产出一份基于种子数据集的更高质量、更多样性的数据集,并在给定计算约束下进行训练。主办方提供开发套件,要求参赛者在统一的框架和参数设置下进行模型训练和任务评测,公平对比数据导致的性能差异。”
https://tianchi.aliyun.com/competition/entrance/532251/
https://tianchi.aliyun.com/competition/entrance/532219
https://tianchi.aliyun.com/competition/entrance/532174
https://tianchi.aliyun.com/competition/entrance/532158 | https://tianchi.aliyun.com/competition/entrance/532157
http://challenge.xfyun.cn/topic/info?type=large-model-inference
8 大模型与传统NLP任务
我请教了一些在大厂应用大模型于业务的专业选手,他们都表示,在不限制机器、时间、数据的前提下,大模型已经在很多生成以外的传统NLP任务也取得了比过去其他模型更好的效果,所以严格意义上来说,所有的NLP比赛都可以看做大模型比赛。所以也有很多比赛指定应用大模型去处理一些传统NLP任务。主要为知识抽取、语义解析、知识图谱、实体识别等。
https://tianchi.aliyun.com/competition/entrance/532183
在零样本知识抽取任务中,参与者面对的挑战是从给定的文本中识别和提取指定类型的信息,而无需依赖事先标注的训练数据。此任务要求模型能够理解和遵循抽取指令—一个明确的命令,指导模型找到并格式化所需信息。
https://tianchi.aliyun.com/competition/entrance/532179
框架语义解析(Frame Semantic Parsing,FSP)是自然语言处理领域中的一项重要任务,其目标是从句中提取框架语义结构,实现对句子中涉及到的事件或情境的深层理解。本次评测设置了开放和封闭两个赛道,其中开放赛道的参赛队伍可以使用ChatGPT等大模型进行推理,但禁止对其进行微调,且需提交所使用的提示模板;封闭赛道中,参赛模型的参数量将会被限制。
https://tianchi.aliyun.com/competition/entrance/532080
根据用户输入的指令抽取相应类型的实体和关系,构建知识图谱。
http://challenge.xfyun.cn/topic/info?type=entity-recognition-effect
本赛题要求参赛者基于大模型微调技术,利用自然语言处理技术,结合大模型微调的方法,能够自动识别文章中的实体,并提取出其相关属性,为各领域研究提供有效支持。赛事规定选手须在AI大赛参赛页面注册报名参赛,并前往讯飞大模型定制训练平台进行任务开发。
http://challenge.xfyun.cn/topic/info?type=role-element-extraction
从给定的<客服>与<客户>的群聊对话中, 提取出指定的字段信息.参赛选手需基于讯飞星火大模型V3.5完成任务
https://zindi.africa/competitions/microsoft-learn-location-mention-recognition-challenge
参与者需要构建一个系统,该系统能够准确地从文本中提取和分类地点提及。这可能包括城市、国家、地区或其他地理实体。
https://zindi.africa/competitions/tuning-meta-llms-for-african-language-machine-translation
参与者需要构建或调整一个机器翻译系统,该系统能够将一种非洲语言翻译成另一种非洲语言,或者将非洲语言翻译成更广泛使用的语言(如英语、法语等)
9.多模态大模型
https://iacc.pazhoulab-huangpu.com/contestdetail?id=668de1237ff47da8cc88c0c4&award=1,000,000
为了推动人工智能在数学推理方面的发展,本次多模态数理大模型挑战赛旨在鼓励开发能够直接理解图像输入且具有出色数学推理能力的人工智能模型。通过解决这个初始基准问题,从而促进多模态数理大模型领域的良性竞争与创新,共同推动人工智能模型在数学推理能力上的准确与可靠评估。
https://iacc.pazhoulab-huangpu.com/contestdetail?id=668de7447ff47da8cc88c7cf&award=1,000,000
本次比赛的核心任务是利用提供的预训练大语言模型和视觉编码器,构建并优化多模态大语言模型。为了全面而客观地评估多模态大模型的性能,我们选用高中各学科的选择题进行测试,题目包含语文、数学、物理、化学、生物、政治、历史和地理八个科目,并涵盖示意图、折线图、地图、照片和几何图形等十二种图像类型。在本次比赛中,我们提供双语(中英)语言模型https://huggingface.co/fnlp/moss2-2_5b-chat作为基础语言模型,视觉表示模型采用https://huggingface.co/openai/clip-vit-large-patch14。为保证比赛的公平性,参赛者只能基于提供的预训练模型进行开发,禁止使用其他预训练模型。
https://iacc.pazhoulab-huangpu.com/contestdetail?id=668de7357ff47da8cc88c7b8&award=1,000,000
本次竞赛从真实性、安全性、鲁棒性、公平性、隐私保护五个维度评估多模态大语言模型的可信性,每个维度中包含多个任务进行评估,以充分全面地评估比较不同模型的可信性。为避免各支队伍在算力资源方面的差异带来的影响,本赛题要求使用LLaVA-v1.5-7B[3]的架构设计作为基础。本赛题将基于可信多模态大语言模型评测MultiTrust和相应的可信评测框架MMTrustEval开展测试
https://bohrium.dp.tech/competitions/7227723022?tab=introduce
为了推动学术界和工业界对多模态表格理解任务的研究,我们推出了最新的 TableBench(Multi-modal Table Evaluation Benchmark)评测基准,TableBench 评测基准中的数据是从 arXiv 开源社区中获得的,包含了 5360 张带精细人工标注的表格数据,覆盖了 8 个大类学科和 153 个二级学科类别。此外,TableBench 包含了基础表格分类、行列识别的视觉任务,也包含了高级别 TableQA 的理解类的视觉任务。InternVL 2.0 是由上海人工智能实验室团队研发的一个开源的多模态大型语言模型,旨在缩小开源模型与专有商业模型在多模态理解方面的差距
10.大模型创作
现在大家都关注大模型的逻辑推理能力,以及具体解决商业、工业问题的应用。大模型的艺术创作能力反而关心的人少了。不过还是有相关的比赛。
https://tianchi.aliyun.com/competition/entrance/532210
基于给定测试集的文本创作任务,选手需要在初赛参考训练数据集的基础上补充数据集,任选35b或以下的开源模型进行模型训练,提升模型创作能力,完成800字左右的文本创作任务。
11. 大模型与搜广推
我们都知道,每次CVNLP领域出现点什么热点,国内的一些搜广推从业者都能以最快的速度迁移到搜广推业务中,并且在业务上有效,然后发论文,阿里妈妈是这方面的佼佼者,hhhhhh。
https://tianchi.aliyun.com/competition/entrance/532236
在这个赛道中,参赛者需要解决如何针对长序列做精准的出价决策。由于众多竞争对手的策略不断变化,出价环境异常激烈。传统方法,例如基于强化学习的策略,在面对较长序列决策时,受到误差累积等因素的限制,其性能表现受限。近年来,广义生成模型在决策任务上展现出了较好的应用潜力。
https://aistudio.baidu.com/competition/detail/1188/0/introduction
本次比赛提供了百度真实的广告数据集,包含了海量的用户点击数据和广告特征。希望参赛者使用指定的生成式模型(Unimo-text-large) 或双塔模型(Ernie-3.0-xbase) 底座,采用双塔度量式检索或生成式检索建模广告召回任务,完成相关广告的召回。任务的目标是基于候选广告特征,在给定搜索词下预估最应召回的 K 个广告,评估召回率;选手同时需要考虑算法效果和算法性能,得分标准详见『评估指标』节。
https://aistudio.baidu.com/competition/detail/1190/0/introduction
本赛道任务是广告图片描述生成,期望通过高质量数据和建模优化,提升图片描述的准度和完备性。本次任务提供百度商业真实的广告图片和图片中文描述,数据量级约100万,参赛者自行划分训练集和验证集。每条样本数据包括了三列,采用tab分割,分别为:* 图片id * 图片base64编码 * 图片的文字描述。如下图所示,通常包括了对图片中各个主体(人物的外貌、衣着、表情、物体颜色)、主体之间关系、背景、风格等细粒度描述。
https://www.aicrowd.com/challenges/amazon-kdd-cup-2024-multi-task-online-shopping-challenge-for-llms
这个挑战旨在通过大型语言模型(LLMs)来简化在线购物的复杂过程,并通过多任务学习来提高在线购物的体验。挑战分为五个轨道,分别评估以下购物技能:
- 购物概念理解
- 购物知识推理
- 用户行为对齐
- 多语言能力
- 全方位(Track 5):要求参与者用单一解决方案解决1-4轨道中的所有问题。
12.大模型的agent调度
https://aistudio.baidu.com/competition/detail/1235/0/introduction
本次比赛旨在通过开发基于 LLM Agent 的智能工具调用系统,提升LLM回答复杂问题的能力。参赛者的任务是开发一个基于LLM的Agent,在给定大量工具集合的条件下,智能地编排和调度这些工具,以回答开放域的复杂问题。LLM基座必须使用eb-系列。开发者必须使用ernie基座开发工具召回模块,为给定问题召回最相关的工具集合。工具召回模块可以使用nvidia加速套件进行推理加速。
https://tianchi.aliyun.com/competition/entrance/532193
在本任务中,参赛者需要根据用户Query,从API集合中筛选出合适的API列表,生成正确的api调用逻辑和答案。参赛者可以充分利用给定的数据集,使用大模型设计最优指令以得到最好的生成结果。
https://www.atecup.cn/matchHomeDetails/100001/100002
本赛题需要通过大模型来理解用户Query,并利用外部API的结果与用户进行多轮交互,最终帮助用户完成某个具体的任务。每个API的功能和所需要的参数都预先提供,大模型需要根据当前对话状态,选择合适的API,并提取对应的参数或进行反问。
13.大模型学术性质的比赛
这些比赛并不指向特定业务,主要针对大模型的评测和操作。
13.1 大模型评价
https://www.kaggle.com/competitions/lmsys-chatbot-arena
我们利用了从Chatbot Arena收集的大量数据集,在这个平台上,用户与两个匿名的LLMs聊天并选择他们更喜欢的回答。你在这个竞赛中的任务是预测用户在这些正面对决中会偏好哪个回答
https://www.datafountain.cn/competitions/1032
在文本生成领域,由于信息的多样性、主观性,以及评价标准的复杂性,传统自动化评估方法效果较差,灵活性不足,而人工评价方式效率低下,成本高昂,难以满足当前大规模的评判需求。因此,如何运用自动化、智能化的手段,实现对文本内容的高效评判,成为了业界亟待解决的问题。在此背景下,本赛题以“基于大模型的文本内容智能评判”作为主题,旨在借助大模型强大的语义理解能力和泛化能力,应对不同领域和场景的评判需求,同时精准对齐人类专家的评判标准,进一步提升评判的准确性和可靠性。
13.2 大模型与prompt
https://www.kaggle.com/competitions/llm-prompt-recovery
自然语言处理(NLP)的工作流程越来越多地涉及到文本的重写,但关于如何有效地给大型语言模型(LLMs)提供提示(prompting),我们还有很多需要学习的地方。这个机器学习竞赛旨在以一种新颖的方式深入挖掘这个问题。比赛目标是:这个竞赛的目标是恢复用于转换给定文本的LLM提示(prompt)。
13.3 大模型知识编辑
https://tianchi.aliyun.com/competition/entrance/532182
知识编辑的目标是通过修改大模型中的特定知识以缓解知识谬误问题。知识编辑通常包含三个基本的设定:知识新增、知识修改和知识删除。知识新增旨在让大模型习得新知识。知识修改旨在改变已存储在大模型内部的知识。知识删除旨在让大模型遗忘已习得的知识。
https://www.datafountain.cn/competitions/1031
本赛题旨在解决大型语言模型在面对非结构化知识时的更新和编辑问题。本赛题任务要求参赛者开发有效的非结构化知识编辑方法,从非结构化数据中提取并编辑知识,以实现模型内部知识的快速更新。同时,编辑方法需确保不影响模型的整体性能和稳定性,能处理复杂多样的用户需求。比赛数据包括多样的非结构化文本,评测标准综合考虑词级别和语义相似度及子问题回答的正确性,以衡量模型的编辑效果。
https://llmunlearningsemeval2025.github.io/
这个挑战的目的是推动“反学习”算法的发展,这些算法能够有效地从 LLMs 中移除训练数据,同时保持模型性能的稳定性。
13.4 大模型融合
https://llm-merging.github.io/
探索合并和重用现有模型以形成新模型的方法,无需额外训练。
其他
https://helsinki-nlp.github.io/shroom/
邀请参与者在一个多语言环境中检测指令调整的大型语言模型(LLM)输出中的幻觉部分。
https://sites.google.com/view/numeval/numeval
专注于数值理解任务,旨在评估模型对包含数值信息的文本的理解和推理能力。
https://www.aicrowd.com/challenges/meta-comprehensive-rag-benchmark-kdd-cup-2024
一个基于检索的问答系统:1以问题Q作为输入,并输出答案A;2这个答案是由大型语言模型(LLMs)根据从外部来源检索到的信息,或者直接从模型内部化的知识生成的;3答案应该提供有用的信息来回答这个问题,不添加任何幻觉或有害内容,如亵渎。这个挑战旨在通过三个不同的任务来改进基于检索的问答(QA)系统。挑战任务概览:
- 基于网络的检索摘要:参与者每个问题接收5个网页,可能包含相关信息。目标是衡量系统识别并将这些信息压缩成准确答案的能力。
- 知识图谱和网络增强:这个任务引入了模拟API来访问底层模拟知识图谱(KGs),这些结构化数据可能与问题相关。参与者使用模拟API,输入从问题中派生的参数,检索答案制定的相关数据。评估侧重于系统查询结构化数据的能力,并将来自不同来源的信息整合成全面的答案。
- 端到端RAG:第三个任务通过为每个问题提供50个网页和模拟API访问权限增加了复杂性,遇到相关信息和噪音。它评估系统从更大的数据集中选择最重要数据的技能,反映了现实世界信息检索和整合的挑战。
https://sites.google.com/view/wsdm24-docqa
对话式问答旨在根据对话中识别的用户意图生成正确且有意义的答案,在现代搜索引擎中发挥着至关重要的作用和对话系统。然而,这仍然具有挑战性,特别是对于当前或趋势主题,因为在语言模型的训练阶段无法获得及时的知识。尽管提供多个相关文档作为上下文信息似乎可行,但该模型仍然面临着被大量输入淹没或误导的风险。基于来自小红书的真实文本数据,WSDM Cup 20241提出了“对话式多文档QA”的挑战,以鼓励对问题的进一步探索。
14.趣味大模型比赛
这类大模型比赛可能并没有明确的业务意义,主要就是通过常规任务对大模型能力进行评测。
https://www.kaggle.com/competitions/llm-20-questions
"20个问题"是一个古老的推理游戏,你尝试在二十个问题或更少的问题中猜出一个秘密单词,只使用是非问题。玩家通过从一般到具体的提问来缩小问题范围,希望在最少的问题中猜出单词。每个团队将由一个猜测者LLM组成,负责提问和猜测,以及一个回答者LLM,负责用"是"或"否"回答。通过策略性提问和回答,目标是让猜测者尽可能少的轮次内正确识别出秘密单词。
#读博对心理有持续负面影响?
读博确实影响心理健康!
大家好!我是奶茶。
众所周知,读博,是一件压力山大的活动。
《Nature》有一项调查统计显示:39%以上的博士有抑郁或焦虑的症状,是正常人群的6倍以上。
这摆出了一个残酷的事实:读博期间患上精神类疾病的概率灰常高!。

最近,奶茶发现一篇来自哥德堡大学等机构的论文,终于为这一话题提供了科学依据,证实了:读博确实影响心理健康!
论文题目:《The Impact of PhD Studies on Mental Health—A Longitudinal Population Study》
论文链接:https://swopec.hhs.se/lunewp/abs/lunewp2024_005.htm?cnotallow=6a5e306c6ab030e5ec651fc6a91fd1c5
研究团队调取和分析了瑞典全部博士生精神科药物处方的管理记录,得出了几个阶段:
博士生领取精神类药物的占比要高于其他持有高学历的人群;
从读博开始,博士生使用精神类药物的情况显著增加。
整个读博过程,使用精神类药物的比例一直上升,与博士学习前相比,博生第五年的用药量增加了40%。
瑟瑟发抖啊!接下来和奶茶一起来看下这样的阔怕的数据是怎么统计出来的~
研究团队在论文的开头阐述了研究这一问题的缘由——最近公开的数据显示,博士生自我报告的心理健康问题异常严重!
在针对博士生的16项调查评估中,有24%的博士生表现出抑郁症状,17%的博士生表现出焦虑症状。
在某些特定地区、特定专业这一数据甚至更为严重!
在美国八所顶尖经济学院中,513名博士生中有25%患有中度至重度抑郁或焦虑;在欧洲14所顶尖经济学院中,556名博士生中有35%表现出相同的症状。与其他教育水平的人群(如拥有学士学位者)相比,博士生的心理健康问题发病率明显更高!
读经济学的压力这么大吗!有没有小伙伴现身一下说法捏~
实验
研究团队认为通过统计、分析博士生就读期间就诊记录,可以深入了解他们的心理健康状况。
因此,研究团队收集了2006年至2017年间在瑞典入学的所有博士生,排除了无法进行时间长度的实验分析的未在瑞典接受大学教育的博士生,以及因其他愿意导致记录不完整的样例,最后符合实验样本要求的共计20,085名博士生。

读博期间使用个体心理健康护理的数据
研究者们在图1展示了统计获得的描述性证据-博士生在开始博士学习前、后几年内获取精神病药物的比例,这份数据与同期未就读博的普通低学历人群(学士以下)和高学历人群(学士、硕士)的对照组进行了比较。

随着时间的推移,所有组别中精神病药物的使用都有所增加。
研究者提出,这个时间内增加部分是可能是由于年龄正相关的心理健康护理需求的正常增加以及瑞典在此期间精神病药物处方普遍上升的影响。
在开始博士学习之前,博士生使用精神病药物的情况与其他非博士高学历个体相似,且远低于普通人群。
然而!当他们正式开始博士学习后,使用精神病药物的比例相对于其他组逐渐增加增加!在博士项目进行五年后,博士生使用精神病药物的比例接近于普通人群,并远远高于其他非博士高学历个体。
读博期间使用处方精神病药物的数据
为了排除其他因素的影响,通过处方药来进一步精确的确定读博对心理健康的影响。研究者们设定一个模型来更精确地识别博士研究对个体的影响:

其中,是一个二进制变量,用于表示个体i在日历年s和事件时间t是否使用了处方精神病药物。变量是事件时间的虚拟变量,当日历年与博士开始年份的时间差为j年时,该变量取值为1(对于未经治疗的对照组,此变量始终为0)。变量代表博士研究开始的年份。变量用于捕捉博士研究开始后至少八年的所有时期,而I(t=-8)则用于捕捉博士研究开始前至少八年的所有时期。此外,系数估计了与博士研究开始前一年相比在第j年使用精神病药物的个体比例的相对变化.
图2展示了处方精神病药物的结果,以相对变化的形式呈现了读博队个体精神健康影响的直观视图。

博士生在入学的前几年内,使用精神病药物的比例与拥有相应硕士学位的对照组相似,低于普通人群的对照组。
然而!一旦开始博士学习,博士生使用精神病药物的情况相较于对照组有所上升。在博士学习开始后的五年内,博士生使用药物的比例大幅超过了受过非博士高等教育的个体,并在整个博士项目期间持续上升。
在博士就读五年以上后,使用精神病药物的倾向比博士开始前一年增加了39.5%,即增加了2.5个百分点。

除了时间维度,一些其他角度的分析也很有意思!
- 各个学科领域中使用精神病药物的情况均有所上升,除医学和健康科学领域外。
- 男性和女性的药物处方率增长相似,但由于男性的基线患病率较低,这种增长在男性中的相对影响更为显著。
- 年轻学生(28岁以下)以及国外出生的学生在使用精神病药物上的相对增长更为突出。
- 婚姻状况和是否有子女对于心理健康的影响较小。

结语
研究团队在报告的结尾部分指出,尽管这项研究是在瑞典进行的,但其结果与其他地区,如美国最近发布的调查数据高度一致!
虽然给大家分享这篇文章,但是奶茶同样与作者一样没有具体的建议和解决方案,但奶茶希望大家意识到,这些心理压力并非孤立现象,不是我们自己的问题,而是许多博士生共同面临的挑战~
读博期间的压力是具体而微的,担心论文被拒稿,担心毕业论文盲审,担心求职,担心非升即走。学术之路充满了挑战和不确定性,似乎焦虑常伴求学的时光。但是!焦虑与否并不会改变那些我们无法控制的结果,而我们能否在一定限度上让自己快乐的度过今日是我们可以做到的!
那么,大家有什么好方法应对这些压力的呢?欢迎在评论区分享你的经验和见解,让我们一起探讨和支持彼此!
#OpenAI CTO Mira Murati离职
一波接着一波,OpenAI 到底怎么了?
OpenAI 又迎来「地震级」高层人员变动。
就在几个小时前,OpenAI CTO Mira Murati 在 X 上发帖表示,在 OpenAI 工作了六年多后,她将离开公司进行自己的探索。
以下是 Mira Murati 的离职公开信全文(第一人称):
「我有件事想和大家分享。经过深思熟虑,我做出了离开 OpenAl 的艰难决定。
我已经在 OpenAl 团队工作了六年半,这是我的荣幸。在接下来的几天里,我会向很多人表示感谢,但首先我想感谢 CEO Sam Altman 和总裁 Greg Brockman 对我领导技术组织的信任以及他们多年来的支持。
离开自己珍视的地方永远没有理想的时机,但此时我感觉很合适。我们最近发布的语音到语音转换和 o1 模型标志着交互和智能新时代的开始。这些成就是由你们的聪明才智和技术实现的。我们不仅构建了更智能的模型,还从根本上改变了人工智能系统学习和推理复杂问题的方式。我们将安全研究从理论领域带入实际应用,创建了比以往任何时候都更稳健、更一致、更可控的模型。
我们的工作使前沿人工智能研究变得直观易用,开发出能了够根据每个人的输入进行调整和发展的技术。这一成功证明了我们出色的团队合作,正是由于你们的才华、奉献和承诺,OpenAI 才站在了人工智能创新的顶峰。
我之所以要离开是因为想创造时间和空间来进行自己的探索。目前,我关注的重点是尽己所能确保平稳过渡,保持我们已经建立的势头。
我将永远感激有机会与这个伟大的团队一起建设和工作。我们一起在改善人类福祉的探索中突破了科学理解的界限。虽然我可能不再与你们并肩作战,但我仍然会支持你们所有人。我深深感谢与你们建立的友谊、取得的成功以及共同克服的挑战。」
OpenAI CEO Altman 第一时间回复表示,「Mira,谢谢你所做的一切。很难用言语来形容你对 OpenAI、我们的使命以及我们所有人的意义。我非常感谢你帮助我们建立和实现的一切,但我最感激的是你在所有困难时期给予我的支持和厚爱。我很期待你接下来会做什么。我们很快就会谈论更多关于过渡计划的事情,但现在,我想花点时间表达我的谢意。」
OpenAI的员工也纷纷表达了对Mira Murati的不舍与祝福。
那张经典的四人合照图又被人拿出来调侃,如今只剩 Altman 自己了(注:Ilya、Mira 离职,Greg Brockman 休长假)。
图源:https://x.com/Yuchenj_UW/status/1839030011376054454
还有人找出了当初 Altman 「被离职」期间 Mira 说过的一句话,「OpenAI is nothing without its people」。
当然,各种猜测也纷至沓来,有网友发出 Ilya 式灵魂一问:Mira 看到了什么?
此外也有趁机招揽 Mira 的,比如前段时间爆火的 SD 作者成立的 AI 初创公司「黑森林实验室」。
谷歌首席科学家 Jeff Dean 也祝福 Mira 未来一切顺利,这引发了一些人的好奇:难道谷歌要聘用她吗?
Mira 是近几个月来离开 OpenAI 的最新一位高管。
此前,最被大家关注的是作为 OpenAI 联合创始人、首席科学家 Ilya Sutskever 的离职。当时 Sutskever 表示:在 OpenAI 工作近 10 年后,他做出了离开的决定。OpenAI 的发展轨迹可以称得上是奇迹,他相信 OpenAI 会在 Sam Altman、Greg Brockman 和 Mira Murati 的领导下,以及 Jakub Pachocki 的出色研究领导下构建安全有益的 AGI。
没想到,短短几个月的时间,Sutskever 在离职信中提及的四个人中, Greg Brockman 选择长期休假,Mira Murati 宣布离职。
除了这几位,当时与 Ilya 同步宣布离开的,还有超级对齐团队的共同领导者 Jan Leike。Ilya 与 Jan 是 OpenAI 超级对齐团队的领导者,该团队的任务是确保人工智能与其制造者的目标保持一致,而不是做出不可预测的行为并伤害人类。
另一位联合创始人 John Schulman 上个月离职转投竞争对手 Anthropic。在 OpenAI 期间,Schulman 领导了被称为「后训练」(post-training)的过程,即完善 ChatGPT 和其他产品背后的大型语言模型。
此外,知情人士透漏,去年加入公司的产品负责人 Peter Deng 也已经离职,此前他曾在 Meta Platforms、Uber 和 Airtable 担任产品负责人。
我们所熟知的还有另一名 OpenAI 联合创始人 Andrej Karpathy,他在今年 2 月离职,并成立了一家教育初创公司。
这些突然被爆出的离职消息不一定具备相关性,但至少说明一点:自从去年 11 月的「宫斗闹剧」发生以来,尽管山姆・奥特曼已经重新回到 OpenAI 并掌权,但这家公司的领导层仍未稳定下来。
Mira Murati 介绍
Mira 于 1988 年出生于阿尔巴尼亚,在 2022 年担任 OpenAI 的首席技术官。
在学生时代,Mira 就参加过许多奥林匹克竞赛和数学竞赛。她本科毕业于达特茅斯学院机械工程系,曾在高盛和法国航空航天集团 Zodiac Aerospace 实习。她还在特斯拉工作了三年,担任特斯拉跨界 SUV Model X 的高级产品经理,在此期间,特斯拉发布了 Autopilot 的早期版本。
2016 年,Mira 加入 Leap Motion,一家为 PC 制造手部和手指追踪运动传感器的初创公司,担任产品和工程副总裁。Mira 在接受 外媒 Fast Company 采访时表示,她希望人类与计算机的交互体验「像玩球一样直观」。
加入 OpenAI 后,Mira 在 ChatGPT、DALL-E、Codex 等的开发中发挥了重要作用。除此以外,今年 5 月份发布的 GPT-4o 以及本月发布的 OpenAI o1,都是在 Mira 的领导下完成的。
而随着 Mira 的最新离职,外媒报道称,随着 OpenAI 逐渐脱离其长期以来的非营利性结构,Altman 将首次获得 OpenAI 的股权。
据称 OpenAI 正在寻求一轮融资,该轮融资将使该公司估值超过 1500 亿美元。据报道,微软、英伟达、苹果和 Thrive Capital 正在洽谈投资事宜,本轮融资最终金额可能高达 65 亿美元。
OpenAI 迫切需要钱。据 The Information 报道,该公司在模型训练上花费了约 70 亿美元,在人员配备上花费了 15 亿美元。据说,仅 ChatGPT 一项,OpenAI 每天的运行成本就高达 70 万美元左右。Altman 曾表示,训练 GPT-4 模型花费了超过 1 亿美元。
CTO前脚刚走,OpenAI后训练负责人、首席研究官也走了,网传公司要给奥特曼7%股权
新领导团队浮出水面,公司性质也要变?
刚刚,就在 OpenAI CTO Mira Murati 官宣辞职后不久,CEO Sam Altman 又投下一枚重磅消息 —— 以另一篇公开信的方式。
奥特曼首先写道,「过去六年半,Mira 对 OpenAI 的进步和成长起到了至关重要的作用;她是我们从一个不为人知的研究实验室发展成为一个重要公司的巨大推动力。今天早上,Mira 告诉我她要离开时,我感到非常难过,但我支持她的决定。在过去的一年里,她一直在培养一支强大的领导团队,他们将继续推动我们的进步。」
接着,他进一步透露更多高层的离职消息。
「我还想告诉大家,Bob( Bob McGrew)和 Barret (Barret Zoph)也决定离开 OpenAI,三人是独立且友好地做出这些决定的,但由于 Mira 的决定时机恰好,我们决定一次性完成所有这些变动,以便我们能够共同努力,顺利地将领导权交给下一代。」
OpenAI 后训练研究副总裁 Barret Zoph 官宣离职。在加入 OpenAI 之前,他曾在谷歌担任研究科学家。2022 年,在 ChatGPT 问世之前,他加入了 OpenAI,和 John Schulman 等人一起从零开始建立了 OpenAI 的后训练团队。
OpenAI 首席研究官 Bob McGrew 官宣离职。此前,他已经在 OpenAI 工作了接近 8 年。
奥特曼的应变速度还是很快的。
他宣布,马克(Mark Chen)将成为新的研究高级副总裁,将与首席科学家雅库布(Jakub Pachocki)合作领导研究组织。
奥特曼显然是有备而来,他表示,「这一直是我们为 Bob 某天离开而做的规划;虽然这比我们预期的要早,但我对马克担任这一角色感到非常兴奋。
马克拥有深厚的技术专长,而且在过去几年里,他以令人印象深刻的方式学会了如何成为一名领导者和管理者。」
Mark Chen 将成为新的研究高级副总裁,他已在 OpenAI 工作五年多,此前曾在微软、Trading 实习,在哈佛做访问学者,担任过 Quantitative Research 合伙人。
Josh Achiam 将担任新的使命对齐负责人,在整个公司范围内工作,确保 OpenAI 所有的部分(包括文化)都正确,以便成功完成使命。
首席产品官 Kevin Weil 和 工程副总裁 Srinivas Narayanan 将继续领导应用团队。
Kevin Weil 是今年 6 月才加入 OpenAI ,曾任 Instagram 产品副总裁和 Twitter 产品高级副总裁。他的加入正值 OpenAI 加快商业化布局,Kevin Weil 主要职责是专注于将 OpenAI 研究应用到有利于消费者、开发者和企业的产品和服务中。
而前安全主管 Matt Knight 将成为 OpenAI 的首席信息安全官(Chief Information Security Officer),他已经在这个职位上服务了很长时间。
入职 OpenAI 之前,工程副总裁 Srinivas Narayanan 曾担任 Meta 应用研究负责人。
Mark、Jakub、Kevin、Srinivas、Matt 和 Josh 都将向奥特曼汇报。
「在过去的一年左右,我大部分时间都花在了我们组织的非技术部分;我现在期待着将大部分时间花在公司的技术和产品部分。」
最后,他写道:
「领导层的变动是公司自然发展的一部分,尤其是对于增长如此迅速且要求如此高公司来说更是如此。我当然不会假装这次变动如此突然是自然的,但我们不是一个普通的公司,我认为,Mira 向我解释的原因(从来没有一个合适的时机,任何不突然的事情都会泄露,她希望在 OpenAI 处于上升期时这样做)是有道理的。我们明天可以在全体员工大会上进一步讨论这个问题。」
对于离职,Bob McGrew 很快在 X 上做出回应。
「现在是我该休息一下的时候了。为我在这里的工作画上句号,再没有比向世界发布 o1 更好的收官之作了。
展望未来,Mark Chen 将作为高级副总裁领导研究团队,Jakub 将担任首席科学家。在接下来的两个月过渡期内,我会继续支持 Mark、Jakub 和团队。我对他们的领导能力充满信心,相信他们能够将 OpenAI 的研究推向 AGI(通用人工智能)及更远的未来。我迫不及待地想看到这个团队接下来会有什么样的成就。」
Barret Zoph 也在 X 上回应了离职,并表示相信后训练团队有许多有才能的领导者,团队处于良好状态。Barret 对 OpenAI 的未来保持乐观,并会继续支持公司。
以下是公开信全文。
看到如此激烈的人事变更,所有人都想问,他们到底看到了什么?
其实,在人事动荡之余,外媒还传出了新消息:OpenAI 正在讨论给予首席执行官 Sam Altman 7% 的公司股权,并重组成为盈利性企业。知情人士透露,这将是 Altman 首次获得这家人工智能初创公司的所有权,标志着重大转变。
消息人士称,该公司正在考虑成为一家公益公司,既要盈利又要帮助社会。由于信息保密,这些消息人士要求匿名。其中一人表示,这一转变仍在讨论中,尚未确定时间表。在一份声明中,一位发言人表示,OpenAI 仍然「专注于构建造福每个人的人工智能」,并补充说,「非营利组织是我们使命的核心,将继续存在。」
OpenAI 成立于 2015 年,当时是一个非营利研究组织,目标是构建对人类安全有益的人工智能。该公司在 2019 年创建了一个盈利性子公司,以帮助获得 AI 模型开发的高成本,并从此吸引了微软公司等数十亿美元的外部投资。本月,彭博社报道称,OpenAI 目前正在努力以 1500 亿美元的估值筹集 65 亿美元,使其成为世界上市值最高的初创公司之一。
众所周知,为了保持公司的非营利初衷,Altman 之前没有接受股权,强调公司旨在广泛惠及社会,并且他有足够的钱。但他也偶尔在采访中表示,他希望自己当时接受了股权,这样人们就不会再问他这个问题。
参考链接
https://www.reuters.com/technology/artificial-intelligence/openai-remove-non-profit-control-give-sam-altman-equity-sources-say-2024-09-25/
https://www.bloomberg.com/news/articles/2024-09-25/openai-cto-mira-murati-says-she-will-leave-the-company?srnd=phx-technology&embedded-checkout=true
#可以实现零代码开发的OPPO智能体平台,到底强在哪?
11 月 16 日,由 OPPO 与浙江大学联合承办的第三届(2024 年)中国高校计算机大赛 —— 智能交互创新赛在浙江省杭州市举行了全国总决赛及颁奖典礼。本届竞赛以 “交互无界,创意无限” 为主题,聚焦人机交互技术,深度挖掘 AI 智能体的应用潜力,推动智能产业的升级和发展。
▲智能交互创新赛全国总决赛颁奖典礼
OPPO 智能体平台强劲助力
挖掘智能交互方案创新动能
作为赛事承办方之一,OPPO 深度参与竞赛。竞赛期间,为了让参赛团队更好地完善参赛作品,提升作品的智能交互创新能力和技术水平,OPPO 携手竞赛组委会在参赛期间,邀请多位业内专家通过主题赛事宣讲会和集训营等形式,围绕智能体的前沿发展、创新应用及实践案例展开分享,帮助参赛团队深入了解智能交互领域的最新趋势,掌握关键核心技术和应用能力,提升竞赛水平,激发潜力,释放创新力,最终使优秀的智能交互作品呈现在大众眼前。

▲智能交互创新赛全国总决赛颁奖典礼
值得一提的是,OPPO 还为赛事提供了强大的技术平台支持。参赛团队可利用 OPPO 智能体平台提供的大语言模型、图像及语音类模型等能力进行创意开发。例如,哈尔滨工业大学带来的参赛作品《雅韵智诵 ——AI 智能背诵助手》荣获竞赛特等奖,其作品针对学生在背诵和理解古诗文时背诵效率低、失分率较高、缺乏科学方法指导和有效检查等问题,基于 OPPO 智能体平台,开发了一款古诗文辅助背诵助手 APP,可提供多模态科学记忆方法辅助背诵、多层面背诵效果检查、个性化复习计划等功能,有效提升了学生的古诗文背诵效率,助力传统文化传承发展。

▲哈尔滨工业大学团队参赛作品《雅韵智诵 ——AI 智能背诵助手》
四川大学带来的《走心》项目,则针对心理健康问题年轻化、普遍化的现状,以及现有心理疾病检测低普及率、主观性强、形式单一、大众不愿意线下就诊等问题,开发了一种创新的心理测评系统,利用 OPPO 智能体平台提供的大语言模型能力,结合注意力检测等辅助心理分析手段,将大语言模型代理集成到互动小说游戏中,实现对心理健康问题的初步筛查。这种做法不仅提高了心理问题初筛的普及性和准确度,同时也为心理问题提供了更具吸引力和个性化的评估工具。

▲四川大学团队参赛作品《走心》
OPPO 超前布局智能体领域
开创智能交互技术新纪元
智能交互技术的快速发展,为各行各业带来了革命性的变化。为推动 AI 生态的创新与开放,在 2024 OPPO 开发者大会上,OPPO 发布了智能体开发平台,标志着智能手机行业发展的一项重要突破,也显示了 OPPO 在智能体领域的超前布局。
OPPO 智能体平台,是基于最新的人工智能技术所构建,这些技术包括自然语言处理、机器学习和多模态 AI 等。平台通过提供大模型应用开发能力以及丰富的工具库、插件库以及私域数据接入等功能,为开发者适配多种业务场景,并采用可视化界面拖拽开发,开发者只需通过自然语言定义、插件点选和工具集成,即可轻松完成智能体的开发、调优和分发。

▲OPPO 智能体平台全景
OPPO 智能体平台具有独特优势,可以全面赋能开发者。首先,该平台为开发者提供了一种全新的零代码开发范式,让智能体的构建变得更加简单快捷。对于有进一步的分发和集成开发需求的开发者团队,平台也支持针对不同的入口需要设计多端卡片,或者设计独立的智能体交互页。其次,该平台在智能体编排开发过程中,支持开发者共建插件工具,有不同的插件能力可供调用,允许开发者 DIY 插件,也可以代入自有业务,同时 OPPO 也提供了一部分原生插件,以及合作伙伴带来的插件供开发者调用。此外,平台还融合 RAG 作为对大模型因训练数据时效性限制的补充增强,让智能体在实际应用中面对 “上下文限制”“多跳推理能力” 等挑战时,具有更靠谱的知识检索能力。最后,该平台提供了多种 API 接口和 SDK,便于开发者根据自身需求进行灵活开发。
目前,OPPO 智能体平台已完成整体建设,涵盖生活、娱乐、医疗、健康以及生产制造等多个领域,通过开放接口与各领域业务实现了深度融合,也与百度云、火山引擎、支付宝、网易有道、58 同城、知乎等国内知名企业建立了战略性智能体生态合作,进一步提升了平台的适用性和影响力。
OPPO 智能体平台的上线,不仅为更多智能领域的科研竞赛提供技术和平台支持,培养更多具有创新思维,引领未来的技术人才,也为开发者、产业界提供了全新的工具和资源,推动智能体技术在日常生活中的广泛应用,进一步丰富了人工智能生态,为用户带来更智能服务的同时,推动整个行业的智能化进程。
#继良品率低后,英伟达Blackwell又出过热问题,说好的明年初发货呢?
发言人将「工程迭代」称为「正常且在意料之中」。
今年的的 GTC 大会,英伟达将 AI 芯片的标杆推向了难以想象的高度。
为了帮助世界构建更大、更智能的 AI,英伟达首先拿出了世界上最先进的 GPU—— Blackwell 系列。
Blackwell 拥有 2080 亿个晶体管,在同一颗芯片上集成了两个 GPU。其两块小芯片之间的互联速度高达 10TBps,彻底解决了内存瓶颈和缓存问题。
与前代产品 H100 相比,Blackwell 的性能提升同样令人瞩目,达到了 Hopper 的 30 倍。

以训练一个 1.8 万亿参数的 GPT 模型为例,如果使用 Hopper,需要 8000 个 GPU,消耗 15 兆瓦电力,训练 3 个月;而换成 Blackwell,仅需 2000 个 GPU,就能在同样的时间内完成,能耗只需 4 兆瓦,实现了性能和效率的双重突破。
Blackwell 的量产问世,无疑将为 AI 模型训练和人形机器人的发展注入强劲动力,对整个 AI 应用生态也将产生深远影响。

自 3 月份发布,6 月份宣布投产以来,Blackwell 最初定于 2024 年第二季度发货,全球科技公司都在疯狂求购。
但在原定的发货时间,传出了 Blackwell 因为良品率低,将推迟发货的消息。
当时,黄仁勋在 2025 财年第二季度财报电话会议上表示,设计上的问题都已修复,有望在第四季度实现量产。
现在,英伟达的客户又在担心一个新问题,当芯片连接到 Nvidia 自己的服务器机架时,会过热。

据 The Information 报道,英伟达 Blackwell GPU 在 72 核的服务器上暴露了过热隐患。这些服务器每个机架的功耗预计高达 120 千瓦,过热问题不仅限制了 GPU 的性能,还可能损坏组件。为此,英伟达不得不多次重新评估服务器机架的设计方案。

这引发了谷歌、Meta 和微软等大客户对能否按时在其数据中心部署 Blackwell 的担忧。
为此,英伟达已要求供应商对机架进行多项设计变更,进一步推迟了预期发货日期。该公司发言人将「工程迭代」描述为「正常且在意料之中」。

此前,由于 GPU 良率不高的问题,Blackwell 的量产计划就推迟了一次。
今年 8 月,有媒体称 Blackwell 存在设计缺陷。由于 Blackwell 是英伟达首个采用 MCM(多芯片封装)设计的 GPU,在同一个芯片上集成了两个 GPU。
这种「二合一」的创新,显然不能再通过传统方式来打造。Blackwell 的 B100 和 B200 GPU 两个型号使用台积电的 CoWoS-L 封装技术连接两个芯片,该技术依赖于配备局部硅互连(LSI)桥接器的 RDL 中介层,以实现约 10 TB/s 的数据传输速。
然而,由于 GPU 芯片、LSI 桥、RDL 中介层和主板基板之间的热膨胀特性不匹配,导致封装结构出现弯曲,从而引发系统故障。

对此,黄仁勋表示:「我们的 Blackwell 芯片存在设计缺陷,虽然可以正常使用,但该设计缺陷导致良率低下」。
更多详情可参见:《100% 英伟达的错:黄仁勋确认 Blackwell 缺陷修复,明年初出货》
最终修订版的 Blackwell GPU 直至 10 月底才开始量产,这意味着英伟达最快也要等到明年 1 月底才能向客户交付这些处理器。
而 Blackwell 正在面临前所未有的需求。近期,黄仁勋在摩根士丹利举办的投资者会议上透露,Blackwell 已经全部售罄。摩根士丹利分析师 Joe Moore 指出,英伟达高管称,Blackwell GPU 产品的订单积压已达 12 个月。
AWS、CoreWeave、谷歌、Meta、微软和甲骨文等科技巨头,已经采购了英伟达及其制造合作伙伴台积电在未来四个季度内能生产的所有 Blackwell GPU。
这种旺盛的需求表明,尽管 AMD、英特尔以及各大云服务商正努力分得一杯羹,英伟达在 AI GPU 的领导地位还将进一步巩固并扩大。
作为人类历史上估值最高的股票,英伟达将于本周三公布收益。与 8 月份的情况相似,在类似的时间节点,又传出了有关下一代 Blackwell 芯片出问题的消息。

在英伟达承认 Blackwell 存在设计缺陷导致良品率低后,当时刚创下历史新高的英伟达股票收跌 2.81 %,又回落到了 140 美元以下。

这一次,英伟达的股价又会发生怎样的变化呢?
参考链接:
https://www.theinformation.com/articles/nvidia-customers-worry-about-snag-with-new-ai-chip-servers
https://www.tomshardware.com/pc-components/gpus/nvidias-data-center-blackwell-gpus-reportedly-overheat-require-rack-redesigns-and-cause-delays-for-customers
#A Theoretical Understanding of Self-Correction through In-context Alignment
自我纠错如何使OpenAI o1推理能力大大加强?北大、MIT团队给出理论解释
自我纠错(Self Correction)能力,传统上被视为人类特有的特征,正越来越多地在人工智能领域,尤其是大型语言模型(LLMs)中得到广泛应用,最近爆火的OpenAI o1模型[1]和Reflection 70B模型[2]都采取了自我纠正的方法。
传统的大语言模型,因为在输出答案的时候是逐个Token输出,当输出长度较长时,中间某些Token出错是必然发生。但即使LLM后来知道前面输出的Token错了,它也得用更多错误来“圆谎”,因为没有机制让它去修正前面的错误。
而OpenAI o1在“慢思考”也就是生成Hidden COT的过程中,通过分析OpenAI官网给出的Hidden COT例子可以发现,在解决字谜问题的思考过程中,o1首先发现了每两个连续的明文字母会映射到一个秘文字母,于是便尝试使用奇数字母来构建明文,但是经过验证发现并不合理(Not directly);接着又重新修正答案最终成功解出字谜。

图1 OpenAI o1 官网示例(部分Hidden CoT)
Reflection 70B的关键技术也包括错误识别和错误纠正。他们用到了一种名为 Reflection-Tuning(反思微调) 的技术,使得模型能够在最终确定回复之前,先检测自身推理的错误并纠正。在实际的执行过程中,这会用到一种名为思考标签(thinking tag)的机制。模型会在这个标签内部进行反思,直到它得到正确答案或认为自己得到了正确答案。
频频应用于大语言模型的自我纠错技术为何有效?为什么纠错过程可以让模型把原本答错的问题重新答对?
为了探究这一问题,北大王奕森团队与MIT合作,从理论上分析了大语言模型自我纠错能力背后的工作机理。
- 论文题目:A Theoretical Understanding of Self-Correction through In-context Alignment
- 论文地址:https://openreview.net/pdf?id=OtvNLTWYww
- 代码地址:https://github.com/yifeiwang77/Self-Correction
作者团队将自我纠错的过程抽象为对齐任务,从上下文学习(In-context learning)的角度对自我纠错进行了理论分析。值得一提的是,他们并没有使用线性注意力机制下的线性回归任务进行理论分析,而是使用真实世界LLM在用的softmax多头注意力机制的transformer结构,并利用Bradley-Terry 模型和 Plackett-Luce 模型(LLM对齐的实际选择,用于RLHF和DPO)设计对齐任务进行研究。受理论启发,他们提出了一种简单的自我纠错策略--上下文检查(Check as Context),并通过实验,在消除大语言模型中存在的潜在偏见以及防御越狱攻击中效果显著。
理论分析:自我纠错实际上是一种上下文对齐?
不同于类似监督学习的标准上下文示例(请求,回答),自我纠错示例可以形成一个三元组形式(请求,回答,奖励),这类似于通过奖励指示好坏样本的 LLM 对齐。因此,作者团队提出将自我纠错形式化为一种“上下文对齐”(In-context Alignment),即通过提供一系列自我纠错步骤的上下文,优化LLM的最终输出,以获得更高的奖励。
对齐的过程通常包括:对于问题,收集个不同的模型回答,然后由人类或评估模型(在本文中,评估模型即该 LLM 本身)对这 个回答给出排序偏好。接着,使用一般的对齐模型(如Bradley-Terry (BT,n=2) or Plackett-Luce (PL loss, general n))进行建模:
其中为奖励模型。
针对transformer模型,作者采用了带有softmax多头注意力机制的transformer结构,其前向传播更新可以分为两部分
- 多头注意力(MHSA)层:
- FFN层:
奖励函数 被设置为负均方误差(MSE)损失,即:
在该设置下,参数的梯度下降可等价于对数据的更新:

作者证明了多层transformer(包含3-head softmax attention和relu激活函数的FFN)可以利用自我纠错样本生成更优奖励的回答。具体而言,作者证明了存在模型权重,使得transformer可以通过在前向传播的过程中执行对其内部奖励模型参数的梯度下降,来生成更符合对齐目标的更优回答。

这是首次在理论上表明 LLM 可以在上下文中实现对齐的分析。该理论适用于多种自我纠错方法,因为评估可以来自人类、外部验证者或 LLM 本身。

图2 关于上下文对齐的验证实验,分别涉及TF和GD的比较(a)、不同奖励噪声p的影响(b)、模型深度的影响(c)、以及不同注意力机制的效果(d)、(e)、(f)。
作者也通过设置验证实验来检验其理论导出的种种结论,以及各个 transformer 结构模块对 LLM 执行上下文对齐能力的影响,作者发现了很多有趣的结论:
- 通过观察比较LLM在执行上下文对齐时前向传播的损失与梯度下降的损失曲线,LLM执行上下文对齐时的前传行为与梯度下降损失曲线几乎相同。(图2(a))
- 评价的质量直接影响自我纠错的质量(图2(b))。
- 对多样本的排序需要更深的模型层数,在达到一定深度后(15层),增加更多的层数并不能带来更高的收益。(图2(c))
- Softmax注意力机制对从评价中分析回答优劣排序至关重要,而linear注意力则做不到这一点。具体来说,softmax 注意力机制可以有效地选取最优回答 并为各样本生成加权平均所需的权重。(图2(d))
- 多头注意力机制对token角色的区分很重要。具体而言,多头注意力机制可以将生成的回答与正样本拉近,与负样本拉远。实验表明,3个attention head是上下文对齐任务中最优选择。(图2(e))
- FFN对于token角色的转变很重要。在经过一个MHSA层后,FFN可以将上一轮的正样本屏蔽掉,从而使次优样本变成下一轮迭代的最优样本。(图2(f))
自我纠错策略:上下文检查
作者使用上下文检查(Check as Context,CaC)作为LLM完成自我纠错的方法,在两个现实世界的对齐任务中探索了自我纠错:缓解社会偏见和防范越狱攻击。

图3 BBQ数据集上使用CaC的示例。
具体而言,首先对模型请求问题获得回答初始回答,然后对该回答进行评估,得到奖励。之后将初始回答,评估送入上下文,并重新请求问题,得到改正后的回答。此过程可多次重复以迭代改进回答,最终以最后一轮的模型回答作为模型的最终输出。
消除LLM社会偏见
本文使用 BBQ(Bias Benchmark for QA)数据集,在 vicuna-7B 和 Llama2-7b-chat 模型上测试了 CaC 方法的效果。此外,还在 BBQ 上研究了模型大小、评估质量和纠错轮数对纠错效果的影响。主要结论如下:
- 多数情况下,自我纠错后的正确率高于原正确率(图4)
- 正确率提升与自我评估的准确率高度相关(图4(c): ),甚至呈线性关系(图5(a))。
- 采用不同的评价方式效果依次提升:仅使用对/错评价 < 自然语言评价 < 包含 CoT 的对/错评价。这是因为 CoT 不仅能提高评价准确性,还能为模型提供额外的自然语言信息。(图5(b))
- 更大的模型有更好的纠错能力(图5(c)(d))
- 当评价的正确率足够高时,更多的纠错轮数可以带来更好的纠错效果。(图5(e))

图4 CaC对于不同种类的偏见的修正

图5 BBQ上关于模型大小、评估质量以及纠错轮数的消融实验
同时,在防御越狱攻击的实验中,CaC也是所有测试的防御手段中最低的。
更多文章细节,请参考原文:https://openreview.net/pdf?id=OtvNLTWYww
参考资料:
[1] https://openai.com/index/introducing-openai-o1-preview/
[2] https://reflection70b.com/