【引子】在上周发布了《大模型应用系列:从Ranking到Reranking》之后, 有AI 产品经理问我,如何评估Ranking 系统的性能呢? 再进一步,如何评估RAG系统的性能呢? 老码农整理了一下在搜索引擎方面的感受,遂成此文。
如何确保RAG系统在实际应用中表现良好呢?RAG本质上具有生成能力的一个信息检索系统,Ranking/Reranking 在其中的作用非常重要。测量该系统的有效性需要提供清晰的度量指标。对信息检索系统评估的全面分析有助于团队对哪些工作正常、哪些需要改进做出明智的决定,从而指导从算法选择到微调策略的各项措施。无论引入新特性还是扩大生产规模,理解评估指标和方法将确保您的系统不仅健壮,而且能够交付正确的结果。
1.信息检索系统的简要回顾
在探索评估信息检索系统的关键指标之前,让我们首先了解一些基础概念。当我们在搜索引擎中输入关键词以寻找特定主题的信息时,系统会生成一个结果列表。这个列表是根据算法确定的,该算法评估每个文档、文章或网页与查询请求之间的相关性,并据此对它们进行Ranking。因此,当你浏览包含标题、摘要及链接的搜索结果页面时,实际上就是在查看经过精心筛选和排序后的信息集合——这正是信息检索过程的核心所在。
为了更好地理解这一过程及其效果,接下来介绍几个用于衡量信息检索系统表现的重要术语。这些术语不仅有助于我们更清晰地认识到不同系统之间存在的差异,也为后续深入探讨各种评估方法奠定了基础。
1.1 实际值与预测值
在评估信息检索系统的性能时,我们将实际情况与预测情况进行对比。其中:
实际值指的是数据集中每项的真实标签。如果某项与查询相关,则标记为正(p);如果不相关,则标记为负(n)。这代表了基本事实。
预测值则是信息检索系统返回的预测标签。对于被系统选中并返回的项目,其预测值为正;而对于未被选中或没有出现在返回结果中的项目,其预测值为负。
通过这种比较方式,我们可以更准确地衡量信息检索系统的有效性和准确性。
1.2 相关性
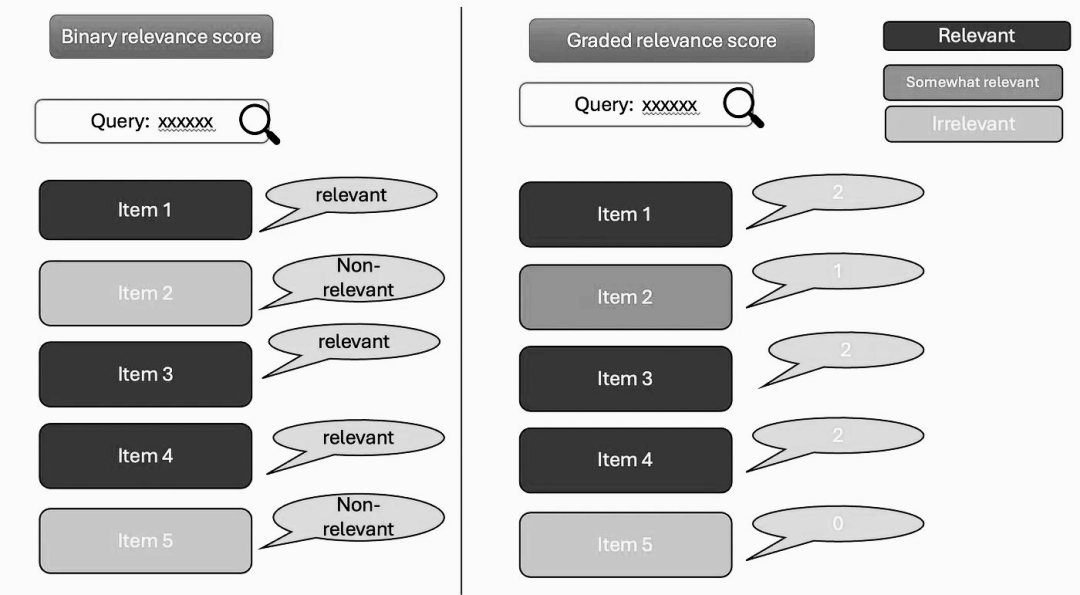
相关性是指信息与查询需求之间的匹配程度,它可以通过两种主要方式来衡量:二进制的布尔值或分级分数。
布尔得分是一种简单直观的方法。对于每个项目,根据用户的互动行为来判断其是否相关。例如,如果用户点击了某个项目,则认为它是相关的;如果他们跳过了该项目,则认为不相关。更进一步地,如果用户将某项加入购物车、标记为喜欢或者开始使用它,这些行为也被视为强相关性的信号。通过跟踪并分析用户的这些操作,我们可以有效地确定哪些推荐内容是真正符合用户需求的。
另一方面,分级评分系统则为不同的用户行为赋予了具体的数值权重。比如,一次普通的点击可能得到1分,而将商品保存至个人收藏夹可以获得2分;添加到购物车的行为或许能拿到3分;最终完成购买则可获得最高分——4分。这种评分机制需要精心设计,以确保每种类型的互动都能恰当反映用户的偏好强度。然而,在实际操作中,建立一个既公平又高效的分级体系可能会遇到不少挑战。
有时,评分过程可以自然发生。例如,当用户对他们购买的商品或观看的电影给出1到5星的评价时,这些数字评分可以直接用于衡量相关性。在某些特定场景下,如互联网搜索,标注人员可能会介入并提供结构化的评分。他们会根据特定的查询条件审查文档的相关部分,并手动分配分数以表示其相关性程度。
此外,我们还可以利用用户数据来创建实际值。假设我们已经训练了一个电影推荐模型,并使用用户的观影历史为每个用户生成了一组预测结果(即系统认为用户可能喜欢的电影)。接下来,我们可以将这些推荐与用户在训练数据之外观看的内容进行比较。在这种情况下,用户后续观看的电影记录就成为了评估模型性能的重要依据。
1.3 相关性判断
相关性判断,也称为qrel,本质上是由三元组(q, d, r)组成的集合,其中r代表对查询‘q’与文档‘d’之间关系的人工注释。简而言之,这些相关性判断是人类创建的标签,用于将文档按照其与特定查询的相关程度进行分类。这些判断通常被保存在文本文件中,可以作为测试集的一部分下载,也可以作为一种“基本事实”供研究使用。
‘r’的值可以是布尔类型,指示文档是否与查询相关;但更常见的做法是采用三级(不相关、相关和高度相关)或五级(完美、优秀、好、公平和差)等非二元评价体系。对于网络搜索来说,五级评分系统尤为常见,这种分级方法能够更细致地反映文档与查询之间的匹配度。
相关性判断在信息检索领域扮演着至关重要的角色,不仅有助于在监督环境下训练排名模型,还为评估这些模型的性能提供了基准。尽管对于熟悉应用机器学习的人来说这似乎有些反直觉——即同一个数据集同时用于训练和评估,但实际上这种做法反映了数据集在不同阶段(如训练、开发和测试)中的作用差异。值得注意的是,如果一个信息检索数据集合规模较小,则可能需要额外的措施来确保模型得到有效训练,而不仅仅是通过简单的参数调整。幸运的是,一些大型数据集已经包含了足够的相关性判断,足以支持在监督环境下有效地训练Ranking模型。
1.4 Top-K 参数
在对信息检索系统的性能进行Ranking评估时,定义一个合适的K参数是至关重要的。"K"代表的是我们希望考察的最佳推荐项的数量,即从所有可能的结果中挑选出最相关的前K个条目来进行评价。这个参数的选择不仅直接影响到评估结果的准确性和可靠性,还反映了用户对于搜索结果质量的期望水平。通常情况下,K值会根据具体的应用场景、数据集特性以及业务需求来确定,以确保能够全面而准确地衡量系统的有效性。
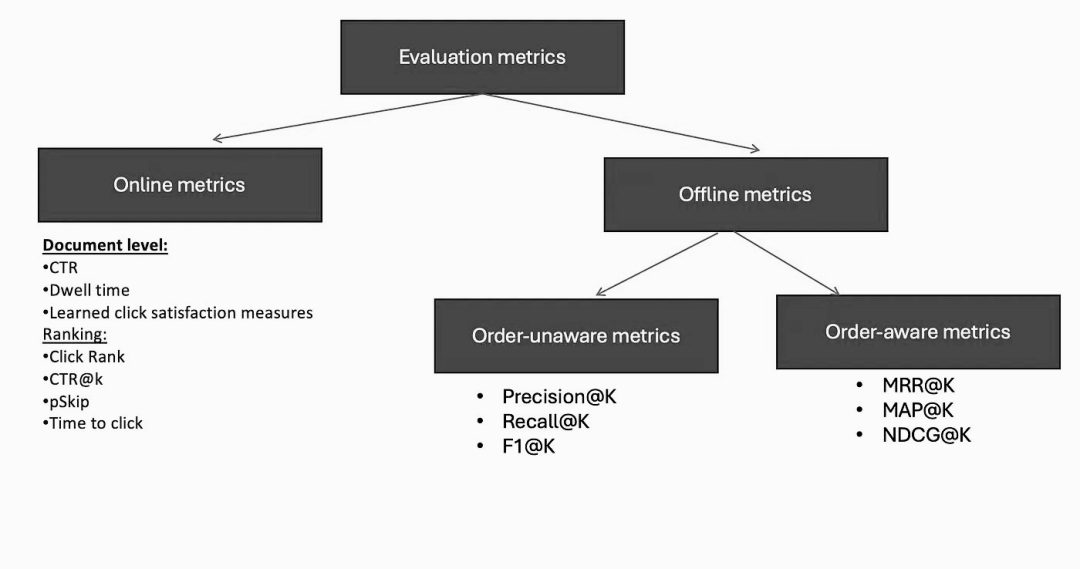
1.5 离在线满意度评估
离在线满意度评估是一种综合方法,用于衡量信息检索系统的性能。离线指标主要用于在系统部署前预测其性能,通过对历史数据和模拟查询的分析来估计模型的潜在效果。而在线指标则在系统部署后使用,直接反映用户对搜索结果或推荐内容的实际反应和满意度。这种双重评估机制不仅有助于优化系统设计,还能确保系统在实际运行中满足用户需求,提供高质量的服务体验。
2.离线满意度评估
为了更深入地理解离线指标的应用,我们可以通过一个宠物鸟推荐系统的例子来说明。这个示例根据用户的具体需求(如希望养一只安静、易于照料的鸟类)以及各种鸟类的特性(如叫声大小、护理难度等),为用户推荐最适合他们的宠物鸟种类。
在这个场景中,我们可以使用ranx Python包来演示如何在代码中评估推荐系统的有效性。ranx是一个专为快速计算排名相关评估指标而设计的库,它利用Numba进行高效的矢量操作和自动并行化处理,从而大大提高了计算速度。要安装ranx,只需运行以下命令:pip install ranx。该工具提供了一个直观易用的接口,使得开发者能够轻松地对不同的信息检索或推荐算法进行性能比较,包括但不限于精确度、召回率及F1分数等关键指标。通过这种方式,即使在没有真实用户参与的情况下,也能较为准确地预测出新开发的信息检索或推荐系统在实际应用中的表现如何。
2.1 Precision@K
Precision@K 用于度量检索结果的准确度。它关注的是,在返回的前K个搜索结果中,有多少个是与查询内容真正相关的。这一指标并不考虑这些相关结果的具体排序位置,而只专注于统计相关结果的数量。具体来说,为了计算Precision@K,我们需要将前K个结果中的相关项数量除以K。
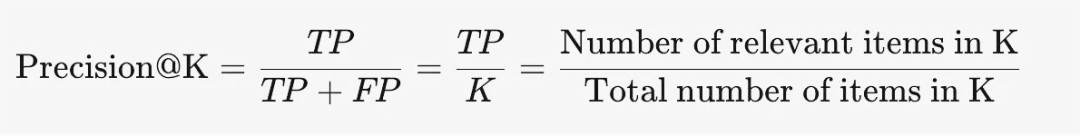
from ranx import Qrels, Run, evaluate, compare#人工标注的真实数据
qrels_dict = {'Colorful pet birds' : {'African_love_birds' : 1,'Sun_conure' : 1, 'Budgies': 1,'Monk_parrot' : 1,'Macaw' : 1,'Indian_Blue_Ring_neck_parrot' : 1,},
}
#模型输出的预测结果
run_dict = {'Colorful pet birds' : {'African_love_birds' : 0.95,'Cocktails' : 0.9,'Sun_conure' : 0.8, 'Finches' : 0.7, },
}
qrels = Qrels(qrels_dict)
run = Run(run_dict)
results=evaluate(qrels, run, ['precision@4'])
print(results)2.2 Recall@K:
Recall@K 指标有助于我们了解从给定数据集中检索所有相关项目的情况。Recall不注意结果的顺序,它是无意识的顺序。它只关注我们设法找到的相关项目的数量。为了计算召回率,我们将前K个结果中的相关项目数量除以整个数据集中的相关项目总数。它表达是的系统捕获所有相关信息的效率有多高。
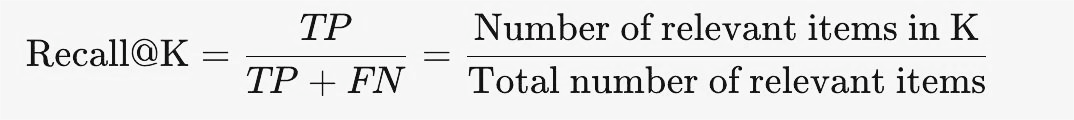
results=evaluate(qrels, run, ['recall@10'])
print(results)2.3 MRR ——平均倒数排名
平均倒数排名(MRR)指标帮助我们了解系统在寻找相关结果并将其置于最顶端方面的表现如何。它关注的是第一个相关结果的顺序,而不是其他相关结果的数量或顺序。为了计算 MRR@K,我们采用每个查询(信息检索系统)或用户(推荐系统)的第一个相关结果的相关性排名,然后在评估的数据集中对它们进行平均。它为我们提供了一个指标,衡量系统在多大程度上一致地将相关结果作为最佳结果。

其中,RR是ranking的倒数:

MRR通过计算模型对于询的第一个正确答案排名的倒数,然后对所有查询的倒数排名取平均得到。
#人工标注的真实数据
qrels_dict = {'Colorful pet birds' : {'African_love_birds' : 1,'Sun_conure' : 1, 'Budgies': 1,'Monk_parrot' : 1,'Macaw' : 1,'Indian_Blue_Ring_neck_parrot' : 1,},'Talking pet birds' : {'African_grey_parrot' : 1,'Indian_Blue_Ring_neck_parrot' : 1, 'Macaw' : 1,'Monk_parrot': 1,'cockatoo': 1,},'Singing birds' : {'cocktails' : 1,'cockatoo' : 1, 'Macaw' : 1},
}
#模型输出的预测结果
run_dict = {'Colorful pet birds' : {'African_love_birds' : 0.95,'Cocktails' : 0.9,'Sun_conure' : 0.8, 'Finches' : 0.7},'Talking pet birds' : {'Sun_conure' : 0.92,'Indian_Blue_Ring_neck_parrot' : 0.91, 'Monk_parrot': 0.83,'African_grey_parrot' : 0.82},'Singing birds' : {'Monk_parrot' : 0.79,'Cocktails' : 0.75, 'cockatoo': 0.70,'Macaw' : 0.69},
}
qrels = Qrels(qrels_dict)
run = Run(run_dict)
results=evaluate(qrels, run, ['mrr@4'])
print(results)MRR 是评估排序模型的指标,衡量了在给定查询情况下,相关结果在排序中的位置。MRR 适用于需要关注第一个相关结果的任务,如问答系统和链接推荐。MRR 计算的是平均倒数排名,即平均倒数的位置,越接近1表示性能越好。
2.4 平均准确度(MAP)
均值平均准确度(MAP)度量评估系统在top-K 结果中返回相关项目的能力。为了计算 MAP@K,我们对评估数据集中的多个查询或用户推荐的精度进行平均。它帮助我们了解系统提供相关结果准确性的能力,从而使最相关的项目具有更高的优先级。

其中,AP@k 衡量了在给定查询情况下,检索结果在前k个位置的准确性。它对于信息检索领域中的排名任务非常有用,尤其是在评估检索系统的性能时。AP@k 更关注前k个结果的相关性和排名,适用于需要重点关注前几个结果的任务。AP@k)的取值范围是从0到1之间,其中1表示最佳性能,而0表示最差性能。

MAP是一个常用的评估指标,较高的MAP值表示模型在返回的结果中有更高的平均精确度,即相关文档排名更靠前。MAP@K 度量了 K 项结果中所有相关位置的精度值,并对它们进行平均,示例代码如下:
#人工标注的真实数据
qrels_dict = {'Colorful pet birds' : {'African_love_birds' : 1,'Sun_conure' : 1, 'Budgies': 1,'Monk_parrot' : 1,'Macaw' : 1,'Indian_Blue_Ring_neck_parrot' : 1,},'Talking pet birds' : {'African_grey_parrot' : 1,'Indian_Blue_Ring_neck_parrot' : 1, 'Macaw' : 1,'Monk_parrot': 1,'cockatoo': 1,}
}#模型输出的预测结果
run_dict = {'Colorful pet birds' : {'African_love_birds' : 0.95,'Cocktails' : 0.9,'Sun_conure' : 0.8, 'Finches' : 0.7},'Talking pet birds' : {'Sun_conure' : 0.92,'Indian_Blue_Ring_neck_parrot' : 0.91, 'Monk_parrot': 0.83,'African_grey_parrot' : 0.82}
}
qrels = Qrels(qrels_dict)
run = Run(run_dict)
results=evaluate(qrels, run, ['map@4'])
print(results)MAP 是检索系统性能的平均精度指标,它计算所有查询的平均 AP 值。MAP 适用于信息检索领域,特别是在评估整个系统的性能时。它综合考虑了所有查询的结果,并给予每个查询相同的权重。
2.5 归一化折扣累积增益(NDCG)
归一化折扣累积收益(NDCG)不仅考虑了文档是否相关,还考虑了文档如何相关。它衡量了系统根据相关性对文档进行排名的能力。计算NDCG@K,需要先计算折扣累积增益(DCG),然后将其归一化到理想累积增益上(IDCG)。它让我们全面了解了该系统根据相关程度对项目进行排序和优先级排序的能力。使用 ranx计算 NDCG@K的代码如下所示:
#人工标注的真实数据
qrels_dict = {'Colorful pet birds' : {'African_love_birds' : 3,'Sun_conure' : 4, 'Budgies': 2,'Monk_parrot' : 2,'Macaw' : 4,'Indian_Blue_Ring_neck_parrot' : 2,},'Talking pet birds' : {'African_grey_parrot' : 4,'Indian_Blue_Ring_neck_parrot' : 2, 'Macaw' : 3,'Monk_parrot': 1,'cockatoo': 3,}
}#模型输出的预测结果run_dict = {'Colorful pet birds' : {'African_love_birds' : 0.95,'Cocktails' : 0.9,'Sun_conure' : 0.8, 'Finches' : 0.7},'Talking pet birds' : {'Sun_conure' : 0.92,'Indian_Blue_Ring_neck_parrot' : 0.91, 'Monk_parrot': 0.83,'African_grey_parrot' : 0.82}
}
qrels = Qrels(qrels_dict)
run = Run(run_dict)
results=evaluate(qrels, run, ['ndcg@4'])
print(results)NDCG 是衡量排序质量的指标,它考虑了候选答案的相关性和排名累计得分的影响,并对累计得分进行折扣和归一化。NDCG的取值范围是0到1,值越接近1表示模型在排序质量上的表现越好。NDCG 考虑了排名的相关性和位置,较好地解决了 AP@k 中可能忽略了后续结果的问题。
总体而言,如果需要关注整个结果集的排序质量,可以使用 NDCG、AP@k 或 MAP。如果目标更关注前几个结果的排序准确性,AP@k 可能更适合。而如果目标重点关注第一个相关结果的位置,那么 MRR 可能更合适。
3.在线满意度评估
在线评估围绕着通过日志数据分析用户行为来实时衡量系统性能。它衡量真实用户在现实环境中与信息检索系统的交互方式。它不依赖于受控测试或专家判断,而是关注用户自然表现出的点击、停留时间和其他行为等隐含信号。与通常使用预定义相关性判断的离线评估不同,在线评估通过捕捉实际用户体验提供了更真实的视图。
在线评估通常与A/B测试相结合,目标是确定哪个版本可以提高用户参与度或转化率。通过将用户分成不同的部分进行测试,我们可以衡量特定变化对用户行为的影响。
当涉及到评估一个信息检索系统时,颗粒度可能会有所不同。有些可能关注排名系统的整体质量(列表级别) ,或者放大单个文档如何满足用户对特定查询(结果级别)的需求。方法的选择取决于我们想要回答的关于系统性能和用户体验的具体问题。
3.1 点击率(CTR)
点击率(CTR)用于衡量文档在搜索结果页上出现时对特定查询的平均单击次数,回答本系统返回的文档是否相关。CTR 度量是通过将文档接收到的点击次数除以它在搜索结果页上显示的次数来计算的。例如,如果一个文档被显示100次并接收到10次点击,那么点击率将是10% 。
然而,需要注意的是,为 CTR 收集的数据可能是有噪音和偏差的。造成这种偏差的一个主要因素是文档在搜索结果页上的位置。在页面上显示较高位置的文档比显示较低位置的文档更容易获得点击。这种偏差可能会歪曲 CTR 指标,使其在代表用户的真实参与度方面不那么准确。
要计算 CTR,可以使用以下代码:
import pandas as pd# Create a pandas dataframe with the data
data = {'Document': ['Document A', 'Document B', 'Document C', 'Document D'],'Impressions': [100, 200, 150, 300],'Clicks': [10, 20, 15, 30]}
df = pd.DataFrame(data)
# Calculate CTR
df['CTR'] = df['Clicks'] / df['Impressions'] * 100
print(df)3.2 停留时间(dwell time)
在提升搜索质量的过程中,停留时间是一个关键指标,用于评估用户对单次点击后所浏览内容的满意程度。一般来说,如果用户在页面上花费更多时间,这通常意味着他们发现的内容对他们来说是有用或有趣的,这是高质量文档的一个良好标志。
基于日志分析,一般的停留时间通常为30秒。然而,值得注意的是,“满意度”的高低实际上取决于内容的性质。例如,一个用户可能会花费更长的时间在一篇详细的研究文章上,而不是一篇简短的博客文章。
下面是一个计算停留时间的简单 Python 代码示例:
import pandas as pd# Assuming df is your DataFrame and it has a column 'entry_time' and 'exit_time'
# Convert them to datetime if they are not already
df['entry_time'] = pd.to_datetime(df['entry_time'])
df['exit_time'] = pd.to_datetime(df['exit_time'])# Calculate dwell time
df['dwell_time'] = (df['exit_time'] - df['entry_time']).dt.total_seconds()
# Filter dwell times that are longer than 30 seconds
satisfied_clicks_df = df[df['dwell_time'] >= 30]3.3 点击排名(click rank)
点击排名用于测量用户在搜索结果中点击文档的位置,以此评估系统对于特定查询的整体表现。如果用户倾向于点击排名靠前的文档(即其点击排名较低),则通常认为检索系统运行良好。例如,如果用户点击了第一个结果,那么点击排名为1;如果他们点击了第三个结果,点击排名则为3,以此类推。因此,较低的平均点击排名表明系统性能更佳,因为它意味着用户通常会点击排名较高的结果。
然而,这个度量标准存在局限性。当比较两个排名系统时,如果一个系统的相关文档较少而另一个较多,低平均点击排名可能导致误导性的结论。这是因为相关结果较少的系统可能仅仅因为用户可选的选项较少而表现出较低的平均点击排名,并不一定意味着该系统性能更优。
点击排名的一种变体是倒数排名。例如,如果用户点击了第一个结果,倒数排名为1/1 = 1;如果他们点击了第三个结果,倒数排名则为1/3 ≈ 0.33。在这种情况下,倒数排名越高,表明系统的性能越好。
下面是一个简单的 Python 代码示例,用于计算点击排名和点击倒数排名。
import pandas as pd# Assuming df is your DataFrame and it has a column 'click_position'
df['click_rank'] = df['click_position']
# Calculate reciprocal rank
df['reciprocal_rank'] = 1 / df['click_rank']3.4 CTR@k
CTR@k 衡量搜索结果列表中top-k 位置内的点击率与展示次数(链接显示的次数)的比率。例如,如果我们有 CTR@10,这意味着我们只考虑搜索结果中的前10个位置。如果点击这10个结果中的5个,那么 CTR@10就是5/10 = 50% 。
CTR@k 对于理解用户与搜索结果页面的关系非常有用。CTR@k 越高,表明用户发现排名前 K 位置的搜索结果越有相关性或吸引力。
下面是一个计算 CTR@k 的简单 Python 代码示例:
import pandas as pd# Assuming df is your DataFrame and it has a column 'clicked' (1 if clicked, 0 otherwise)
# and 'position' (the position of the result in the search results)
# Filter the DataFrame for the top k positions
k = 10
top_k_df = df[df['position'] <= k]
# Calculate CTR@k
ctr_at_k = top_k_df['clicked'].mean()3.5 pSkip
pSkip 衡量用户跳过任何结果并点击搜索排名较低结果的概率。换句话说,它提供了一个概念,用户是否经常绕过顶部的结果,点击排名较低的。
它是点击位置度量的一个高级变体,它提供了对用户行为和搜索结果相关性的更深入的了解。如果跳过的可能性很低,这表明用户在搜索结果的顶部找到了他们需要的东西,这表明搜索排名很高。
下面是一个使用Padas DataFrame 计算 pSkip 的简单代码示例:
import pandas as pd# Assuming df is your DataFrame and it has a column 'click_position'
# representing the position of the clicked result in the search results
# Calculate total number of clicks
total_clicks = df['click_position'].count()
# Calculate number of clicks that are not at the first position
skipped_clicks = df[df['click_position'] > 1].count()
# Calculate pSkip
pSkip = skipped_clicks / total_clicks3.6 点击时间
点击时间用于衡量从搜索结果页面展示给用户到用户通过点击与信息检索系统进行交互之间的整个时间段。这一指标反映了用户找到相关搜索结果的速度。
这个度量指标存在不同的变体。例如,“首次点击时间”(time to first click)测量的是用户在搜索结果页面显示后点击任意结果所需的时间。另一方面,“最后一次点击时间”(time to last click)指的是从搜索结果页面展示到用户进行最后一次点击的时间间隔。
一般来说,点击时间越短,表明检索系统的性能越好。这是因为较短的点击时间意味着用户能够迅速找到相关结果,从而说明搜索结果与用户的查询匹配度较高。
下面是一个简单的代码示例,用于计算第一次单击和最后一次单击的时间:
import pandas as pd# Assuming df is your DataFrame and it has columns 'serp_time' and 'click_time'
# Convert them to datetime if they are not already
df['serp_time'] = pd.to_datetime(df['serp_time'])
df['click_time'] = pd.to_datetime(df['click_time'])# Calculate time to first click
df['time_to_first_click'] = df.groupby('user_id')['click_time'].transform('min') - df['serp_time']
# Calculate time to last click
df['time_to_last_click'] = df.groupby('user_id')['click_time'].transform('max') - df['serp_time']4.小结
评估信息检索系统的性能和有效性时,结合使用离线与在线指标至关重要。离线评估能够深入洞察系统的内部运作机制,帮助分析其效率、准确性及鲁棒性。通过预设的测试集,这些评估标准为我们提供了对IRS执行状况的全面认识。相比之下,在线度量则更加侧重于用户体验,通过监测用户与系统的即时互动来反映用户满意度、参与度以及成功获取相关信息的情况。点进率、停留时间和转化率等关键指标揭示了用户行为模式的变化趋势,并有助于识别出需要优化的地方、用户偏好以及整个系统在实际应用中的表现。
将离线与在线两种评价方式相结合,可以使我们对信息检索过程有一个更为全面的理解。其中,离线指标为技术层面的分析打下了坚实的基础;而在线反馈则补充了一个以用户为中心的视角。通过对这两类数据的对比分析,我们不仅能够更准确地把握当前检索系统的长处与短处,还能基于此做出更加合理的改进决策,从而不断提升用户体验和服务质量。
【关联阅读】
大模型应用的10种架构模式
7B?13B?175B?解读大模型的参数
大模型应用系列:从Ranking到Reranking
大模型应用系列:Query 变换的示例浅析
解读文本嵌入:语义表达的练习
解读知识图谱的自动构建
“提示工程”的技术分类
大模型系列:提示词管理
提示工程中的10个设计模式
大模型微调:RHLF与DPO浅析
Chunking:基于大模型RAG系统中的文档分块
大模型应用框架:LangChain与LlamaIndex的对比选择
在大模型RAG系统中应用知识图谱
面向知识图谱的大模型应用
让知识图谱成为大模型的伴侣
如何构建基于大模型的App
Qcon2023: 大模型时代的技术人成长(简)
论文学习笔记:增强学习应用于OS调度
LLM的工程实践思考
大模型应用设计的10个思考
基于大模型(LLM)的Agent 应用开发
解读大模型的微调
解读向量索引
解读ChatGPT中的RLHF
解读大模型(LLM)的token
解读提示词工程(Prompt Engineering)
解读Toolformer
解读TaskMatrix.AI
解读LoRA
解读RAG
大模型应用框架之Semantic Kernel
浅析多模态机器学习
深度学习架构的对比分析
老码农眼中的大模型(LLM)