数字人Live_Talking的搭建和使用
Live_Talking是一个实时交互流式数字人,可以实现音视频同步对话。今天咱们来试着部署一下项目。
先来看下本地环境
系统:Ubuntu 22.04
显卡:rtx 3060
cuda: Cuda 12.1
git上推荐cuda11.3,但是我用cuda12.2也搭建成功了。
1、先来下载git 代码
git clone https://github.com/lipku/LiveTalking.git2、conda 创建环境
conda create -n nerfstream python=3.10conda activate nerfstream
3、去https://pytorch.org/get-started/previous-versions/官网上面找到cuda对应版本的pytorch安装下
conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 pytorch-cuda=12.1 -c pytorch -c nvidiapip install -r requirements.txt
安装过程很顺利,没出现什么问题
4、下载模型
夸克云盘https://pan.quark.cn/s/83a750323ef0
GoogleDriver https://drive.google.com/drive/folders/1FOC_MD6wdogyyX_7V1d4NDIO7P9NlSAJ?usp=sharing
下载后按照这个方式修改下放到对应目录下面
将wav2lip256.pth拷到本项目的models下, 重命名为wav2lip.pth;
将wav2lip256_avatar1.tar.gz解压后整个文件夹拷到本项目的data/avatars下
4、接着跑下代码试试。
python app.py --transport webrtc --model wav2lip --avatar_id wav2lip256_avatar1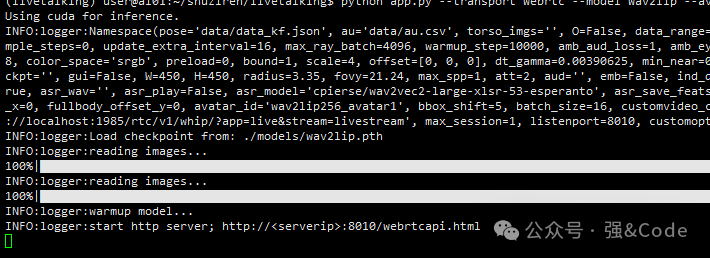
显示成功,浏览器中输入地址,如图:
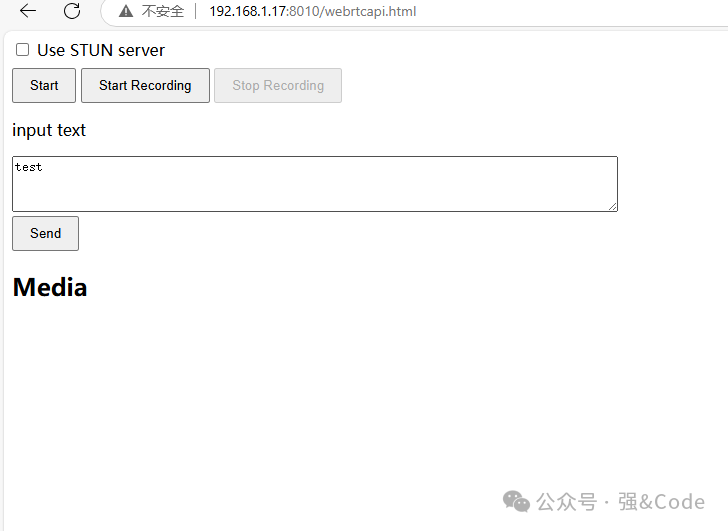
咦,怎么没有数字人形象呢?而且,输入文字,一点send就报错。
研究了半天,又是看源码,又是重新搭建环境的,到最后才发现需要先点start,效果如图
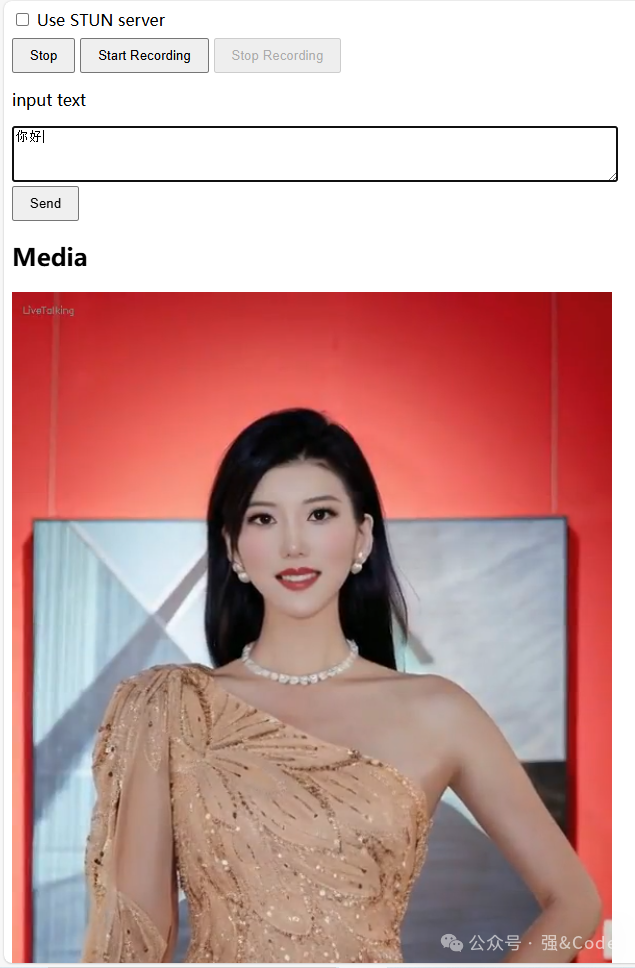
哎...终于成功了。
这就是搭建livetalking的整个过程,大家在搭建的过程中有遇到什么问题的欢迎留言,大家一起讨论学习。