map和set:
今天学习map和set

我们看图中,我们的搜索树和我们之前学习的数据结构是不一样的,他的每个数据之间的关联是比较大的,他就没有头尾的之类的插入,他只有说是按他自己的方式来进行插入。
二叉树搜索树不仅是用来存储数据,他建立这种关联性之后,可以方便快速的查找搜索。
set:
std::set 是关联容器,它存储的是唯一元素,并且元素会按照升序排列。set 中的元素一旦插入就不能修改,因为修改可能会破坏元素的顺序。
set的底层是红黑树,红黑树是我们的一颗平衡二叉搜索树。
库里面的set分为一个允许冗余,一个不允许冗余,multiset,这个表示允许冗余;
这个实际当中我们用的不多;
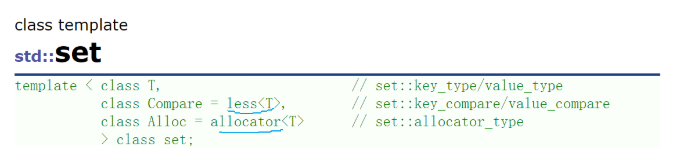
我们看我们的这个容器,第一个参数是我们的模板类型,第二个参数是我们的仿函数,当我们的比较逻辑不满足我们的需要的时候,这时候我们就可以自己完成一个仿函数来完成比较逻辑,第三个是我们的内存池。

我们看我们的set,二叉搜索树可以增删查,但是不能进行修改。
容器的构造:
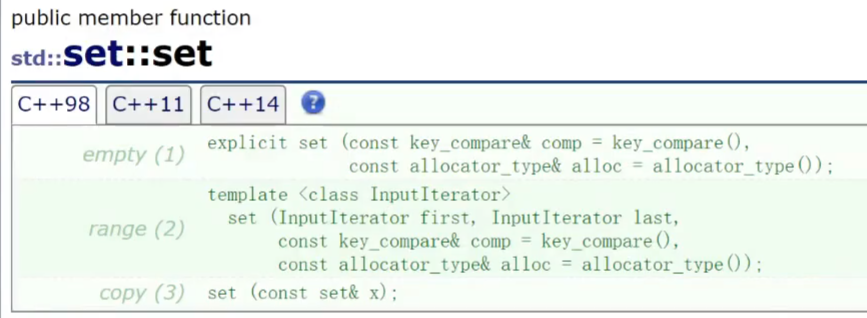

set的构造:
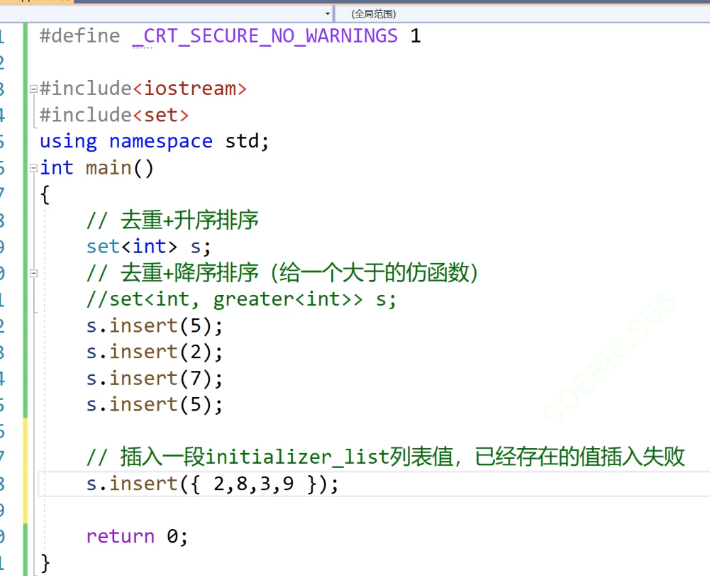
可以是insert的插入,也可以是插入一段内存空间,initializer_list的初始化方式。
我们的initializer_list的初始化方式其实就是遍历我们的数据,然后逐个的insert。
容器迭代器:
我们的这个容器的迭代器是一个双向的迭代器,不是随机的,和我们的list一样。
我们的迭代器的遍历走的是中序的遍历方式,这个遍历我们就是要看迭代器的底层是怎样封装实现的。

我们不能通过我们的迭代器去修改我们的set的里面的数据。
set的接口:
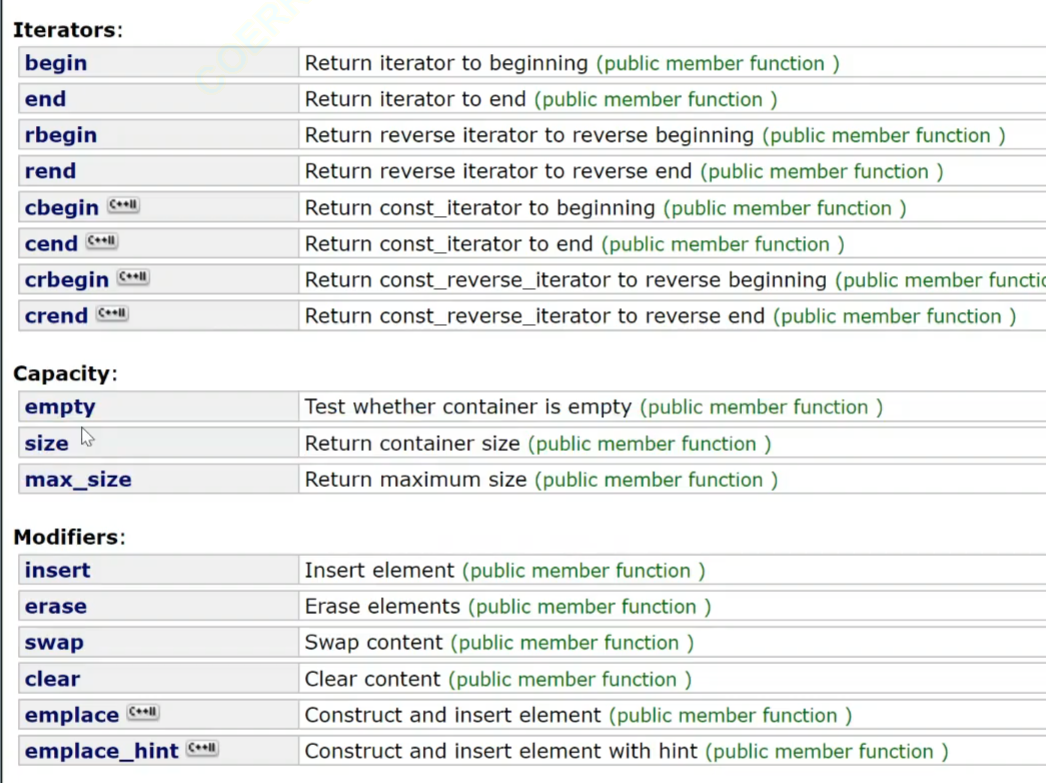
set的使用:
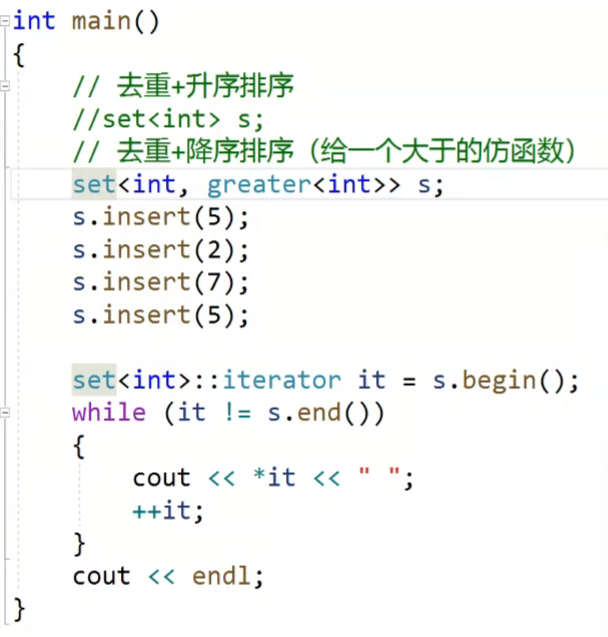
我们看这个代码,他最终的结果是:7 5 2;
我们的set是不允许有冗余的数据的,所以,我们会进行去重,,然后我们这里的set的第二个参数我们传的是greater这个仿函数,所以这里是降序。
如果不传的话,他的默认的逻辑是升序,因为他的遍历的方式是我们的中序遍历,刚好就是升序的,他的默认的仿函数也是less,这个也表示升序,和我们之前学习的是一样的。
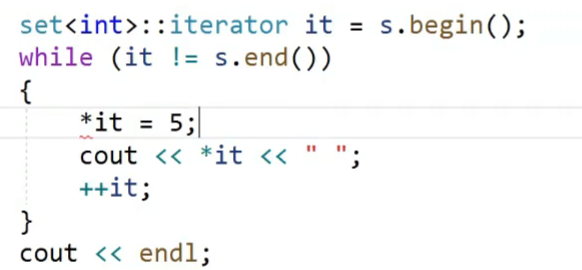
我们看这个迭代器,这里我们使用迭代器对我们的红黑树的结点的值进行修改,他就会报错,我们的红黑树的值是不允许被修改的,这个平衡的二叉搜索树,里面的值都是有序的存放的,一个数据被修改,可能这个二叉树的有序就会被破坏。所以我们的红黑树的结点里面的数据是不允许被修改的。
核心接口:
我们的set容器的底层是我们的红黑树,我们可以暂时的理解为平衡的二叉搜索树。他的核心的接口,我们上节已经讲过了,二叉搜索树有三个核心的接口:Insert();Find();Erase();这三个是核心的接口;
find():

find接口,查找我们的val数据,找到后,会返回我们的val数据的位置的迭代器,如果没有找到这个数据,我们就返回end()位置的迭代器,我们的end()位置的迭代器就是一个无效的迭代器。
erase函数:

可以是删除一个迭代器位置的数据,也可以是删除以一个数据,这个数据让他自己去查找,找到以后删除,,我们的上面的erase,他是删除迭代器位置的数据以后会返回下一个位置的迭代器去更新迭代器,我们的下面的erase函数,删除val以后,他的返回值是size_t类型的,删除成功返回1,val不存在,删除失败返回0,这里为什么他的返回值是size_t类型的,这是因为我们的set是不允许冗余的,但是我们的multiset是允许冗余的,我们的multiset里面有重复的数据的时候,假如我们现在要删除这个重复的数据,这时候我们删除就是把他全部删完,这时候我们的erase函数,返回的就是我们删除的数据的个数。(删掉几个就返回几)。
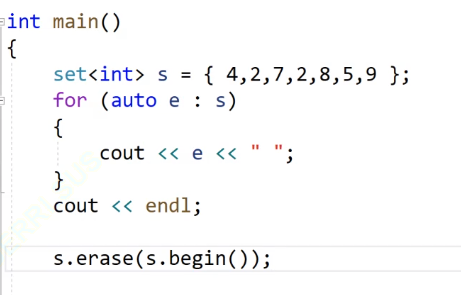
我们看这个图片:我们首先initializer_list初始化我们的set的对象s,然后我们的erase函数要删除我们的开始位置的迭代器,因为我们的二叉搜索树的迭代器的遍历方式是中序遍历,也就是从小到大的遍历方式,所以我们的begin()位置就是我们的开始的位置,就是2,我们的这个代码就是把2删除掉。
我们也可以是传一个数据进去:
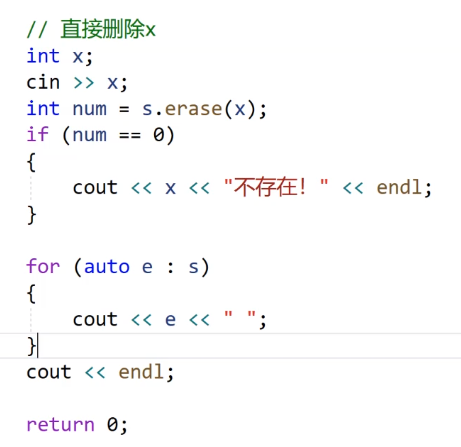
我们看这个代码:我们输入一个值进去,然后删除。

这种也可以。
count接口:
count接口,我们传一个数进去,会返回我们的容器里面有这个数的个数。
平常我们判断一个数据在不在容器里面的时候,我们这样:

我们的set的新的接口count:

我们现在可以使用count来判断我们的容器里面有没有这个数据,我们的count会返回我们的容器里面的这个数据的个数。
lower_bound():
我们的lower_bound() 和我们的upper_bound()都是用来寻找边界的,lower_bound():是用来寻找比函数参数里面的val大或者相等的值,upper_bound():是用来寻找比函数参数val大的值。
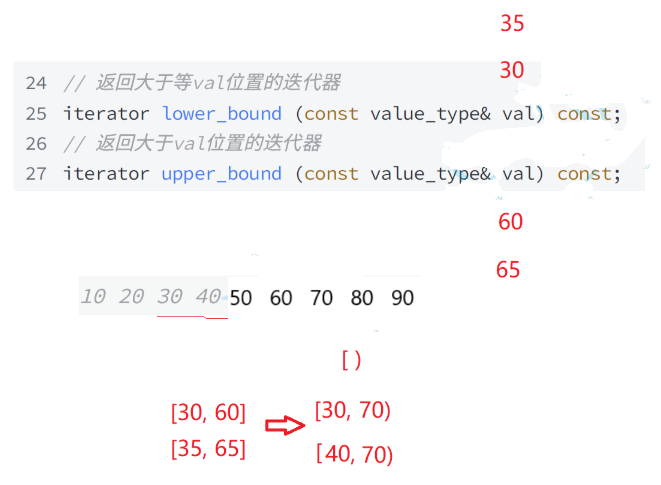
upper_bound():
我们这里的两个函数是为了方便我们找到一段左闭右开的区间;

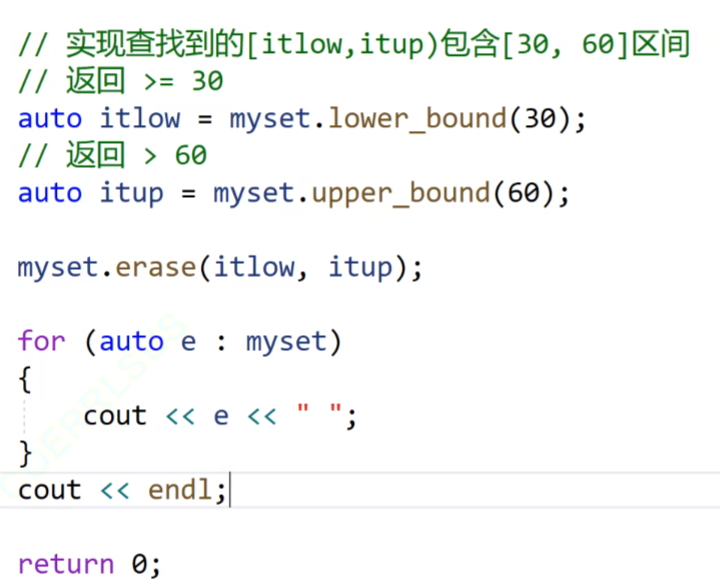
我们lower传30的时候,lower找的边界时比val大或者相等就可以,他的边界就是30,然后upper传60的时候,因为我们的upper找的是比我们的val大的值,他的边界就是70,但是不包括70,因为我们的迭代器区间时左闭右开的区间。
我们删除使用的是我们的erase,我们的erase删除函数也可以是删除一段迭代器空间。
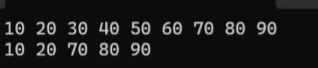
我们看上面的代码,我们的容器是10~90的数据,我们现在找到30~60的部分然后删除,我们就使用上面的两个函数来。
set和multiset的差异:

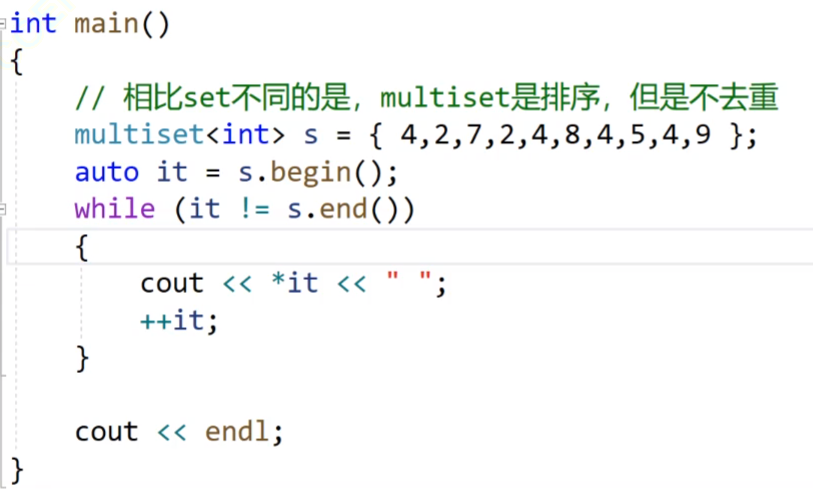
我们的multiset是不去重的,允许重复的数据产生。
还有:
这里我们说我们的find函数,当我们查找我们的数据的时候,就比如我们再multiset里查找我们的4的时候,这时候因为他又多个4,那么他返回的是哪个位置的4呢?
这里我们的结果是,我们的find查找,当我们查找的数据有多个的时候,返回的是我们的中序的第一个数据。
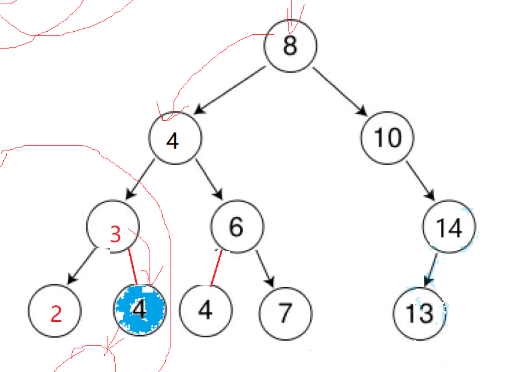
我们看这个图片:当我们查找4的时候,二叉树里面有好几个4,我们要返回的是中序的第一个位置的迭代器,我们图中标出的位置。

看这个代码,我们的find会返回我们的中序的第一个4,我们这个代码就会把所有4打印出来。
继续往下看:
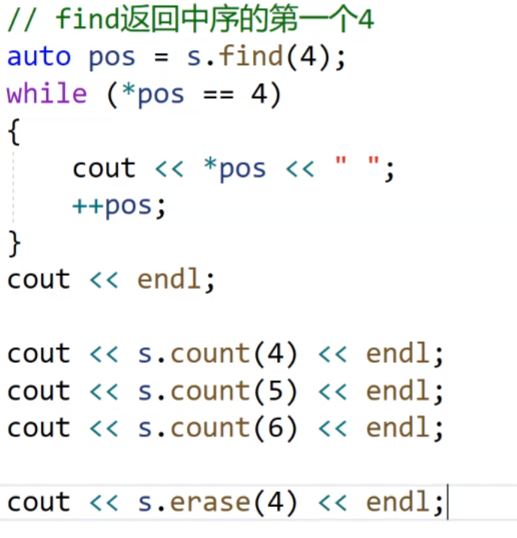
我们继续看,我们看一下multiset的接口,这个count接口还是会返回容器里面的数据的个数,然后erase函数,会返回我们删除的数据的个数。和set都一样。
我们看下面,我们也可以是删除第一个4,先使用find找到第一个4的迭代器的位置,然后把这个迭代器传给erase函数。

map:
std::map 属于关联容器,它存储的是键值对(key - value pairs),且键是唯一的。元素会按照键的顺序进行排序,默认是升序排列。
key是用来进行比较来维持我们的map的底层的红黑树的结构的。val不需要来维持底层的结构。

我们说一下,我们的set里面是存储的唯一的元素,但是我们在学习搜索二叉树的时候我们的map里面存的是一个pair值,这个值的话,我们存储的不是说是两个值,我们存储的是一对值。
因为你要是里面存了两个值的时候,我们的迭代器进行解引用可以得到两个值吗,迭代器解引用是通过重载操作符来实现的,我们的迭代器解引用本质上是调用我们的重载的函数,函数可以一次性返回两个值吗?当然不行,
所以,我们的key和val他们不是单独的存成两个数据,而是存成一个结构体,pair类型。
pair:


看上面的代码,这个就是我们的pair,我们的pair是一个类,里面的两个成员变量first和second是我们的key和val。
我们的map的底层是我们的红黑树,红黑树的结点里面是我们的pair和两个指针。
map的结构:
我们看我们的map的结构和我们的set是高度相似的,只有些许不同。
我们来写代码:

我们看我们的map的数据插入,我们可以是创建一个有名的对象插入,也可以是匿名对象的插入,但是最方便的还是我们的隐式类型转换,我们的第三种初始化方式。
std::map 的 insert 成员函数接收的参数类型是 std::pair<const Key, T> ,而 {"right", "右边"} 是花括号初始化列表形式,编译器会将其隐式转换为 std::pair<const std::string, std::string> 类型,从而匹配 insert 函数的参数要求完成插入操作。
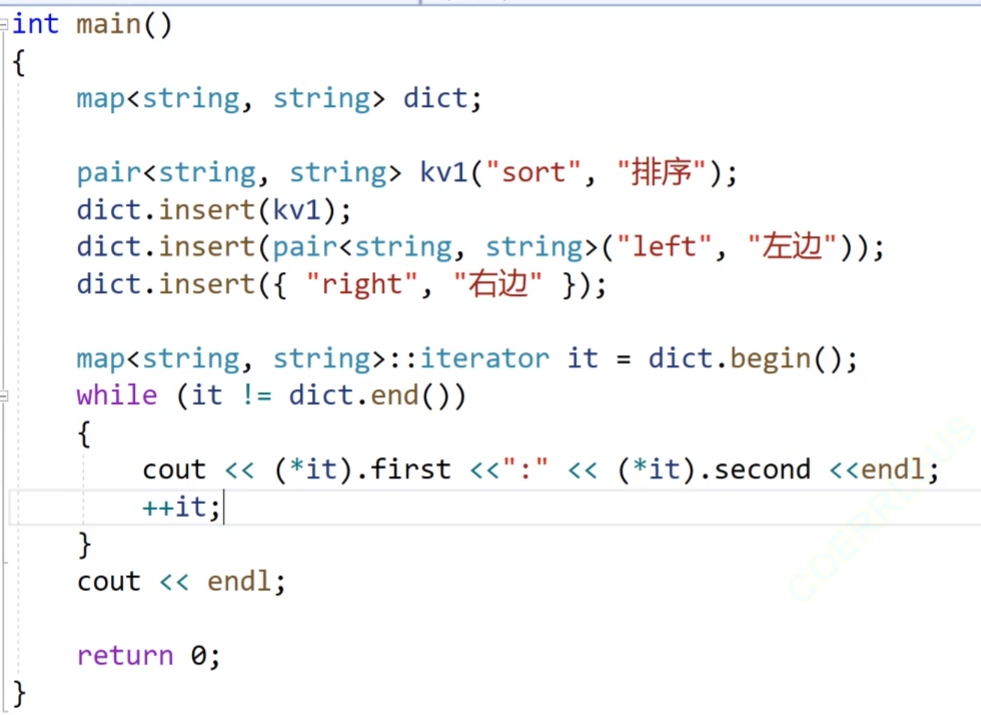
我们看上面的代码:上面的这个代码,我们使用迭代器解引用得到我们的结点里面的结构体,然后可以直接访问里面的数据,因为我们定义的pair是struct公有的。
map的方括号[]:
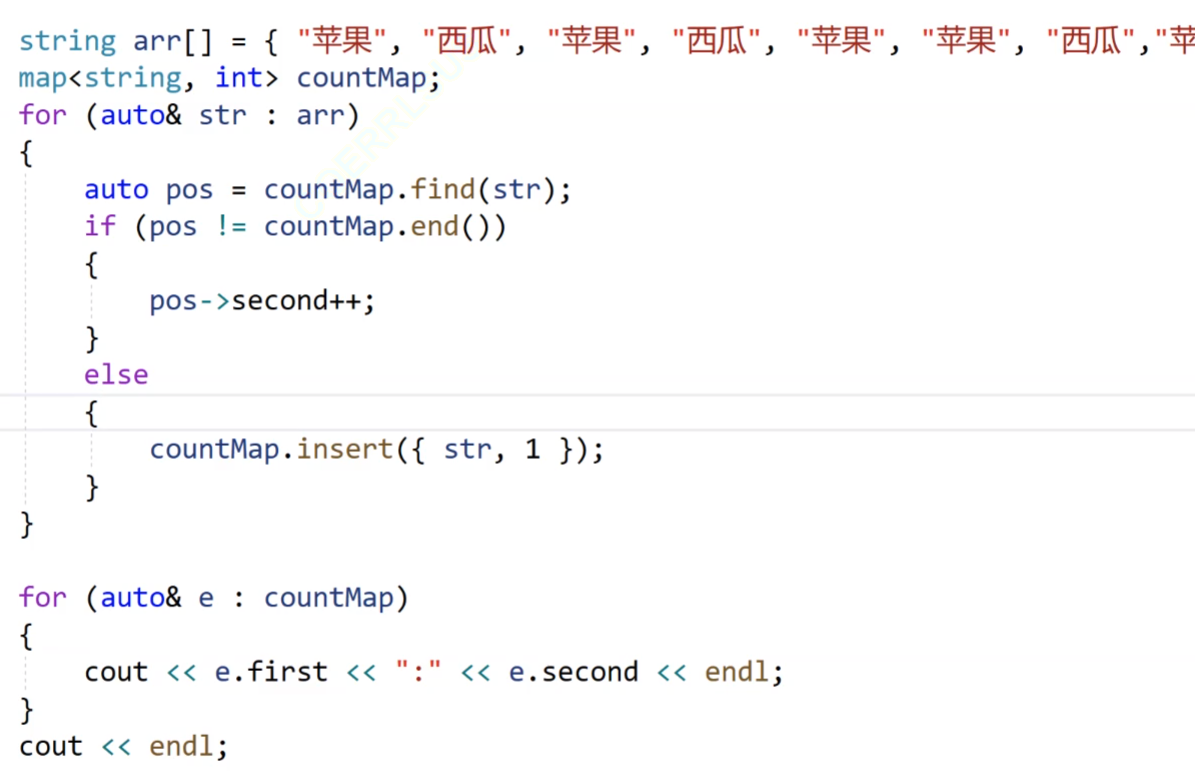
我们看上面的代码,我们创建了一个数组,然后我们使用map来进行记录,我们使用范围for来遍历这个arr数组,我们把数据和这个数据在arr里面出现的次数记录下来。
我们之讲过,我们的set底层是我们的红黑树,红黑树的结点里面的数据是不能被修改的,但是我们的map我们可以使用·迭代器去修改里面的数据,我们的map的底层也是我们的红黑树,我们当然不能破坏掉红黑树的结构,我们的map维持红黑树的结构的是我们的key,但是我们的右边的val,我们不需要他来维持我们的红黑树的结构,我们是可以对他进行修改的。
我们的上面的代码,我们其实还有一种更简便的方式来进行代替:
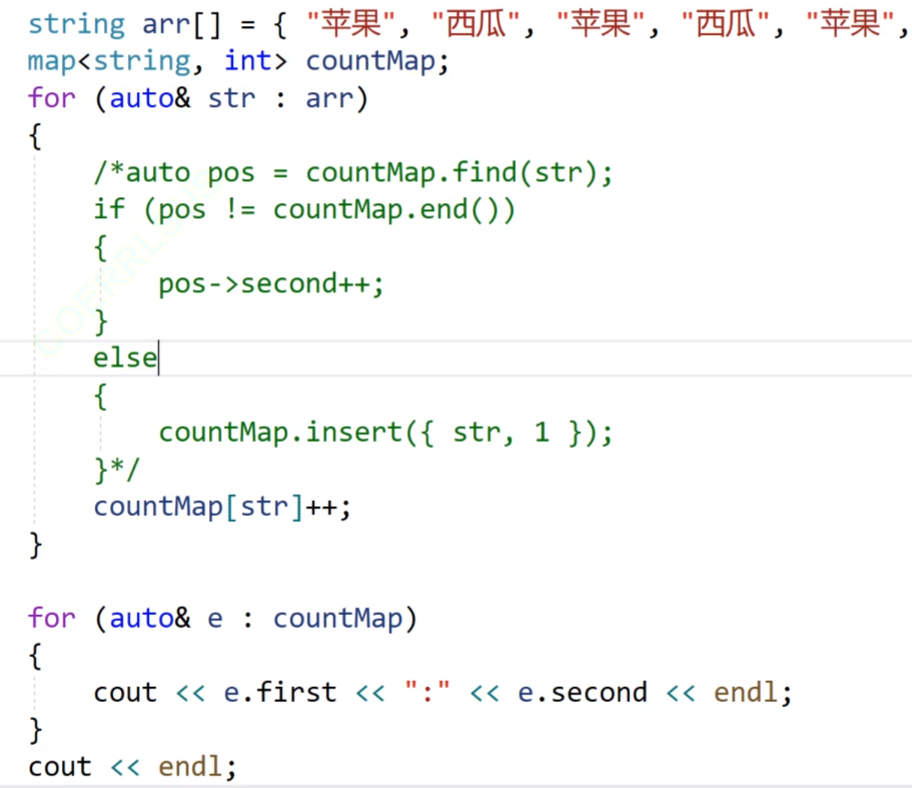
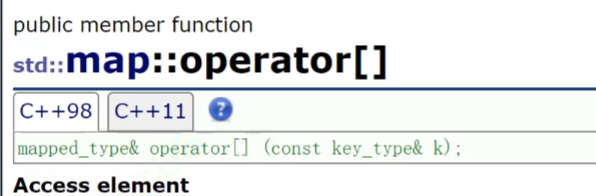
我们的map的方括号和我们的之前的方括号不一样,我们的map的方括号是给你一个key,让你返回对应的val的引用。(但是他还有一个隐藏的含义就是,当我们的key(第一个数据(维持红黑树的结构的数据))没有的时候,他会进行插入)。
就比如我们看上面的数据,当我们的苹果第一次出现的时候,我们的map里面是没有这个string的,我们的[]就会把他插入进去。
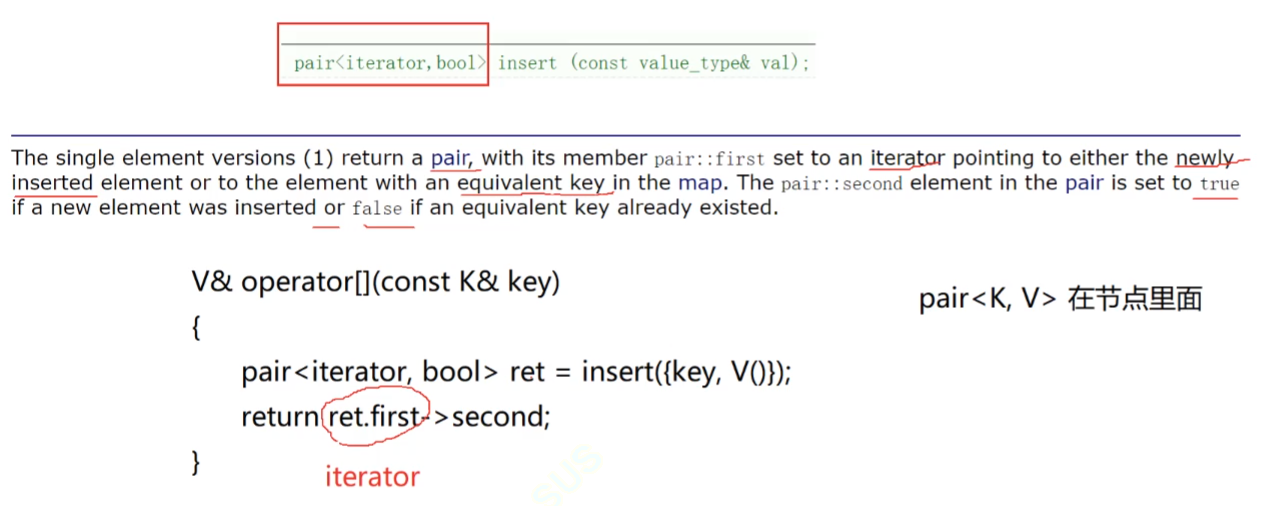
这个就是我们的[]的底层,是借助insert来实现的,我们的insert插入第一个数据,这个数据没有在我们的容器出现过的时候,我们的insert就可以把他插入,当下次我们的这个数据在我们的容器出现过的时候,我们的insert就不再进行插入,,我们的insert的返回值是pair<iterator,bool>类型的,当我们成功插入的时候,后面的bool就是true,这个数据已经有了,插入失败的时候,bool就是false,我们的pair的第一个迭代器返回的就是我们的插入的结点位置,如果没有插入,返回的就是我们的key这个数据的结点位置的迭代器。
我们的ret就是我们的insert返回的值,是pair类型的,然后这个结构使用 . 来得到我们的iterator(key结点位置的迭代器),再进行解引用得到val。
最后我们的返回值返回我们次数的引用。
补充:
我们在这里补充一点知识:

我们看这个图片:我们想把我们的vector的里面的数据拷贝给给我们的set,我们可以使用set迭代器来进行迭代器的区间的拷贝构造。

我们这里的迭代器区间不一定是自身容器的迭代器区间,我们的迭代器区间构造写的都是函数模板。我们这里的函数模板的优势就是,我们可以是自己类型的迭代器,也可以是其他类型的迭代器。只要你传过来的数据符合我们的要求就好。