软考-软件设计师中级备考 2、计算机系统组成、指令系统
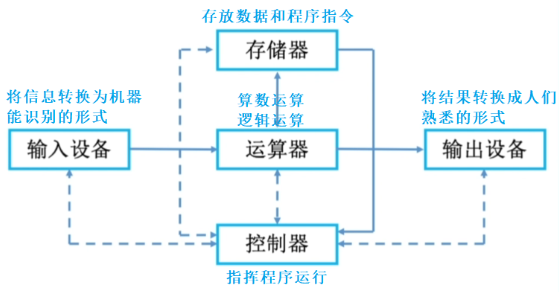
计算机的五大部件
1)输入设备:键盘、鼠标、扫描仪、摄像头、麦克风
2)输出设备:显示器、打印机、音箱
3)主存储器:就是内存,暂时存储计算机正在运行的程序和数据,与 CPU 直接进行数据交换,速度较快,但容量相对较小。
4)运算器:执行各种算术运算(5+3)和逻辑运算(5>3)的部件。
5)控制器:指挥中心,负责协调和控制计算机各部件的工作。
 |
1、主存储器(内存):关键点【存储字长】、【存储单元】
MAR(Address地址寄存器)、MDR(Data数据寄存器)是位于 CPU 中的寄存器,它们用来计算存储字长:
MAR=4位——》2*2*2*2个存储单元
MDR=16位——》存储字长为16(每个存储单元可以存放16bit)
区别于上一节的机器字长(我的电脑是64位操作系统,机器字长就是64)
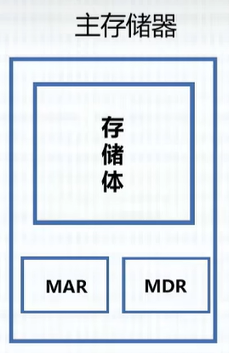 | 存储元(1bit)=>存储单元(1个存储字长)=>存储体 |
2、CPU-运算器:算术运算(加、减、乘、除等)、逻辑运算(与、或、非、异或等)、数据处理(对数据进行移位、比较等)
| ACC | Accumulator | 累加器 |
| MQ | Multiplier - Quotient Register | 乘商寄存器 |
| X | 通用数据寄存器,用于暂存数据 | |
| ALU | Arithmetic Logic Unit | 算术逻辑单元 |
| DR | Data Register | 数据寄存器 |
| PSW | Program Status Word | 程序状态字寄存器 |
3、CPU-控制器:
| PC | Program Counter | 程序计数器 | 取指令: 1)PC初始化为程序的第一条指令的地址, 2)CPU将其发送到AR 3) AR 从内存中读取指令,将其存入 IR 4)PC 自动加 1,指向下一条指令的地址 | 存储着下一条要执行指令的内存地址 |
| AR | Address Register | 地址寄存器 | 存放当前要访问的内存单元的地址 | |
| IR | Instruction Register | 指令寄存器 | 指令译码:IR 中的指令被送入 ID 进行译码,ID 分析出指令的操作码和操作数等信息,发送给 CU 执行指令:CU 根据 ID 译码得到的信息,生成相应的控制信号,控制计算机的各个部件进行相应的操作。 循环执行:一条指令执行完成后,CPU 会根据 PC 中的地址继续取下一条指令,重复上述取指令、指令译码和执行指令的过程,直到程序执行结束。 | 存放当前正在执行的指令 |
| ID | Instruction Decoder | 指令译码器 | 对指令寄存器中的指令进行译码 | |
| CU | Control Unit | 控制单元 | 根据 ID 译码得到的操作码和操作数,生成控制信号 |
以下是计算机执行 1 + 2 的整个指令过程,涉及到的运算器(ACC、MQ、X、ALU、DR)、程序状态字寄存器(PS)、程序计数器(WPC)以及控制器(AR、IR、ID、CU)的具体操作:
取指令阶段:
- 程序计数器(PC):首先,程序计数器(PC)中存放着当前要执行的指令的地址。假设该加法指令存放在内存的地址为 100H(这里只是假设的地址,实际可能不同),PC 的初始值为 100H。
- 地址寄存器(AR):PC 将指令地址 100H 传送给地址寄存器(AR),AR 用于保存要访问的内存单元的地址。
- 内存访问:控制器(CU)发出内存读命令,根据 AR 中的地址 100H,从内存中读取加法指令,并将指令传送到数据寄存器(DR)。
- 指令寄存器(IR):DR 将读取到的指令传送给指令寄存器(IR),IR 用于保存当前正在执行的指令。
- 指令译码(ID):指令译码器(ID)对 IR 中的指令进行译码,识别出这是一条加法指令,并确定操作数的来源和操作类型。
取操作数阶段:
- 假设操作数 1 和 2 分别存放在内存的地址 200H 和 201H 中。
- 地址寄存器(AR):根据指令译码的结果,CU 控制 AR 分别获取操作数 1 和 2 的地址 200H 和 201H。
- 内存访问:CU 发出内存读命令,分别从内存地址 200H 和 201H 读取操作数 1 和 2,并将它们传送到数据寄存器(DR)。
- 操作数暂存:假设运算器中有寄存器 X 用于暂存操作数,DR 将读取到的操作数依次传送给 X。
运算阶段:
- 累加器(ACC):假设累加器(ACC)初始值为 0(在实际运算前,ACC 可能保存上一条指令的结果等,这里为了简化假设为 0)。
- 运算器(ALU):ALU 从 ACC 和 X 中获取操作数(假设先将操作数 1 传送到 ACC,操作数 2 存放在 X 中),根据指令译码确定的加法操作,对两个操作数进行加法运算,即 1 + 2 。
- 结果保存:运算结果通过 ALU 传送到 ACC,此时 ACC 中的值变为 3。
状态标志更新:
程序状态字寄存器(PS):运算完成后,根据运算结果更新程序状态字寄存器(PS)中的标志位。例如,如果运算结果为 0,则零标志位(ZF)可能会被置位;如果运算结果产生溢出,则溢出标志位(OF)可能会被置位等。指令执行完成:
程序计数器更新:PC 自动加 1(假设每条指令占用一个内存单元),指向下一条要执行的指令的地址,为下一条指令的执行做好准备。
4、计算机体系结构(Flynn分类法)
I是 “Instruction Stream” 的缩写,即指令流;D是 “Data Stream”,即数据流。
S=>single M=>Multipule
| 单指令流单数据流(SISD) |
| 单指令流多数据流(SIMD) |
| 多指令流单数据流(MISD) |
| 多指令流多数据流(MIMD) |
5、指令是计算机运行的最小功能单位,一台计算机所有指令的集合就是指令系统
指令包括操作码(OP)字段和地址码(A)字段两部分组成。
| 操作码(OP) | 指明操作的类型 | 加法、减法、数据传送、跳转等 |
| 地址码(A) | 指明操作数及运算结果存放的地址 | 考点:七种寻址方式 |
1+2=3=》操作码涉及(+);地址码涉及(1、2、3)
6、七种寻址方式,记住这几个汇编语言的例子
| 立即寻址 | 操作数直接包含在指令中 | 在汇编语言中,指令 MOV AX, 1234H ,其中 1234H 就是立即数,直接将其传送到寄存器 AX 中 |
| 寄存器寻址 | 操作数存放在 CPU 的寄存器中,指令中指定寄存器的名称来访问操作数。 | 指令 MOV AX, BX ,将寄存器 BX 中的操作数传送到寄存器 AX 中。 |
| 直接寻址 | 指令中直接给出操作数的内存地址,CPU 根据该地址从内存中读取操作数。 | 指令 MOV AX, [1000H] ,表示将内存地址为 1000H 处的操作数传送到寄存器 AX 中 |
| 寄存器间接寻址 | 操作数的有效地址存放在寄存器中,指令中指定寄存器名称,CPU 通过该寄存器中的值来访问操作数。 | MOV AX, [BX],假设BX寄存器中存放的是1234H,那么 CPU 会到数据段中偏移地址为1234H的地方取操作数传送给AX。 |
| 寄存器相对寻址 | 操作数的有效地址是由一个基址寄存器(如BX、BP)或变址寄存器(如SI、DI)的内容加上指令中给定的位移量(8 位或 16 位)得到的。 | MOV AX, [BX + 10H],若BX的值为2000H,则操作数的有效地址为2000H + 10H = 2010H,CPU 会从数据段的2010H处取数据传送给AX。 |
| 基址加变址寻址 | 操作数的有效地址是由一个基址寄存器(如BX、BP)的内容加上一个变址寄存器(如SI、DI)的内容得到的。 | MOV AX, [BX + SI],如果BX = 3000H,SI = 200H,那么有效地址为3000H + 200H = 3200H,CPU 从数据段的3200H处取数据送AX。 |
| 相对基址加变址寻址 | 操作数的有效地址是由一个基址寄存器、一个变址寄存器的内容再加上指令中给定的位移量共同确定的。 | MOV AX, [BX + SI + 10H],若BX = 4000H,SI = 300H,则有效地址为4000H + 300H + 10H = 4310H,CPU 将从数据段的4310H处取数据传送给AX。 |
7、CISC vs RISC
| 对比项目 | CISC(复杂指令集计算机) | RISC(精简指令集计算机) |
|---|---|---|
| 指令集特点 | 指令数量多,功能复杂,指令长度可变,包含能完成复杂操作的指令 | 指令数量少,功能简单,指令长度固定,以基本算术、逻辑运算和数据传输指令为主 |
| 硬件设计 | 硬件复杂,需要更多晶体管实现指令解码和执行单元,指令译码电路复杂 | 硬件相对简单,指令格式统一,译码容易,适合流水线技术,执行单元设计更优化 |
| 执行效率 | 对于复杂任务,一条指令可完成多个步骤,能减少指令条数,但执行每条指令时钟周期数多,不利于流水线优化 | 指令简单,执行时间短,通常一个时钟周期完成一条指令,通过流水线技术可提高整体执行速度 |
| 编译器设计 | 编译器设计复杂,需处理多种指令类型和格式,优化难度大 | 编译器设计相对简单,指令集规整,易于生成高效代码,便于进行指令优化 |
8、指令控制方式有顺序方式、重叠方式、流水方式三种
| 指令控制方式 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 顺序方式 | 按指令在内存中的存放顺序依次执行,上一条指令执行完毕后才开始执行下一条指令,各指令串行执行 | 控制简单,硬件设计相对容易;每条指令执行完后系统状态清晰,易于故障诊断和处理 | 执行效率较低,处理器和其他硬件资源利用率不高,任何时刻 CPU 只能执行一条指令 |
| 重叠方式 | 让当前指令的执行阶段与下一条指令的取指阶段在时间上重叠,即在执行本条指令时提前取出下一条指令 | 相比顺序方式,能提高 CPU 的利用率和指令执行速度,减少指令执行的空闲时间 | 需增加硬件实现指令重叠执行,硬件设计相对复杂;可能出现数据相关等问题,若不妥善处理会影响指令执行正确性 |
| 流水方式 | 将指令执行过程分解为多个阶段(如取指、译码、执行、访存、写回等),每个阶段由专门硬件部件完成,不同指令的不同阶段可并行执行 | 能显著提高计算机运算速度和硬件资源利用率,理想情况下可让指令连续不断执行,单位时间内处理指令数量大幅增加 | 硬件实现复杂,需大量硬件资源支持流水线各阶段;对指令执行顺序和数据相关性要求严格,出现数据冲突、转移指令等情况可能导致流水线停顿或断流,需复杂的流水线控制技术解决问题 |
9、流水线的计算
一条指令分为取址Δt_1、执行Δt_2、分析Δt_3三部分
1)顺序执行时间
T_顺序 = n * (Δt_1 + Δt_2 + … + Δt_k)
2) 流水线执行时间 一次完整+(n-1)*流水线周期,流水线周期=max(Δt_1, Δt_2,Δt_3)
T_流水 = (Δt_1 + Δt_2 + … + Δt_k) + (n - 1) * max(Δt_1, Δt_2, …, Δt_k)
例题:某指令流水线由4段组成,如下图,求连续输出8条指令的吞吐率(指令条数/流水线执行时间)
——>Δt——>2Δt——>3Δt——>Δt——>
解:首先计算流水线时间 (1+2+3+1)+7*3 = 28=>吞吐率为8/28Δt
10、CPU 与外设之间的数据传送方式,关键词【中断】
| 传送方式 | 特点 | 适用场景 |
|---|---|---|
| 直接程序控制方式 | CPU 直接通过程序指令控制数据传送,在数据传送过程中,CPU 要不断地查询外设状态,直到外设准备好数据或接收完数据为止。这种方式硬件简单,但 CPU 利用率低,数据传送速度慢。 | 适用于外设数量少、数据传输量小且对实时性要求不高的场合,如简单的键盘输入、LED 显示等。 |
| 中断方式 | 当外设准备好数据或可以接收数据时,向 CPU 发送中断请求,CPU 暂停当前正在执行的程序,转去处理与外设的数据传送,处理完后再返回原来的程序继续执行。这种方式提高了 CPU 的利用率,能实时响应外设请求,但中断处理需要一定的时间开销。 | 适用于数据传输量不大,但要求 CPU 能及时响应外设请求的场合,如打印机打印数据、鼠标键盘输入等。 |
| 直接存储器存取方式(DMA) | 外设与内存之间直接进行数据传送,不需要 CPU 的干预,数据传送由 DMA 控制器(DMAC)来控制。这种方式数据传送速度快,大大提高了系统的性能,但硬件电路相对复杂。 | 适用于高速外设与内存之间大量数据的快速传送,如硬盘与内存之间的数据读写、图像数据的传输等。 |
| 输入 / 输出处理机(IOP) | IOP 是一个独立于 CPU 的专门处理输入输出的部件,它有自己的指令系统和存储器,可以独立地执行程序来完成数据的输入输出操作。这种方式使 CPU 从繁杂的输入输出事务中解脱出来,提高了整个系统的并行性和效率,但硬件成本较高。 | 适用于大型计算机系统或对输入输出处理能力要求较高的系统,如服务器系统、大型数据处理中心等。 |