计算机视觉算法 segment anything 论文解读
文章目录
- 前言
- 核心观点
- 什么样的任务
- 用了什么模型框架?
- 避免模糊输出
- 训练方法
- 如何获得数据集?
- 总结
前言
segment anything 可以说是声名在外了,之前看遥感领域文章的时候好几篇高引文章都是结合sam完成的。
但是今天读了sam的论文后,唯一的感觉就是文章好晦涩。
我思考了之后,总结出一下几个原因:
- sam提出了一种新的任务,为了解释这个新的任务很重要,篇幅大量往这里倾斜,其他部分的内容就少了。
- 新的任务肯定要新的模型,新的模型里的很多部分的组件抉择我感觉是可以大写特写的,结果只是提了一嘴用了啥,为啥用这个不用那个完全没讲。
- 这么多要讲的东西,论文的消融实验却消失了。整整30页的论文,消融实验只有半页。最让我难绷的是论文里关于模型偏见的部分都有一页。
其实文章没我说的那么不堪,但是也确实无法让人眼前一亮,尤其是看过depth anything的论文后。
核心观点
论文作者开篇就讨论了为什么要提出一个新的模型。
nlp领域的language model是一个很好的模型,因为它能够利用大量的语料进行训练,训练成功只需要少量的prompt就可以应用于下游任务了。
clip也是一个很好的模型,可以利用大量图像文本对进行预训练,很容易就应用到下游。因为有图像和文本的编码部分,所以也算可以利用文字prompt。
但是还有很多cv领域的任务是不能从clip这种encoder中收益的。(虽然但是个人感觉语义分割应该是可以从clip中收益的吧?我感觉这里有点为了讲故事而讲故事了)
所以作者提出要构建一个图像分割领域的fundation model,这个model满足两个条件:
1.在大规模数据上进行预训练
(其实这个条件的目的就是第二个条件。大规模预训练=良好泛化性=zero shot能力)
2.可以通过prompt运用到很多下游任务。
作者接下来的大量篇幅是围绕着训练出具有这种性质的模型所需要的三要素来讲的,也就是:
1.什么样的任务能训练出泛化性强的模型?
2.什么样的模型架构能支撑完成1提出的任务?
3.怎么样收集大量且广泛的数据?
如果说具体的细节是战术的话,这三个要素就是战略了。
我虽然前面吐槽了很多关于模型细节相关部分的缺失,但是,作者能够提出一种新的体系,并且实操效果很好,我还是很佩服的。
什么样的任务
什么样的任务可以训练出泛化性强的模型?
其实就是 利用prompt产生分割掩码。
在图像分割领域的prompt是什么?
作者认为应该是多种形式的,包括文本、点、方框、图像掩码。
我觉得这是考虑到了图像处理领域的几个任务的常见输出:图像文本匹配、目标检测、语义分割。直接将prompt的形式和下游任务匹配了,那肯定可以很好的适应下游任务。
为什么说如果模型可以利用prompt产生分割掩码就有很好的泛化性呢?
这是因为sam加上其他的cv组件(提供prompt),就可以完成很大一部分的图像分割任务。
作者在这里格外强调,这不是说我们提前在多任务上进行训练得来的能力,而是我们对多种样式的prompt的兼容能力所带来的能力。
用了什么模型框架?
关于模型的宏观框架可以用下面的一幅图理解。
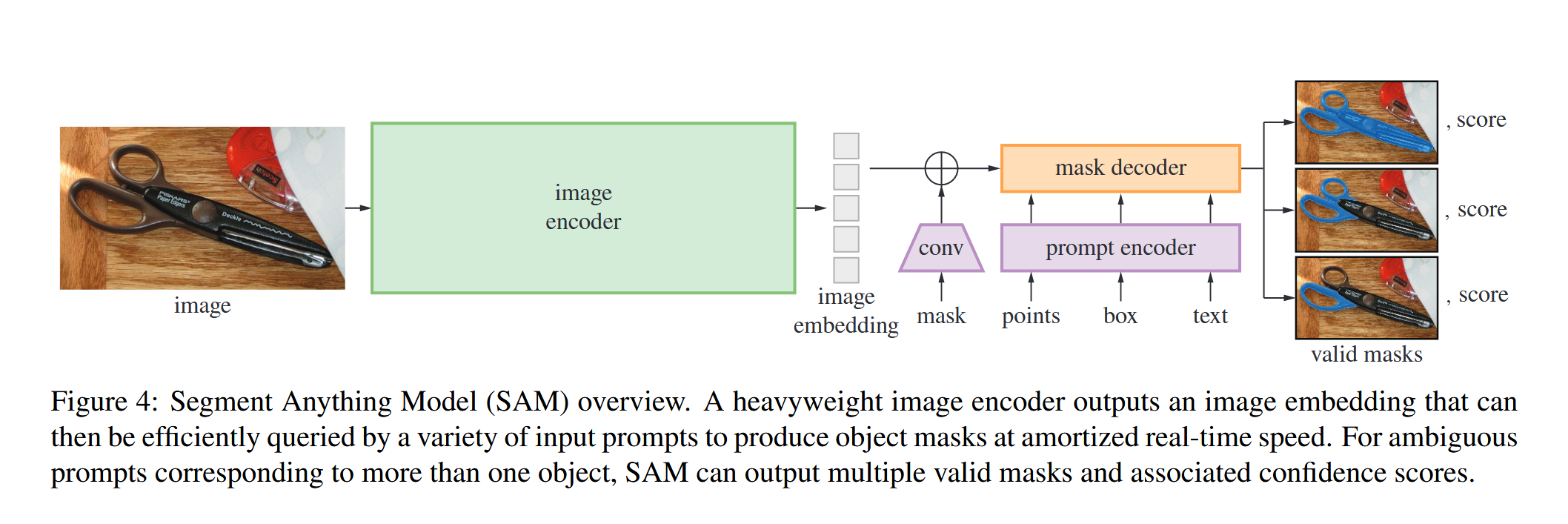
总的来说可以分为三部分:图像编码器,提示编码器,掩码解码器。
原始的图像输入到一个encoder中输出tokens作为image embedding。
这个image embedding只会生成一次,这也是这篇工作的卖点之一,给定图片,用计算量大的encoder生成一次特征图,之后不同的prompt都是作用于这个特征图上的。
关于这个encoder的选择,作者使用了windowed attetion和global attention的结合:大部分attention layer使用windowed attention,中间选几个layer使用global attention。
可能有人不太清楚什么是windowed attention,其实就是根据图片的原始二维顺序排列token,然后把相邻的token划分为一个window(不重合),之后的注意力计算,只在window内部进行。
这个image encoder的选择是mae预训练的vit,其实我挺好奇为什么没有用dino预训练的,但是作者也没有在为什么选mae多费笔墨。
之后的prompt分为两个类别:稠密型和稀疏型。
稠密型就一个,那就是掩码mask,直接进行下采样后元素加到特征图上就行了。
唯一值得注意的就是对于不提供掩码prompt的情况,模型还要在每一个特征token上加一个特殊的代表“没有掩码”的embedding。
有一说一,我暂时没理解这样做的必要。
稀疏型就有很多了,点、框、文本都是。具体来说稀疏型的prompt是先嵌入变换为token,而后和图像的特征图(tokens)之间进行交叉注意力。
但是这个将prompt变为token的操作其实是很dirty,也就是很繁琐的。我们仔细讲讲。
先来说点。
点的输入包括一个二维的坐标,还有前景/后景的表示。
所以在将点变为token的时候,需要将点的位置嵌入(也就是将二维坐标对应到一个token)加上前景/后景的嵌入表示。
再来说框。
框一般来说由两个二维坐标决定,这里是左上角坐标和右上角坐标,所以是变成了两个token。
对于每一个token都是位置嵌入加上坐上/右上的嵌入表示。
关于文本我就不谈了,论文我没看懂,代码里没这部分,感兴趣的读者可以阅读原文。
大家这里需要注意的是这些点、框都是可以出现很多的,也就是说可以很多点和很多框共同作为prompt。这是由maskdecoder的形式所决定的。
但是,能不能有很好的表现就是两说了。
大家会发现对于不同的prompt需要不同的、提前训练好的embedding,我觉得这是很别扭的一点。
这让整个框架变得复杂不易理解。
但是实话实说,我也想不出来有更好的办法兼容这么多的prompt。
也许统一的位置编码加上单独的嵌入表示就是最通用的方法了。
至于mask decoder,就是接受特征图以及prompt,输出mask了。
不得不说的是mask decoder 的组成十分的复杂。
具体的操作可以看下面这张图。
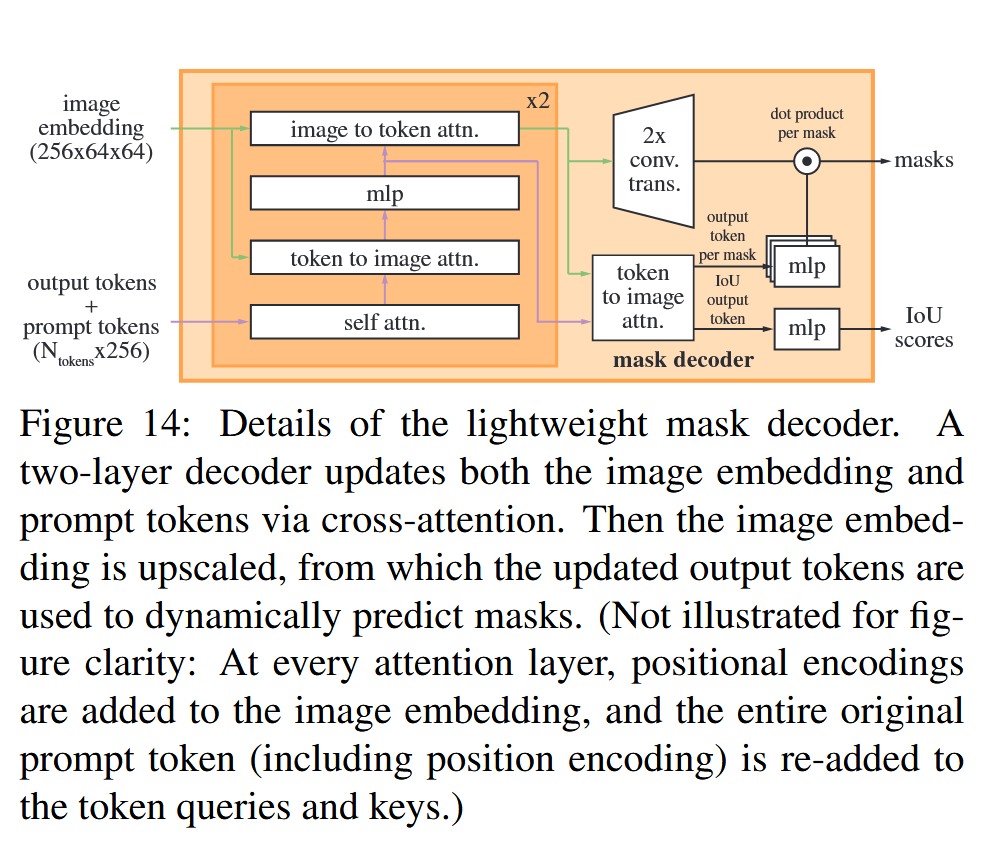
模型结构的复杂一般都是研究者所极力避免的,因为这会增加别人理解你工作的成本,因此在你的基础上做工作的人就少了。
但是关于sam的复杂的decoder我倒是可以理解,就像作者在论文中不断提到的,更快的响应速度。
接下来我们来说具体的decoder结构。
首先就是在prompt tokens concat 上output token。这个output token是在训练过程中学习到的。所以,对的,又是一个特殊的embedding。(简化版,后面会提到作者为了避免模糊输出特意设计了)
注意:接下来我们会将prompt tokens concat 上output token 称为 prompt tokens。
之后就是一个经典的transformer 的decoder结构(注意,这里的decoder不是mask decoder的decoder),但是与transformer中的decoder不同的是,sam在一个attention layer之后会将图像特征作为query和prompt进行交叉注意力计算。
这是很符合直觉的,我们最后要输出的是一个完整尺寸的掩码,而不是一个token。
所以不能仅仅用prompt token 作为query查询图像特征(这里可能有点绕,简单理解就是在计算交叉注意力的时候,更新的是query的值)
这里还有很多小的trick。
例如说图像的特征在每一次更新前(其实也就是作为query)会加上位置编码,说是为了加强图像的集合特征。
(所以消融实验呢?起码提一句做了消融实验结果证明这样更好)
还有在prompt tokens 的每一次更新之后都会加上最原始的prompt tokens。
在经过transformer的decoder后,图像的特征进行上采样,分辨率乘了4,所以分辨率还是原图对的1/4。(我不明白为什么不直接恢复原图分辨率)
而prompt tokens 也还有用处,经过mlp后对图像特征进行矩阵乘法。
在最后对图像特征进行上采样,分辨率恢复了原始分辨率
避免模糊输出
有些读者可能已经注意到了,这个图中的output tokens 怎么是复数啊?有很多output tokens 吗?
以及这个iou score是什么东西?
这其实都是作者为了避免模糊输出所做出的特殊模型框架设计。
作者在这里提到了说是模型一定要有鲁棒性,无论是多模糊的prompt,至少要输出一个合理的图像分割的掩码。
对应到llm就是无论你输入什么,模型总会输出一个token。
注意,这是很重要的一点,值得我们细细分析。
为什么图像分割会输出一个不合理的掩码呢?
这是由图像分割本身的模糊性决定的,也就是说对于一个prompt可以给出不同的掩码。
如下图所示。

这是个很好的性质,保持了模型输出的多样性。
但是,这会给分割模型的训练带来麻烦。
比如用鸵鸟的头上的点作为prompt进行推理,训练集里包含了三种不同的掩码,这是我们期望的。
但是对于模型来说一会让我输出这个掩码,一会让我输出那个掩码,我怎么知道要输出哪个掩码?于是模型就平均了一下,输入两个掩码的中间掩码。
这太糟糕了,你输出哪个都行,但不能输出平均后的结果啊!
有人可能会问,模型为什么会平均,就不能单独增加每个输出的概率吗?
当然可以,但是这对模型的输出的分布提出了很高的要求,这要求模型能够建模这种离散的输出分布。
模型能够建模离散的输出分布吗?
当然可以。
mlp模型的输出分布天然就是离散的。
也就是说如果你的模型不带有特殊的结构(输出概率然后取样、输出均值然后取样),那么本来就不会遇到被平均的问题。
但是这种稠密预测的问题损失函数就是每个像素的交叉熵,
模型输出的是像素是掩码的概率。所以就会有问题。
插一句题外话,其实伯克利大学的强化学习的课程就谈到过这个问题,课程中举的例子是模仿学习。
对于相同的状态,expert会做出不同的动作(前面有棵树,我可能从左边绕过去,也可能从右边绕过去)

模型的输出是动作的均值的话,就无法建模离散的输出分布,最后学到的分布就是平均后的走中间。
说回图像分割任务。 在图像分割任务中也是一样的,模型输出的是每个像素是掩码的概率。 对于相同的输入,不同的训练集有不同的输出, 也就是说存在很多这样的像素,有的样本认为他应该是掩码,把他概率往上拉,有的样本认为他不应该是掩码,将他概率往下拉,最终概率在0.5上下了。 那么实际应用是会出现的情况就是有很多的掩码噪点,是完全不规律的分布的。 这就是作者想要避免的现象。
那么作者想要怎么避免呢?
这就不得不提到作者特殊的模型设计了。
泛泛的说就是sam每次都会输出三个不同的掩码,训练的时候会选择损失函数最小的那个掩码进行梯度回传。这样就可以让模型的输出分布是三个离散分布的叠加。
这是作者经验之谈,认为三个离散的分布就足够建模输出分布了,其实这充满了手工设计的意味,不是很优雅。
那么推理的时候怎么选择选择使用哪个掩码呢?
作者又做了一个特殊的设计,模型训练的时候同时训练一个iou预测器,推理的时候看一下哪个掩码对应的iou最大,就输出对应的掩码。
别急,作者还有特殊操作。
sam是可以同时接受多个prompt的,作者认为多个prompt的情况下模型的输出会收敛到一种情况,所以当有多个prompt的时候,作者专门设计了第四个掩码用来输出。
所以我们具体到代码上就是prompt tokens concat上的output tokens实际上是四个,并且还要concat上一个iou token。这些都是需要学习的嵌入。
所以我觉得很神奇的一点是,框架中有如此多的嵌入,模型还能很好的训练。
训练方法
了解了sam中各种各样的prompt,以及十分特殊的模型结构,我相信大部分人都会有一个疑惑,这东西要怎么训练?或者说要怎么训练才能稳定?
作者的方法也是十分的特殊,但是我看完之后的感觉是这样做很合理。
我们把sam训练的一个最小单位称为一个iteration,一个迭代。
在一个迭代中,我们只处理一个mask掩码。
(注意,一个掩码不等于一个样本。严格来说有很多的样本的掩码是一样的,但是prompt不同)
首先我们会以相同的概率选择点/框。
(这里有个很值得关注的点,那就是在初始的数据集里是没有点/框的,所以这一步中的点是随机在标注mask中选择,作为前景点。
而框则是对于掩码的bbox加上一些小扰动)
然后我们用这个点/框作为prompt进行推理。接下来就像我们在避免模糊输出中所说的,我们会用三个掩码中损失函数最小的掩码进行梯度回传,并且对对应iou的损失进行梯度回传。
之后我们用这个预测的掩码作为下一次的prompt,并且加上一个额外的点/框的prompt,进行下一次训练。
额外的框很简单,就是上一次预测掩码的bbox加上扰动。
这个额外的点是怎么产生的?
是在预测掩码和标注掩码的error 区域随机采样的。
根据错误的类别(fp/fn)分别标注为后景/前景。
就这样不断进行,作者发现一个掩码迭代8次以内都可以有效产生梯度。
当然了,作者还在中间以及结尾各参杂了一次只给上一次预测的掩码作为prompt的训练。
关于具体的损失函数。作者在掩码预测这一方面使用了focal loss 以及 dice loss 的结合。
focal loss 是交叉熵的改进,更加关注预测与实际偏差较大的损失占比(虽然交叉熵本身就有这样的功能),具体的表达式如下。
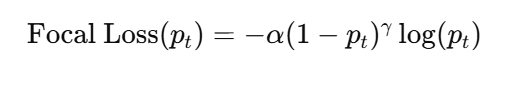
dice loss 则就是f1-score,均衡了召回率以及精确率。
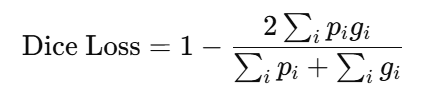
如何获得数据集?
论文的很大一部分篇幅是在说作者新构建的这个数据集SA-1B。
数据集的构建过程其实很简单,就是利用sam辅助生成掩码(这得益于mask decoder的轻量化,只要提前计算好图像的特征图,那么模型完全可以几乎实时的响应标注员,根据标注员给出的点prompt生成mask),利用生成掩码训练sam,不断重复。
整个过程可以分为三个阶段。
第一个阶段主要是人工标注。因为一开始的sam能力很弱(训练数据少),所以生成的掩码和真实的掩码有很大的差距,需要标注员手动修改。
随着第一阶段的进行,sam能力越来越强,标注员修改用时也越来越少。
值得注意的是,这一阶段标注员标注的对象是最主要的部分,并没有太考虑掩码的多样性。
第二阶段主要仍然是人工标注主导。
其实经过第一阶段的反复标注、训练,sam的能力已经很强大了,但是为了模型有更强的泛化性,标注员被要求根据已有的覆盖了掩码的图像,标注别处的掩码。所以这一阶段的耗时是很大的,因为需要标注人员更多的思考如何标注。
第三阶段就是图像掩码的自动生成了,这个过程并没有人类标注员的参与。
具体来说就是将一张图片切分成32x32个patch,每个patch的中心点作为prompt让sam生成掩码。
就像我们前面所说的,我们选择iou输出最大的掩码,并且要求掩码阈值在0.5上下变动时,掩码区域不能有大变化。
在这一步的基础上作者还将模型先划分为有重叠区域的2x2的大patch,然后在每个大patch中间划分出比一开始更细粒度的spatch,在每个大patch内部进行上面同样操作,同时要求掩码不能触及边界,这是为了样本的完整性。
然后是有重叠区域的4x4的大patch,大patch内部的patch粒度更细,操作类似。
最后,我们对于所有掩码进行一次nms。
第三阶段的样本数量占了整个SA-AB的99%。
这一部分其实我没看懂,欢迎高手在评论区讨论。
作者唯一做的消融实验就是关于数据集的,具体的可以看下图。
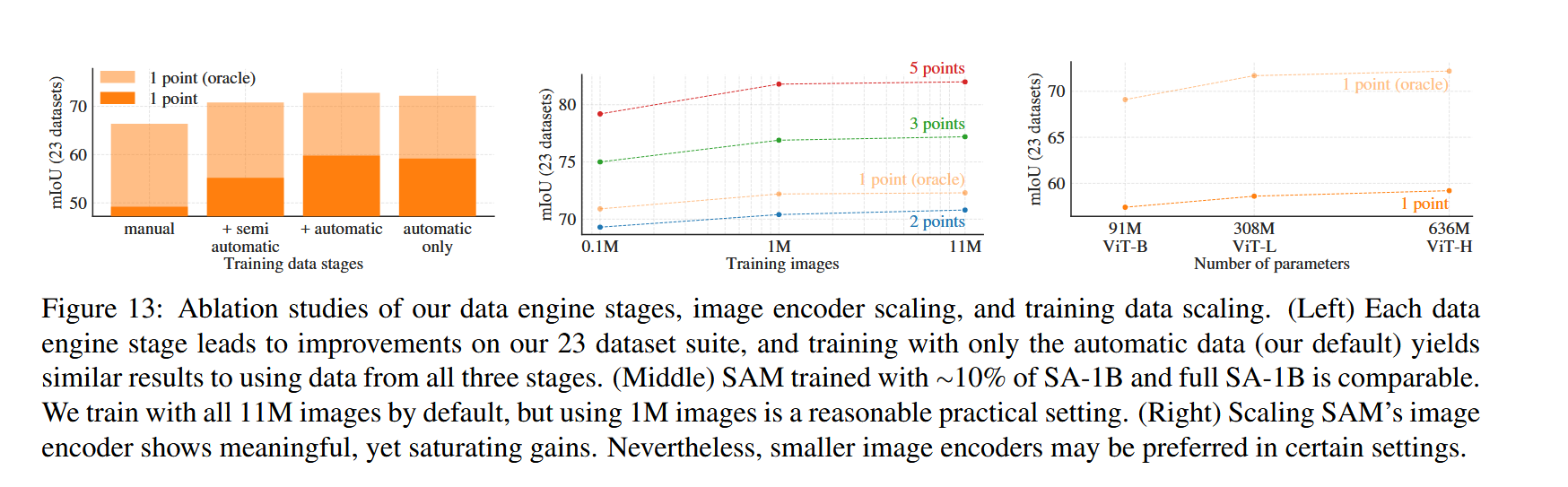
左边是三个阶段迭代数据集对于模型能力的提升效果。很明显的是哪怕第三个阶段的数据是模型自己产生的,但是一系列的后处理,加上更多的数据意味着更强的泛化性,模型的性能还是显著的提升了。
中间的图是模型性能关于数据规模的scaling law,右边的图是模型性能关于模型大小的scaling law。
其实结果都不太乐观吧,我个人感觉sam的结构太过于特殊了,decoder和prompt encoder 太小了,限制了性能的进一步提升。
总结
sam的论文和代码都不太好理解,一部分原因是我没接触过这个领域,还有一部分原因是这整个框架都是极其客制化的,增加了读者的理解成本。
我个人的看法,真正的有潜力的任务/模型 一定是可以充分运用更多的计算资源,更多的数据的。
最后在吐槽一下,论文编排真是不够好,看的头晕。