2024-11-14,由首尔国立大学创建的DAHL数据集,为评估大型语言模型(LLMs)在生物医学领域长文本生成中的幻觉问题提供了一个重要的工具,这对于提高模型的准确性和可靠性具有重要意义。
数据集地址:DAHL|生物医学数据集|模型评估数据集
一、研究背景:
随着大型语言模型(LLMs)在自然语言理解和生成领域的迅速发展,它们在生物医学、法律和金融等专业领域的应用日益增多。然而,这些模型在生成文本时可能会出现“幻觉”现象,即生成包含不准确或有偏见信息的响应,这在对事实精确度要求极高的领域中尤其危险。
目前遇到困难和挑战:
1、幻觉问题:LLMs生成的幻觉响应可能导致虚假信息的传播,引发伦理问题和严重后果。
2、专业领域挑战:在生物医学等领域,对事实精确度的要求极高,幻觉问题的风险更大。
3、评估和缓解方法:现有的评估方法多依赖于多项选择题任务或人工标注,成本高且耗时。
数据集地址:DAHL|生物医学数据集|模型评估数据集
二、让我们一起来看一下DAHL数据集
DAHL是一个专为评估生物医学领域LLMs长文本生成中幻觉问题而设计的基准数据集和自动化评估系统。
DAHL数据集包含8573个问题,涵盖29个类别,基于PubMed Central(PMC)的生物医学研究论文精心策划而成。该数据集通过将LLMs的响应分解为代表单个信息单元的原子单位,计算这些原子单位的平均事实准确性,从而产生DAHL分数。
数据集构建:
涉及从PMC中选取研究论文,生成可能的考试问题,并通过过滤过程保留可以独立回答的问题。
数据集特点:
1、覆盖广泛的生物医学领域,包含多个类别。
2、自动化的数据集构建过程,易于扩展到其他领域。
3、通过原子单位级别的事实精确度评估,提供更深入的幻觉评估。
DAHL数据集可以用于评估LLMs在生物医学领域长文本生成中的事实准确性,通过计算响应中原子单位的平均事实准确性来得出DAHL分数。
基准测试 :
通过与不同模型的实验,发现较大的模型倾向于较少的幻觉,但超过70-80亿参数的模型规模,进一步扩展并不显著提高事实准确性。
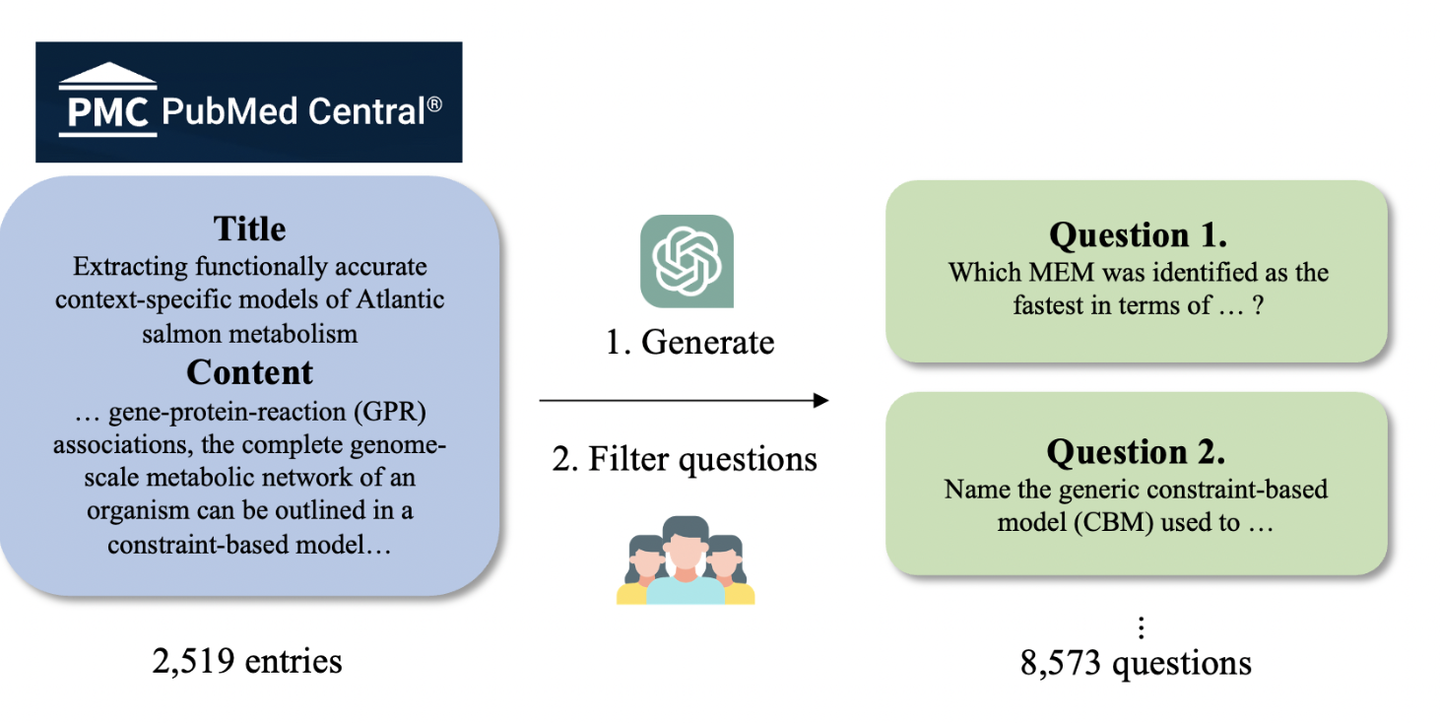
DAHL 基准数据集构建过程。
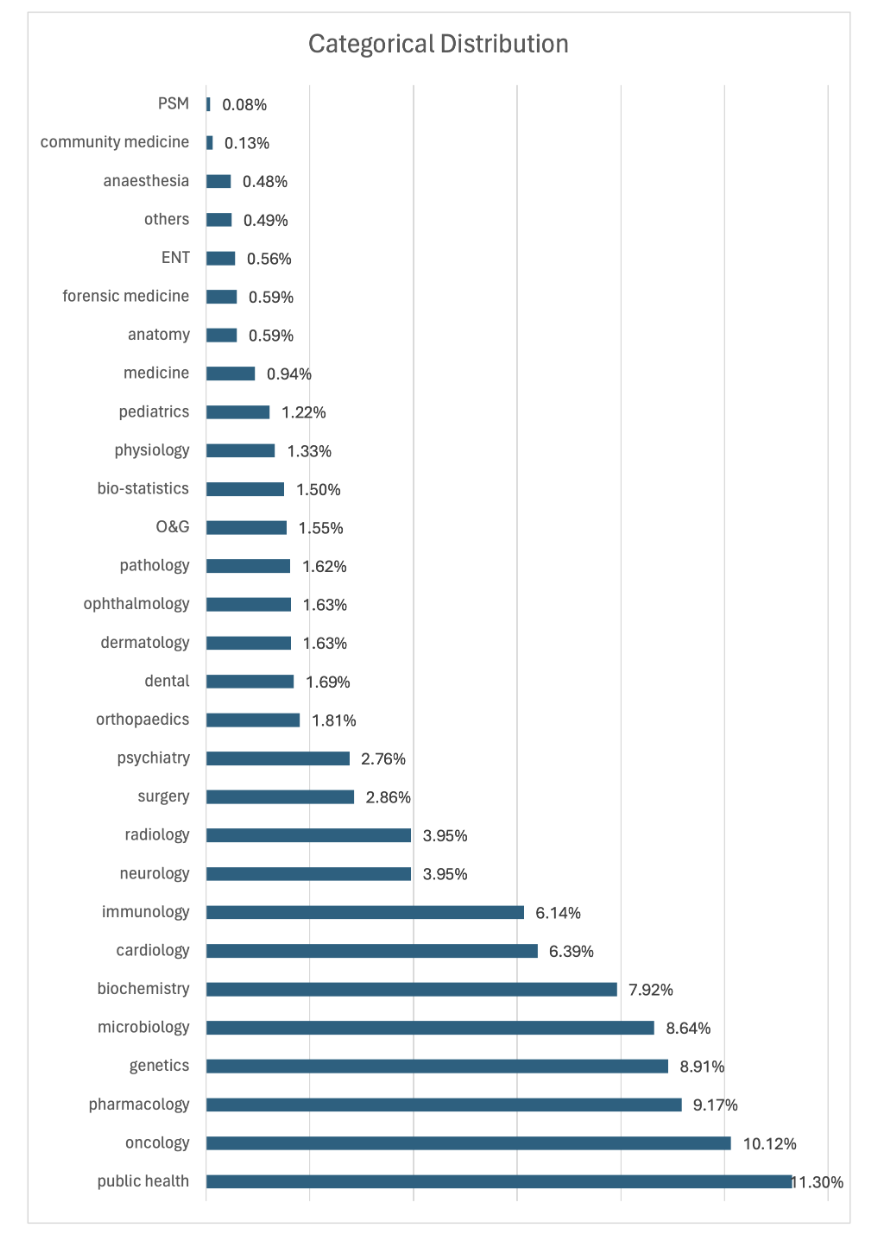
DAHL 基准数据集的分类分布。

自动幻觉评估管道。
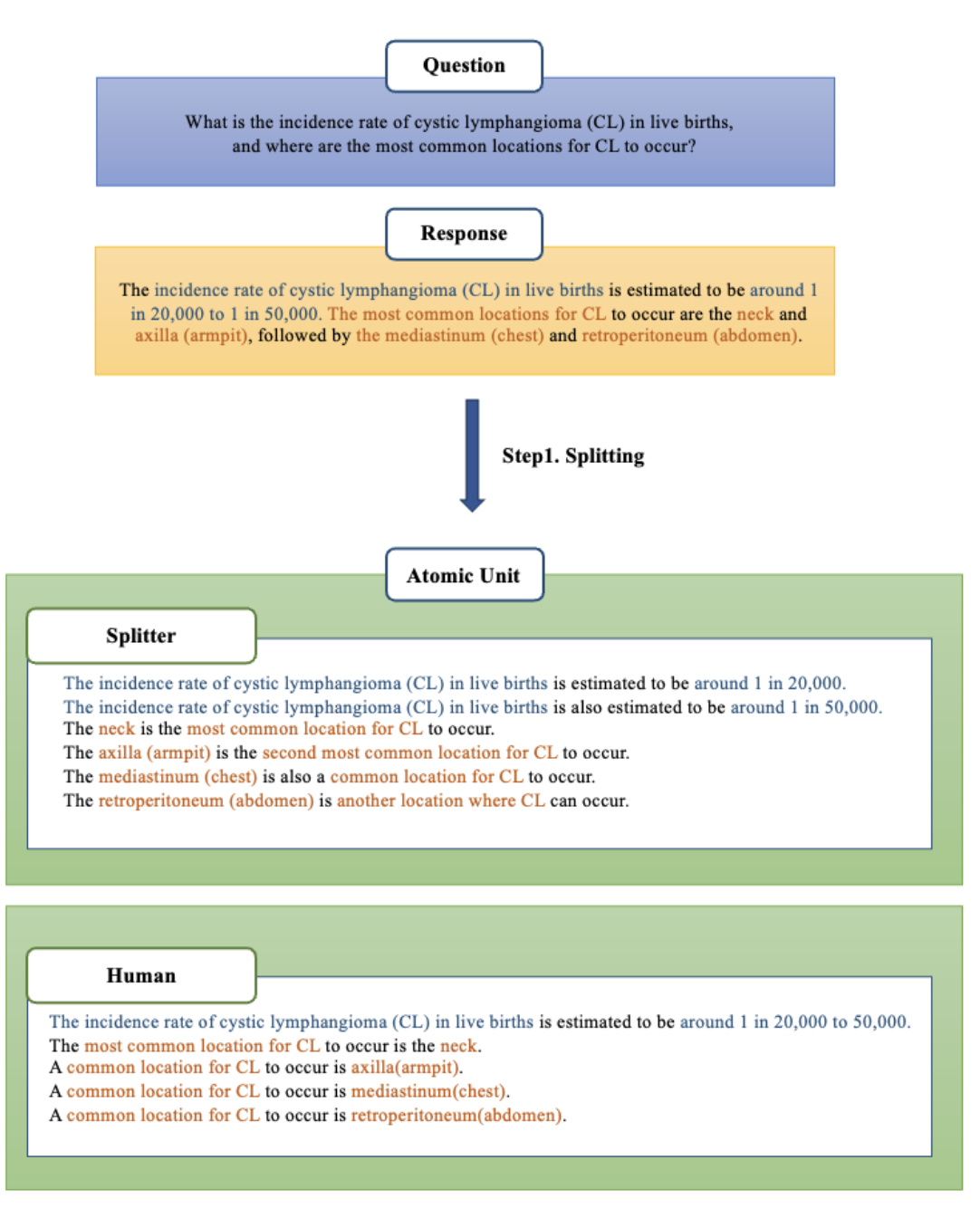
生成的响应及其两个版本的细分单元示例,一个来自 Splitter 模型,另一个来自人工注释。Splitter 通过将响应拆分为包含有关实体的一条信息或信息之间关系的单元来实现全面评估。
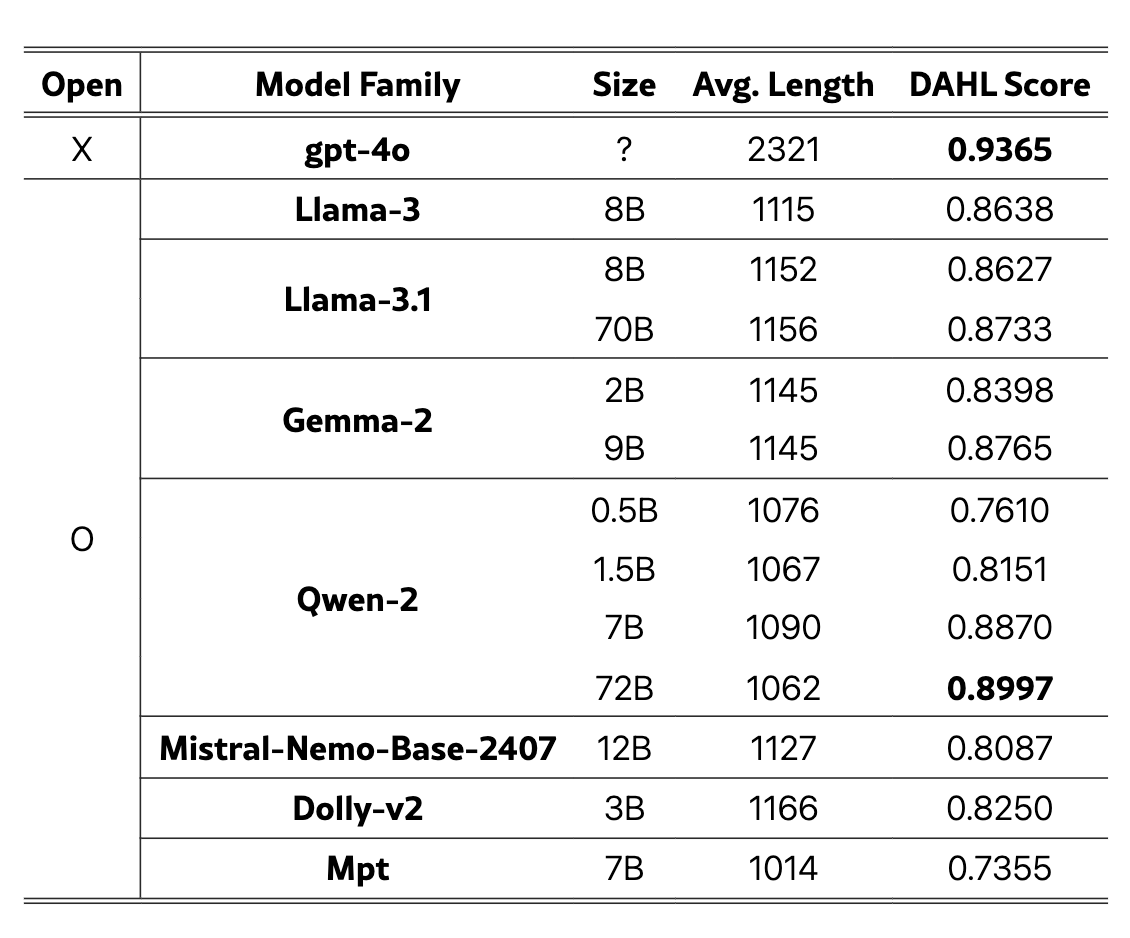
DAHL 分数和每个测试模型生成的响应(字符串)的平均长度。Gpt-4o 的表现优于所有,其次是 Qwen-2、Gemma-2、Llama-3、Llama-3.1、Dolly-v2、Mistral-Nemo-Base-2407 和 MPT。Qwen-2 的 DAHL 分数为 72B 参数,开源模型中得分最高的模型,以及 gpt-4o 的分数,标记为粗体。
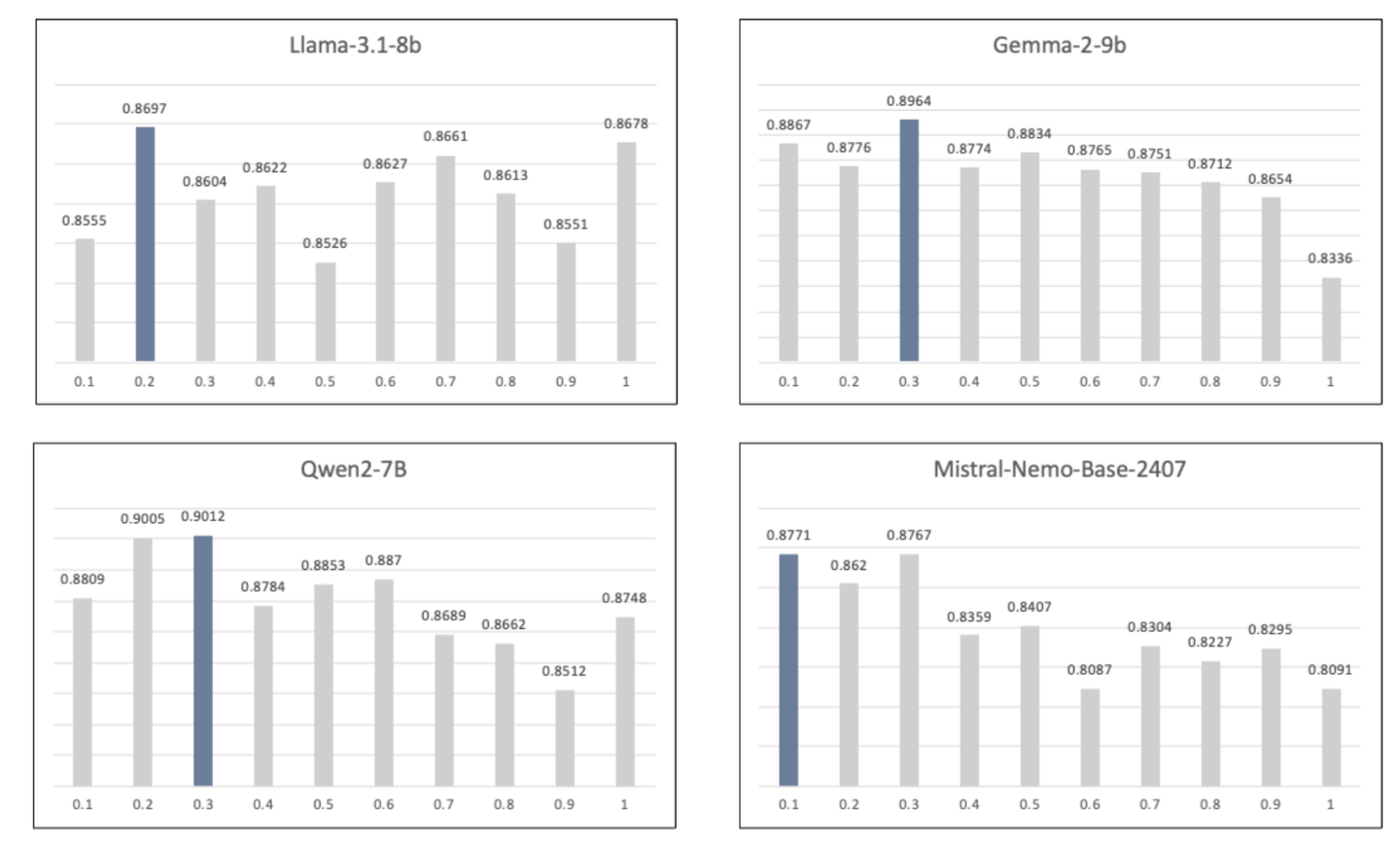
在 0.1 到 1.0 的温度范围内评估了 Llama-3.1-8b、Gemma-2-9b、Qwen-2-8b 和 Mistral-Nemo-Base-2407(120 亿个参数)的 DAHL 评分。每个模型的最佳温度在 0.1 到 0.3 的范围内,随着温度的升高,DAHL 分数略有线性下降。
三、让我们一起展望DAHL数据集的应用场景:
比如,我是一名医生。
我每天的工作之一就是撰写临床报告。这通常是一个既耗时又需要高度集中精力的任务。
今天一个刚做完心脏手术的病人,我需要查看手术记录、病理报告和术后监测数据。然后,我需要将这些信息整合成一份报告,描述手术过程、发现的问题以及术后的恢复情况。这个过程可能会花费他几个小时,因为我需要确保报告中的每一个细节都是准确无误的。
现在有来DAHL数据集训练的智能系统
智能系统能够自动从电子健康记录中提取病人的所有相关信息,并开始生成初步的临床报告。
1、数据提取:
智能系统首先从电子健康记录中提取病人的医疗信息,包括手术记录、病理报告和术后监测数据。
2、报告生成:
智能系统利用DAHL数据集训练出的模型,将这些信息整合成一份初步的临床报告。这个过程中,系统会确保报告中的每一个信息单元都是准确无误的。
3、事实验证:
智能系统会使用DAHL评分系统对报告中的每个信息单元进行事实验证,确保报告的准确性。比如,系统会检查“病人的心脏瓣膜修复手术成功”这一信息是否与手术记录相符。
4、报告优化:
经过事实验证后,系统会将验证无误的信息单元重新整合成一份完整的临床报告,并对其进行优化,使其更加清晰易懂。
最后,我会收到这份由智能系统生成的报告,并进行快速审核。通过智能系统,我撰写临床报告的时间大大缩短,我可以将更多的时间和精力投入到病人的诊断和治疗中。同时,报告的准确性和质量也得到了显著提升,这对于提高医疗服务的质量和病人的满意度至关重要。
更多开源数据集,请打开:遇见数据集
DAHL|生物医学数据集|模型评估数据集DAHL是由首尔国立大学精心策划的生物医学领域长篇文本生成幻觉评估基准数据集。该数据集包含8,573个问题,涵盖29个类别,来源于PubMed Central的生物医学研究论文。数据集的创建过程包括自动生成问题和人工筛选,确保问题的高质量和独立可答性。DAHL旨在评估大型语言模型在生物医学领域...![]() https://www.selectdataset.com/dataset/c5c259c5a72a9fcc8e4826916d9249c1
https://www.selectdataset.com/dataset/c5c259c5a72a9fcc8e4826916d9249c1
















![[vulnhub] Chronos: 1](https://i-blog.csdnimg.cn/direct/e417674c71c44322853c3ec5a7dc0888.png)

