【深度好文】4、Milvus 存储设计深度解析
引言
作为一款主流的云原生向量数据库,Milvus 通过其独特的存储架构设计来保证高效的查询性能。本文将深入剖析 Milvus 的核心存储机制,特别是其最小存储单元 Segment 的完整生命周期,包括数据写入、持久化、合并以及索引构建等关键环节。
1. 数据写入流程
Milvus 中的每个 Collections 指定若干分片,每个分片对应一个虚拟通道(vchannel)。如下图所示,Milvus 会为日志代理中的每个 vchannel 分配一个物理通道(pchannel)。任何传入的插入/删除请求都会根据主键的哈希值路由到分片。
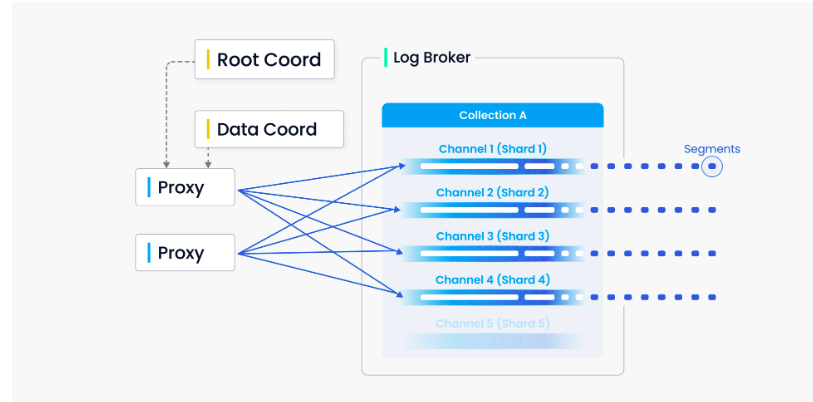
1.1 Insert 请求处理
当 Milvus 启动后,系统会在消息队列(Pulsar/Kafka)中创建数据接收管道,具体数量由 milvus.yaml 中的 rootCoord.dmlChannelNum 配置决定。数据写入流程如下:
-
请求接收与分片
- Proxy 接收 insert 请求
- 根据数据的 primary key 计算 hash 值
- 将 hash 值对 collection 的 shards_num 取模,确定数据分片
-
数据传输机制
- 每个 shard 的数据通过指定管道传输 ,多个 shard 可共享同一管道实现负载均衡
- Data node 订阅对应 shard 数据 , 并尽可能把不同的 shard 分配到多个 data node 上。如果只有一个 data node ,那么就订阅所有的 shard 数据。
-
Growing Segment 处理
- 每个 partition 中的每个 shard 对应一个 growing segment
- Data node 为每个 growing segment 维护缓存
- 缓存用于存储未落盘的数据
下图展示了在 shards_num=2 的情况下,数据经由管道传输至 data node 的流程示意图:
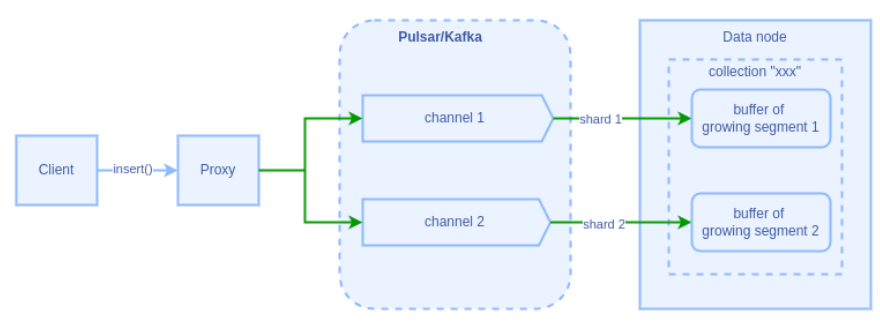
2. 数据持久化机制
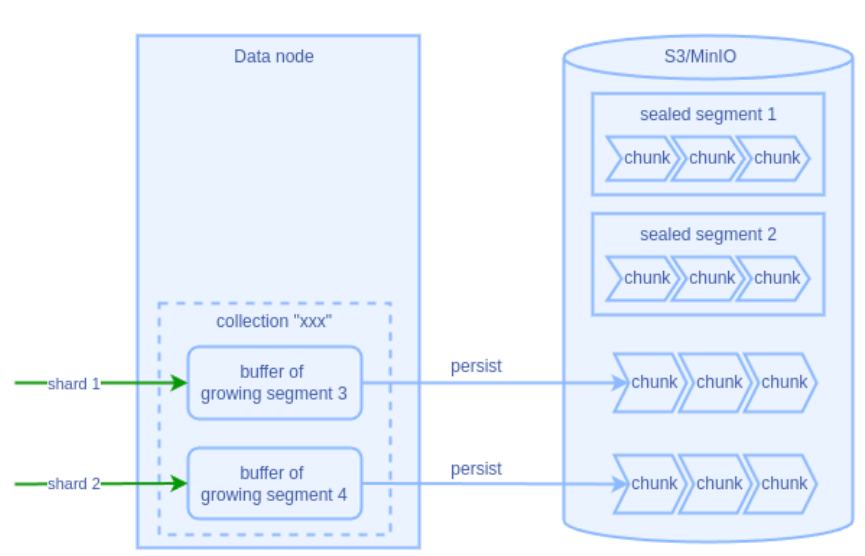
2.1 Growing Segment 持久化
Growing segment 的数据持久化受以下参数控制:
dataNode.segment.insertBufSize: 缓存最大容量(默认16MB)dataNode.segment.syncPeriod: 数据最长停留时间(默认600秒)
当满足以下任一条件时,数据会被写入 S3/MinIO:
- 缓存数据量超过 insertBufSize
- 数据在缓存中停留时间超过 syncPeriod
为什这么设计:
1、减少 data node 内存占用,避免growing segment 内存占用过多。
2、如果系统发生故障之后 ,无需从mq 中重新拉取growing segment 的全部数据,已持久化的数据直接从S3/MinIO读取。
2.2 Sealed Segment 转换
Growing segment 在达到特定条件后会转换为 sealed segment:
- 触发条件:数据量达到
dataCoord.segment.maxSize(默认1024MB) ×dataCoord.segment.sealProportion(默认0.12) - 转换后会创建新的 growing segment 继续接收数据。
数据在 S3/MinIO 中的存储路径由 milvus.yaml 中 minio.bucketName(默认值 a-bucket)以及 minio.rootPath(默认值 files)共同决定。segment 数据的完整路径格式为:
[minio.bucketName]/[minio.rootPath]/insert_log/[collection ID]/[partition ID]/[segment ID]
在 docker 里面的显示如下:
3. 性能优化建议
3.1 避免频繁调用 flush()
- 频繁调用 flush() 可能导致大量碎片化的小 segment
- 建议依赖系统自动落盘机制
- 仅在需要确认全量数据落盘时手动调用
3.2 Segment 管理优化
-
监控 Segment 数量
- 使用 attu 工具监控 segment 分布
- 适当调整 segment_size 参数
- 根据数据量设置合理的 shards_num:
- 百万级数据:shards_num=1
- 千万级数据:shards_num=2
- 亿级数据:shards_num=4或8
-
Partition 规划
- 合理控制 partition 数量
- 避免过多 partition 影响系统性能
3.3 Clustering Key 设计
- 针对范围查询场景优化
- 优化批量数据删除性能
- 提升 compaction 效率
3.4 Segment 合并与 Compaction
在持续执行 insert 请求时,sealed segment 的数量会随着新数据不断写入而增加。如果数据被拆分成过多小尺寸(如小于 100MB)的 segment,会影响系统的数据管理和查询效率。为此,data node 会通过 compaction 将若干较小的 sealed segment 合并成更大的 sealed segment。理想情况下,合并后 segment 大小会尽量接近 dataCoord.segment.maxSize(默认 1GB)。
Compaction 主要包括以下三种场景:
(1) 小文件合并(系统自动)
- 触发条件:存在多个体积较小的 sealed segment,其总大小接近 1GB。
- 优化效果:减少元数据开销,提高批量查询的性能。
(2) 删除数据清理(系统自动)
- 触发条件:segment 中的被删除数据占比 ≥ dataCoord.compaction.single.ratio.threshold(默认 20%)。
- 优化效果:释放存储空间,减少无效数据的重复扫描。
(3) 按聚类键(Clustering Key)重组(手动触发)
- 使用场景:面向特定查询模式(如地域或时间范围检索)优化数据分布。
- 调用方式:通过 SDK 调用 compaction,并按照指定的 Clustering Key 对 Segment 进行重组。
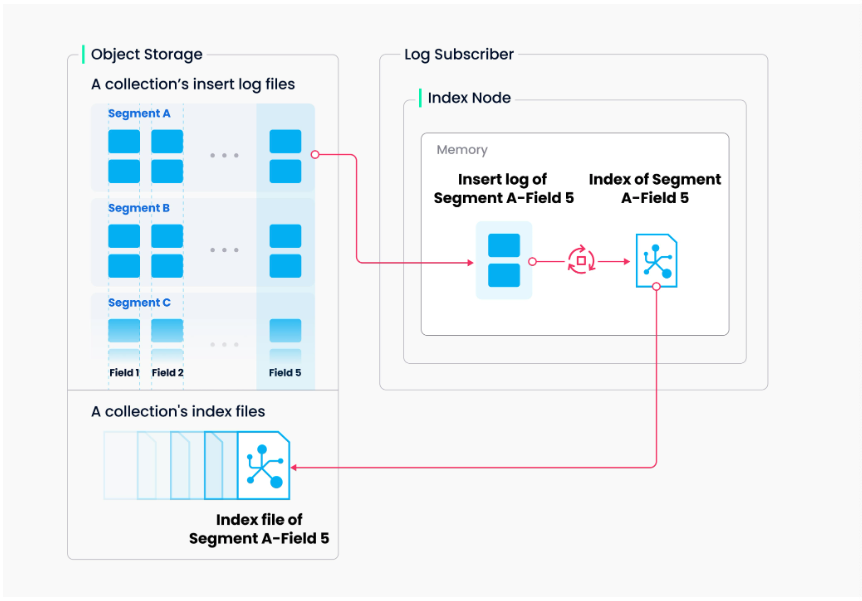
4. 索引构建机制
4.1 索引构建流程
索引构建由专门的 index node 负责执行。为了避免频繁的数据更新导致重复建索引,Milvus 采用了基于 segment 的索引构建策略:
4.1 临时索引 vs 持久化索引
对于每个 growing segment,query node 会在内存中为其建立临时索引,这些临时索引并不会持久化。
同理,当 query node 加载未建立索引的 sealed segment 时,也会创建临时索引。
关于临时索引的相关配置,可在 milvus.yaml 中通过 queryNode.segcore.interimIndex 进行调整。
当 data coordinator 监测到新的 sealed segment 生成后,会指示 index node 为其构建并持久化索引。然而,如果该 sealed segment 的数据量小于 indexCoord.segment.minSegmentNumRowsToEnableIndex (默认 1024 行) ,index node 将不会为其创建索引。
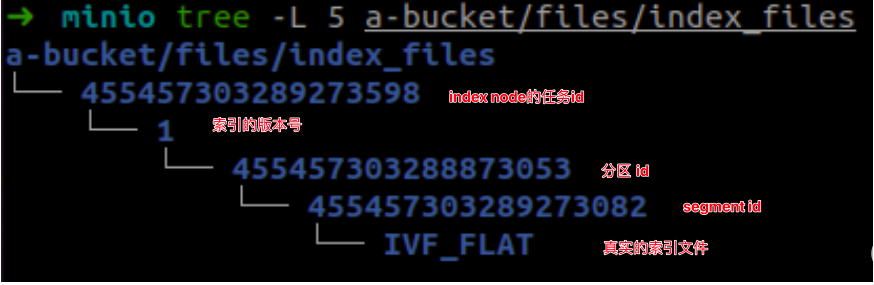
所有索引数据都被保存在以下路径:
[minio.bucketName]/[minio.rootPath]/index_files
5. 数据查询处理
5.1 查询执行流程
Milvus 支持两种主要的查询模式:
- K 近邻搜索:返回与目标向量最接近的 K 个向量
- 范围搜索:返回与目标向量距离在指定范围内的所有向量
查询流程如下:
-
查询请求广播
- 搜索请求广播至所有 query node
- 各节点并发执行搜索
- 对本地 segment 进行剪枝和搜索
- 汇总并返回结果
-
查询节点职责
- 按照 query coord 指令加载或释放 segment
- 在本地 segment 中执行搜索
- Query node 之间相互独立
- Proxy 负责归并各节点结果
5.2 数据一致性管理
Milvus 通过 handoff 机制管理数据一致性:
-
Segment 状态转换
- Growing segment:用于增量数据
- Sealed segment:用于历史数据
- Query node 通过订阅 vchannel 接收最新更新
-
Handoff 流程
- Growing segment 达到阈值后被 data coord 封存
- 开始构建索引
- Query coord 触发 handoff 操作 ,只有等新的 segment 创建之后,索引也可以使用了。旧的数据才从内存中进行删除。
- 增量数据转换为历史数据
-
负载均衡
- Query coord 根据多个指标分配 sealed segment:
- 内存使用情况
- CPU 负载
- Segment 数量
- Query coord 根据多个指标分配 sealed segment:
总结
通过深入理解 Milvus 的存储设计,特别是 Segment 的生命周期管理,开发者可以更好地:
- 设计合理的数据写入策略
- 优化系统配置参数
- 确保系统在复杂场景下保持稳定的高性能表现
本文详细介绍了 Milvus 存储架构的核心组件和关键概念,希望能帮助开发者更好地使用和优化 Milvus 系统。