Spark Mllib 机器学习
概述
机器学习是什么
根据百度百科的定义: 机器学习是一种通过算法和模型使计算机从数据中自动学习并进行预测或决策的技术。
定义比较抽象,根据常见的机器学习可以总结出三个关键字: 算法、经验、性能。
机器学习的过程可以抽象成一个pipeline
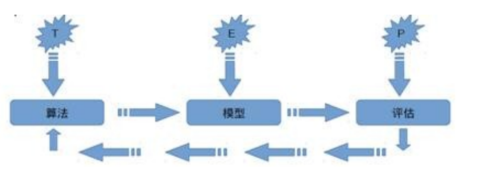
数据通过某一个算法构建出模型,然后对这个模型进行评估。
模型就是利用数据经过算法训练出来的“经验”。
评估是评估什么?评估得到的这个模型“性能”如何,是否满足需求,也就说这个经验是否有价值。
如果不满足,就要调整算法,或是继续训练,增加经验。
云端机器学习资源
机器学习需要消耗较多资源,但机器学习的步骤固定,所以云计算厂商提供了pipeline平台,只要本地写好算法和数据,可以直接进行云端机器学习。
阿里云 PAI : 人工智能平台PAI_机器学习_模型训练与部署_人工智能-阿里云
AWS Sagemaker: Amazon SageMaker 机器学习_机器学习模型构建训练部署-AWS云服务
Google AutoML: https://cloud.google.com/automl/
机器学习的种类
人工智能、机器学习、神经网络、深度学习、AI大模型的区别
Spark MLlib介绍
MLlib(Machine Learnig lib) 是 Spark 对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器。Spark 的设计初衷就是为了支持一些迭代的 Job, 这正好符合很多机器学习算法的特点。
Spark 之所以在机器学习方面具有得天独厚的优势:
1、机器学习算法一般都有很多个步骤迭代计算的过程,机器学习的计算需要在多次迭代后获得足够小的误差或者足够收敛才会停止,迭代时如果使用 Hadoop 的MapReduce 计算框架,每次计算都要读/写磁盘以及任务的启动等工作,这会导致非常大的 I/O 和 CPU 消耗。而 Spark 基于内存的计算模型天生就擅长迭代计算,多个步骤计算直接在内存中完成,只有在必要时才会操作磁盘和网络,所以说 Spark 正是机器学习的理想的平台。
2、从通信的角度讲,如果使用 Hadoop 的 MapReduce 计算框架,由于是通过heartbeat 的方式来进行的通信和传递数据,会导致非常慢的执行速度,而 Spark 具有出色而高效的 Akka 和 Netty 通信系统,通信效率极高。
MLlib 目前支持 4 种常见的机器学习问题: 分类、回归、聚类和协同过滤
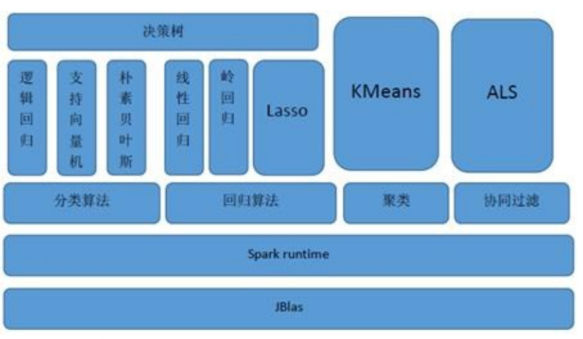
MLlib 基于 RDD,天生就可以与 Spark SQL、GraphX、Spark Streaming 无缝集成。
MLlib 是 MLBase 一部分,其中 MLBase 分为四部分:MLlib、MLI、ML Optimizer 和MLRuntime。ML Optimizer 会选择它认为最适合的已经在内部实现好了的机器学习算法和相关参数,来处理用户输入的数据,并返回模型或别的帮助分析的结果。
MLI 是一个进行特征抽取和高级 ML 编程抽象的算法实现的 API 或平台。
MLlib 是 Spark 实现一些常见的机器学习算法和实用程序,包括分类、回归、聚类、协同过滤、降维以及底层优化,该算法可以进行可扩充; MLRuntime 基于 Spark计算框架,将 Spark 的分布式计算应用到机器学习领域。
Spark MLlib架构
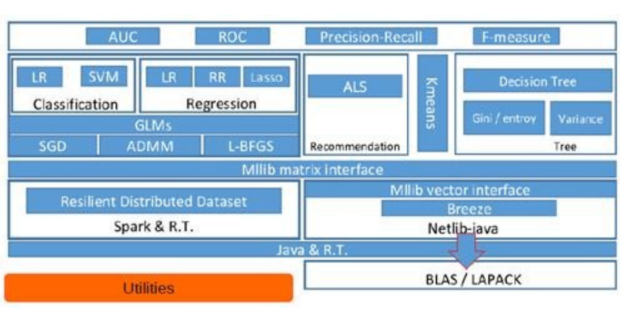
MLlib 采用分层设计, 主要包含三个部分:
1. 底层基础设施层:包括 Spark 的运行库、矩阵库和向量库;
2. 算法库:包含广义线性模型、推荐系统、聚类、决策树和评估的算法;
3. 高级API层:包括测试数据的生成、外部数据的读入等功能, 提供 Pipeline API 和调优工具。
核心组件
数据表示
- Vector/Matrix:本地和分布式向量/矩阵表示
- DataFrame-based API:使用 Spark SQL 的 DataFrame 作为主要数据容器
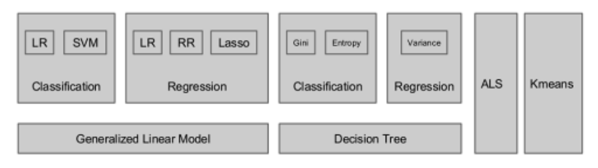
算法分类
- 分类算法:逻辑回归、决策树、随机森林等
- 回归算法:线性回归、广义线性回归等
- 聚类算法:K-means、LDA 等
- 协同过滤:ALS (交替最小二乘法)
- 特征提取与转换:TF-IDF、Word2Vec 等
工作流工具
- Pipeline API:将多个机器学习阶段组合成工作流
- Transformer:将 DataFrame 转换为新 DataFrame
- Estimator:拟合数据生成 Transformer
- 模型评估工具:交叉验证、超参数调优
分类算法
支持向量机(SVM)算法把输入数据映射到一个高阶的向量空间, 在这些高阶向量空间里, 有些分类或者回归问题能够更容易解决。
分类算法用于预测离散的类别标签,将输入数据划分到预定义的类别中。
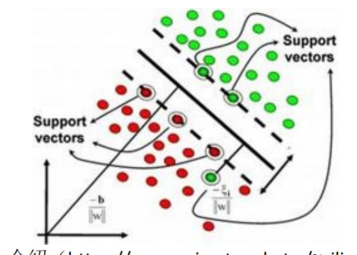
开源实现:libsvm 介绍( LIBSVM -- A Library for Support Vector Machines)
特点:
- 输出是离散的类别(如"是/否"、"A/B/C"等)
- 属于监督学习(需要已标注的训练数据)
- 评估指标:准确率、精确率、召回率、F1分数、AUC-ROC等
常见算法:
- 逻辑回归(Logistic Regression)
- 决策树(Decision Tree)
- 随机森林(Random Forest)
- 支持向量机(SVM)
- 朴素贝叶斯(Naive Bayes)
- 神经网络(Neural Networks)
应用场景:
- 垃圾邮件检测(垃圾邮件/正常邮件)
- 图像识别(猫/狗/鸟)
- 信用风险评估(通过/拒绝)
- 疾病诊断(患病/健康)
import org.apache.spark.sql.SparkSessionval spark = SparkSession.builder().appName("SparkMLlibDemos").master("local[*]") // 本地模式,使用所有核心.getOrCreate()import spark.implicits._// 1. 准备数据
val trainingData = Seq((1.0, Vectors.dense(0.0, 1.1, 0.1)),(0.0, Vectors.dense(2.0, 1.0, -1.0)),(0.0, Vectors.dense(2.0, 1.3, 1.0)),(1.0, Vectors.dense(0.0, 1.2, -0.5))
).toDF("label", "features")// 2. 创建逻辑回归模型
val lr = new LogisticRegression().setMaxIter(10).setRegParam(0.01)// 3. 训练模型
val lrModel = lr.fit(trainingData)// 4. 打印模型参数
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}")// 5. 预测新数据
val testData = Seq((1.0, Vectors.dense(-1.0, 1.5, 1.3)),(0.0, Vectors.dense(3.0, 2.0, -0.1)),(1.0, Vectors.dense(0.0, 2.2, -1.5))
).toDF("label", "features")val predictions = lrModel.transform(testData)
predictions.show()// 6. 评估模型
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator
val evaluator = new BinaryClassificationEvaluator().setMetricName("areaUnderROC")val auc = evaluator.evaluate(predictions)
println(s"Area under ROC = $auc")回归算法
线性回归是利用称为线性回归方程的函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析方法,只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归,在实际情况中大多数都是多元回归。
线性回归(Linear Regression)问题属于监督学习(Supervised Learning)范畴,又称分类(Classification)或归纳学习(Inductive Learning)。这类分析中训练数据集中给出的数据类型是确定的。机器学习的目标是,对于给定的一个训练数据集,通过不断的分析和学习产生一个联系属性集合和类标集合的分类函数(Classification Function)或预测函数(Prediction Function),这个函数称为分类模型(Classification Model——或预测模型(Prediction Model)。通过学习得到的模型可以是一个决策树、规格集、贝叶斯模型或一个超平面。通过这个模型可以对输入对象的特征向量预测或对对象的类标进行分类。
回归问题中通常使用最小二乘(Least Squares)法来迭代最优的特征中每个属性的比重,通过损失函数(Loss Function)或错误函数(Error Function)定义来设置收敛状态,即作为梯度下降算法的逼近参数因子。
logistic 回归主要是进行二分类预测,也即是对于 0~1 之间的概率值,当概率大于0.5 预测为 1,小于 0.5 预测为 0.显然,我们不能不提到一个函数,即sigmoid=1/(1+exp(-inX)),该函数的曲线类似于一个 s 型,在 x=0 处,函数值为 0.5。
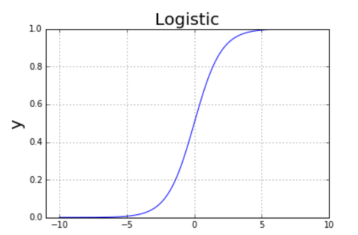
特点:
- 输出是连续值(如价格、温度、销量等)
- 属于监督学习
- 评估指标:均方误差(MSE)、均方根误差(RMSE)、R²分数等
常见算法:
- 线性回归(Linear Regression)
- 多项式回归(Polynomial Regression)
- 岭回归(Ridge Regression)
- Lasso回归
- 弹性网络(Elastic Net)
- 回归树(Regression Tree)
应用场景:
- 房价预测
- 股票价格预测
- 销售额预测
- 温度预测
import org.apache.spark.sql.SparkSessionval spark = SparkSession.builder().appName("SparkMLlibDemos").master("local[*]") // 本地模式,使用所有核心.getOrCreate()import spark.implicits._// 1. 准备数据
val dataset = Seq((1.0, 1.0, 2.0, 1.0),(2.0, 2.0, 3.0, 2.0),(4.0, 3.0, 5.0, 3.0),(3.0, 4.0, 2.0, 4.0)
).toDF("label", "x1", "x2", "x3")// 2. 特征向量化
val assembler = new VectorAssembler().setInputCols(Array("x1", "x2", "x3")).setOutputCol("features")val assembledData = assembler.transform(dataset)// 3. 划分训练集和测试集
val Array(trainData, testData) = assembledData.randomSplit(Array(0.7, 0.3))// 4. 创建线性回归模型
val lr = new LinearRegression().setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8)// 5. 训练模型
val lrModel = lr.fit(trainData)// 6. 打印模型摘要
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}")
println(s"RMSE: ${lrModel.summary.rootMeanSquaredError}")
println(s"R2: ${lrModel.summary.r2}")// 7. 预测
val predictions = lrModel.transform(testData)
predictions.select("prediction", "label", "features").show()聚类算法
所谓聚类问题,就是给定一个元素集合 D,其中每个元素具有 n 个可观察属性,使用某种算法将 D 划分成 k 个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高。其中每个子集叫做一个簇。
聚类算法用于发现数据中的自然分组或模式,将相似的数据点聚集在一起。
K-Means 属于基于平方误差的迭代重分配聚类算法,其核心思想十分简单:
1. 随机选择 K 个中心点;
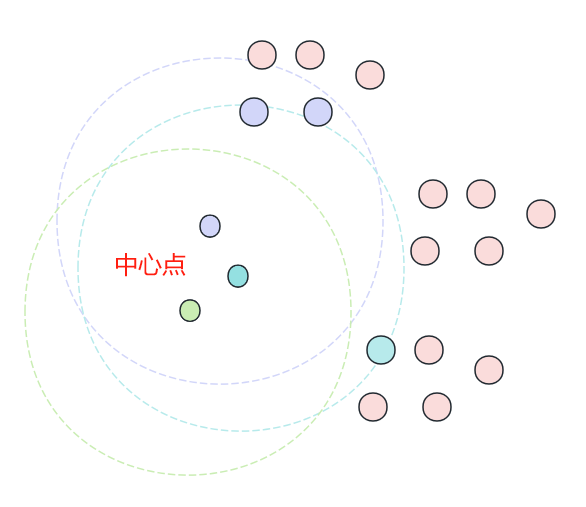
2. 计算所有点到这 K 个中心点的距离,选择距离最近的中心点为其所在的簇;
3. 简单地采用算术平均数(mean)来重新计算 K 个簇的中心;
4. 重复步骤 2 和 3,直至簇类不再发生变化或者达到最大迭代值;
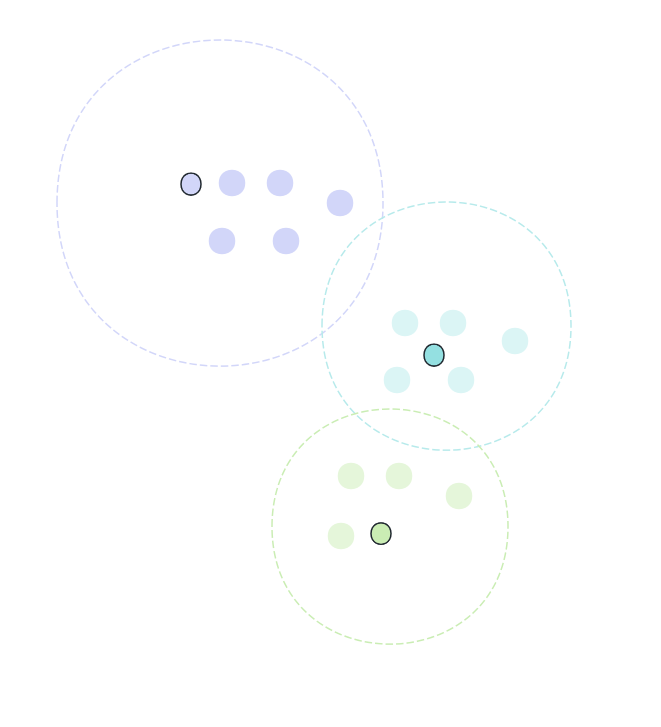
5. 输出结果。
特点:
- 无监督学习(不需要已标注数据)
- 没有明确的"正确"答案
- 评估指标:轮廓系数、Davies-Bouldin指数等
- 需要预先指定或自动确定簇的数量
常见算法:
- K均值(K-Means)
- 层次聚类(Hierarchical Clustering)
- DBSCAN(基于密度的聚类)
- 高斯混合模型(GMM)
- 谱聚类(Spectral Clustering)
应用场景:
- 客户细分
- 异常检测
- 图像分割
- 社交网络分析
- 文档聚类
import org.apache.spark.sql.SparkSessionval spark = SparkSession.builder().appName("SparkMLlibDemos").master("local[*]") // 本地模式,使用所有核心.getOrCreate()import spark.implicits._// 1. 准备数据
val dataset = Seq(Vectors.dense(0.0, 0.0),Vectors.dense(1.0, 1.0),Vectors.dense(9.0, 8.0),Vectors.dense(8.0, 9.0),Vectors.dense(0.1, 0.1),Vectors.dense(8.1, 9.1)
).map(Tuple1.apply).toDF("features")// 2. 创建K-means模型
val kmeans = new KMeans().setK(2) // 设置聚类数量.setSeed(1L)// 3. 训练模型
val model = kmeans.fit(dataset)// 4. 预测
val predictions = model.transform(dataset)
predictions.show()// 5. 评估聚类效果
val evaluator = new ClusteringEvaluator()
val silhouette = evaluator.evaluate(predictions)
println(s"Silhouette with squared euclidean distance = $silhouette")// 6. 查看聚类中心
println("Cluster Centers: ")
model.clusterCenters.foreach(println)