导读
本文提出了INTEGER,一种面向户外点云数据的无监督配准方法,通过整合高层上下文和低层几何特征信息来生成更可靠的伪标签。该方法基于教师-学生框架,创新性地引入特征-几何一致性挖掘(FGCM)模块以提高伪标签的准确性,并利用锚点对比学习(ABCont)和混合密度学生(MDS)模块实现密度不变的特征学习。实验结果显示,INTEGER在大规模户外场景中表现出色,在多个数据集上达到了较高的配准精度和良好的泛化性,显著优于其他无监督方法。
论文信息
-
论文标题: Mining and Transferring Feature-Geometry Coherence for Unsupervised Point Cloud Registration
-
作者: Kezheng Xiong, Haoen Xiang, Qingshan Xu, Chenglu Wen∗, Siqi Shen, Jonathan Li, Cheng Wang
-
论文链接: https://arxiv.org/pdf/2411.01870
-
项目地址: https://github.com/kezheng1204/INTEGER
动机(motivation)
当前无监督点云配准方法在大规模户外场景中面临的局限性:这些方法依赖于低层几何特征,但缺乏对高层上下文信息的有效整合,导致伪标签质量差、优化目标不够可靠,尤其在稠密度变化和低重叠场景下难以适用。此外,现有方法在处理复杂场景中的内点(inlier)与外点(outlier)时表现不够理想,使得生成的伪标签在噪声和变密度条件下缺乏鲁棒性。为解决这些问题,本文旨在利用特征-几何一致性挖掘来动态调整伪标签生成过程,通过整合高层上下文信息和几何特征来改进配准精度,实现无监督框架在户外大规模点云配准中的通用性和可靠性。
![(1) 动机:新的内点(外点)倾向于分别聚集在特征空间中代表现有内点(外点)的潜在正(负)锚点周围。(2) 性能:INTEGER生成的伪标签相比于当前最先进的EYOC[12]更加稳健且准确。](https://img-blog.csdnimg.cn/img_convert/bdf04b9269a5fc00a1d0a987c49c8745.png)
(1) 动机:新的内点(外点)倾向于分别聚集在特征空间中代表现有内点(外点)的潜在正(负)锚点周围。(2) 性能:INTEGER生成的伪标签相比于当前最先进的EYOC[12]更加稳健且准确。
算法核心思想与实现
本文的核心算法是INTEGER,一个专为无监督点云配准设计的方法,主要通过三个模块实现:特征-几何一致性挖掘(Feature-Geometry Coherence Mining, FGCM)、基于锚点的对比学习(Anchor-Based Contrastive Learning, ABCont)和混合密度学生(Mixed-Density Student, MDS)。以下是每个模块的详细介绍:
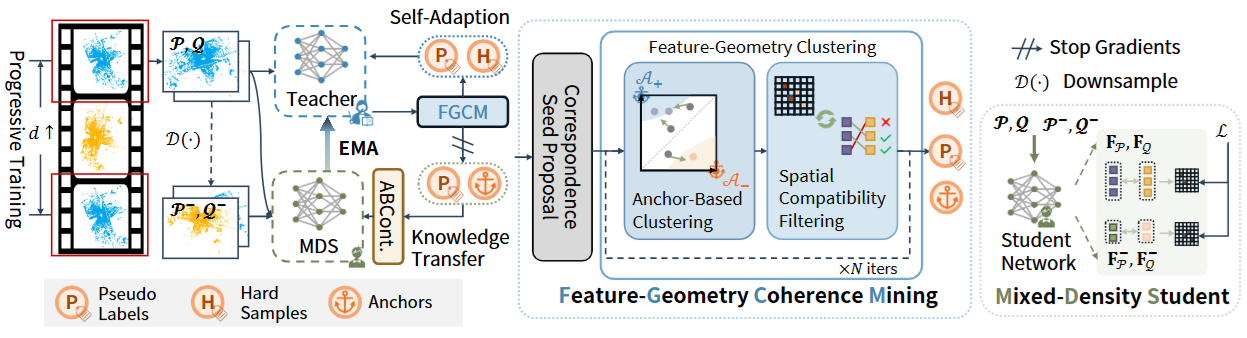
The Overall Pipeline
1. 特征-几何一致性挖掘(FGCM)
FGCM模块负责生成和优化伪标签。为了提高伪标签的准确性,INTEGER采用教师-学生框架,其中教师模型动态适应每批次数据,进而产生较为精确的伪标签。FGCM包括以下步骤:
-
初始种子匹配提议:FGCM首先通过简单的相似度阈值生成初始匹配对。
-
特征-几何聚类:基于特征相似度,FGCM逐步扩展初始匹配,利用锚点(正锚点和负锚点)来聚类潜在内点和外点。同时,空间兼容性过滤用于进一步排除不一致的外点。
-
批次自适应:在每次前向传播中,FGCM会自适应调整教师模型,使其更符合当前批次数据的特征分布,进而生成更精确的伪标签。这一自适应过程利用InfoNCE损失,使教师能够有效区分特征空间中的内点和外点。
2. 基于锚点的对比学习(ABCont)
ABCont模块用于增强特征空间中的鲁棒性,通过锚点约束实现有效的对比学习。在特征空间中,ABCont利用正负锚点代表整体的内点和外点,从而减少了不一致标签带来的噪声,并减少了计算负担。具体实现包括:
-
伪标签对比损失:ABCont定义了一种基于锚点的对比损失(Lcorr),对正负锚点进行分组,以区分内点和外点。
-
对比学习目标:通过将锚点作为学习目标,ABCont使学生模型能够在特征空间中学习到与教师模型一致的特征表示,并提高学生模型在新数据上的泛化能力。
3. 混合密度学生(MDS)
MDS模块用于解决点云密度变化对配准结果的影响,通过密度不变的特征学习来增强鲁棒性。MDS主要步骤如下:
-
混合密度特征匹配:通过对点云进行不同密度的采样,MDS在密度较低和较高的点云中分别提取特征,然后利用ABCont来匹配这些不同密度的特征,进而学习到密度不变的特征。
-
损失聚合:MDS在稠密和稀疏特征匹配上都使用ABCont损失,通过结合两个损失函数来优化学生模型,使其在密度变化的情况下也能保持较好的特征匹配性能。
4. 整体流程
INTEGER算法的整体训练流程如下:
-
教师初始化:首先在合成数据上初始化教师模型,生成初始伪标签。
-
FGCM自适应伪标签生成:FGCM模块对教师模型进行批次自适应调整,并生成伪标签。
-
ABCont对比学习:通过基于锚点的对比学习,ABCont模块使学生模型能够在特征空间中学习到与教师一致的特征表示。
-
MDS密度不变特征学习:MDS模块利用不同密度的点云数据,通过密度不变特征学习增强学生模型的泛化能力。
-
更新教师模型:通过迭代训练,教师模型不断学习新的伪标签,为学生模型提供更准确的监督信号。
5. 算法实现的关键技术点
-
特征-几何一致性:通过结合高低层信息,确保伪标签能够准确地包含内点对应关系。
-
锚点对比学习:利用锚点来增强特征空间的一致性,使得伪标签在噪声和密度变化条件下更加稳健。
-
密度不变学习:利用MDS模块实现点云在稀疏和密集场景下的特征一致性,提升算法的鲁棒性。
实现
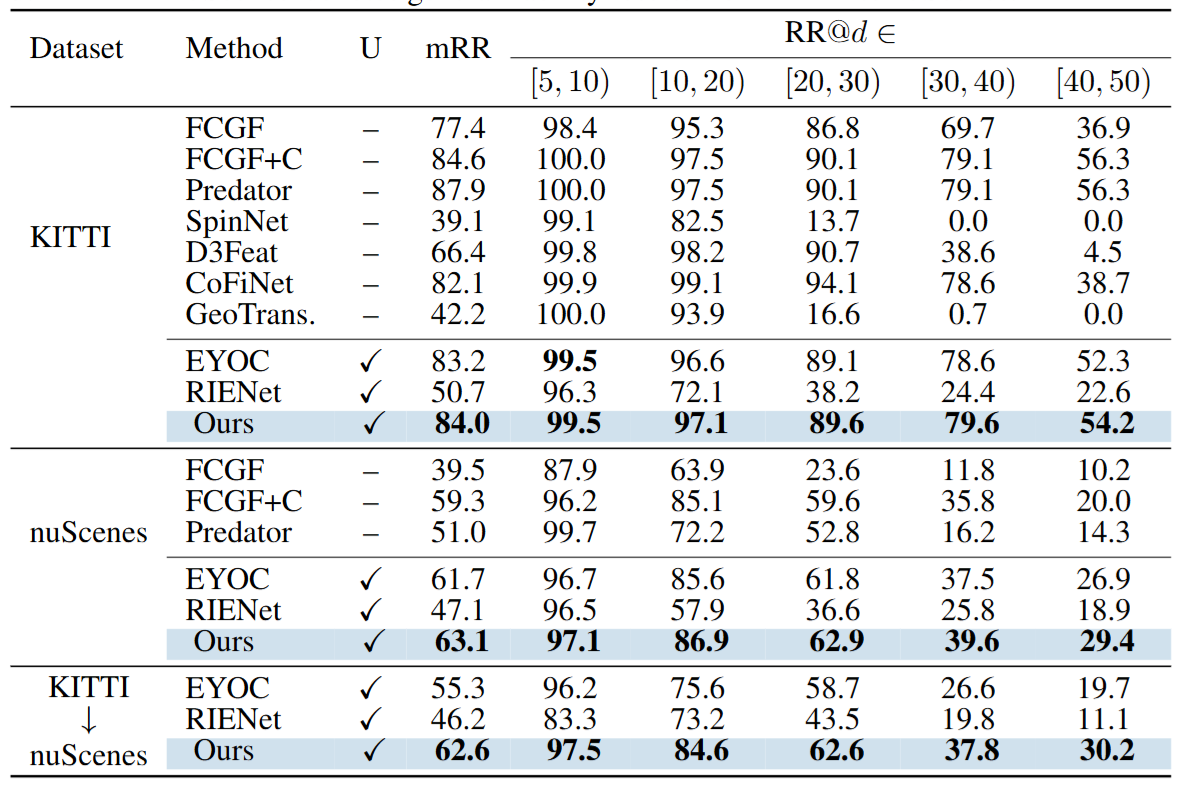
Comparisons with State-of-the-Art Methods
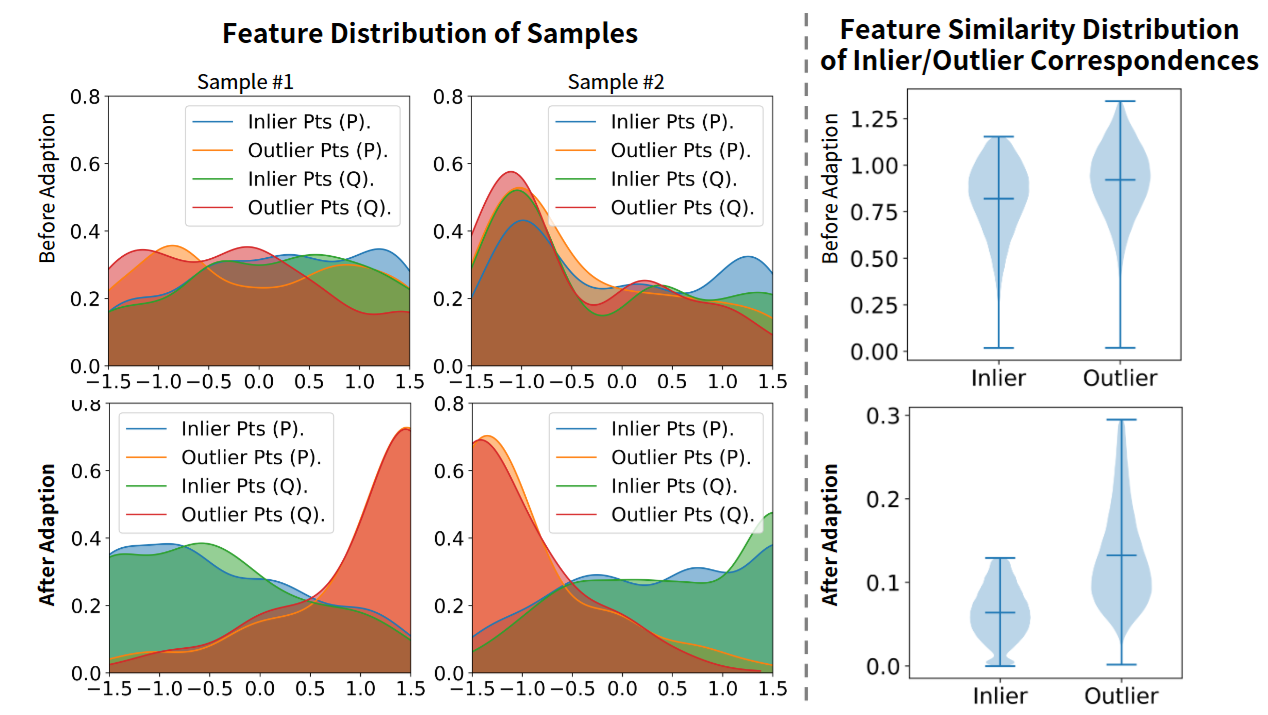
FGCM自适应前后:逐点特征和对应相似性分布表明,自适应会产生更多的判别特征。
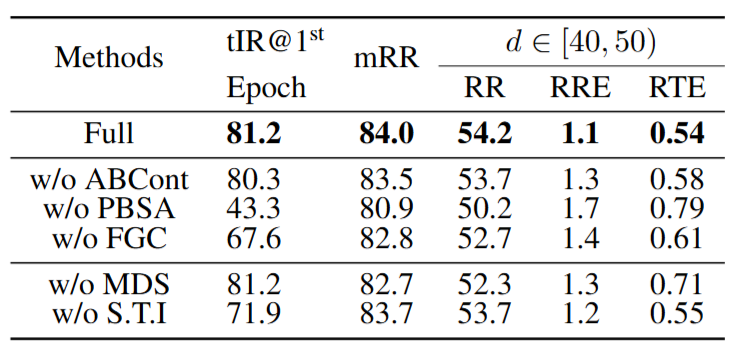
INTEGER消融研究。S.T.I表示综合教师初始化。PBSA和FGC分别表示每批自适应和特征几何聚类
总结 & 局限性
本文提出了INTEGER,一种用于点云配准的无监督新方法,通过整合低层几何信息和高层上下文信息来生成可靠的伪标签。该方法引入了特征-几何一致性挖掘模块(FGCM),用于动态地对教师模型进行自适应调整,并基于特征和几何空间进行稳健的伪标签挖掘。然后,我们设计了混合密度学生(MDS)以学习密度不变的特征,并通过锚点对比学习(ABCont)实现高效的对比学习。大量实验表明,INTEGER在两个大型户外数据集上的表现优异,尽管是无监督方法,其结果依然与当前最先进的监督方法相当,甚至在远距离场景中优于现有的无监督方法。此外,我们的方法在未见数据集上的泛化能力也表现出色。
局限性
所提出方法的局限性主要有两点:
-
方法依赖于教师模型的质量。如果教师模型不准确,特征空间可能会变得过于嘈杂,尤其是在远距离场景下,这会阻碍FGCM中特征-几何聚类的效果。一个可能的改进方案是开发更稳健的教师模型初始化策略。
-
与现有方法相比,由于FGCM模块中采用了迭代的方法,我们的方法在获取伪标签的速度上稍慢。未来的工作可以探索更高效的伪标签挖掘策略。
本文仅做学术分享,如有侵权,请联系删文!
如何利用无监督方法将点云配准做到又准又鲁棒?详细解读24年最新开源的五个State-of-the-Art算法
👇👇👇👇👇👇👇👇👇👇
点击下方卡片
第一时间获取最热行业热点资讯,最新智驾机器人行业技术






![[含文档+PPT+源码等]精品基于springboot实现的原生Andriod手机使用管理软件](https://img-blog.csdnimg.cn/img_convert/485b39844736dda91d34414e2089d39c.jpeg)