网友 竹林风 说,已经成功的用 mxbai-embed-large 映射到 text-embedding-ada-002,并测试成功了。不愧是爱折腾的人,老苏还没时间试,因为又找到了另一个支持 AI 的桌面版笔记 Reor
Reor 简介
什么是 Reor ?
Reor是一款由人工智能驱动的桌面笔记应用:它会自动链接相关笔记、回答笔记中的问题并提供语义搜索。所有内容都存储在本地,您可以使用类似Obsidian的Markdown编辑器编辑笔记。
Reor 可以成为你的一款私人和本地的 AI 个人知识管理应用
主要特点
-
AI 驱动的笔记管理:
Reor自动链接相关笔记,支持语义搜索,并可以回答关于笔记的问题。 -
本地存储:所有数据都存储在本地,用户可以使用类似
Obsidian的Markdown编辑器编辑笔记。 -
模型本地运行:
Reor支持本地运行大型语言模型(LLMs),用户可以通过应用下载和运行模型,还可以连接到OpenAI兼容的API。 -
智能信息检索:应用通过向量数据库连接相关笔记,并提供基于检索增强生成(
RAG)的问答功能。 -
易于导入和集成:用户可以手动将其他应用的
Markdown文件导入到Reor。
Reor 的目标是增强用户的思维过程,帮助他们更有效地管理和利用知识。
核心功能
聊天
-
你可以向整个笔记集提问,询问任何你想知道的内容!
Reor会自动为大型语言模型(LLM)提供相关上下文。 -
例如,可以问:“我对哲学的看法是什么?”或“总结一下我关于黑洞的笔记”。
-
在设置中,你可以连接本地
LLM或使用你的API密钥连接到OpenAI模型。 -
LLM可以被提供“工具”,如搜索、创建文件等。这能让LLM在你的知识库中更有效地执行任务。 -
你还可以编辑提供给
LLM的系统提示。
写作助手
-
Reor内置了写作助手,可以帮助你进行写作。 -
你可以通过在新行上按空格键或选择文本并点击出现的图标来触发它。
链接
-
Reor会自动将你的笔记链接到“相关笔记”侧边栏中的其他笔记。 -
你可以通过高亮特定文本并点击出现的按钮来查看与之相关的笔记。
-
你也可以通过用两个方括号包围文本来创建行内链接(类似于
Obsidian)。[[像这样]]
Reor 功能演示
你可以通过将 markdown 文件添加到你的库目录中,从其他应用导入笔记。请注意,Reor 仅会读取 markdown 文件。
下载及运行
Reor 的下载地址:https://www.reorproject.org/downloads

或者 https://github.com/reorproject/reor/releases
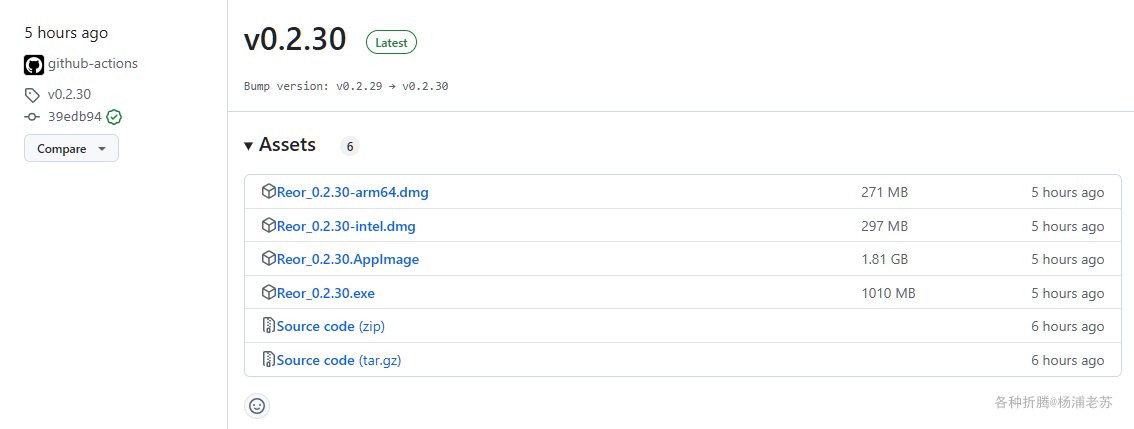
目前的更新迭代速度非常快,老苏下载了 windows 版

第一次运行
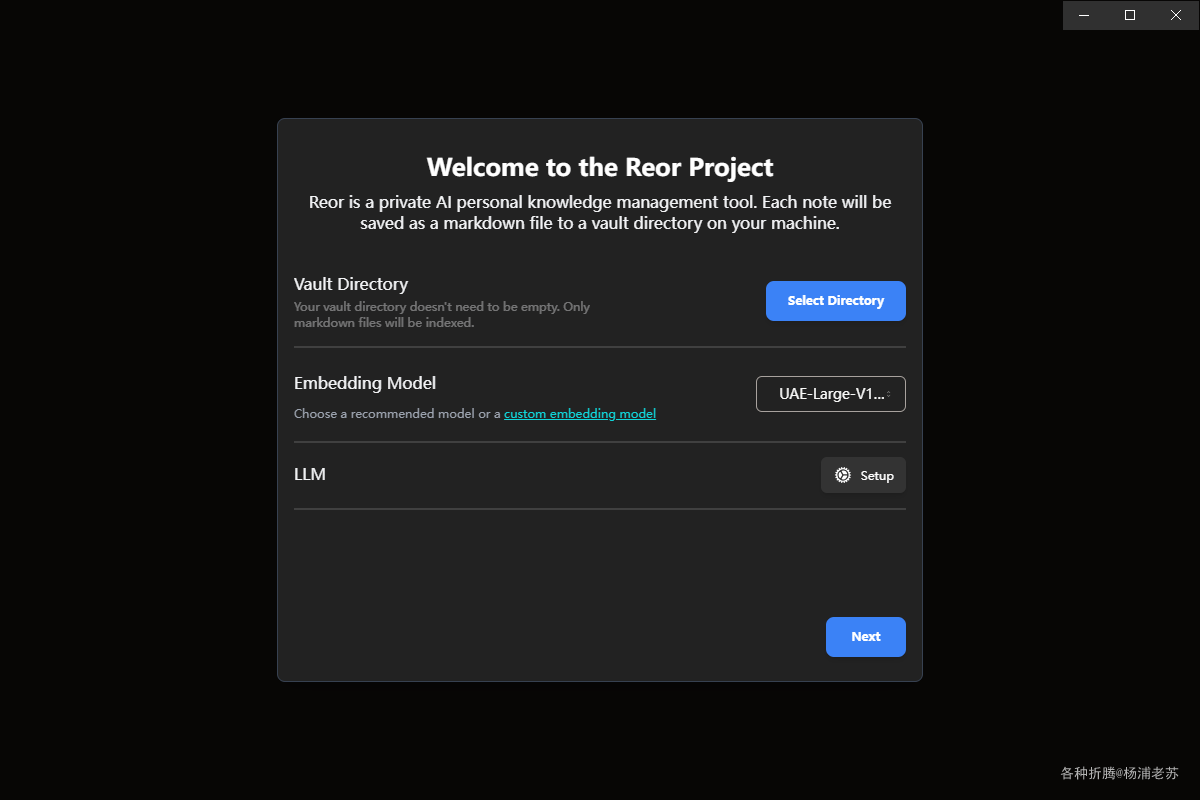
选择笔记库的目录后,直接点 Next
- 嵌入模型:如果你的笔记多,而且以中文为主,建议改为
jina-embeddings-v2-base-zh,对中文支持可能更好。LLM暂时先不管,安装完成后可以再设置。

开始索引笔记
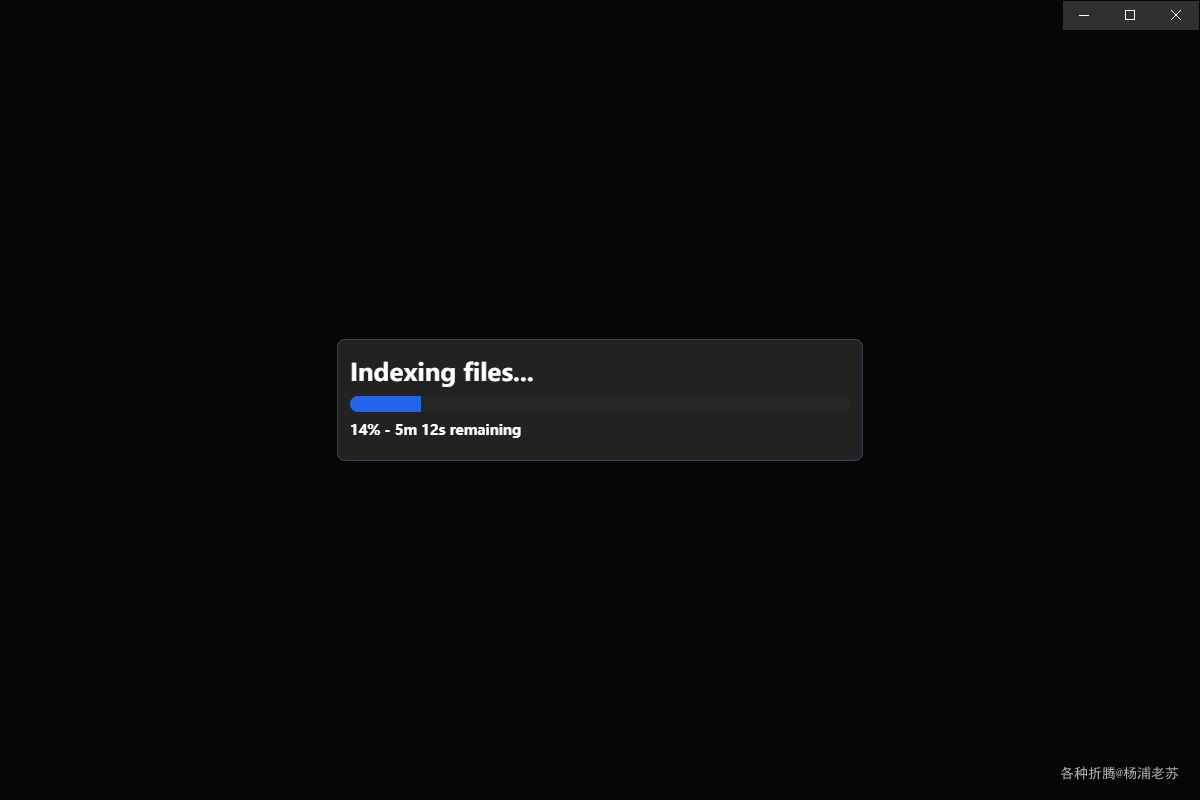
因为文件不多,还是比较快的
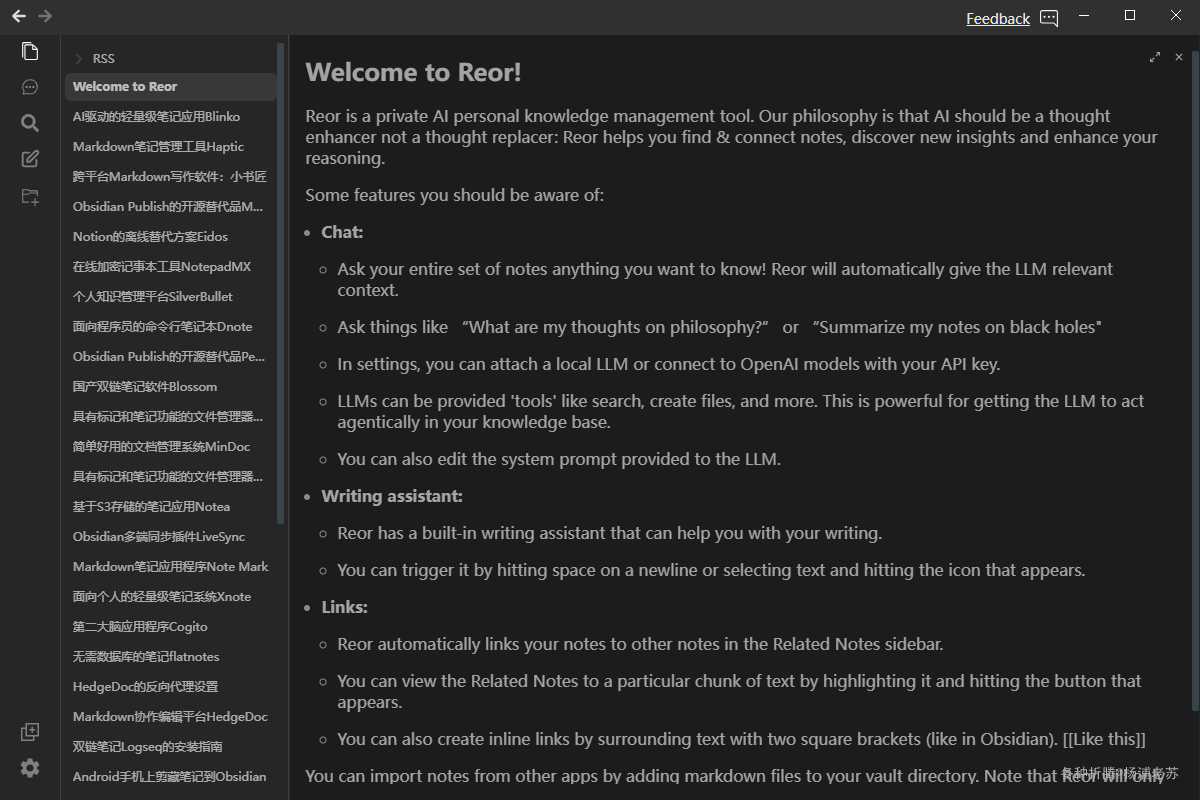
完成索引之后的主界面
设置
LLM
点左下角的小齿轮
进入设置 --> LLM 设置界面
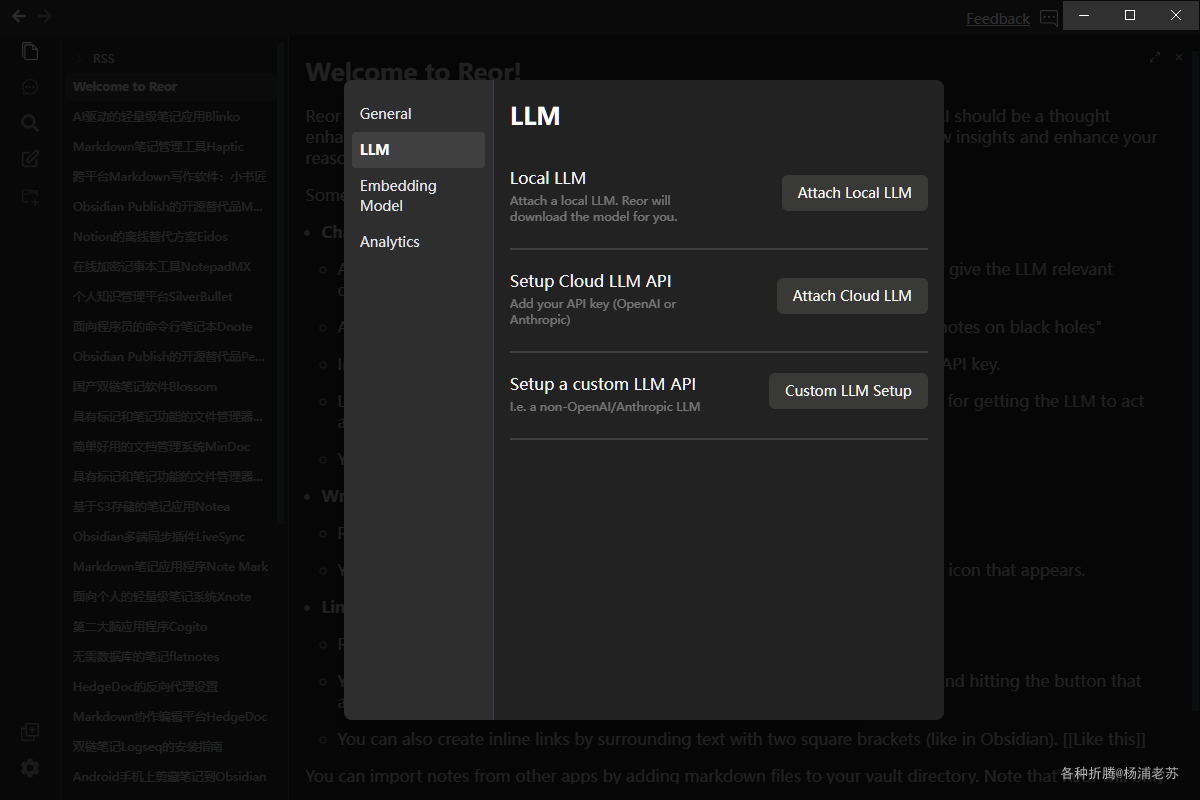
支持三种模式:
Local LLM模式。可以直接输入模型名称。这是在本地运行的,不过老苏觉得这种方式不太经济,尤其是你需要在多台电脑上同步笔记的情况下
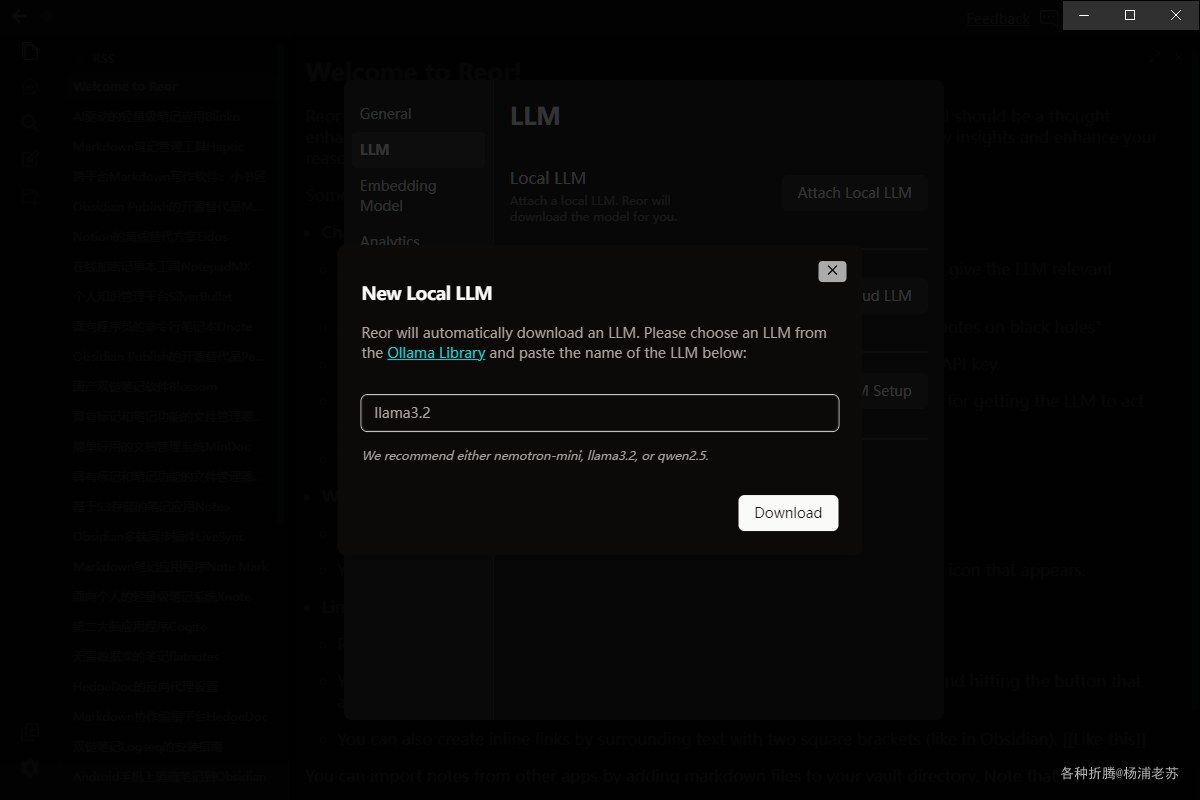
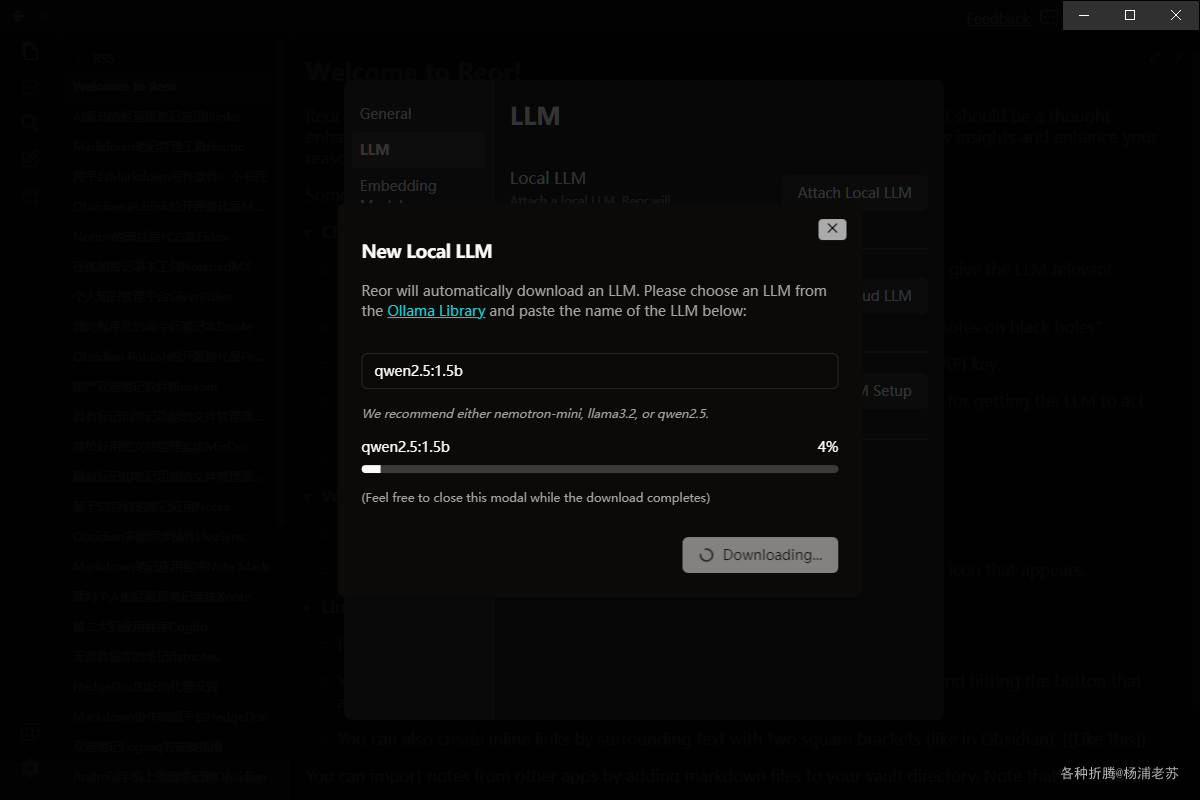
可以指定参数,例如:qwen2.5:1.5b
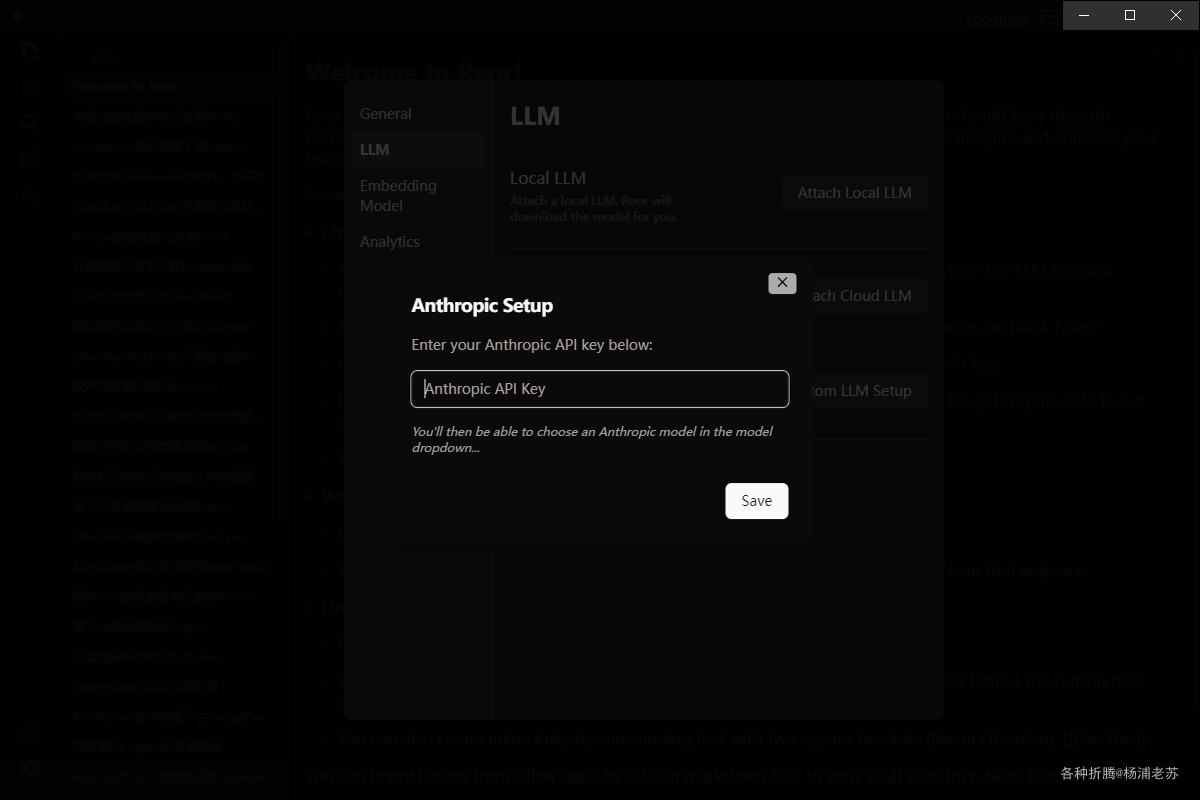
Setup Cloud LLM API模式。支持OpenAI和Anthropic,都只要输入API key就可以。云服务虽然简单,但是对国内用户不太友好
Setup a custom LLM API模式。这种自定义模式适合自己安装了AI服务的玩家
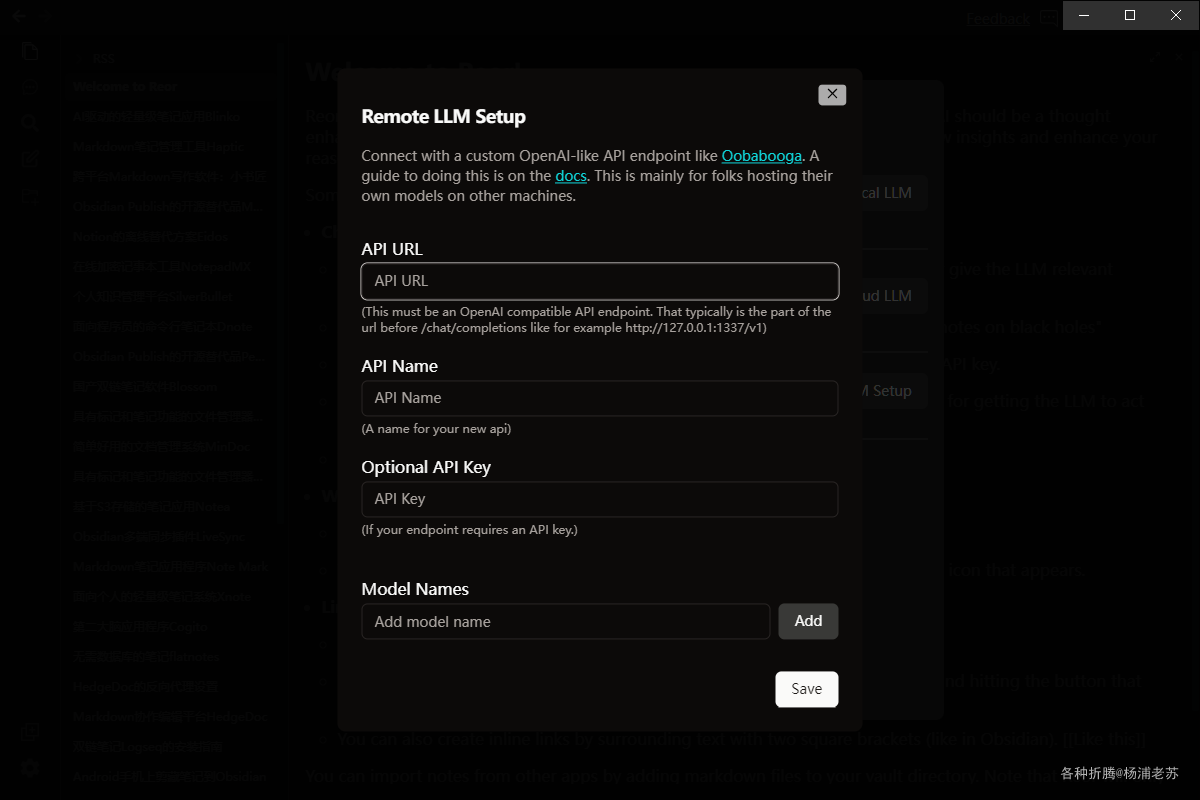
这里假设你已经安装了我们需要用到的 One API 和 kimi-free-api,当然 One API 并不是必须的,你要是想省事,可以只安装 kimi-free-api
文章传送门:
- 长文本大模型API服务kimi-free-api
- 大模型接口管理和分发系统One API
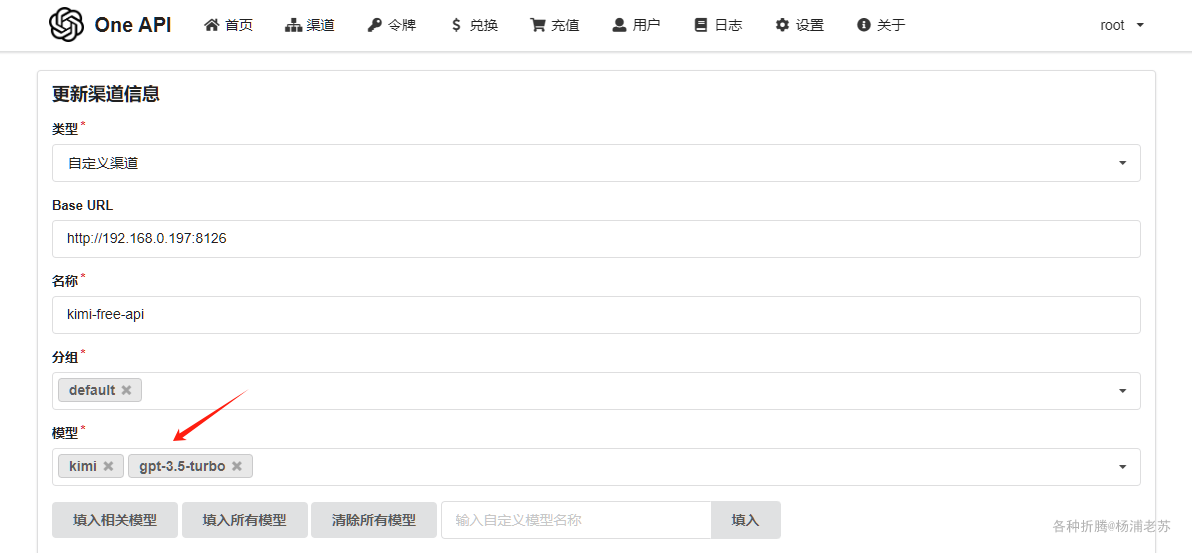
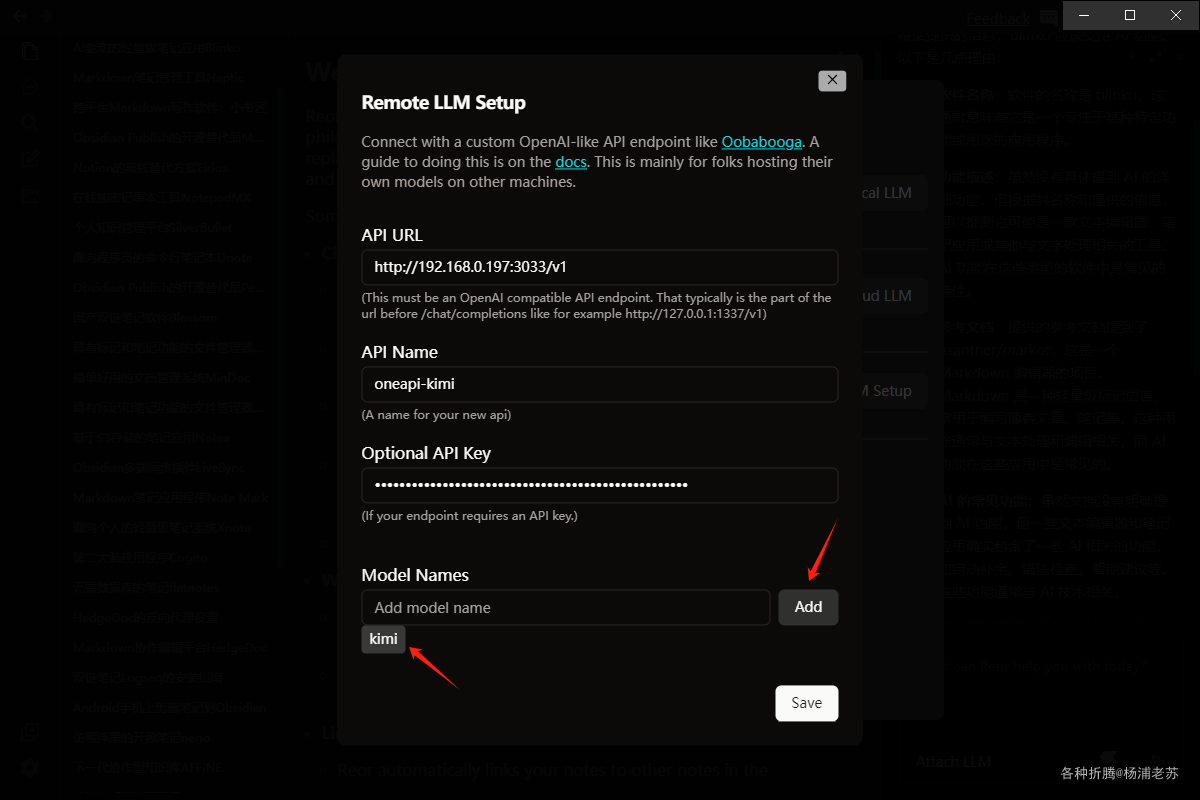
API URL:用One API的地址,加上/v1,例如:http://192.168.0.197:3033/v1;API Name:这是给API一个名字,例如:oneapi-kimi;Optional API Key:用One API的令牌;
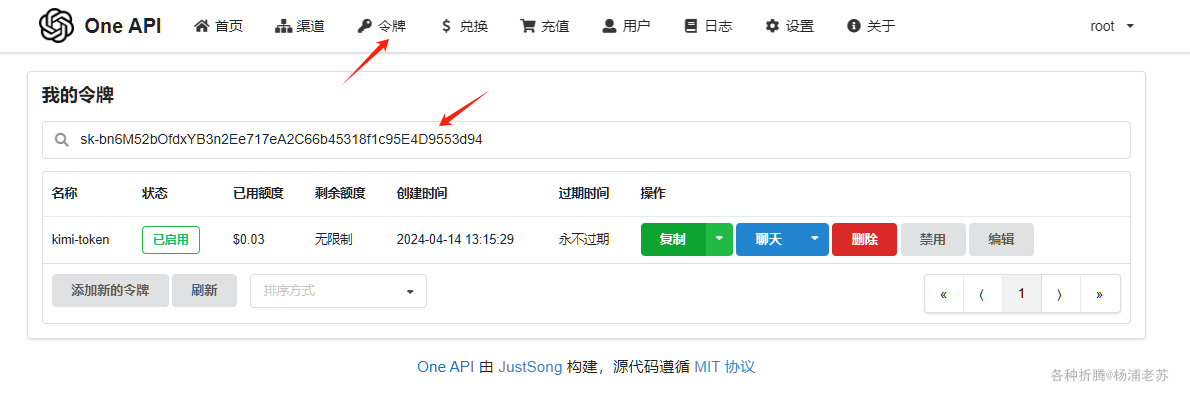
Model Names:用One API的模型名称;
输入模型名称后,需要点后面的 Add
现在的设置界面
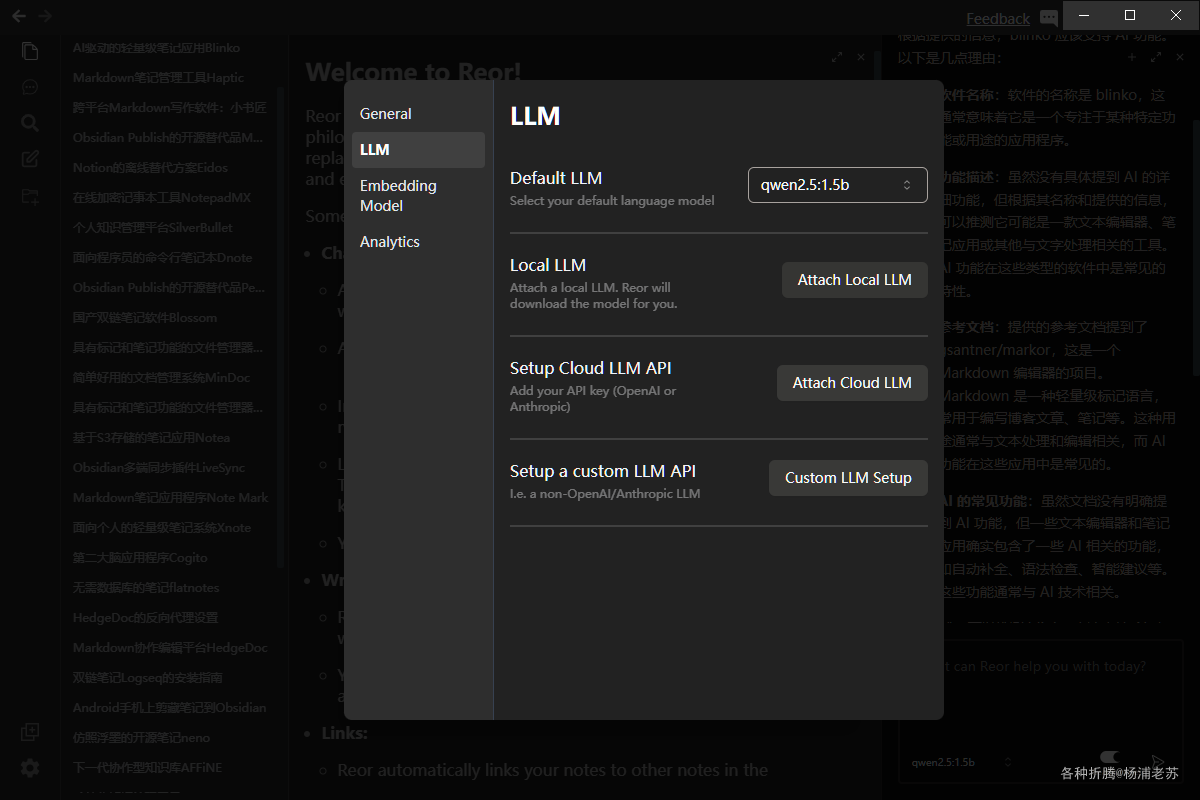
多个模型是可以切换的
本地的模型所在的目录
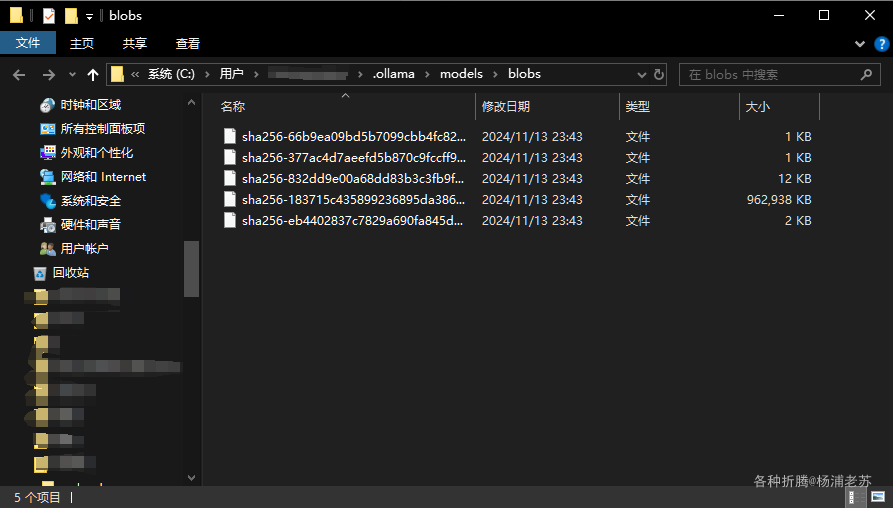
Embedding Model
Select Model 除了开始选择的默认的 UAE-Large-V1 外,还有其他的可选
但是说实话不太了解,不过从小字看,显然 jina-embeddings-v2-base-zh 更适合中文
另外,Custom Embedding Model 同样支持下载 huggingface 上的模型
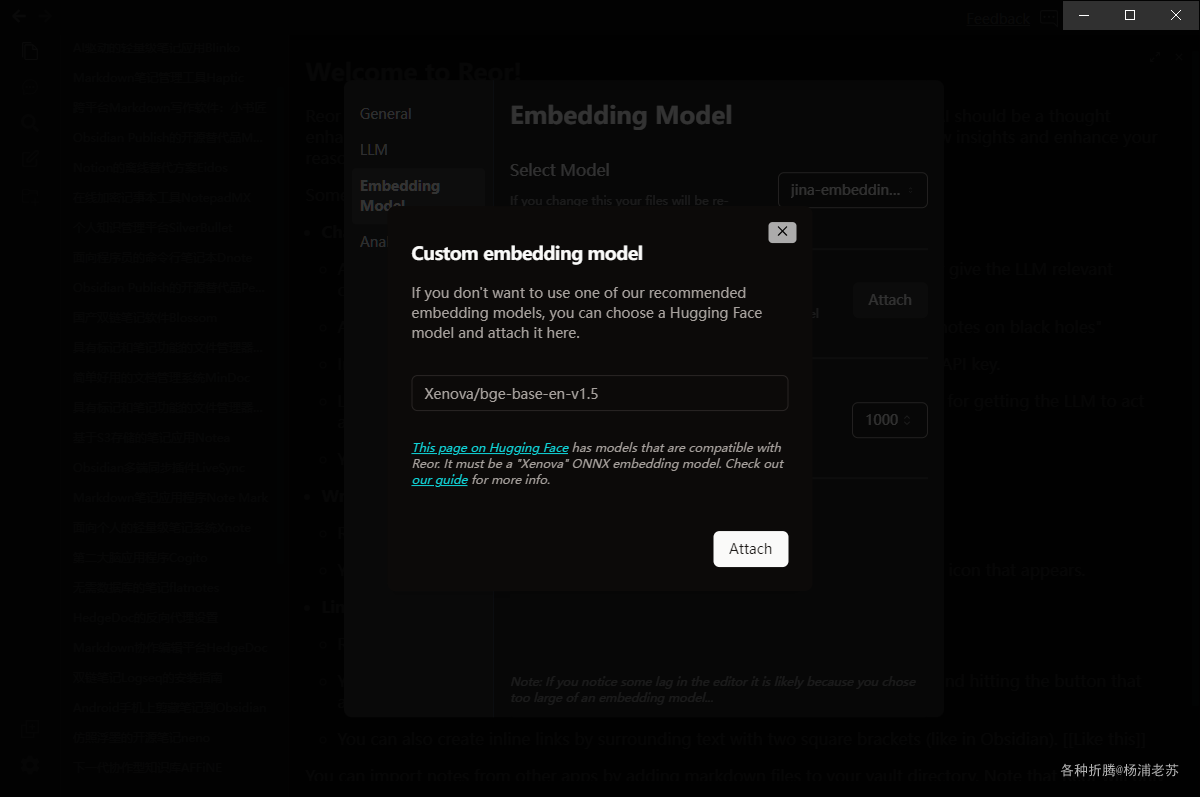
例如老苏之前安装过的 M3E
需要注意的是,如果你更换了 Embedding Model ,会重新矢量化和索引笔记,所以笔记多的话,不建议随意切换
ChatBot
点右上角的 Show ChatBot
先试试 qwen2.5 ,随便问问

继续
再用 kimi,一次不合规,一次卡死
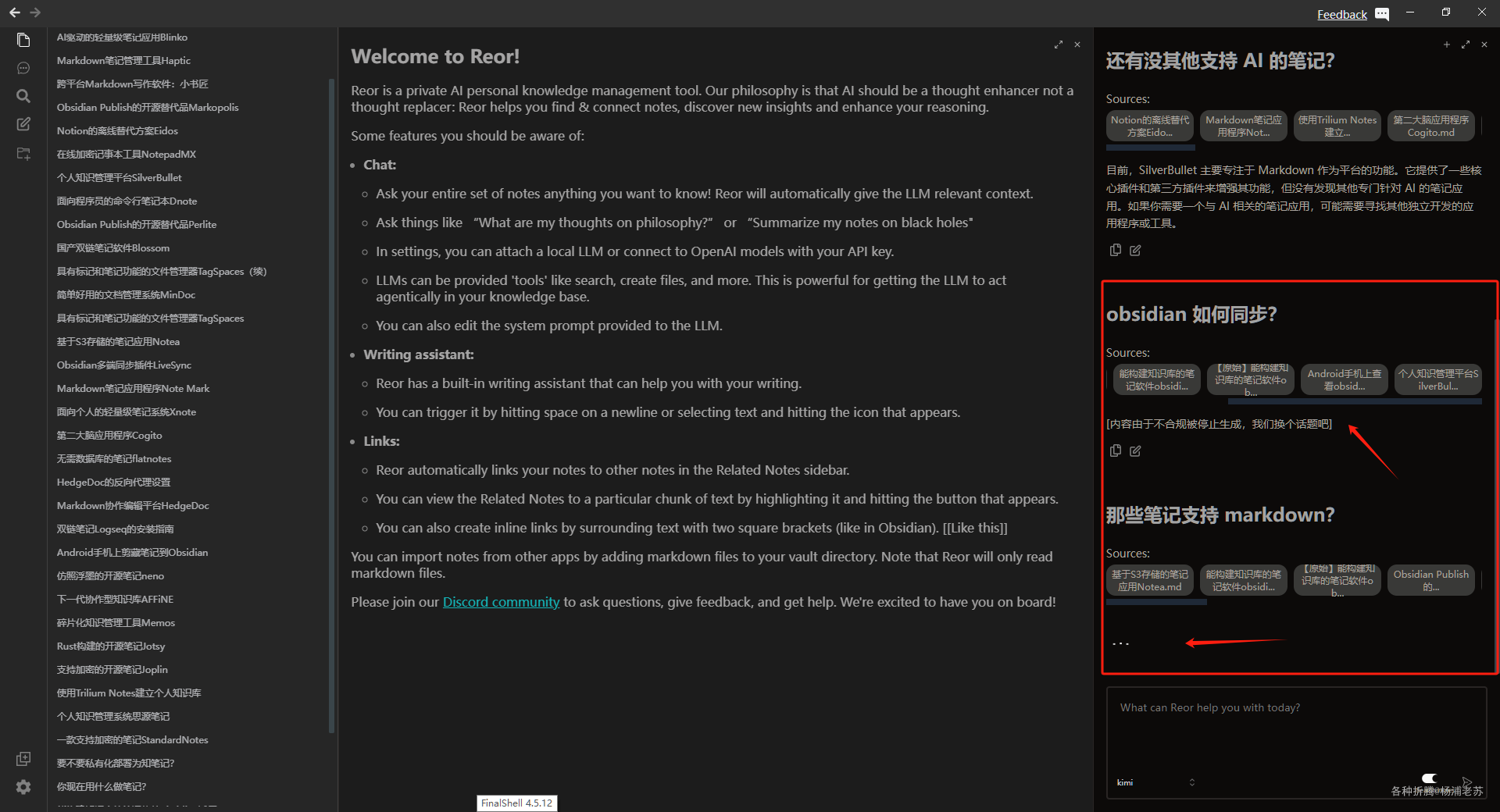
从 kimi-free-api 的日志看,提示词限定了只能从笔记里查询
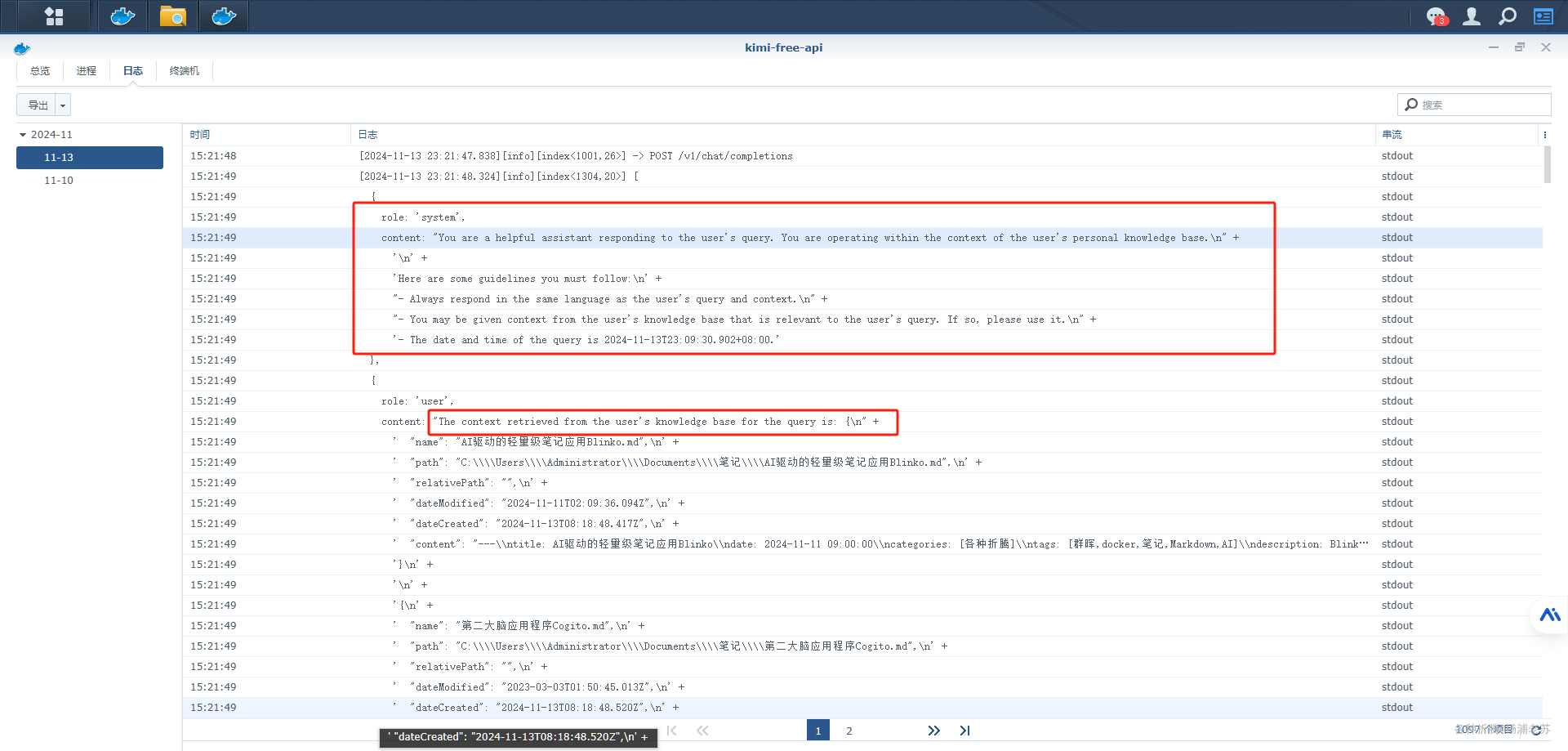
出错的原因,也许因为短时间内密集的提交,或者 token 超了
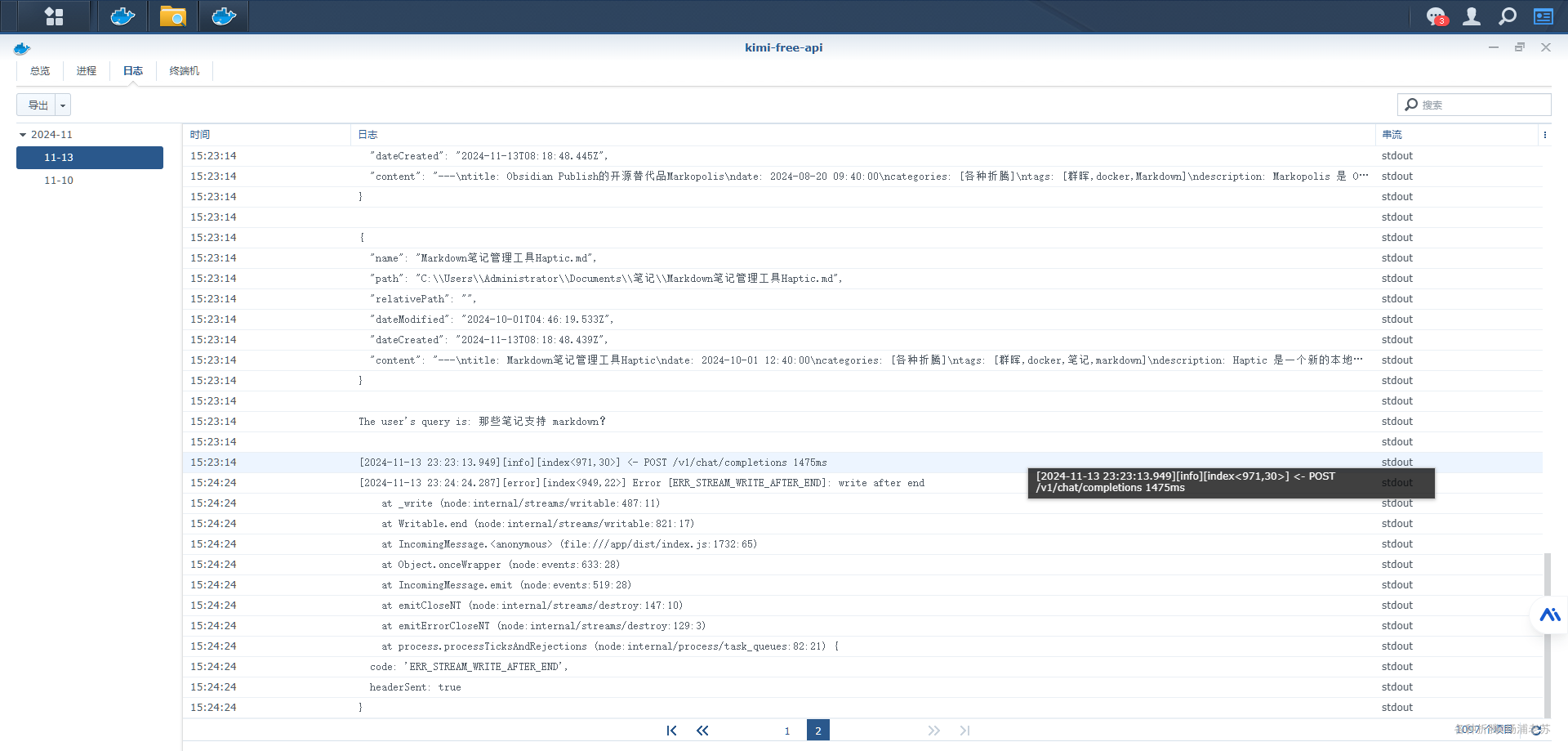
缩小范围后,果然就可以了
所以可能还是本地模型或者 ollama 更适合,毕竟自己搭建的,能限制你的只有硬件配置,而不是其他的

老苏的台式机是很古老的第六代 i7,而且是板载的显卡,但毕竟比跑群晖的 NUC 还是强多了。所以本机跑 qwen2.5:1.5b 还是很快的
最后建议跟踪功能关闭掉
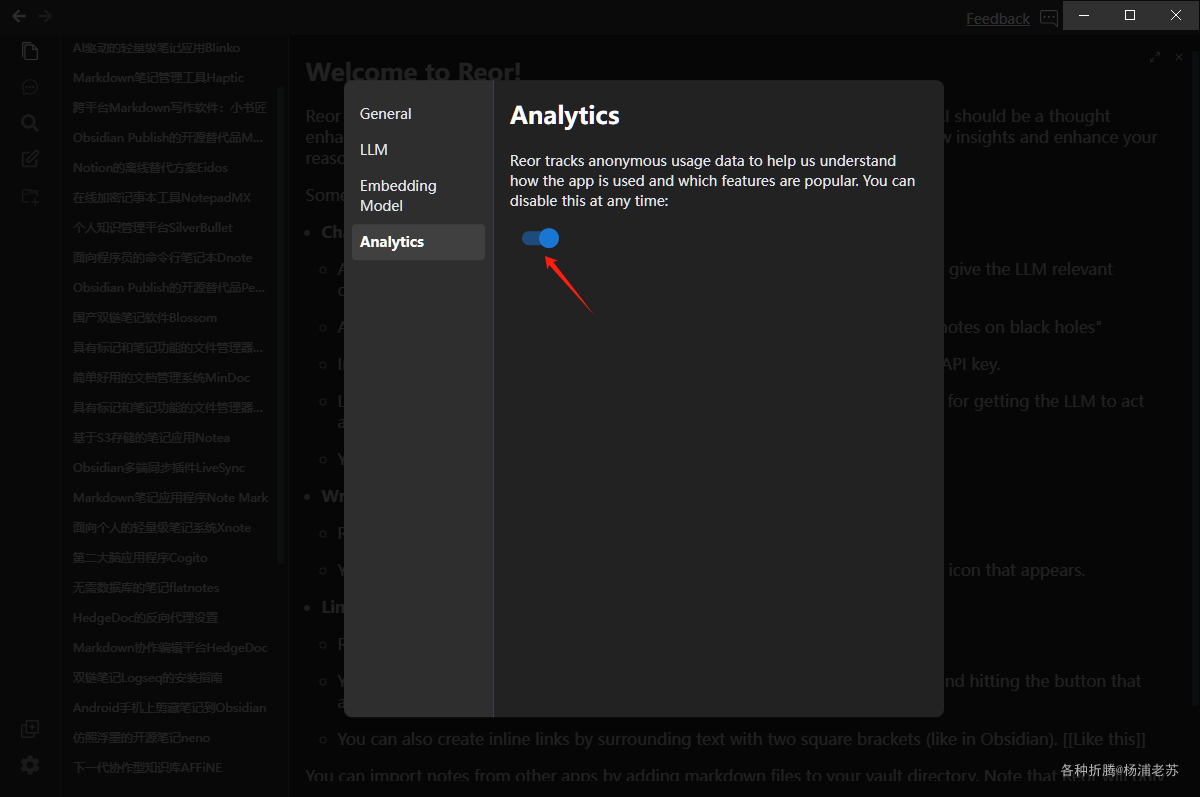
估计后续的一段时间,老苏会是 Obsiadian + Reor 的组合,因为笔记库是可以共用的,这弥补了 Reor 没有插件及其他方面的不足
参考文档
reorproject/reor: Private & local AI personal knowledge management app for high entropy thinkers.
地址:https://github.com/reorproject/reor
Reor
地址:https://www.reorproject.org/










![[HE phy]](https://i-blog.csdnimg.cn/direct/f7810c577510490d932ee25798e1e83f.png)