节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型技术趋势、算法项目落地经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
总结链接如下:
《大模型面试宝典》(2024版) 发布!
喜欢本文记得收藏、关注、点赞。技术交流见文末
本文主要使用Unsloth基于Qwen2基础模型微调对话机器人以及在Ollama上运行。
仅需要10G显存,使用Unsloth来微调Qwen2创建自定义聊天机器人,并创建GGUF文件,可以在PC端本地运行。
1 Unsloth是什么?
Unsloth是一个预训练模型微调框架,专注于提高训练速度和减少显存占用。针对现在主流模型,如Llama-3,Qwen2,Mistral等LLM的微调速度可提升2倍,内存使用量减少70%,而且准确度并不会降低!
-
所有内核均用OpenAI 的 Triton语言编写
-
准确度损失为 0%
-
通过bitsandbytes支持 4 位和 16 位 QLoRA / LoRA 微调。
-
开源训练速度提高 5 倍
-
拥有一张很酷的贴纸!所有基于Unsloth的模型都可以用这张贴纸

2 Ollama是什么?
Ollama 是一款极其简单的基于命令行的工具,用于运行 LLM,极易上手,可用于构建 AI 应用程序。本文使用Ollama作为我们的推理引擎。
3 环境安装
安装Unsloth:
!pip install "unsloth[cu121-torch230] @ git+https://github.com/unslothai/unsloth.git"
4 选择需要微调的模型
本文选择Qwen2-7B,Qwen2 是 Qwen 大型语言模型的新系列。与最先进的开源语言模型(包括之前发布的 Qwen1.5)相比,Qwen2 总体上超越了大多数开源模型,并在一系列针对语言理解、语言生成、多语言能力、编码、数学、推理等的基准测试中展现出与专有模型的竞争力。
from unsloth import FastLanguageModel
import torch
from modelscope import snapshot_download
max_seq_length = 2048
dtype = torch.bfloat16
load_in_4bit = True model_dir=snapshot_download("qwen/Qwen2-7B")
model, tokenizer = FastLanguageModel.from_pretrained(model_name = model_dir, max_seq_length = max_seq_length,dtype = dtype,load_in_4bit = load_in_4bit,
)
其中三个参数的设置:
max_seq_length = 2048
这决定了模型的上下文窗口长度,比如Qwen2-7B的上下文长度为32K,并可以通过yarn拓展到128K。本文从测试的角度,设置上下文长度为2048。
dtype = torch.bfloat16
根据A10的GPU选择torch.bfloat16
load_in_4bit = True
本文采用 4 位量化进行微调。这样可将内存使用量减少 4 倍。4 位量化本质上将权重转换为一组有限的数字以减少内存使用量。这样做的缺点是准确度会下降 1-2%。
5 微调参数
model = FastLanguageModel.get_peft_model(model,r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128target_modules = ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj",],lora_alpha = 16,lora_dropout = 0, # Supports any, but = 0 is optimizedbias = "none", # Supports any, but = "none" is optimized# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long contextrandom_state = 3407,use_rslora = False, # We support rank stabilized LoRAloftq_config = None, # And LoftQ
)
微调参数的设置目标是改变这些微调参数以提高微调的准确性,同时也不希望发生过拟合。过度拟合是指让语言模型记住数据集,而无法回答新颖的新问题。本文希望最终模型能够回答从未见过的问题,而不是进行记忆。
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
微调过程的rank。数值越大,占用的内存越多,速度越慢,但可以提高复杂任务的准确性。通常建议数值为 8(用于快速微调),最高可达 128。数值过大可能会导致过度拟合,从而损害模型的质量。
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj",],
本文选择所有模块进行微调。您可以删除一些模块以减少内存使用量并加快训练速度,但强烈不建议这样做。
lora_alpha = 16,
微调的缩放因子。较大的数字将使微调更多地了解您的数据集,但可能会导致过度拟合。建议将其等于等级r,或将其加倍。
lora_dropout = 0, # Supports any, but = 0 is optimized
将其保留为 0 以加快训练速度!可以减少过度拟合,但效果不大。
bias = "none", # Supports any, but = "none" is optimized
将其保留为 none,以实现更快、更少的过度拟合训练!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
选项包括True、False 和"unsloth"。本文建议这样做"unsloth",因为unsloth将内存使用量减少了 30%,并支持极长的上下文微调。
random_state = 3407,
确定确定性运行的次数。训练和微调需要随机数,因此设置此数字可使实验可重复。
use_rslora = False, # We support rank stabilized LoRA
高级功能可自动设置lora_alpha = 16。
loftq_config = None, # And LoftQ
高级功能可将 LoRA 矩阵初始化为权重的前 r 个奇异向量。可以在一定程度上提高准确度,但一开始会使内存使用量激增。
6 Prompt模板和数据集
现在使用 Qwen-2 的chatml格式进行对话风格微调。数据集使用 ShareGPT 风格的 Open Assistant 对话数据集。
使用 get_chat_template 函数来获取正确的聊天模板。get_chat_template 函数目前支持 zephyr、chatml、mistral、llama、alpaca、vicuna、vicuna_old 等模板。
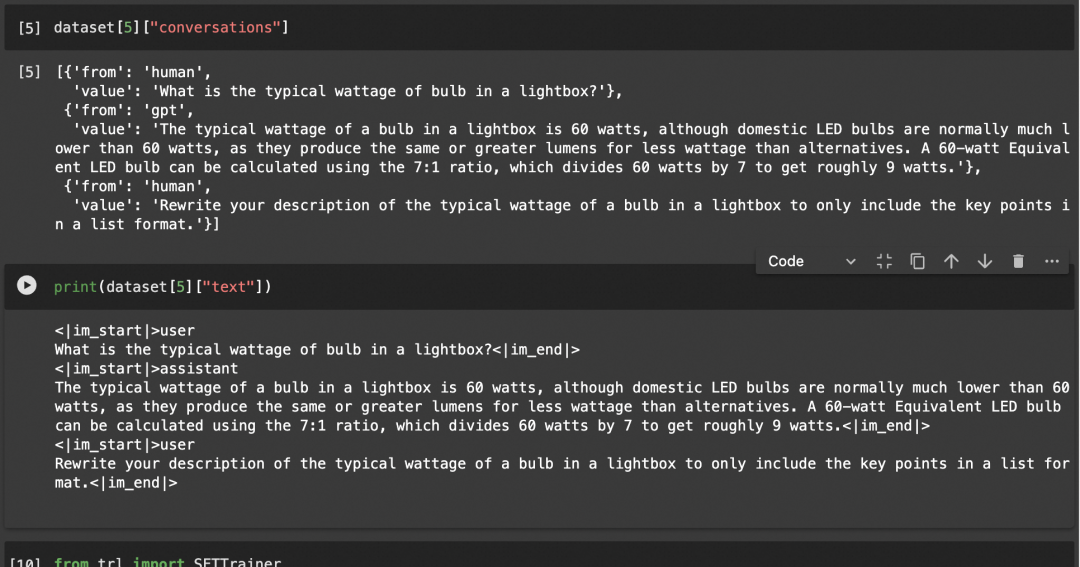
注意 ShareGPT 使用 {“from”: “human”, “value” : “Hi”} 而不是 {“role”: “user”, “content” : “Hi”},因此使用mapping做一轮映射。
from unsloth.chat_templates import get_chat_templatetokenizer = get_chat_template(tokenizer,chat_template = "chatml", # Supports zephyr, chatml, mistral, llama, alpaca, vicuna, vicuna_old, unslothmapping = {"role" : "from", "content" : "value", "user" : "human", "assistant" : "gpt"}, # ShareGPT style
)def formatting_prompts_func(examples):convos = examples["conversations"]texts = [tokenizer.apply_chat_template(convo, tokenize = False, add_generation_prompt = False) for convo in convos]return { "text" : texts, }
passfrom modelscope.msdatasets import MsDataset
dataset = MsDataset.load('OmniData/guanaco-sharegpt-style', split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)
可以看到mapping前后的数据集的具体样式:
7 训练模型
下面开始训练模型,使用huggingface的trl库
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supportedtrainer = SFTTrainer(model = model,tokenizer = tokenizer,train_dataset = dataset,dataset_text_field = "text",max_seq_length = max_seq_length,dataset_num_proc = 2,packing = False, # Can make training 5x faster for short sequences.args = TrainingArguments(per_device_train_batch_size = 2,gradient_accumulation_steps = 4,warmup_steps = 5,max_steps = 60,learning_rate = 2e-4,fp16 = not is_bfloat16_supported(),bf16 = is_bfloat16_supported(),logging_steps = 1,optim = "adamw_8bit",weight_decay = 0.01,lr_scheduler_type = "linear",seed = 3407,output_dir = "outputs",),
)
通常不建议更改上述参数,但需要详细说明其中一些参数:
per_device_train_batch_size = 2,
如果想更多地利用 GPU 的内存,请增加批处理大小。同时增加批处理大小可以使训练更加流畅,并使过程不会过度拟合。
gradient_accumulation_steps = 4,
相当于将批量大小增加到自身之上,但不会影响内存消耗!如果您想要更平滑的训练损失曲线,通常建议增加这个值。
max_steps = 60, # num_train_epochs = 1,
我们将步骤设置为 60 以加快训练速度。对于可能需要数小时的完整训练运行,请注释掉max_steps,并将其替换为num_train_epochs = 1。将其设置为 1 表示对数据集进行 1 次完整传递。通常建议传递 1 到 3 次,不要更多,否则您的微调会过度拟合。
learning_rate = 2e-4,
如果您想让微调过程变慢,但同时又最有可能收敛到更高精度的结果,请降低学习率。我们通常建议尝试 2e-4、1e-4、5e-5、2e-5 作为数字。
trainer_stats = trainer.train()
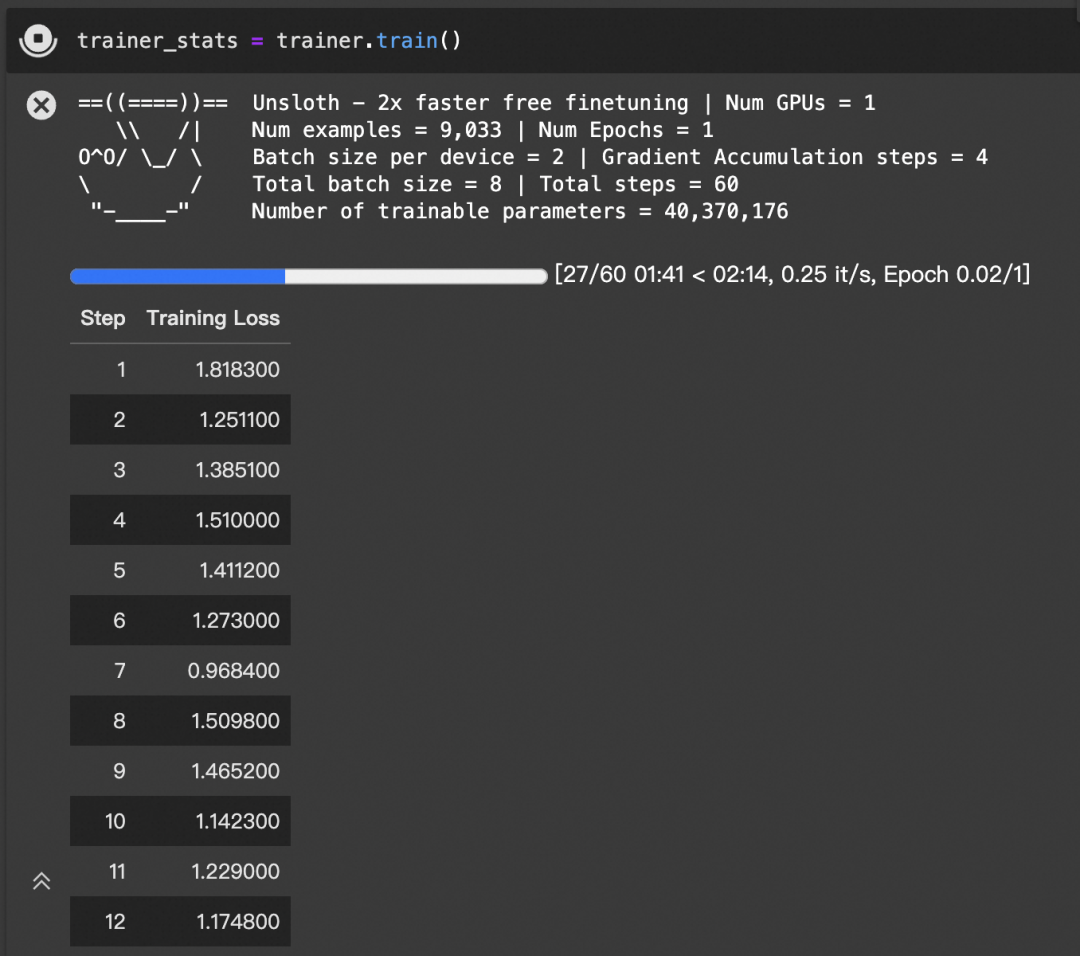
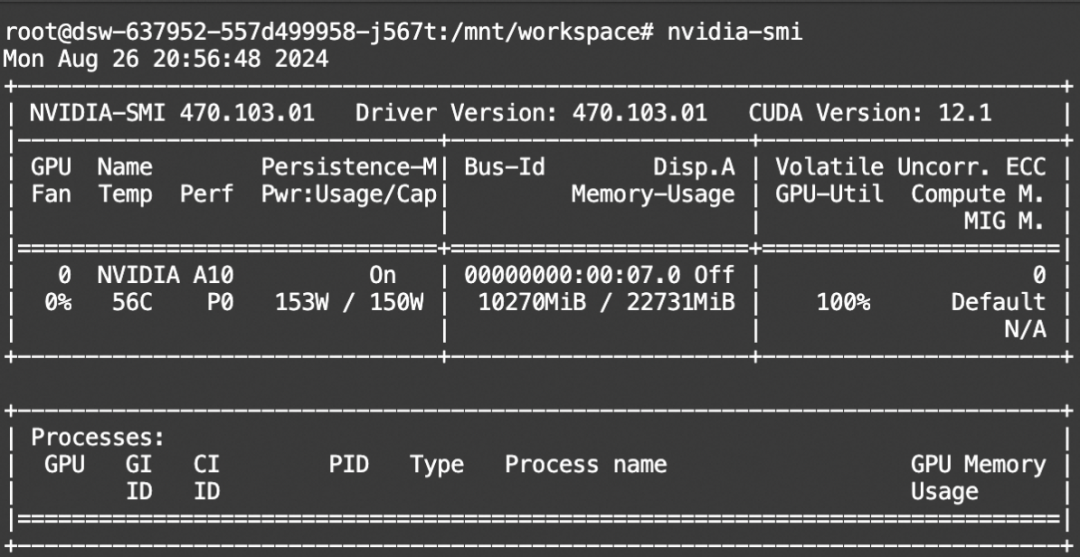
显存占用(使用Unsloth):
8. 推理/运行模型
完成训练过程后运行模型!
from unsloth.chat_templates import get_chat_templatetokenizer = get_chat_template(tokenizer,chat_template = "chatml", # Supports zephyr, chatml, mistral, llama, alpaca, vicuna, vicuna_old, unslothmapping = {"role" : "from", "content" : "value", "user" : "human", "assistant" : "gpt"}, # ShareGPT style
)FastLanguageModel.for_inference(model) # Enable native 2x faster inferencemessages = [{"from": "human", "value": "杭州的省会在哪里?"},
]
inputs = tokenizer.apply_chat_template(messages,tokenize = True,add_generation_prompt = True, # Must add for generationreturn_tensors = "pt",
).to("cuda")outputs = model.generate(input_ids = inputs, max_new_tokens = 64, use_cache = True)
tokenizer.batch_decode(outputs)
也支持流式输出:
FastLanguageModel.for_inference(model) # Enable native 2x faster inferencemessages = [{"from": "human", "value": "杭州的省会在哪里?"},
]
inputs = tokenizer.apply_chat_template(messages,tokenize = True,add_generation_prompt = True, # Must add for generationreturn_tensors = "pt",
).to("cuda")from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt = True)
_ = model.generate(input_ids = inputs, streamer = text_streamer, max_new_tokens = 128, use_cache = True)
9.保存模型
我们将微调后的模型保存到一个名叫LoRA的100MB小文件。
model.save_pretrained("lora_model") # Local saving
tokenizer.save_pretrained("lora_model")
10.导出至Ollama
最后,可以将经过微调的模型导出为GGUF格式!本文选择的量化方法是q4_k_m格式。可以前往https://github.com/ggerganov/llama.cpp了解有关 GGUF 的更多信息。
if True: model.save_pretrained_gguf("model", tokenizer, quantization_method = "q4_k_m")

11.自动创建Modelfile
Unsloth 在转化模型为GGUF格式的时候,自动生成Ollama所需的Modelfile文件,其中包括模型的路径和我们用于微调过程的聊天模板!可以打印Modelfile生成的模板,如下所示:
print(tokenizer._ollama_modelfile)
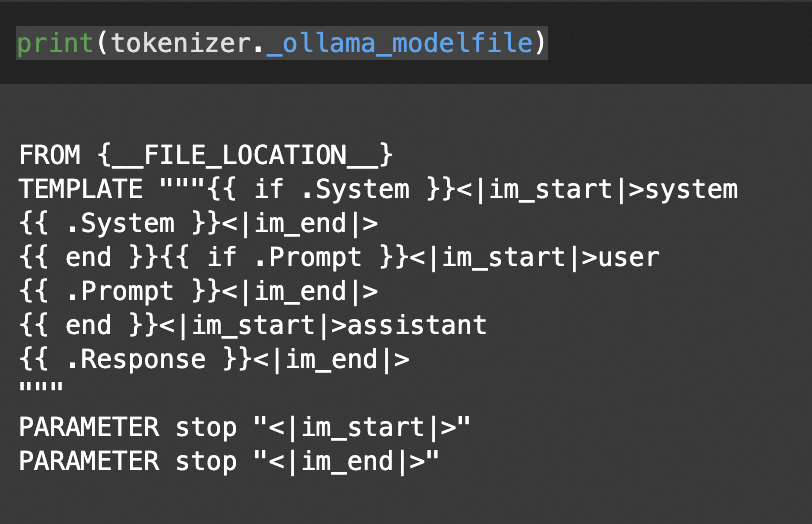
12.使用Ollama创建和推理模型
Linux环境使用
Liunx用户可使用魔搭镜像环境安装【推荐】
git clone https://www.modelscope.cn/modelscope/ollama-linux.git
cd ollama-linux
sudo chmod 777 ./ollama-modelscope-install.sh
./ollama-modelscope-install.sh
启动Ollama服务
ollama serve
创建自定义模型
使用ollama create命令创建自定义模型
!ollama create unsloth_qwen2 -f /mnt/workspace/model/Modelfile
多轮对话测试
在terminal中运行gguf模型
ollama run unsloth_qwen2
测试模型多轮对话效果:

至此,您已经成功使用Unsloth微调了Qwen2基础模型,使之具备多轮对话能力,并导出Ollama支持本地运行,显存使用10G以内。
技术交流