基于亚马逊云科技构建音频转文本无服务器应用程序
Amazon Transcribe是一项基于机器学习模型自动将语音转换为文本的服务。它提供了多种可以提高文本转录准确性的功能,例如语言自定义、内容过滤、多通道音频分析和说话人语音分割。Amazon Transcribe 可用作独立的转录服务,也可以集成到应用程序中提供语音转文本功能。您可以实时转录媒体内容(流式处理),也可以转录位于 Amazon S3存储桶中的媒体文件(批处理)。
我们将介绍如何:
- 使用 Amazon CloudFormation部署解决方案。
- 测试解决方案。
所需的 Go 库:
- Amazon Lambda 的 Go 库。
- Amazon Rekognition 的 Go SDK。
- 用于实现整个解决方案“基础设施即代码” (IaC) 的Amazon Cloud Development Kit (Amazon CDK) 的 Go 绑定 以及 Amazon CDK CLI。
应用程序简介
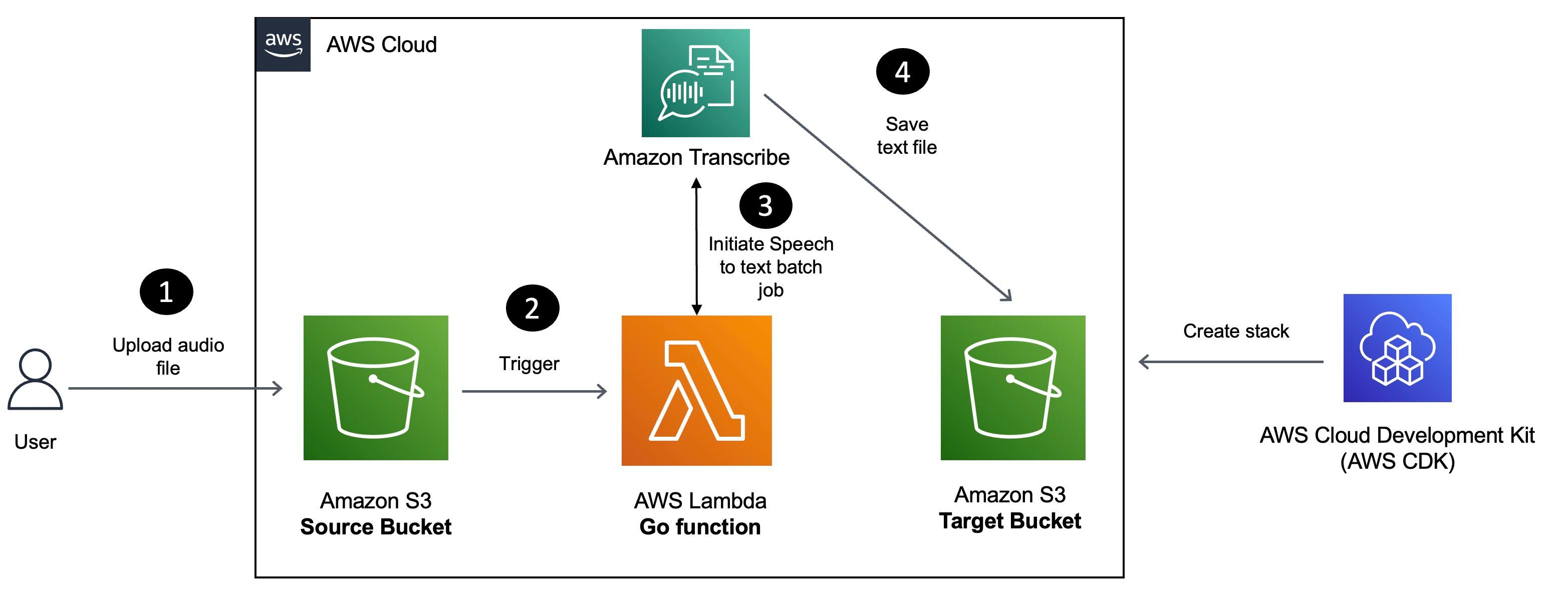
以下是该应用程序的工作原理:
- 上传 MP3 音频文件到 S3 存储桶时触发 Lambda 函数。
- Lambda 函数向 Amazon Transcribe 提交异步任务,最后 Amazon Transcribe 把生成的文件(包含转换后的文本)存储到另一个 S3 存储桶中。
前提条件
在开始本教程之前,需要满足以下条件:
-
创建并登录亚马逊云科技账户。
亚马逊云科技为开发者提供了众多免费云产品。想深入体验基于 Amazon Bedrock 部署 DeepSeek-R1 大模型,可以访问亚马逊云科技
-
Go 语言环境(v1.18 或更高版本)。
-
Amazon CDK。
-
Amazon CLI。
-
Git。
使用 Amazon CDK 部署解决方案
克隆项目并切换到正确的目录:
git clone https://github.com/build-on-aws/amazon-transcribe-lambda-golang-examplecd amazon-transcribe-lambda-golang-example
Amazon CDK 提供一个框架。您可以使用其支持的编程语言将云基础设施定义为代码,并通过 Amazon CloudFormation 进行预置。
调用 cdk deploy 开始部署。稍事等待后,界面上显示要创建的资源列表。需您确认后,流程才能继续。
cd cdkcdk deploy# outputBundling asset LambdaTranscribeAudioToTextGolangStack/audio-to-text-function/Code/Stage...✨ Synthesis time: 4.42s//.... omittedDo you wish to deploy these changes (y/n)? y
输入 y 确认。系统开始创建应用程序所需的亚马逊云科技资源。
如果您想查看后台使用的 Amazon CloudFormation 模板,请运行 cdk synth,然后查看 cdk.out 文件夹中的内容。
您可以在终端或亚马逊云科技控制台上跟踪堆栈创建进度。在控制台上,导航至CloudFormation > Stacks > LambdaTranscribeAudioToTextGolangStack查看。
创建的资源:
- 两个 S3 存储桶:源存储桶用于存储上传的音频文件,输出存储桶用于存储转录的文本文件。
- 调用 Amazon Transcribe 将音频转换为文本的 Lambda 函数。
- 以及其他资源,如 IAM 角色等。
在终端中,您将看到创建的资源。(输出中显示创建的资源名称)在本例中,CDK 创建的 S3 存储桶的名称如下:
✅ LambdaTranscribeAudioToTextGolangStack✨ Deployment time: 98.61sOutputs:
LambdaTranscribeAudioToTextGolangStack.audiofilesourcebucketname = lambdatranscribeaudiotot-audiofilesourcebucket05f-182vj224hnpfl
LambdaTranscribeAudioToTextGolangStack.transcribejobbucketname = lambdatranscribeaudiotot-transcribejoboutputbucke-1gi0bu6r1d1jn
.....
下一步,测试解决方案。
语音转文本
您可以使用自己的 MP3 音频文件来测试这个解决方案。由于我非常喜欢收听 Go Time 播客,因此我将直接使用其中一集,并使用 Amazon CLI 将其(MP3 文件)上传到 S3 源存储桶。
export SOURCE_BUCKET=<enter source S3 bucket name - check the CDK output>curl -sL https://cdn.changelog.com/uploads/gotime/267/go-time-267.mp3 | aws s3 cp - s3://$SOURCE_BUCKET/go-time-267.mp3# verify that the file was uploaded
aws s3 ls s3://$SOURCE_BUCKET
这将生成一个转录作业。您可以在亚马逊云科技控制台查看作业状态:Amazon Transcribe > Jobs。完成后,您应该会在输出 S3 存储桶中看到一个新文件,该文件与传的音频文件同名,但其扩展名为 .txt。这就是 Amazon Transcribe 生成输出的文本文件。
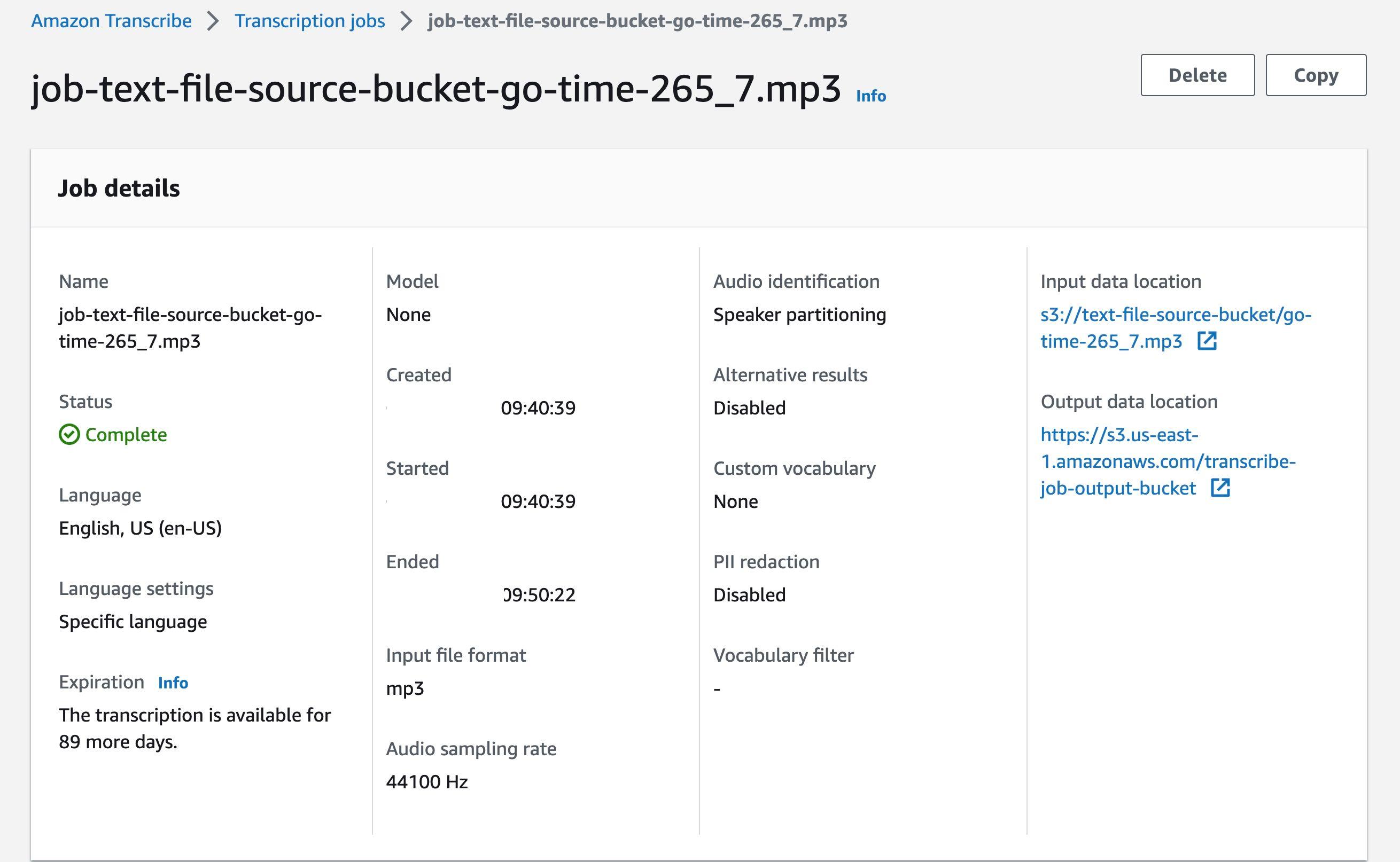
下载并打开输出文件。
export TARGET_BUCKET=<enter target S3 bucket name - check the CDK output># list contents of the target bucket
aws s3 ls s3://$TARGET_BUCKET# download the output file
aws s3 cp s3://$TARGET_BUCKET/go-time-267.txt .
文件内容包含一个 JSON payload,如下所示:
{"jobName": "job-go-time-267","accountId": "1234566789","results": {"transcripts": [{"transcript": "<transcribed text output...>"}]},"status": "COMPLETED"
}
您可以使用 transcript 属性提取实际文本。
完成端到端解决方案测试后,您可以清除实验过程中创建的资源和了解相关 Lambda 函数逻辑。
清理资源
试验完成后,运行以下命令删除实验过程中创建的资源:
cdk destroy#output prompt (choose 'y' to continue)Are you sure you want to delete: LambdaTranscribeAudioToTextGolangStack (y/n)?
Lambda 函数代码说明
以下是相关 Lambda 函数逻辑的简要介绍。注意:以下示例中省略了错误处理、日志记录等代码,只展示了关键代码部分。
func handler(ctx context.Context, s3Event events.S3Event) {for _, record := range s3Event.Records {sourceBucketName := record.S3.Bucket.NamefileName := record.S3.Object.Keyerr := audioToText(sourceBucketName, fileName)}
}
新文件上传到源存储桶时触发 Lambda 函数。Handler 函数遍历 S3 事件记录并调用 audioToText 函数。
下面是 audioToText 函数的代码。
func audioToText(sourceBucketName, fileName string) error {inputFileNameFormat := "s3://%s/%s"inputFile := fmt.Sprintf(inputFileNameFormat, sourceBucketName, fileName)languageCode := "en-US"jobName := "job-" + sourceBucketName + "-" + fileNameoutputFileName := strings.Split(fileName, ".")[0] + "-job-output.txt"_, err := transcribeClient.StartTranscriptionJob(context.Background(), &transcribe.StartTranscriptionJobInput{TranscriptionJobName: &jobName,LanguageCode: types.LanguageCode(languageCode),MediaFormat: types.MediaFormatMp3,Media: &types.Media{MediaFileUri: &inputFile,},OutputBucketName: aws.String(outputBucket),OutputKey: aws.String(outputFileName),Settings: &types.Settings{ShowSpeakerLabels: aws.Bool(true),MaxSpeakerLabels: aws.Int32(5),},})return nil
}
- audioToText 函数将一个转录作业提交到 Amazon Transcribe。
- 转录作业配置中指定将转录结果输出到输出 S3 存储桶。
注意:输出文件的名称根据输入文件的名称派生。
总结
使用 Amazon CDK 部署了 Go Lambda 函数,用 Amazon Transcribe 将音频转换为文本,并将结果存储在另一个 S3 存储桶中。您可以尝试以下几项措施来扩展此解决方案:
- 再构建一个由输出存储桶中的转录输出文件触发的 Lambda 函数,解析输出文件中的 JSON 内容并提取转录的文本。
- 使用 Amazon Transcribe Streaming实时生成转录文本。