[Lc day] 滑动窗口 | hash | 前缀和 | 维护区间最值子数组

题解
- 滑动窗口初始化
-
right从0开始遍历整个数组- 使用标准的滑动窗口双指针结构
- 哈希表更新逻辑
-
- 添加
hash[nums[right]]++更新元素出现次数 - 使用
if(hash[...]++ == 0)自动统计不同元素数量
- 添加
- 结果计算优化
-
- 当窗口满足条件时,所有以当前right为结尾的子数组都有效
- 直接通过
n - right计算有效子数组数量(优化时间复杂度到O(n))
说明: 该实现采用滑动窗口法,时间复杂度O(n),空间复杂度O(n)。
当窗口包含所有不同元素时,右端点固定时左端点可以移动到当前left位置,此时产生的有效子数组数为 n - right(因为后续所有元素都会保持窗口有效性)。
class Solution {
public:int countCompleteSubarrays(vector<int>& nums) {unordered_set<int> set;for(int& num:nums){set.insert(num);}int len=set.size();int n=nums.size();unordered_map<int,int> hash;int left=0,count=0,res=0;for(int right=0;right<n;right++){if(hash[nums[right]]++==0)count++;//满足条件的话while(count==len){res+=n-right; //统计//!!!计算 有效子数组if(--hash[nums[left]]==0)count--; //还原left++; //收缩}}return res;}
};

暴力:
class Solution {typedef long long ll;
public:long long countInterestingSubarrays(vector<int>& nums, int modulo, int k) {ll ret;int n=nums.size();for(int left=0;left<n;left++){int cnt=0;for(int right=left;right<n;right++){if(nums[right]%modulo==k)cnt++;if(cnt%modulo==k)ret++;}}return ret; }
};超时

- 双重循环的时间复杂度是O(n²),当nums的长度达到1e5时,这样的算法会导致超时。
- 因此,必须找到一种更高效的方法,比如O(n)或O(n log n)的算法
优化:
将双重循环的暴力解法优化为线性时间复杂度。
用前缀和+哈希表统计余数出现次数
class Solution {
public:long long countInterestingSubarrays(vector<int>& nums, int modulo, int k) {
//类似于 两数之和
//想到 hash+数学转化 就简单了int n = nums.size();vector<int> dp(n + 1);unordered_map<int, int> hash;hash[0] = 1;long long ret = 0;for(int i = 1; i <= n; i++){dp[i] = dp[i - 1] + (nums[i - 1] % modulo == k);int x = dp[i] % modulo;int y = (x - k + modulo) % modulo;if(hash.count(y)) ret += hash[y];hash[x]++;}return ret;}
};题解
- 前缀和+hash优化
1.将原始数组转换为二进制标记数组,创建哈希表记录前缀和余数出现的次数。
2.利用 余数的性质,数学转化一下:之前的前缀和(target) ≡ (当前前缀和 -k) % modulo(转换是为了便于哈希查找)
3.ret+=hash[target(余数)],更新哈希表
核心公式:
对于子数组nums[j...i],要满足:
(前缀和[i] - 前缀和[j]) % modulo == k
即:
前缀和[j] ≡ (前缀和[i] - k) (mod modulo)
通过哈希表快速查找符合条件的j的数量,实现高效统计。
总结:转化为前缀和(cnt), 模modulo的情况,并通过哈希表来记录余数的出现次数。
拓展:例如和为k的子数组数目,或者和模某个数的问题。例如,560题(和为k的子数组)和974题(和可被K整除的子数组)的处理方法。

代码:
class Solution {
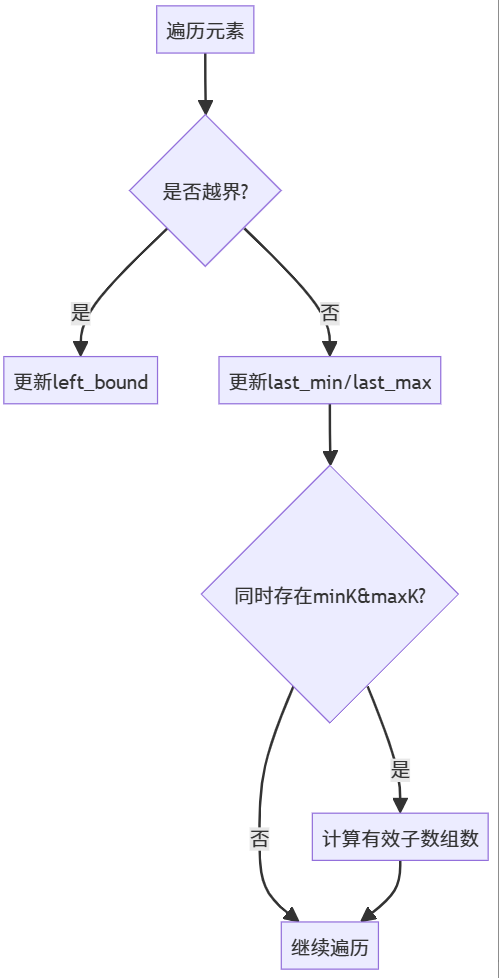
public:long long countSubarrays(vector<int>& nums, int minK, int maxK) {int n = nums.size();long long ret = 0;int left_bd = 0; // 有效子数组的起始边界int last_min = -1, last_max = -1; // 必须初始化为-1(未找到状态)for(int i = 0; i < n; i++) {// 越界处理if(nums[i] < minK || nums[i] > maxK) {left_bd = i + 1; // 新子数组只能从i+1开始last_min = last_max = -1; //重新标记continue;}// 边界更新if(nums[i] == minK) last_min = i;if(nums[i] == maxK) last_max = i;// 当两个目标值都已包含 时计算if(last_min != -1 && last_max != -1) {// 有效子数组的左边界是left_bd,右边界是i// 必须包含最近的minK和maxKret += max(0, min(last_min, last_max) - left_bd + 1);}}return ret;}
};题解

- 遍历
for(int i=0; ...) - 核心算法重构
不用 dp, 追踪三个关键位置即可:
-
left_bound:最近越界元素位置(子数组左边界)last_min:最近的minK出现位置last_max:最近的maxK出现位置
- 条件判断修正
❌minN >= minK && maxN <= maxK
-
- 应为必须同时包含minK和maxK(通过last_min/last_max判断)
- 需要严格满足
nums[i]在[minK, maxK]范围内
- 计算结果方式
当同时存在minK和maxK时,有效子数组左边界为:
max(left_bound, min(last_min, last_max))
算法可视化
复杂度对比
该解法通过维护关键边界位置,在单次遍历中高效完成统计,符合题目要求的:
- 必须同时包含minK和maxK
- 所有元素必须在[minK, maxK]范围内
- 统计所有满足条件的连续子数组
常见问题解答
- 为什么用
min(last_min, last_max)?
子数组必须同时包含两个极值,因此左边界不能超过更早出现的那个极值 - 为什么越界时设置
left_bd = i+1?
因为越界元素本身不能出现在任何有效子数组中,下一个可能有效的子数组只能从i+1开始 - 如何处理多个minK/maxK的情况?
算法自动记录最后出现的位置,确保子数组必须包含至少一个minK和一个maxK
统计同时包含最小值和最大值的连续子数组
用「快递站选址」类比
📦 核心思想
想象我们要在一条街道(数组)上选快递站(子数组),要求:
- 必须同时有顺丰站点(minK)和京东站点(maxK)
- 整个区域不能有违建(数值必须在[minK, maxK]之间)
ret += max(0, min(last_min, last_max) - left_bd + 1);这行代码相当于在说:当前能开多少个同时包含两家快递站的合规店铺?
📍 关键参数对照表
| 变量名 | 快递站比喻 | 示例(nums = [1,3,5,2,7,5]) |
|
| 最近的违建位置+1(合法区域起点) | 当i=4(7越界)时,left_bd=5 |
|
| 最近的顺丰站点位置 | 遍历到i=2时,last_min=0 |
|
| 最近的京东站点位置 | 遍历到i=2时,last_max=2 |
🧩 分步拆解(以i=3时的计算为例)
// 当前状态:
last_min = 0(顺丰在0号位)
last_max = 2(京东在2号位)
left_bd = 0(没有违建)
i = 3(当前处理2号位置的值2)ret += min(0,2) - 0 + 1 → 0-0+1=1这相当于计算:从合法起点到最早快递站之间能开多少分店?
💡 为什么要用min(last_min, last_max)?
假设顺丰在5号位,京东在3号位:
街道: [1, 3, 5, 2, 7, 5]↑京东 ↑顺丰必须保证分店包含两家快递站,所以左边界不能超过京东的位置3(更早出现的关键站点)
🚧 边界情况处理
当遇到违建(越界值)时:
nums[i] = 7 → 越界!
left_bd = i+1 = 5 // 新分店只能从5号位开始
last_min = last_max = -1 // 清空快递站记录这相当于说:7号位置有城管检查,之后的分店必须从5号位之后开始
🌰 模拟
输入:nums = [1,3,5,2,7,5], minK=1, maxK=5
| i | 值 | left_bd | last_min | last_max | 新增ret | 解释 |
| 0 | 1 | 0 | 0 | -1 | 0 | 只有顺丰 |
| 1 | 3 | 0 | 0 | -1 | 0 | 缺京东 |
| 2 | 5 | 0 | 0 | 2 | +1 | [0-2]区间有效 |
| 3 | 2 | 0 | 0 | 2 | +1 | [0-3]有效 |
| 4 | 7 | 5 | -1 | -1 | 0 | 遇到违建 |
| 5 | 5 | 5 | -1 | 5 | 0 | 缺顺丰 |
最终ret=2 ✔️ 对应两个有效子数组:[1,3,5]和[1,3,5,2]
📝 公式记忆口诀
双站齐全才能算(last_min和last_max都存在)
左界取大防越界(max(0, min(...)))
右界当前i位置
区间长度加1计(+1处理闭区间)