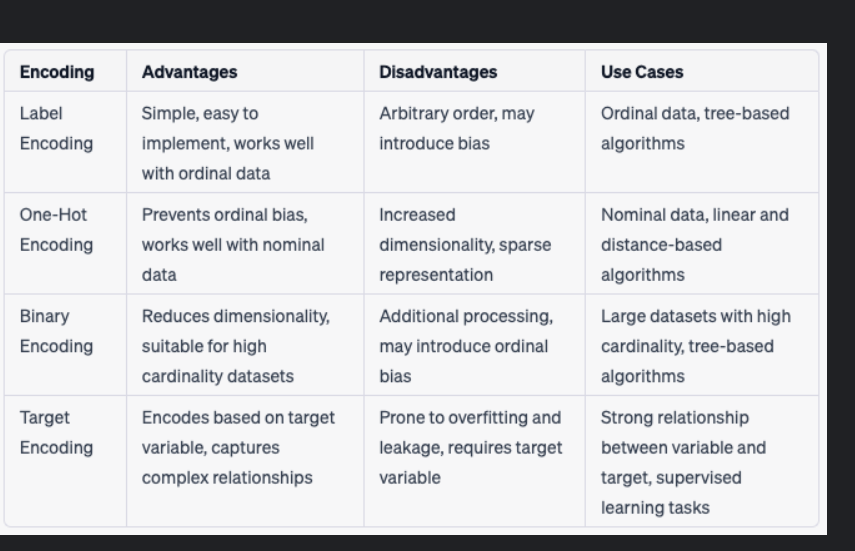
GPT1-GPT3论文理解
视频参考:https://www.bilibili.com/video/BV1AF411b7xQ/?spm_id_from=333.788&vd_source=cdb0bc0dda1dccea0b8dc91485ef3e74
1 历史
2017.6 Transformer
2018.6 GPT
2018.10 BERT
2019.2 GPT-2
2020.5 GPT-3
GPT核心技术:将Transformer的解码器拿出来,在没有标号的大量文本数据上训练一个语言模型,来获得一个预训练模型,再用其再子任务上进行微调得到每一个任务所要的分类器。
BERT:将Transformer的编码器拿出来,收集一个更大的数据集用来做预训练,结果效果比GPT好很多。
- 模型1:BERTBASE,与GPT的模型大小一样
- 模型2:BERTLARGE,比BERTBASE大一些
GPT2:搜集了更大的数据集,训练了一个更大的模型。比BERTLARGE还要大。继续使用transformer的解码器来深入挖掘语言模型的潜力,这个非常适合做zero shot。
GPT3:比GPT2数据和模型都大了一百倍,暴力出奇迹,效果非常惊艳。
Transformer与BERT都来自Google的团队,一开始想解决的问题比较小,Transformer想解决机器翻译(从一个序列翻译到另一个序列),BERT想把计算机视觉那个成熟的先训练一个预训练模型,然后再做微调子任务的结果。
GPT系列文章来自OpenAI团队,OPenAI想解决更大的问题,所以在选择问题上大一点。
2 GPT1
论文:Improving Language Understanding by Generative Pre-Training(使用通用的预训练来提升语言的理解能力)
论文链接:language_understanding_paper.pdf
摘要
自然语言理解包括各种不同的任务,如文本关联、问题解答、语义相似性评估和文档分类。虽然大量未标注的文本语料库非常丰富,但用于学习这些特定任务的标注数据却非常稀少,这使得经过鉴别训练的模型难以充分发挥作用。我们证明,通过在各种未标注文本语料库上对语言模型进行生成性预训练,然后在每个特定任务上进行判别性微调,可以在这些任务上取得巨大的收益。与以往的方法不同,我们在微调过程中利用任务感知输入转换来实现有效的转移,同时只需对模型架构做最小的改动。我们在各种自然语言理解基准上证明了我们方法的有效性。在所研究的 12 项任务中,我们的通用任务无关模型在 9 项任务中的表现明显优于使用专为每项任务设计的架构的判别训练模型。例如,我们在常识推理(Stories Cloze Test)、问题解答(RACE)和文本引申(MultiNLI)方面分别取得了 8.9% 和 5.7% 的绝对改进。
注:ImageNe有标号的图片和文字对应关系的数据集,100万的量。换算到文本,1张图片的信息对等于10个句子,意味着自然语言处理需要1000万的标好的数据集才能够进行训练。之前都是计算机视觉在引领潮流,现在来到了自然语言处理届,然后很多创新优惠反馈回CV。
CLIP打通了文本和图像。
2.1 介绍
如何更好的利用无监督的文本,当时最成功的模型还是词嵌入模型。
用没有标号文本的时候遇到的一些困难:一是不知道用什么样的优化目标函数,二是如何有效的将学到的文本表示传递到下游的子任务中。NLP里的子任务差别较大,没有一个简单统一有效的方式使得一种表示能够一致的牵引到多有的子任务上面。
提出了一个半监督的方法,即半监督学习,在没有标号的文本上训练一个表较大的语言模型,再在子任务上进行微调。
其核心思想:我有一些标好的数据,但我还有大量的相似的没有标好的数据,我怎么样把这些没有标好的数据用过来,这就是半监督学习想学习的东西。
半监督学习现在被统称为自监督学习(Self supervised Learning)
CLIP里面也是同样的算法。
所用模型:1、基于Transformer架构,transformer里面有更结构化的记忆,使得能够处理更长的这些文本信息,从而抽取出更好的句子层面和段落层面的语义信息。2、在迁移时,用的是一个任务相关的输入的一个表示
2.2 相关工作
NLP里面半监督是什么
无监督的运行模型
在训练时需要使用多个目标函数的时候会如何
2.3 模型框架
三小节:1、如何在没有标号的数据上训练模型。2、如何做微调。3、如何对每个子任务表示我的输入
2.3.1 无监督预训练
GPT使用多层Transformer的解码器,只对前预测,预测第i个词的时候,只看当前词和词之前的信息,不看后面的词。
transformer:编码器和解码器(编码器:一个序列进来,对第i个元素抽特征时,它能够看到整个序列里面所有的元素。解码器:因为掩码的存在,所以对第i个元素抽特征的时候,只会看到当前元素和他之前的这些元素,后面那些元素通过一个掩码使得在计算机注意力机制的时候变成0,所以不看后面的内容)
Bert是完形填空,将一个句子的中间的一个词挖掉,预测中间的。预测时既能看见它之前的词又能看见之后的词。所以其可以对应的使用transformer的编码器。
GPT是预测未来(预测开放式的结局)。
比如股票的信息,这是作者为何一直不断的把模型做大,一直不断努力最后才能做出GPT3。选择了更难的技术路线,但很可能天花板就更高。
2.3.2 监督微调
微调任务里是有标号的,具体而言,每次给一个长为m的一个词的序列,序列对应的标号是y,即每次给这个序列去预测y。
做法:将整个这个序列放入之前训练好的GPT模型里,得到transformer块最后一层的输出对应的h_m这个词的输出,然后再乘以一个输出层,然后再做一个softmax就得到其概率。
2.3.3 特定于任务的输入变换
26:20
NLP四大常见应用:
第一行是分类,给一句话判断它对应的标号。
第二行是蕴含,下一句的假设是否被上一句的事实所支持。比如上一句是A送B玫瑰,下一句是A喜欢B。
第三行是相似,判断两段文字是否相似。
第四行是多选题,选答案。算置信度,选最大的那个。都可以构造成序列,预训练好Transformer的模型不变。
2.4 实验
1、在BookCorpus的一个数据集上训练出来
2、模型大小:用的12层解码器,每一层768个维度。
3 BERT
BERT采用的数据集:BookCorpus(800M)和Wikipedia(2500M),总体数据是GPT数据集4倍
其训练的模型比GPT大三倍
4 GPT2
论文:Language Models are Unsupervised Multitask Learners(语言模型是无监督的多任务学习器)
4.1 介绍
GPT-2 15亿参数
百万网页的数据集:WebText。
Zero-Shot:
现在的模型,泛化性不好,一个数据集在一个应用上面不错,但不好应用在另一个应用。举例,我拿来写情书OK,但写PRD不OK。
Multitask Learning,多任务学习,训练一个模型的时候,同时看多个数据集,使用多个损失函数来达到一个模式能够在多个任务上都能用。但在NLP上用的不多。
目前主流的:在一个比较大的数据集上做一个预训练模型,然后再对每一个任务做有监督的学习的微调。出现的问题:1、对于每一个下游任务都需要重新训练模型进行微调,2、要导入有标号的数据。
继续做语言模型,但在做下游任务时,用Zero-Shot的设定,它不需要下游任务的任何标注的信息,也不需要训练我的模型。
4.2 方法
基本上与GPT1一样
gpt:在自然的文本上训练的,在下游任务的时候对他的输入进行了构造,加入了开始符,结束符和中间的分隔符。
用了zero-shot之后不能引入模型没有见过的符号
4.2.1 训练数据集
采用Common Crawl(公开的网页抓取的项目),这是有一群人写的一个网络爬虫,不断的去网上抓取网页,将抓取的网页放在aws的s3上面,供大家免费下载。目前时TB级的数量级,但其数据信噪比比较低,数据需要清洗,很麻烦。
后面用Reddit,是美国排名很靠前的一个新闻聚合网页,大家可以自主的放网页上去,大家可以投票,投票后产生Karma,是用户对帖子的评价,选取有3个Karma的帖子,拿到4500万的链接,一共有800万个文档,40GB的文字
GPT2在很多任务上得分并不高,更多地看起来还是在讲Zero-Shot的问题。
5 GPT3
论文:Language Models are Few-shot Learners(语言模型是few shot learners)
论文链接:[2005.14165] Language Models are Few-Shot Learners (arxiv.org)
GPT2在子任务上不提供任何的样本,直接使用预训练模型去对子任务做预测。一篇论文的价值取决于你的新意度、有效性、问题的大小。所以还是要回到few-shot上面来,
摘要
训练了一个GPT3的模型,是一个自回归模型,它有1750亿个可学习的参数。GPT3在作用到子任务上的时候不做任何的梯度更新或者微调。
GPT3可以生成一些新闻的文章,人类很难分辨。
GPT3是完全基于GPT2这个模型
5.1 介绍
近年来NLP都是使用预训练好的语言模型,然后再做微调。这当然是有问题的,我们对每个子任务还是需要一个跟任务相关的数据集,还有跟任务相关的一个微调,具体问题如下:
微调问题:
- 对于每一次都需要一些标号的数据;
- 微调效果好,不一定模型的泛化性能好
- 人类不需要很大的数据集来学会绝大部分的语言任务
“In-Context learning”:GPT3因为模型太大了,更新不了,所以不会去更新所谓的权重。
评估GPT3:
- few-shot:每个子任务提供10-100个训练样本;
- one-shot:1个样本
- zero-shot:0个样本
5.2 方法
讲述了fine-tuning和zero-shot,one-shot,few-shot
zero-shot:设置prompt(提示)
one-shot:在任务描述后,在真正做翻译之前,插入一个样本,只是做预测,不做训练,虽然它是一个训练样本,但是它放进去之后不会对模型计算梯度,也不会对模型做更新。所以它希望的是在模型做前向推理的时候能够通过注意力机制去处理比较长的序列信息,从而从中间抽取出有用的信息来帮助下面做事情,这也就是为什么叫上下文学习,就是你的学习只是限于你的上下文。
few-shot:是对one-shot的一个拓展,给多个样本
5.2.1 模型和架构
基本结构和gpt2一样,但是还用了一个sparse transformer的结构
5.2.2 训练数据集
common crawl(一种数据,但是其数据比较脏)
采用三种方法让其干净:1、过滤了一个版本,基于相似性和一个更高的一个数据集。2、去重,LSH。3、加入一些已知的高质量的数据集
GPT3局限性
长文本比较弱,写小说就不行。
结构和算法上的局限性,只能往前看。
对于词的预测是平均的,不知道什么词才是重点。虚词。
视频、真实世界的物理交互是无法理解的
样本有效性不够,训练起来非常的贵
无法解释,不知道为何得出的输出
负面:
- 可能会被用来做坏事
- 散布一些不实的消息
- 论文造假
- 公平性、偏见
- 性别







![[Python]一、Python基础编程(2)](https://i-blog.csdnimg.cn/direct/c074f9e8d9674c2e93ce791b9f02d482.png)