LeadeRobot具身智能应用标杆:无人机X柔韧具身智能,空中精准作业游刃有余
当前,具身智能已成为全球科技领域的前沿焦点,更受到国家战略级重视,吸引科技产业巨头抢滩布局。但同时,具身智能的商业化路径、规模化应用场景、技术成本等难题也开始在资本界与产业圈引起广泛讨论。
目前,万勋科技基于Pliabot® 柔韧技术已推出多款具身智能柔韧机器人产品,在柔性硬件+视触觉AI能力的加持下,能安全适应各种环境变化,可以长期在户外和极端、高危条件下,辅助人类开展各种交互类作业,已广泛应用于建筑清洗、能源运维、新能源汽车等多个行业。基于此,4月15日,凭借具身智能柔性机器人产品在无人机空中精准作业与新能源汽车无人化补能两大领域的创新应用与商业化落地,万勋科技荣获第二届LeadeRobot机器人与具身智能行业2025年度评选「具身智能应用标杆引领奖」。

在低空经济场景中,无人机是重要的应用工具。然而,现阶段行业内的无人机空中作业方案优化大多侧重于无人机技术本身,如稳定性、续航能力等,受限于常规技术框架,难以搭载更为复杂、高性能的作业装置乃至机器人系统,作业能力提升进展缓慢,应用场景集中在非接触式的基础任务层面,如巡检、绘图、监测监控、简单运输等,存在严重同质化。
随着各行各业日益增长且趋于复杂化的空中作业需求,空中作业机器人的出现带来了新的发展方向。作为一种创新形态,空中作业机器人本质上是无人机与机器人的结合,为智能机器人插上了一双翅膀,让其既拥有快速空间移动能力,也拥有精确操纵能力,极大地拓宽了应用场景。
相较于普通无人机,空中作业机器人最核心的优势在于其具备精确的操纵能力和环境交互能力,因此更适合强交互性的应用场景。例如接触式检测、精准操控、装配、清洁、主动抓取/释放等。
但是,目前行业内比较常见的空中作业机器人解决方案,普遍是将简单的机械臂、夹爪或高压水枪等特定的末端工具搭载到无人机上。这种“外挂+无人机本体”的简单叠加,不仅只能用于特定的作用场景,无法大规模普及,还在安全性、灵活性等方面存在巨大风险。另一方面,具备一定作业能力的传统机器人技术也因负重比低、自由度不足,缺少柔韧性、功耗偏高等固有缺陷,即便能够无人机进行整合,作业效果、效率也难以满足实际需求。
柔性具身架构赋能
无人机空中精准作业极致安全、高效多能
为提升空中作业能力的安全性、泛化性、灵活性,依托独有的Pliabot®柔韧技术,万勋科技在业内首创了“柔韧机器人+无人机”应用模式,赋予无人机精准作业能力与环境智能适应能力,让无人机“不怕碰、不怕撞”,在悬停/飞行状态下完成多种安全、无损的接触式精准作业。

基于Pliabot®柔韧技术打造的柔韧机器人,以“神经元具身智能+柔韧肌肉”双螺旋驱动,构成柔性具身架构,在柔性硬件+视触觉AI能力的加持下,具备原生主被动适应能力、原生碰撞安全、超高负重比等独特性能,能对环境自主感知,并灵活调整姿态、力度、运动模式等,实现与各种环境变化的自适应安全互动,进而在户外和极端、高危条件下,开展各种空中交互式作业,满足多行业和场景的应用需求。
以无人机空中洗楼为例,传统清洗无人机在空中作业时,容易受到风力、气流等外部因素的干扰,包括业内强调最多的水压,都可能导致飞行不稳定,影响飞行安全与作业质量。在极端情况下,由于自身结构与普遍采用的刚性材料设计,无人机一旦发生碰撞事故,不仅会给无人机本身带来损坏,更可能会对建筑物等作业目标造成损伤。
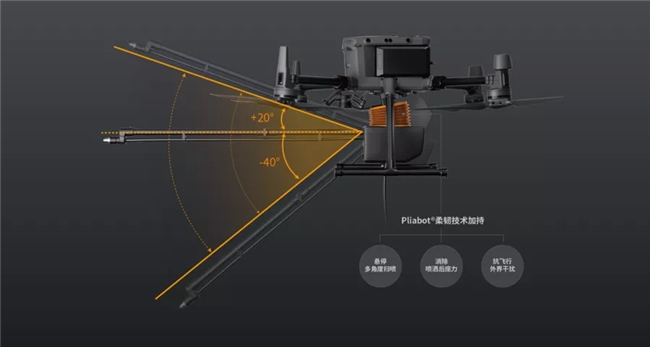
相比之下,万勋科技猎户座AP3-P3柔韧系留清洗系统在Pliabot®柔韧技术加持下,通过独家配备的柔韧云台与触觉AI,不仅可以通过柔韧自适应平衡能力抵抗飞行干扰,还可与作业目标进行柔性交互,充分保证空中作业稳定与安全,并能在极端状况下消弭冲击影响。
目前,万勋科技已推出多款空中柔韧机器人产品,广泛应用于高空清洁、能源运维、应急救援、环境保护等十余个不同行业。作为全球通用软体机器人领航者,万勋科技将不断探索柔韧机器人在低空经济中的应用,让机器人走进千行百业,成为人类工作的得力助手,加速机器人时代的全面到来。