模型广场上新,多款模型任君挑选~
限时免费体验!快来开启你的AI创作之旅吧~
01
comfyui 工作流

ComfyUI是一个基于Stable Diffusion开发的图形用户界面(GUI),它将Stable Diffusion的流程拆分成节点,你能够直观地构建和运行AI模型流程,实现图像生成和编辑的定制化。它适用于数字艺术家、AI研究人员、内容创作者、教育者、游戏开发者和产品设计师等多种用户群体。ComfyUI提供丰富的预设工作流模板,你可以通过一键加载轻松实现人像生成、背景替换、图像动画化等复杂操作,同时也可以根据自己的需求自定义工作流,实现更加个性化的创作。
02
InstantMesh3D内容创作模型

这是由腾讯 ARC 实验室推出的创新项目,该项目旨在通过单张图像快速生成高质量的三维网格模型。InstantMesh适用于多个领域,包括游戏开发、动画制作、虚拟现实、工业设计等。它能够帮助游戏开发者快速生成游戏中的3D模型,提升游戏开发效率;为动画师提供更多创作可能性,加速动画制作流程;生成逼真的虚拟场景和3D物体,提升虚拟现实体验;以及快速生成产品原型,加速产品设计迭代。能够在短短10秒内完成高质量的3D网格模型生成,显著超越了现有的SOTA(State-Of-The-Art)模型。
03
whisper-large-v3自动语音识别

OpenAI 的 whisper-large-v3 能自动语音识别,高效精准转录,广泛应用,提升效率。Whisper-large-v3支持多种语言的语音识别和语音翻译,适用于各种需要语音转录和翻译的场景,如会议记录、视频字幕生成、跨语言交流等。它既可以作为独立的语音识别工具使用,也可以集成到其他应用程序或系统中。
04
ComfyUI图生视频

ComfyUI图生视频功能是基于Stable Diffusion的AI绘画创作工具ComfyUI中的一个重要模块,它可以快速将静态图像转换为动态视频。适用于各种需要图像转视频的场景,如广告制作、产品展示、个人创意表达等。你可以通过简单的拖拽、调整参数等操作,快速生成高质量的动态视频内容。
05
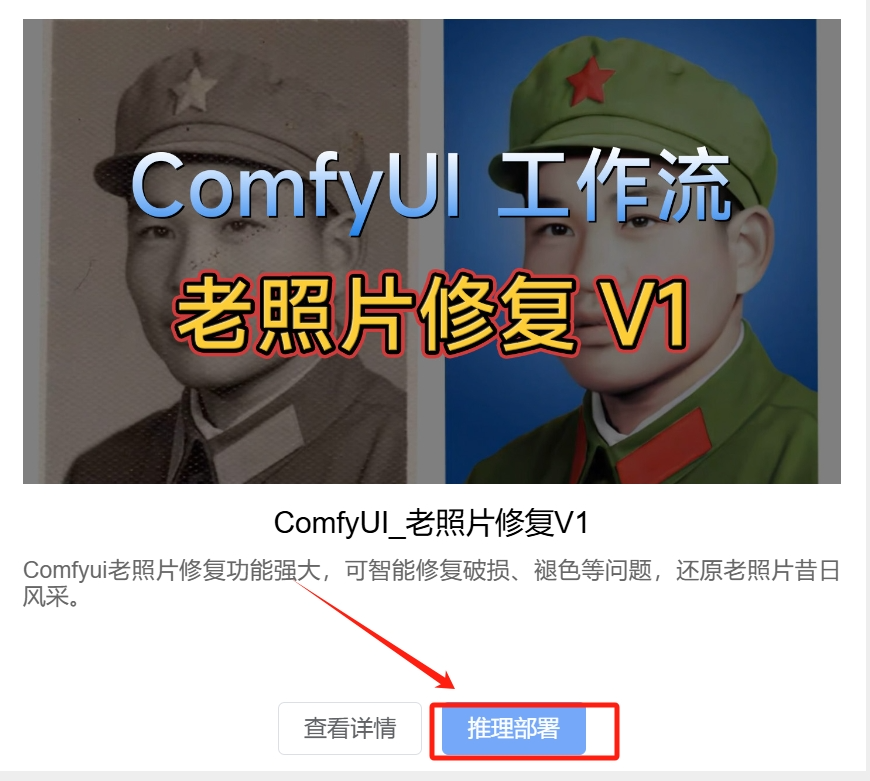
ComfyUI老照片修复

ComfyUI是一个基于web的图形用户界面,用于直观地构建和运行AI模型流程,而老照片修复功能是通过在ComfyUI中加载特定的工作流来实现的,该工作流利用AI技术对老照片进行修复和上色。ComfyUI老照片修复功能适用于各种老旧、褪色或破损的照片,无论是黑白照片还是彩色照片,都可以它进行修复和还原。
06
YOLOv8

YOLOv8是由Ultralytics公司在2023年推出的目标检测和图像分割模型,是YOLO(You Only Look Once)系列的最新成员。它建立在先前YOLO版本的成功基础上,并引入了一系列新功能和优化。它支持全方位的视觉人工智能任务,包括分类、检测、分割、姿态估计和跟踪等。由于其卓越的性能、灵活性和可扩展性,YOLOv8被广泛应用于安全监控、自动驾驶、智能家居、工业自动化等多个领域。
07
WebUI
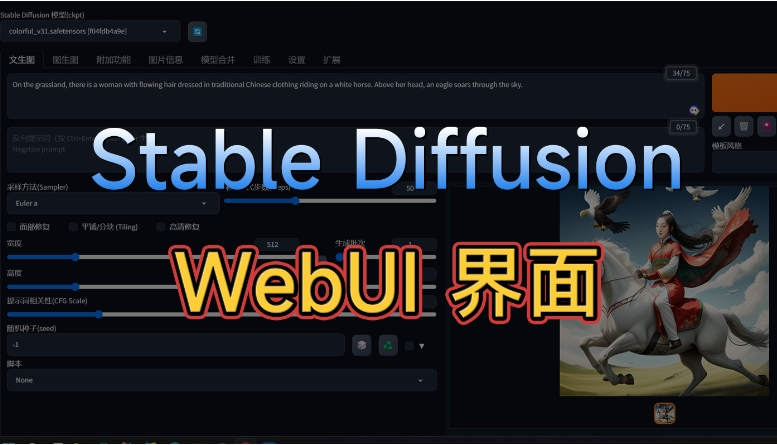
Stable Diffusion WebUI适用于多种场景,包括艺术创作、设计辅助、教育与研究以及娱乐与游戏等。能够生成分辨率和细节程度都非常高的图像,你可以通过调整参数和使用不同的模型,精确控制生成图像的内容和风格,从而满足个性化的创作需求。
08
Llama3

Llama3是一种大语言模型,参数规模多样,可用于生成文本、回答问题、语言翻译等。Llama3还支持8K长文本,并采用了编码效率更高的tokenizer,进一步提升其处理复杂任务的能力。
09
Flux-webui超轻量文生图模型

Flux-webui是一个基于Gradio和Diffusers实现的Flux UI项目,支持一次生成多张图片,适用于多种图像生成场景,如封面设计、促销海报、UI设计稿等,你可以根据自己的需求选择对应的模型进行图像生成。
以上模型均支持一键开启,快来体验吧~
模型广场直达入口:
模型广场




![[Java]Properties类加载配置文件](https://i-blog.csdnimg.cn/direct/34e623cb41564caba3db1676727d3c1f.png)








![[Docker#10] network | 架构 | CRUD | 5种常见网络类型 (实验)](https://img-blog.csdnimg.cn/img_convert/58b5bad79bb655602283502088c7bd9e.png)