列表与字典应用
目的:熟练操作组合数据类型。
任务:
1.基础:生日悖论分析。如果一个房间有23人或以上,那么至少有两 个人的生日相同的概率大于50%。编写程序,输出在不同随机样本数量下,23个人中至少两个人生日相同的概率。
2.进阶:统计《一句顶一万句》文本中前10高频词,生成词云。
3.拓展:金庸、古龙等武侠小说写作风格分析。输出不少于3个金庸(古龙)作品的最常用10个词语,找到其中的相关性,总结其风格。
1.生日悖论分析
import randomdef calculate_birthday_probability(sample_size):match_count = 0for _ in range(sample_size):birthdays = [random.randint(1, 365) for _ in range(23)]if len(set(birthdays)) < 23: # 存在重复生日match_count += 1return match_count / sample_size# 测试不同样本数量
sample_sizes = [1000, 10000, 100000]
for size in sample_sizes:prob = calculate_birthday_probability(size)print(f"样本数量={size}, 概率={prob:.4f}")运行结果:
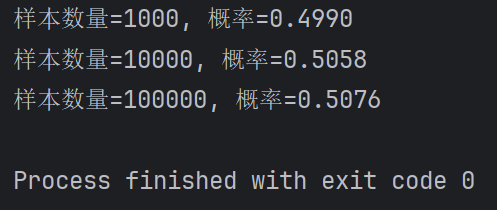
2.统计《一句顶一万句》文本中前10高频词,生成词云
一句顶一万句.txt和chinese_stopwords.txt停用词表文件可自行搜索获取。
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt# 读取《一句顶一万句》文本内容
with open("一句顶一万句.txt", "r", encoding="utf-8") as f:text = f.read()# 读取停用词表
with open("chinese_stopwords.txt", "r", encoding="utf-8") as f:stopwords = [line.strip() for line in f.readlines()]# 分词
words = jieba.lcut(text)# 过滤停用词
filtered_words = [word for word in words if word not in stopwords and len(word) > 1]# 统计词频
word_freq = {}
for word in filtered_words:word_freq[word] = word_freq.get(word, 0) + 1# 取前10高频词
top_10 = sorted(word_freq.items(), key=lambda x: -x[1])[:10]
print("前10高频词:", top_10)# 生成词云
wordcloud = WordCloud(font_path="simhei.ttf", width=800, height=400).generate_from_frequencies(word_freq)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()运行结果:

3.金庸、古龙等武侠小说写作风格分析
import jieba
import jieba.posseg as psegdef analyze_novel_style(novel_path, stopwords_path, top_n=10):# 读取小说文本with open(novel_path, 'r', encoding='utf-8') as f:text = f.read()# 读取停用词表with open(stopwords_path, 'r', encoding='utf-8') as f:stopwords = set([line.strip() for line in f.readlines()])# 分词words = jieba.lcut(text)# 过滤停用词、单字filtered_words = [word for word in words if word not in stopwords and len(word) > 1]# 统计词频word_freq = {}for word in filtered_words:word_freq[word] = word_freq.get(word, 0) + 1# 按词频排序并取前 top_n 个高频词top_words = sorted(word_freq.items(), key=lambda x: x[1], reverse=True)[:top_n]return [word for word, _ in top_words]# 定义金庸和古龙小说路径
jin_yong_novels = {"射雕英雄传": "射雕英雄传.txt","神雕侠侣": "神雕侠侣.txt","倚天屠龙记": "倚天屠龙记.txt"
}stopwords_path = "chinese_stopwords.txt"# 分析金庸小说
jin_yong_top_words = {}
for name, path in jin_yong_novels.items():jin_yong_top_words[name] = analyze_novel_style(path, stopwords_path)# 输出结果
print("金庸小说高频词:")
for name, words in jin_yong_top_words.items():print(f"{name}: {words}")# 简单总结风格
jin_yong_common_words = set()
for words in jin_yong_top_words.values():jin_yong_common_words.update(words)print("\n金庸写作风格特点:")
if '江湖' in jin_yong_common_words:print("- 常涉及宏大的江湖背景,展现江湖中的恩怨情仇和门派纷争。")
if '大侠' in jin_yong_common_words:print("- 着重刻画大侠形象,强调侠义精神。")
if '武功' in jin_yong_common_words:print("- 对武功招式和门派武功体系有较多描写。")
运行结果:
