LatentSync - 字节联合北交大开源的端到端唇形同步框架-附整合包
LatentSync - 字节联合北交大开源的端到端唇形同步框架-附整合包
「LatentSync1.5-codeyuan」
链接:https://pan.quark.cn/s/d6c3918f54f5
一、项目概述
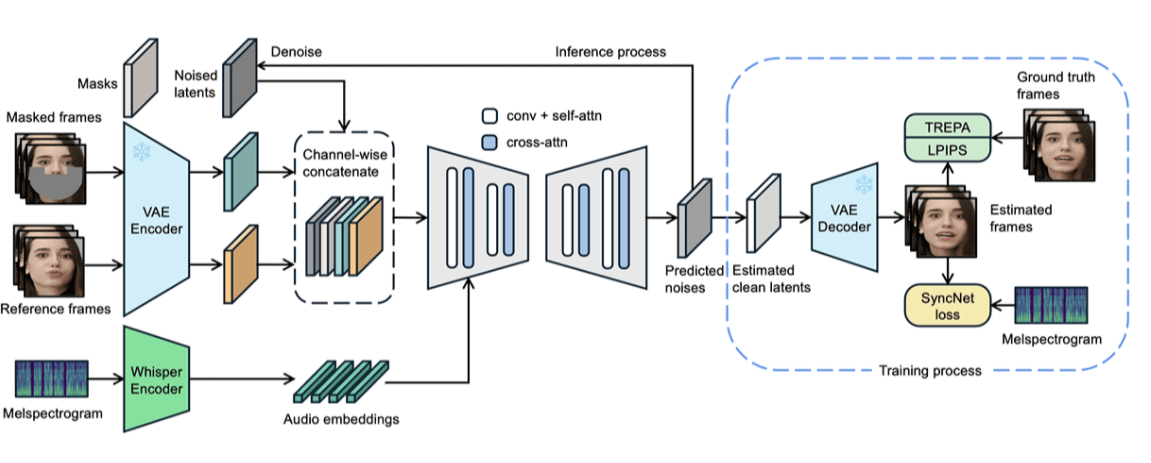
LatentSync 是由字节跳动联合北京交通大学共同打造的端到端唇动同步系统。它摒弃了传统依赖 3D 模型或 2D 特征点的中间表示,直接基于“音频条件下的潜在扩散模型”在潜在空间内生成视频帧,实现高保真度的口型同步效果。
- 利用 Stable Diffusion 的生成实力,精细捕获语音与视觉的时序关联
- 端到端设计,无需额外的后处理或双阶段生成
- 引入 Temporal REPresentation Alignment (TREPA) 机制,显著提升帧间连贯性
- 结合 SyncNet 损失,进一步强化唇动与音频的对齐精度
二、核心功能亮点
- 精准的唇动同步
根据用户输入的音频信号,模型能够自动合成与之严格对应的口唇姿态,广泛适用于配音合成、虚拟人形象等场景。 - 高分辨率输出
在潜在空间中完成扩散过程,避免像素级扩散带来的算力瓶颈,可生成更高分辨率的视频内容。 - 细腻的情感表达
生成视频不仅能重现口型,更能体现说话时的微表情和语调韵律,让人物表现更具真实感。 - 帧间时间一致性
借助 TREPA 方法,从大规模自监督视频模型(如 VideoMAE-v2)中提取时间特征,将其作为额外约束,减少闪烁,提高连续帧的视觉连贯度。
三、技术实现原理
3.1 音频条件的潜在扩散
- 潜在空间建模:以音频嵌入作为条件输入,避免直接在像素空间扩散,从而降低计算复杂度。
- 一体化流程:将音频特征提取、潜在表征生成、图像解码等环节统一到同一个网络架构中,无需分离训练或后处理。
3.2 TREPA:时间表示对齐
- 特征抽取:调用 VideoMAE-v2 等自监督视频模型,分别对真实视频帧和合成帧提取时间序列特征。
- 对齐损失:在训练时,将两者在时间域上的表征差异纳入优化目标,增强生成帧与真实帧的时序一致性。
3.3 SyncNet 监督
- 唇动对齐损失:使用预训练的 SyncNet 对合成视频施加额外监督,确保口型与音频内容一一对应。
- 像素级优化:在解码输出后,额外计算 SyncNet 损失,帮助模型更好地学习音频–唇动映射关系。
四、开源资源
- GitHub 仓库:https://github.com/bytedance/LatentSync
- 论文链接:https://arxiv.org/pdf/2412.09262
五、应用场景
- 影视后期:自动生成与配音音轨同步的口唇动画,提升制作效率,保证角色连贯性。
- 在线教育:将教师语音实时转换为同步口型视频,辅助学生更直观地学习发音。
- 数字广告:为虚拟代言人自动配口型,使商业广告中的人物演绎更生动自然。
- 远程会议:针对网络延迟问题,生成与语音同步的视频,提高跨时区会议的体验。
- 游戏开发:让游戏中 NPC 与配音对话时,口型与声音完全匹配,增强沉浸感。