Seata 源码篇之AT模式启动流程 - 中 - 03
- 数据源代理
- 会话代理
- 锁定查询执行器
- 本地事务提交
- 本地事务回滚
- 更新执行器
- 删除执行器
- 插入执行器
- 小节
本系列文章:
- Seata 源码篇之核心思想 - 01
- Seata 源码篇之AT模式启动流程 - 上 - 02
数据源代理
当我们的数据源被代理后,代理数据源方法调用会走AOP拦截逻辑,也就是被SeataAutoDataSourceProxyAdvice的invoke方法拦截。invoke方法内部会将原本调用DataSource的方法转发给SeataDataSourceProxy执行:
@Overridepublic Object invoke(MethodInvocation invocation) throws Throwable {// 1. 检查当前是否存在全局事务,或者是否需要获取全局锁if (!inExpectedContext()) {return invocation.proceed();}// 2. 获取当前调用的是数据源的哪个方法Method method = invocation.getMethod();String name = method.getName();Class<?>[] parameterTypes = method.getParameterTypes();Method declared;try {declared = DataSource.class.getDeclaredMethod(name, parameterTypes);} catch (NoSuchMethodException e) {return invocation.proceed();}// 3. 取出当前数据源对应的SeataDataSourceProxy,然后调用代理数据源对应的方法DataSource origin = (DataSource) invocation.getThis();SeataDataSourceProxy proxy = DataSourceProxyHolder.get(origin);Object[] args = invocation.getArguments();return declared.invoke(proxy, args);}
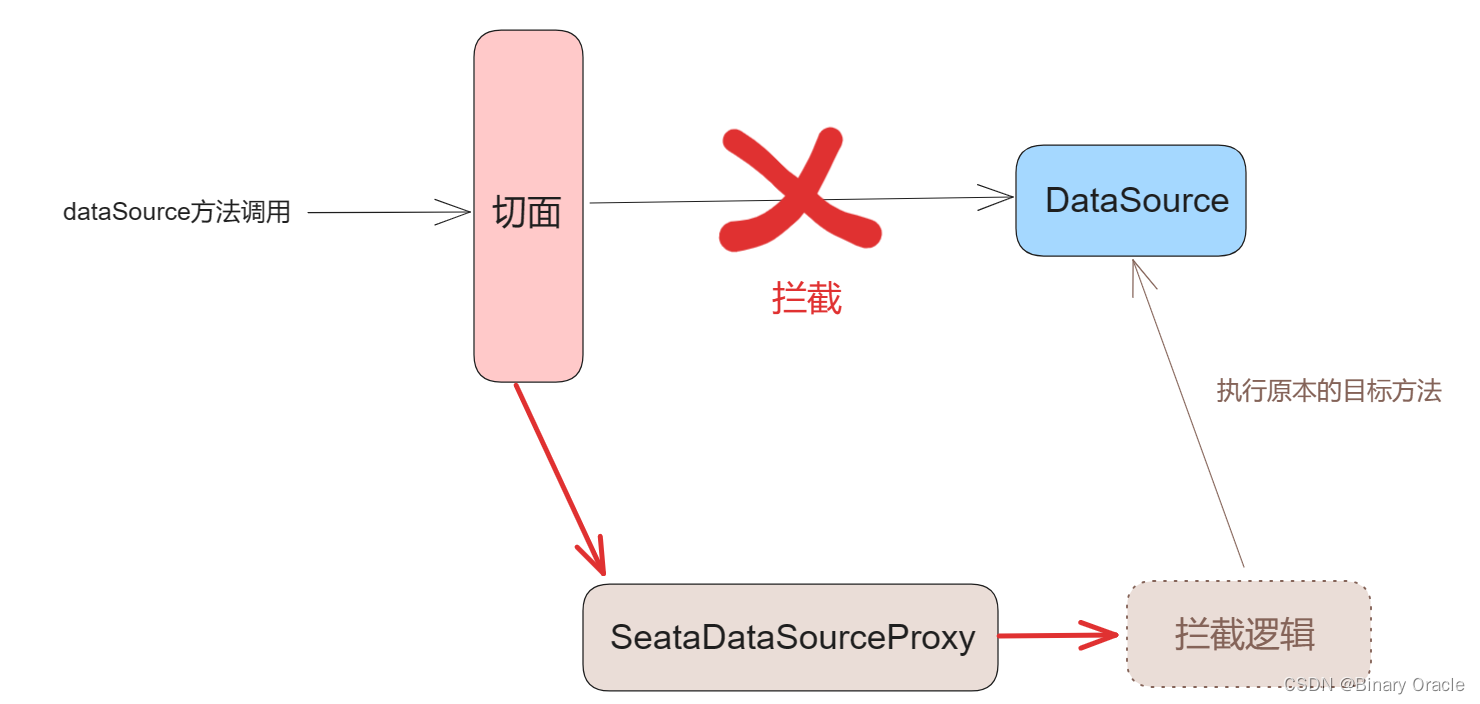
SeataDataSourceProxy这里采用装饰器模式实现对DataSource的增强,同时借助动态代理实现对用户的无感装饰。这里有趣的一点在于,为什么不直接在拦截器invoke方法内部实现拦截逻辑,而是借助装饰器倒了一手,大家可以思考一下原因。
我们通常会通过DataSource的getConnection方法从连接池中获取一个空闲连接,然后借助Connection创建一个会话对象Statement,最后利用Statament对象完成SQL语句的执行。Seata需要拦截SQL执行,那么就不仅需要在DataSource层面做装饰增强,还需要在Connection和Statement层面同样进行装饰增强。
public class DataSourceProxy extends AbstractDataSourceProxy implements Resource {@Overridepublic ConnectionProxy getConnection() throws SQLException {Connection targetConnection = targetDataSource.getConnection();// 返回的Connection对象同样采用装饰器进行增强return new ConnectionProxy(this, targetConnection);}
...
}
ConnectionProxy 内部会在创建Statement会话对象的时候进行装饰增强:
public abstract class AbstractConnectionProxy implements Connection {@Overridepublic Statement createStatement() throws SQLException {Statement targetStatement = getTargetConnection().createStatement();// 返回的Statement采用装饰器进行增强return new StatementProxy(this, targetStatement);}...
}
但是ConnectionProxy不仅仅负责对Statement对象进行装饰,Seata还需要能够在commit和rollback等时间点进行拦截,因此ConnectionProxy的commit和rollback方法就不能只是简单的方法转发了,而是需要增加相关拦截逻辑,这一点后文会讲到。
同时ConnectionProxy内部还需要维护本次连接期间的上下文信息,上下文信息由ConnectionContext保存:
public class ConnectionContext {// 全局事务IDprivate String xid;// 分支事务IDprivate Long branchId;// 是否需要获取全局锁private boolean isGlobalLockRequire;// 自动提交的状态是否变更过private boolean autoCommitChanged;private final Map<String, Object> applicationData = new HashMap<>(2, 1.0001f);private final Map<Savepoint, Set<String>> lockKeysBuffer = new LinkedHashMap<>();private final Map<Savepoint, List<SQLUndoLog>> sqlUndoItemsBuffer = new LinkedHashMap<>();private final List<Savepoint> savepoints = new ArrayList<>(8);...
}
StatementProxy 负责拦截本次会话中执行的每条SQL语句,并通过解析,查询前置和后置镜像,组装undo_log日志,最终完成本地事务的提交。
下面我们将来仔细分析一下StatementProxy的模版流程实现。
会话代理
StatementProxy 类中的拦截逻辑也是以模版方法固定下来的,但是由于模版逻辑存在于query,insert,delete 和 update 逻辑中,所以这里将模版逻辑抽取到了ExecuteTemplate类中:
public class StatementProxy<T extends Statement> extends AbstractStatementProxy<T> {@Overridepublic ResultSet executeQuery(String sql) throws SQLException {this.targetSQL = sql;return ExecuteTemplate.execute(this, (statement, args) -> statement.executeQuery((String) args[0]), sql);}@Overridepublic int executeUpdate(String sql) throws SQLException {this.targetSQL = sql;return ExecuteTemplate.execute(this, (statement, args) -> statement.executeUpdate((String) args[0]), sql);}...
}
到此,应该可以猜到,SQL解析和前后镜像组织的核心逻辑都汇聚于ExecteTemplate类的execute方法中,下面我们来详细看看具体实现:
public class ExecuteTemplate {public static <T, S extends Statement> T execute(StatementProxy<S> statementProxy,StatementCallback<T, S> statementCallback,Object... args) throws SQLException {return execute(null, statementProxy, statementCallback, args);}public static <T, S extends Statement> T execute(List<SQLRecognizer> sqlRecognizers,StatementProxy<S> statementProxy,StatementCallback<T, S> statementCallback,Object... args) throws SQLException {// 1. 当前事务执行无需获取全局锁,直接调用原本的Statement方法if (!RootContext.requireGlobalLock() && BranchType.AT != RootContext.getBranchType()) {return statementCallback.execute(statementProxy.getTargetStatement(), args);}// 2. 根据DB类型,获取对应的SQL解析器String dbType = statementProxy.getConnectionProxy().getDbType();if (CollectionUtils.isEmpty(sqlRecognizers)) {sqlRecognizers = SQLVisitorFactory.get(statementProxy.getTargetSQL(),dbType);}Executor<T> executor;// 3. 当前SQL无需执行任何拦截处理,直接调用原本的Statement方法if (CollectionUtils.isEmpty(sqlRecognizers)) {executor = new PlainExecutor<>(statementProxy, statementCallback);} else {// 4. 如果SQL解析器只存在唯一的一个if (sqlRecognizers.size() == 1) {SQLRecognizer sqlRecognizer = sqlRecognizers.get(0);// 5. 根据当前SQL类型,获取不同类型的执行拦截器switch (sqlRecognizer.getSQLType()) {case INSERT:executor = EnhancedServiceLoader.load(InsertExecutor.class, dbType,new Class[]{StatementProxy.class, StatementCallback.class, SQLRecognizer.class},new Object[]{statementProxy, statementCallback, sqlRecognizer});break;// 下面就是case update , case delete 等同质的选择逻辑了...}} else {// 6. 当存在多个SQL解析器时executor = new MultiExecutor<>(statementProxy, statementCallback, sqlRecognizers);}}T rs;// 7. 执行器的execute方法中包含SQL解析等逻辑,但是不同操作对于的处理逻辑不太一样,所以需要使用不同的执行器类型rs = executor.execute(args);...return rs;}}
ExecuteTemplate 会根据所执行的SQL语句类型不同,通过SPI加载不同类型的执行器来执行,执行器继承体系如下所示:
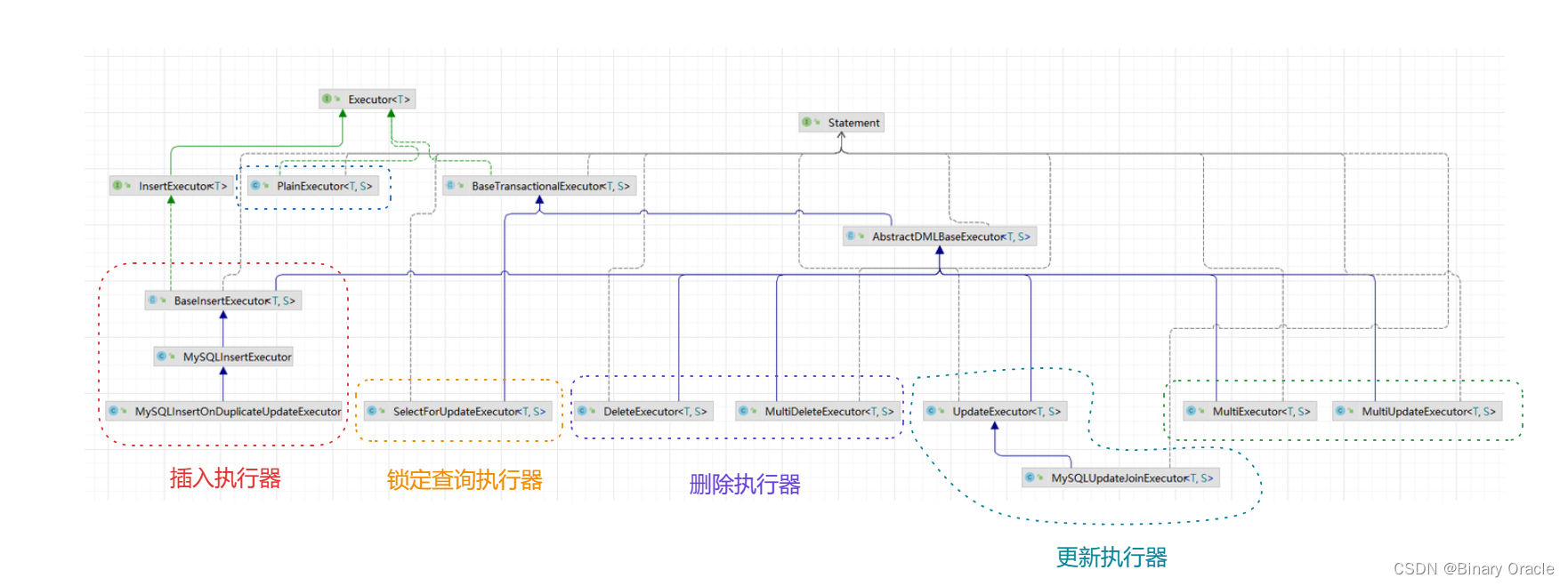
SQLRecognizer 作为SQL解析器,由于内部使用Druid作为最终解析工具,所有看做是Seata与Druid的一层隔离,防止两者直接耦合在一起。不同类型的SQL语句同样对应不同类型的SQLRecognizer实现,具体如下图所示:
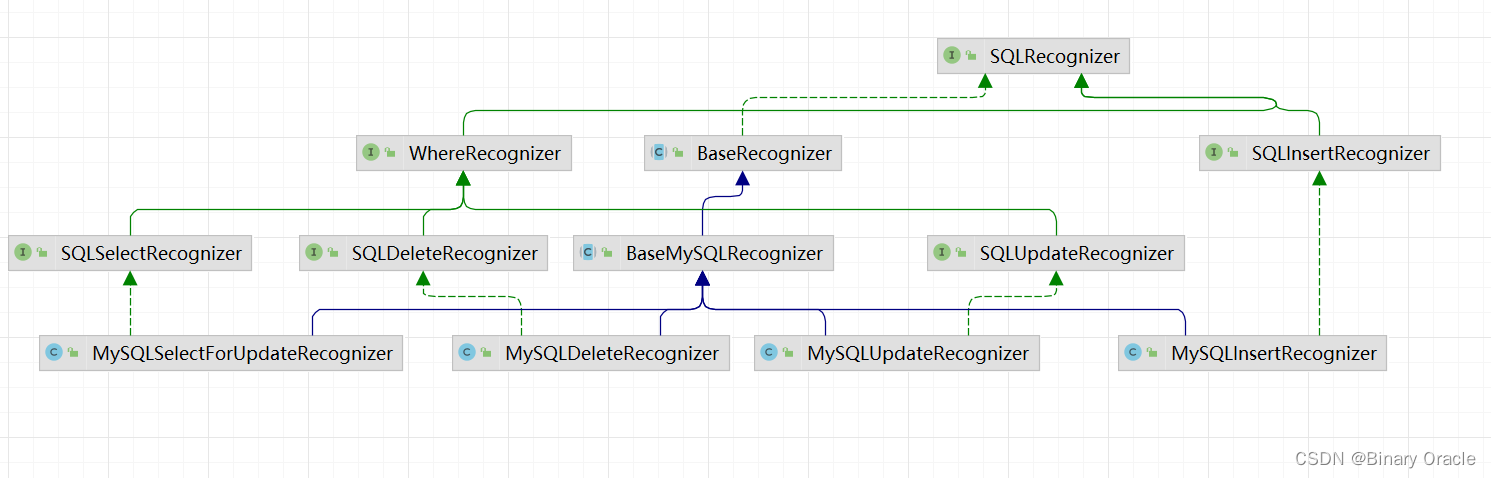
执行器主要负责解析SQL语句来组织回滚日志,执行本地事务,获取全局锁以及提交本地事务。
下面我们来看看不同场景下,执行器执行逻辑的区别。
锁定查询执行器
我们首先来看最简单的SelectForUpdateExecutor实现,针对select … for update 语句进行拦截增强:
public abstract class BaseTransactionalExecutor<T, S extends Statement> implements Executor<T> {@Overridepublic T execute(Object... args) throws Throwable {// 1. 获取全局事务ID,并绑定到当前连接上下文中String xid = RootContext.getXID();if (xid != null) {statementProxy.getConnectionProxy().bind(xid);}// 2. 将是否需要全局锁这一标识设置到连接上下文中 statementProxy.getConnectionProxy().setGlobalLockRequire(RootContext.requireGlobalLock());// 3. 真正执行查询的方法return doExecute(args);}...
}
public class SelectForUpdateExecutor<T, S extends Statement> extends BaseTransactionalExecutor<T, S> {@Overridepublic T doExecute(Object... args) throws Throwable {// 1. 获取代理数据源连接Connection conn = statementProxy.getConnection();// 2. 从代理数据源连接中获取当前数据库元数据信息DatabaseMetaData dbmd = conn.getMetaData();T rs;Savepoint sp = null;boolean originalAutoCommit = conn.getAutoCommit();try {// 3. 如果当前数据源开启了事务自动提交,则将自动提交暂时关闭if (originalAutoCommit) {conn.setAutoCommit(false);} else if (dbmd.supportsSavepoints()) {// 4. 如果当前数据源关闭了事务自动提交,则在当前数据源支持回滚点的前提下,创建一个回滚点// 如果因为全局锁获取失败,需要执行全局回滚,则可以直接回滚到当前事务执行到此处的状态,而非把之前的操作全部执行回滚sp = conn.setSavepoint();} else {throw new SQLException("not support savepoint. please check your db version");}LockRetryController lockRetryController = new LockRetryController();ArrayList<List<Object>> paramAppenderList = new ArrayList<>();// 5. 构建SQL语句负责查询出本次查询涉及到的所有记录: select 主键 from 表 需要执行的sql的where子句String selectPKSQL = buildSelectSQL(paramAppenderList);// 这里的while循环为的是全局锁获取失败后,进行重试while (true) {try {// 6. 执行目标SQL查询语句rs = statementCallback.execute(statementProxy.getTargetStatement(), args);// 7. 执行before image对应的SQL语句,同时利用返回的记录列表,构建全局锁的key,该全局锁覆盖本次查询得到的记录列表TableRecords selectPKRows = buildTableRecords(getTableMeta(), selectPKSQL, paramAppenderList);String lockKeys = buildLockKey(selectPKRows);if (StringUtils.isNullOrEmpty(lockKeys)) {break;}// 8. 本地事务执行完毕,提交前,尝试获取全局锁 if (RootContext.inGlobalTransaction() || RootContext.requireGlobalLock()) {// Do the same thing under either @GlobalTransactional or @GlobalLock, // that only check the global lock here.statementProxy.getConnectionProxy().checkLock(lockKeys);} else {throw new RuntimeException("Unknown situation!");}break;} catch (LockConflictException lce) {// 9. 获取全局锁失败,会先回滚当前本地事务,然后休眠指定时间后,再次重试if (sp != null) {conn.rollback(sp);} else {conn.rollback();}// trigger retrylockRetryController.sleep(lce);}}} finally {// 10. 如果有需要,则释放先前临时的创建的回滚点,同时将自动提交设置更改回来if (sp != null) {try {if (!JdbcConstants.ORACLE.equalsIgnoreCase(getDbType())) {conn.releaseSavepoint(sp);}} catch (SQLException e) {LOGGER.error("{} release save point error.", getDbType(), e);}}// 11. 如果先前开启了自动提交,此处需要提交本地事务,同时将原本的自动提交设置更改回来if (originalAutoCommit) {conn.setAutoCommit(true);}}// 12. 返回执行目标SQL语句得到的结果return rs;}...
}
由于select … for update 锁定读不涉及数据修改,所以也就无需前置和后置镜像了,但是这里有四点需要注意一下:
- selectPKSQL 如何构建出来的 ?
// 目标SQL语句
select * from test where id = 1 and name = 'dhy' for update;
// 构建得到的selectPKSQL,组装规则为: select + 主键 + from 表 + 目标SQL语句的where子句
SELECT id FROM test WHERE id = 1 AND name = 'dhy' FOR UPDATE;
- 全局锁的key是如何构成的 ?
// 对于只有单个主键的情况,例如上面的SQL语句,则key的模样如下
// 表名:记录1主键值,记录2主键值,记录3主键值
test:1,2
// 对于联合主键的情况,则key的模样如下
// 表名:记录1主键1值_记录1主键2值
test:1_a,2_b
- 如何判断全局锁是否获取成功 ?
public class ConnectionProxy extends AbstractConnectionProxy {public void checkLock(String lockKeys) throws SQLException {if (StringUtils.isBlank(lockKeys)) {return;}try {// 全局锁等资源由默认的资源管理器管理boolean lockable = DefaultResourceManager.get().lockQuery(BranchType.AT,getDataSourceProxy().getResourceId(), context.getXid(), lockKeys);// 获取全局锁失败,抛出锁冲突异常if (!lockable) {throw new LockConflictException(String.format("get lock failed, lockKey: %s",lockKeys));}} catch (TransactionException e) {// 识别是否为锁冲突异常,如果是的话,抛出锁冲突异常recognizeLockKeyConflictException(e, lockKeys);}}...
}
获取全局锁是否成功完全由资源管理器说的算,所以下面我们来看看资源管理器是如何判断全局锁是否获取成功的:
public class DataSourceManager extends AbstractResourceManager {@Overridepublic boolean lockQuery(BranchType branchType, String resourceId, String xid, String lockKeys) throws TransactionException {// 1. 构建全局锁获取亲戚GlobalLockQueryRequest request = new GlobalLockQueryRequest();request.setXid(xid);request.setLockKey(lockKeys);request.setResourceId(resourceId);try {GlobalLockQueryResponse response;// 2. 借助RmNettyRemotingClient发送同步请求if (RootContext.inGlobalTransaction() || RootContext.requireGlobalLock()) {response = (GlobalLockQueryResponse) RmNettyRemotingClient.getInstance().sendSyncRequest(request);} else {throw new RuntimeException("unknow situation!");}// 3. 判断请求是否成功if (response.getResultCode() == ResultCode.Failed) {throw new TransactionException(response.getTransactionExceptionCode(),"Response[" + response.getMsg() + "]");}// 4. 判断全局锁是否获取成功return response.isLockable();} catch (TimeoutException toe) {throw new RmTransactionException(TransactionExceptionCode.IO, "RPC Timeout", toe);} catch (RuntimeException rex) {throw new RmTransactionException(TransactionExceptionCode.LockableCheckFailed, "Runtime", rex);}}...
}
全局锁资源具体是如何管理的,由server端负责承接逻辑实现,这一点在本系列文章后面会进行详细分析,这里暂时不展开。
最后还有一点,LockRetryController主要负责两件事:
- 维护重试次数和重试间隔
public LockRetryController() {this.lockRetryInterval = getLockRetryInterval();this.lockRetryTimes = getLockRetryTimes();}
- 负责休眠等待逻辑实现
public void sleep(Exception e) throws LockWaitTimeoutException {// prioritize the rollback of other transactionsif (--lockRetryTimes < 0 || (e instanceof LockConflictException&& ((LockConflictException)e).getCode() == TransactionExceptionCode.LockKeyConflictFailFast)) {throw new LockWaitTimeoutException("Global lock wait timeout", e);}try {Thread.sleep(lockRetryInterval);} catch (InterruptedException ignore) {}}
本地事务提交
关于本地事务提交这一点,由于内容较多,我想单独开一节进行讲解。
本地事务提交有两种方式,一种是在设置autoCommit属性为false的前提下,由开发者手动提交;另一种就是在设置autoCommit属性为true的前提下,由框架内部的模版代码先将自动提交关闭,执行完本地SQL语句和附加逻辑后,再最后由框架内部调用commit方法完成提交,同时恢复原先自动提交的属性设置。
要想享受上面框架提供的事务模版服务,我们需要首先把要执行的事务交付于框架托管,比如在事务方法上标注@Transactional注解,表示当前事务执行交由Spring事务模块托管;下面我们复习一下Spring为我们提供的事务执行的整套模版流程:
public abstract class TransactionAspectSupport implements BeanFactoryAware, InitializingBean {protected Object invokeWithinTransaction(Method method, @Nullable Class<?> targetClass,final InvocationCallback invocation) throws Throwable {...// 1. 准备平台事务管理器 PlatformTransactionManager ptm = asPlatformTransactionManager(tm);...// 2. 根据事务传播行为,决定是否开启新的本地事务TransactionInfo txInfo = createTransactionIfNecessary(ptm, txAttr, joinpointIdentification);// 3. 执行本地事务Object retVal;try {retVal = invocation.proceedWithInvocation();}catch (Throwable ex) {// 4. 出现异常则回滚completeTransactionAfterThrowing(txInfo, ex);throw ex;}...// 5. 执行正常则提交commitTransactionAfterReturning(txInfo);return retVal;}...}
}
- 开启新的本地事务过程中,会调用PlatformTransactionManager的doBegin方法真正开启一次新的事务连接
@Overrideprotected void doBegin(Object transaction, TransactionDefinition definition) {DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;...con = txObject.getConnectionHolder().getConnection();// 核心: 如果连接开启了自动提交,则关闭自动提交,并设置标记if (con.getAutoCommit()) {txObject.setMustRestoreAutoCommit(true);con.setAutoCommit(false);}...}
- 无论我们是设置了手动提交,还是默认的自动提交,只要事务交由了Spring托管,那么Spring便会在目标方法正常执行完毕后,进行commit
@Overrideprotected void doCommit(DefaultTransactionStatus status) {DataSourceTransactionObject txObject = (DataSourceTransactionObject) status.getTransaction();Connection con = txObject.getConnectionHolder().getConnection();...con.commit();...}
- 在事务提交完毕后的资源清理环节,会将先前更改的自动提交恢复过来
@Overrideprotected void doCleanupAfterCompletion(Object transaction) {DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;...// 重新将连接设置回自动提交Connection con = txObject.getConnectionHolder().getConnection();if (txObject.isMustRestoreAutoCommit()) {con.setAutoCommit(true);}...}
Spring声明式事务实现的特点在于,如果当前连接设置的是自动提交,则更改为手动提交,同时目标方法执行完毕后,统一由Spring框架内部帮我们调用commit方法完成本地事务提交。我们下面会看到Seata的实现有所不同。
Seata在遇到设置为自动提交模式的连接处理上,和Spring处理思路一致,但是当连接处于手动提交模式时,Seata不会在目标方法执行完毕后,帮助我们统一调用commit进行提交,而是需要开发者自行调用commit方法进行提交。
对于SelectForUpdateExecutor来说,其execute方法可以简化为如下过程:
@Overridepublic T doExecute(Object... args) throws Throwable {... // 1. 如果当前连接开启了自动提交,则先关闭自动提交boolean originalAutoCommit = conn.getAutoCommit();if (originalAutoCommit) {conn.setAutoCommit(false);}// 2. 执行业务SQL...// 3. 如果先前为自动提交模式,则在此处提交本地事务,同时恢复自动提交if (originalAutoCommit) {conn.setAutoCommit(true);}return rs;}
Seata只会在自动提交模式下,才会由框架内部在业务SQL执行完毕后,帮助我们调用commit方法完成本地事务提交,这一点需要注意。
下面看看本地事务提交的具体过程:
public class ConnectionProxy extends AbstractConnectionProxy {@Overridepublic void setAutoCommit(boolean autoCommit) throws SQLException {// 1. 在开启了全局事务场景下,并且原先是自动提交模式,则在此处由框架内部手动帮助我们提交事务if ((context.inGlobalTransaction() || context.isGlobalLockRequire()) && autoCommit && !getAutoCommit()) {doCommit();}// 2. 恢复自动提交设置targetConnection.setAutoCommit(autoCommit);}...
}
真正的本地事务提交逻辑在doCommit方法中,我们下面来看看其具体实现:
private void doCommit() throws SQLException {// 1. 如果处于全局事务模式下,则走seata拦截逻辑if (context.inGlobalTransaction()) {processGlobalTransactionCommit();} else if (context.isGlobalLockRequire()) {processLocalCommitWithGlobalLocks();} else {// 2. 否则直接走正常事务提交逻辑 targetConnection.commit();}}
下面看看对标注了@GlobalTransactional注解的目标方法的事务提交逻辑实现:
private void processGlobalTransactionCommit() throws SQLException {try {// 1. 当前分支事务执行本地提交前,先执行分支事务注册(分支注册过程同时包含获取全局锁逻辑)register();} catch (TransactionException e) {// 识别是否为全局锁获取失败抛出的异常recognizeLockKeyConflictException(e, context.buildLockKeys());}try {// 2. 刷新UNDO日志到undo_log表中UndoLogManagerFactory.getUndoLogManager(this.getDbType()).flushUndoLogs(this);// 3. 执行本地事务提前(这里包括原有的业务逻辑和undo_log日志的落盘逻辑)targetConnection.commit();} catch (Throwable ex) {// 4. 上报分支事务执行失败report(false);throw new SQLException(ex);}// 5. 上报分支事务执行成功if (IS_REPORT_SUCCESS_ENABLE) {report(true);}// 6. 清空当前连接上下文context.reset();}private void register() throws TransactionException {if (!context.hasUndoLog() || !context.hasLockKey()) {return;}// 1. 分支事务提交前,到TC中进行注册Long branchId = DefaultResourceManager.get().branchRegister(BranchType.AT, getDataSourceProxy().getResourceId(),null, context.getXid(), context.getApplicationData(),// 传入需要获取的全局锁key,不难猜出,分支事务注册的同时,还包括获取全局锁的逻辑context.buildLockKeys());// 2. 保存分支事务IDcontext.setBranchId(branchId);}
如果将连接设置为手动提交模式,则需要开发者手动调用ConnectionProxy的commit方法完成分支事务提交:
@Overridepublic void commit() throws SQLException {try {// 分支事务一阶段提交包括注册和获取全局锁两个过程,如果全局锁获取失败// 此处由lockRetryPolicy提供的模版方法,完成重试抢锁lockRetryPolicy.execute(() -> {// 同样是调用doCommit方法完成分支事务一阶段提交doCommit();return null;});} catch (SQLException e) {if (targetConnection != null && !getAutoCommit() && !getContext().isAutoCommitChanged()) {rollback();}throw e;} catch (Exception e) {throw new SQLException(e);}}
SelectForUpdateExecutor 自动提交模式下无需在setAutoCommit方法中处理抢锁失败逻辑,是因为这段逻辑已经存在于了execute方法中,有遗忘的可以回看。而doCommit方法不只SelectForUpdateExecutor 会调用,所以内部需要处理获取全局锁失败逻辑。
本地事务回滚
本地事务回滚会调用ConnectionProxy的rollback方法,回滚逻辑实现比较简单,关键在于会向TC报告自己本地执行失败的状态:
@Overridepublic void rollback() throws SQLException {// 1. 执行正常的回滚操作targetConnection.rollback();// 2. 向TC报告当前分支事务的状态if (context.inGlobalTransaction() && context.isBranchRegistered()) {report(false);}// 3. 清空连接上下文context.reset();}
大家可以思考一下,当TC收到某个分支事务执行失败的状态后,它又是如何通知其他分支事务完成回滚的呢?这部分内容将在本系列后面揭晓。
更新执行器
UpdateExecutor 的逻辑是其次简单的,我们来看看其实现逻辑:
public abstract class BaseTransactionalExecutor<T, S extends Statement> implements Executor<T> {@Overridepublic T execute(Object... args) throws Throwable {// 1. 获取全局事务ID,并绑定到当前连接上下文中String xid = RootContext.getXID();if (xid != null) {statementProxy.getConnectionProxy().bind(xid);}// 2. 将是否需要全局锁这一标识设置到连接上下文中 statementProxy.getConnectionProxy().setGlobalLockRequire(RootContext.requireGlobalLock());// 3. 真正执行查询的方法return doExecute(args);}...
}
public abstract class AbstractDMLBaseExecutor<T, S extends Statement> extends BaseTransactionalExecutor<T, S> {@Overridepublic T doExecute(Object... args) throws Throwable {AbstractConnectionProxy connectionProxy = statementProxy.getConnectionProxy();// 如果当前连接本身已经开启了自动提交,则在事务执行前,关闭自动提交,执行结束后,再开启自动提交if (connectionProxy.getAutoCommit()) {return executeAutoCommitTrue(args);} else {return executeAutoCommitFalse(args);}}...
}
下面我们来看看处理更全面的一种情况,也就是连接本身开启了自动提交的前提下,是如何进行处理的:
public abstract class AbstractDMLBaseExecutor<T, S extends Statement> extends BaseTransactionalExecutor<T, S> {protected T executeAutoCommitTrue(Object[] args) throws Throwable {ConnectionProxy connectionProxy = statementProxy.getConnectionProxy();try {// 1. 关闭自动提交设置connectionProxy.changeAutoCommit();// 2. 分支事务一阶段提交逻辑包含获取全局锁的逻辑,所以需要处理抢锁失败的重试逻辑return new LockRetryPolicy(connectionProxy).execute(() -> {// 执行SQL解析等拦截逻辑,然后执行最终的目标SQL语句T result = executeAutoCommitFalse(args);// 提交事务connectionProxy.commit();return result;});} catch (Exception e) {if (!LockRetryPolicy.isLockRetryPolicyBranchRollbackOnConflict()) {connectionProxy.getTargetConnection().rollback();}throw e;} finally {// 恢复自动提交设置connectionProxy.getContext().reset();connectionProxy.setAutoCommit(true);}}...
}
protected T executeAutoCommitFalse(Object[] args) throws Exception {try {// 1. 获取前置镜像TableRecords beforeImage = beforeImage();// 2. 执行正常的SQL语句T result = statementCallback.execute(statementProxy.getTargetStatement(), args);// 3. 获取后置镜像TableRecords afterImage = afterImage(beforeImage);// 4. 准备undo日志prepareUndoLog(beforeImage, afterImage);return result;} catch (TableMetaException e) {...}}
更新过程中的拦截逻辑核心就三步,下面我们来详细看看每一步的具体实现过程:
- 准备前置镜像
@Overrideprotected TableRecords beforeImage() throws SQLException {ArrayList<List<Object>> paramAppenderList = new ArrayList<>();TableMeta tmeta = getTableMeta();// 1. 构建组装前置镜像对应的SQL语句String selectSQL = buildBeforeImageSQL(tmeta, paramAppenderList);// 2. 执行该SQL语句,然后获取查询出来的记录return buildTableRecords(tmeta, selectSQL, paramAppenderList);}
这里简单讲讲前置镜像SQL语句组装的规则:
// 目标SQL语句
update test set name = 'WILL' where age = 18
// 构建得到的SQL语句
// 规则: select + 主键,update涉及列 + from 表 + 目标SQL语句的where子句
SELECT id, name FROM test WHERE age = 18 FOR UPDATE
- 准备后置镜像
@Overrideprotected TableRecords afterImage(TableRecords beforeImage) throws SQLException {TableMeta tmeta = getTableMeta();if (beforeImage == null || beforeImage.size() == 0) {return TableRecords.empty(getTableMeta());}// 1. 构建后置镜像查询SQLString selectSQL = buildAfterImageSQL(tmeta, beforeImage);ResultSet rs = null;// 2. 执行后置镜像查询SQL,返回查询结果try (PreparedStatement pst = statementProxy.getConnection().prepareStatement(selectSQL)) {SqlGenerateUtils.setParamForPk(beforeImage.pkRows(), getTableMeta().getPrimaryKeyOnlyName(), pst);rs = pst.executeQuery();return TableRecords.buildRecords(tmeta, rs);} finally {IOUtil.close(rs);}}
后置镜像SQL语句组装是依赖于前置镜像SQL的,而非目标SQL语句,:
// 目标SQL语句
update test set name = 'WILL' where age = 18
// 前置镜像SQL语句
SELECT id, name FROM test WHERE age = 18 FOR UPDATE
// 构建得到的SQL语句
// 规则: select + 主键,update涉及列 + from 表 + where 主键 in (前置镜像查询出来的记录列表的主键列聚合得到的主键列表)
SELECT id, name FROM test WHERE (id) in ( (?),(?) )
- 准备undo_log日志
protected void prepareUndoLog(TableRecords beforeImage, TableRecords afterImage) throws SQLException {// 0. 健壮性检查if (beforeImage.getRows().isEmpty() && afterImage.getRows().isEmpty()) {return;}if (SQLType.UPDATE == sqlRecognizer.getSQLType()) {if (beforeImage.getRows().size() != afterImage.getRows().size()) {throw new ShouldNeverHappenException("Before image size is not equaled to after image size, probably because you updated the primary keys.");}}ConnectionProxy connectionProxy = statementProxy.getConnectionProxy();// 1. 提交本地事务前,需要获取对应的全局锁,如果此处执行的时删除语句,则以前置镜像作为锁记录,否则以后置镜像作为锁记录(删除操作,无需记录后置镜像)TableRecords lockKeyRecords = sqlRecognizer.getSQLType() == SQLType.DELETE ? beforeImage : afterImage;// (此处key的组装规则和上文说的一致)String lockKeys = buildLockKey(lockKeyRecords);if (null != lockKeys) {// 2. 向当前连接上下文的lockKeysBuffer中追加需要获取的全局锁keyconnectionProxy.appendLockKey(lockKeys);// 3. 构建undo日志SQLUndoLog sqlUndoLog = buildUndoItem(beforeImage, afterImage);// 4. 像当前连接上下文的sqlUndoItemsBuffer中追加构建好的undo日志connectionProxy.appendUndoLog(sqlUndoLog);}}
构建undo日志的具体过程如下:
protected SQLUndoLog buildUndoItem(TableRecords beforeImage, TableRecords afterImage) {SQLType sqlType = sqlRecognizer.getSQLType();String tableName = sqlRecognizer.getTableName();SQLUndoLog sqlUndoLog = new SQLUndoLog();sqlUndoLog.setSqlType(sqlType);sqlUndoLog.setTableName(tableName);sqlUndoLog.setBeforeImage(beforeImage);sqlUndoLog.setAfterImage(afterImage);return sqlUndoLog;}
lockKeysBuffer 和 sqlUndoItemsBuffer 会在当前本地事务提交的时候用到。
分支事务提交会调用ConnectionProxy的doCommit方法,这一点上面已经说过了,而doCommit方法会在注册分支事务的同时,传入需要获取的全局锁的key:
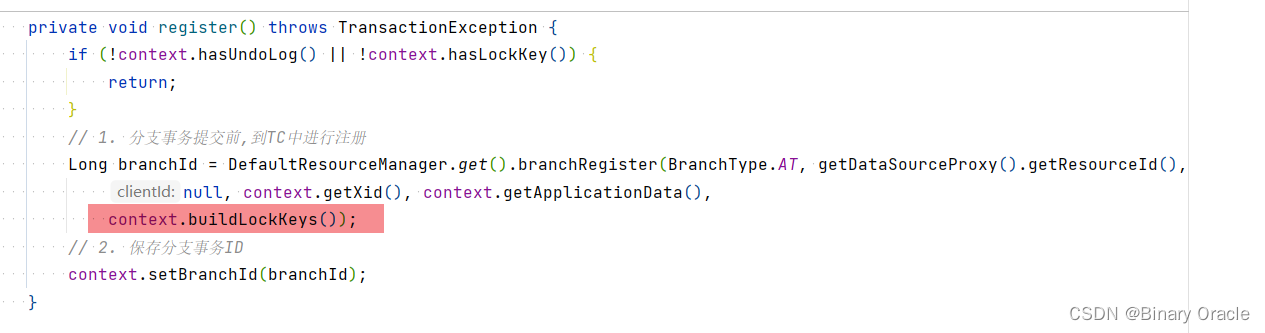
ConnectionContext 的buildLockKeys 方法中会遍历lockKeysBuffer 集合,对所有需要获取的全局锁key进行拼接:
public String buildLockKeys() {if (lockKeysBuffer.isEmpty()) {return null;}// 1. 获取所有全局锁keySet<String> lockKeysBufferSet = new HashSet<>();for (Set<String> lockKeys : lockKeysBuffer.values()) {lockKeysBufferSet.addAll(lockKeys);}if (lockKeysBufferSet.isEmpty()) {return null;}// 2. 用;拼接在一起,然后返回StringBuilder appender = new StringBuilder();Iterator<String> iterable = lockKeysBufferSet.iterator();while (iterable.hasNext()) {appender.append(iterable.next());if (iterable.hasNext()) {appender.append(";");}}return appender.toString();}
执行完分支事务注册和全局锁获取后,下一步就是向undo_log表中写入undo日志,然后提交本地事务了; 这里会调用UndoLogManager的flushUndoLogs写入undo日志,下面我们一起来看看:
@Overridepublic void flushUndoLogs(ConnectionProxy cp) throws SQLException {ConnectionContext connectionContext = cp.getContext();if (!connectionContext.hasUndoLog()) {return;}// 1. 准备分支事务的undo日志String xid = connectionContext.getXid();long branchId = connectionContext.getBranchId();BranchUndoLog branchUndoLog = new BranchUndoLog();branchUndoLog.setXid(xid);branchUndoLog.setBranchId(branchId);branchUndoLog.setSqlUndoLogs(connectionContext.getUndoItems());// 2. 调用undo日志解析器对undo日志进行编码UndoLogParser parser = UndoLogParserFactory.getInstance();byte[] undoLogContent = parser.encode(branchUndoLog);// 3. 尝试对undo日志进行压缩CompressorType compressorType = CompressorType.NONE;if (needCompress(undoLogContent)) {compressorType = ROLLBACK_INFO_COMPRESS_TYPE;undoLogContent = CompressorFactory.getCompressor(compressorType.getCode()).compress(undoLogContent);}// 4. 将undo日志插入undo_log表中,如果使用的是Mysql,这里会调用MySQLUndoLogManager的insertUndoLogWithNormal实现insertUndoLogWithNormal(xid, branchId, buildContext(parser.getName(), compressorType), undoLogContent, cp.getTargetConnection());}
删除执行器
本节来看看DeleteExecutor的执行流程,由于DeleteExecutor和UpdateExecutor都继承了AbstractDMLBaseExecutor,所以二者主要区别主要集中在前置和后置镜像构建的逻辑上,下面我们一起来看一下:
- 构建前置镜像
public class DeleteExecutor<T, S extends Statement> extends AbstractDMLBaseExecutor<T, S> {@Overrideprotected TableRecords beforeImage() throws SQLException {SQLDeleteRecognizer visitor = (SQLDeleteRecognizer) sqlRecognizer;TableMeta tmeta = getTableMeta(visitor.getTableName());ArrayList<List<Object>> paramAppenderList = new ArrayList<>();// 构建前置镜像对应的SQL,然后执行该SQL,返回查询得到的结果String selectSQL = buildBeforeImageSQL(visitor, tmeta, paramAppenderList);return buildTableRecords(tmeta, selectSQL, paramAppenderList);}...
}
这里还是老规矩,来看看前置镜像SQL组装的逻辑:
// 目标SQL
delete from t where id = 1
// 前置镜像SQL
// 组装规则: select * from 表 + 目标SQL的where子句
SELECT name, id FROM t WHERE id = 1 FOR UPDATE
- delete操作无需后置镜像,所以返回结果集合为空
@Overrideprotected TableRecords afterImage(TableRecords beforeImage) throws SQLException {return TableRecords.empty(getTableMeta());}
插入执行器
本节我们再来看看MySQLInsertExecutor的执行流程,由于MySQLInsertExecutor同样继承了AbstractDMLBaseExecutor,所以这里我们也只对前置和后置镜像构建过程进行分析:
- 构建前置镜像
@Overrideprotected TableRecords beforeImage() throws SQLException {// insert操作无需前置镜像,所以返回的空集合return TableRecords.empty(getTableMeta());}
- 构建后置镜像
@Overrideprotected TableRecords afterImage(TableRecords beforeImage) throws SQLException {// 1. 获取插入记录的主键值Map<String, List<Object>> pkValues = getPkValues();// 2. 正常情况下,此处返回的后置镜像里面的内容也是空的,因为记录插入之前并不存在TableRecords afterImage = buildTableRecords(pkValues);if (afterImage == null) {throw new SQLException("Failed to build after-image for insert");}return afterImage;}
除了简单的增删改查语句外,还有涉及Join的更新操作,InsertOnUpdate等操作,这部分操作对应的执行器实现大家可自行翻阅源码进行学习。
小节
本文和大家一起探索了Seata AT模式的一阶段实现,下篇文章将和大家一起来看看AT模式二阶段的实现和一阶段中漏掉的全局事务提交和回滚。







![buuctf-[GXYCTF2019]禁止套娃 git泄露,无参数rce](https://img-blog.csdnimg.cn/99adbfe03e804e4399282a047f043873.png)