一、背景
随着得物用户规模和业务复杂度不断提升,端上网络体验优化已逐步进入深水区。为了更好地保障处于弱网状态下得物App用户的使用体验,我们在已有的网络体验大盘、网络诊断工具的基础上研发了弱网诊断能力。该工具能够高效实时诊断用户真实网络环境,同时给出精确网络质量分级,为后续App各业务场景进行针对性优化做好基础建设保障。
一些网络性能指标:
-
速率:指传送数据的速率。速率是计算机网络中最重要的性能指标,单位是b/s(比特每秒,也写作bps ,即bit per second )。速率较高时可写作kbps,mbps。
-
带宽:带宽用来表示网络的通信线路传送数据的能力,表示在单位时间内从网络中的某一点到另一点所能通过的“最高速率”。
-
吞吐量(throughput):表示在单位时间内通过某网络的数据量。吞吐量常用于对网络的一种测量。吞吐量受网络带宽或者速率限制。例如,对于一个100Mb/s的网络,其额定速率是100Mb/s,那么该数值是此网络的吞吐量的上限,其吞吐量可能只有70Mb/s。
-
时延:指数据从网络上的一端传输到另一端所需要的时间。
-
往返时间RTT(Round-Trip Time):表示从发送方发送数据开始,到发送方收到接收方的确认,总共经历的时间。
-
HttpRTT:指从客户端请求的第一个字节开始发送到收到第一个数据包响应的时间差。这个时间包含3个部分,客户端发送数据到服务器耗时、服务器处理耗时、服务器响应数据到客户端耗时。
弱网诊断观察的指标:
弱网诊断根据HttpRTT和吞吐量来观察用户网络环境。
-
HttpRTT:在不考虑服务器处理耗时的情况下,能够体现用户请求被处理的真实时延。
-
吞吐量(throughput):用户的额定速率能被系统提供的API获取到,然而其仅能表示设备能够提供的最大速率(一般很大),却不是真实速率,而测量真实的吞吐量更能体现出用户当前真实网络环境。
二、整体架构
本次实现的是被动弱网诊断,也就是不主动发起探测请求,被动采集App内的全部网络请求,再根据一定在策略计算出用户网络环境。相对于主动探测,被动探测不会浪费用户资源。尤其是在吞吐量计算方面,主动探测不仅会消耗用户流量,还可能会对正在进行中的用户网络请求产生影响。而且当用户网络环境不佳时,负向影响更加严重。
以下为被动网络诊断的整体架构图:
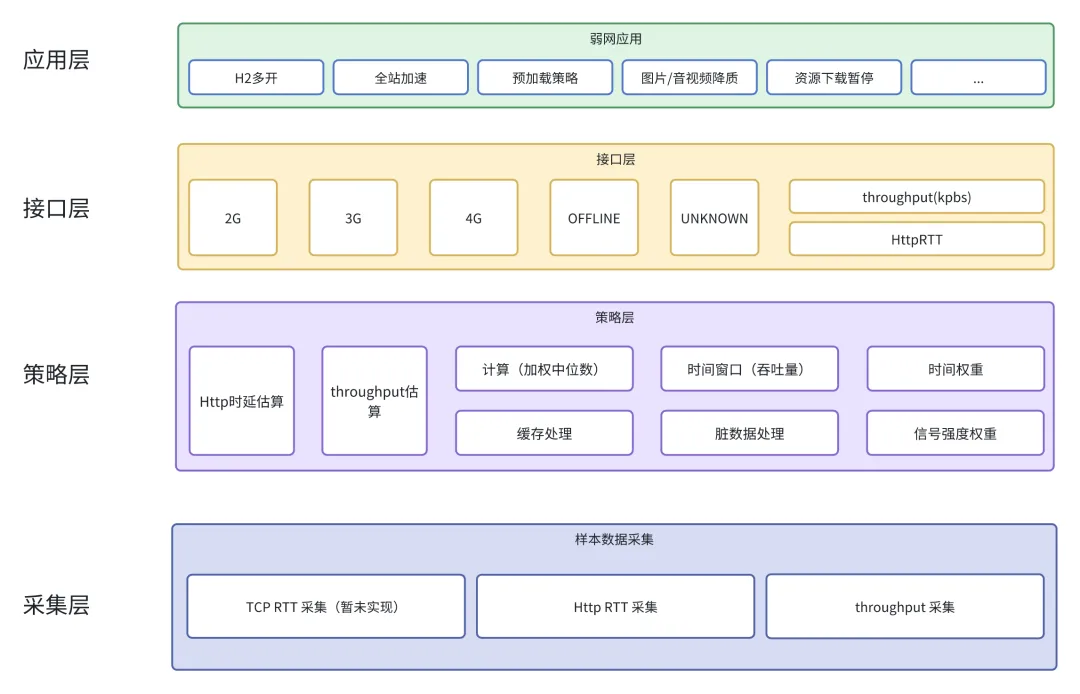
整体架构图
三、采集层
HttpRTT采集
HttpRTT的采集比较简单,各端根据自身Http协议栈的实现获取到从写入requestHeader开始,到收取responseHeader的时间差即可。
对于Android,我们通过OkHttp完成Http请求,通过向OkHttp注册网络监听即可实现。需要说明的是,在不修改源码的情况下,Android无法获取到收到第一个响应数据包的时间,只能监听到Header读取完成,这会有些许误差,但实测下来可以忽略。
对于其他客户端内通过自行实现Http协议栈发起的网络请求(如PCDN),我们通过向其注册特定的监听回调,也能获取到HttpRTT。
采集样本过滤
HttpRTT包含了服务器处理时间,而当服务器处理时间过长或过低时对其他普遍意义上的Http请求参考价值相对较低,因此我们需要排除这些数据:
-
localhost:如果向localHost发起请求,且响应的仅是缓存的数据,那么其HttpRTT时延明显接近于0;
-
PUT请求:由于PUT请求传输的数据量一般较大,其HttpRTT明显高于其他;
-
其他明显偏离的数据。
吞吐量(throughput)采集
throughput(bit/s , bps) = 单位时间内通过的数据量(bit) / 单位时间(s)
吞吐量的采集相对要复杂得多,吞吐量采集目的是获取用户所能使用的最大的数据率(或带宽),因而其需要在设备上恰好有大量数据正在传输时采集。对于主动探测来说,在无其他请求干扰的情况下,主动发起一个大数据量CDN下载请求即可快速测量出吞吐量。而被动探测则需要想办法预测或检测到大量数据传输的时刻,并适时计算吞吐量。
时间窗口
怎样选取计算吞吐量的时间窗口是计算吞吐量准确性的关键。这个窗口要恰好在大量数据正在传输时,不能早也不能晚。如果提前开启了时间窗口,那么同样的大小的数据通过,由于分母增大会导致计算出的数值偏低;如果数据传输完成后,稍晚关闭时间窗口,那么同样会由于分母增大而导致计算出的数值偏低。
我们知道Http请求或多或少会有上行/下行数据,但由于服务器处理耗时长短的不确定性(不能算在分母里),单个Http请求测速时并不可靠。而多个Http正在并发请求进行中的时候,其请求的流量会叠加,单个请求的服务器耗时会被其他Http请求覆盖,此时采集吞吐量会是个好的选择。因此,我们可以在监听到Http并发请求数量达到5个以上时采集吞吐量。
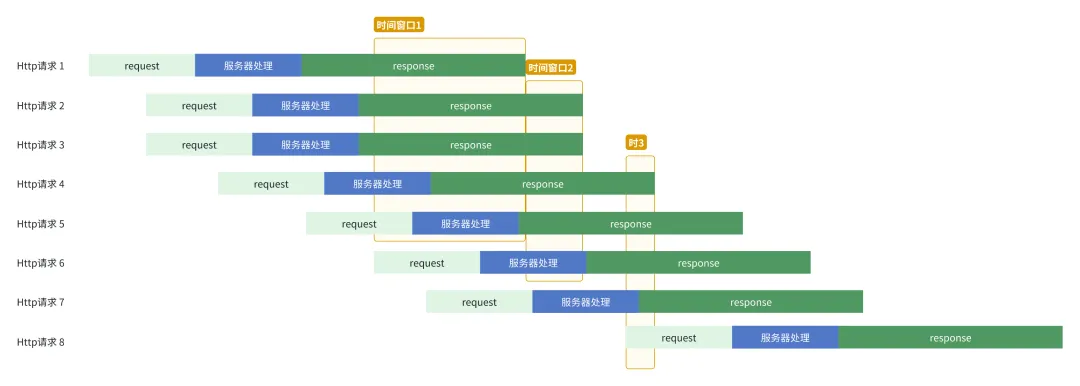
时间串口的选择(忽略建连耗时)
可以看出,当并发较多时,服务器耗时会被覆盖,每个时间窗口内存在约4个Http请求的响应数据。
我们始终监听App内的全部Http请求,当监控到有5个及以上的网络请求尚未完成时,也就是Http并发5个以上,开启时间窗口;当时间窗口已开启且任意一个请求结束时,我们结束当前时间窗口;
需要注意的是,当我们结束一个时间窗口的时候,需要立刻检测当前并发是否5个以上,而不是等到新的请求到来时,这样能避免类似(图2:时间窗口2)的采样机会被浪费掉,而采样成功的样本数越多,越有利于最终结论的准确性(后面策略层会讲原因)。
可行性(我们的App内能满足5个并发以上吗?)
当然可以。通过观察线下测试和线上数据分析,我们App内的并发数能够满足吞吐量采集的必要条件。举个例子,进入商详一次的并发量就能满足。
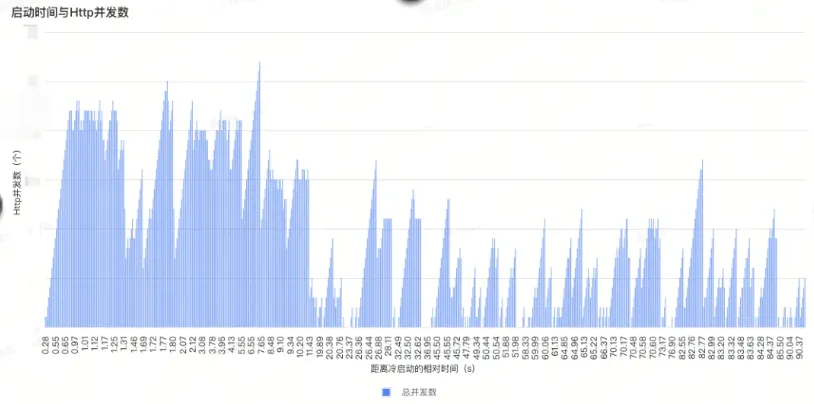
用户A启动90秒内Http并发数量(线上数据)
数据量
分母(单位时间)的问题解决了,分子(单位时间内通过的数据量)如何取值呢?
-
思路1:当前时间窗口内并行的Http通过的Reponse数据量;
-
思路2:设备内所传输的数据量;
-
思路3:当前网卡传输的数据量。
先说思路1,这个实现上需要我们在时间窗口开始时记录全部Http请求已传输的字节数,时间窗口关闭时再记录一次,然后把当前并行的Http请求时间窗口内的数据量全部累加起来。这意为着我们要时刻监控每一个Http请求中每个字节的读取,成本太高了。另一方面,如果有其他非Http请求(或者我们App之外的请求)也在进行,我们仅测算App内Http请求的吞吐量显然是偏低的。因此,思路1不合适。
再说思路2,相对合适。我们要测算的就是设备的吞吐量。因为即使是App外的流量,其也会有结束的时候,总能为我们所用(除非用户对我们App单独做带宽限制)。
获取网卡的数据量
相对于获取设备内的全部流量,获取网卡的流量则更为合适。
原因1:部分系统已经支持WIFI与蜂窝并行请求,如果当前使用的是WIFI,将App外的蜂窝流量测算进去会导致偏差。
原因2:网络切换时,处于旧网络上的请求不会立即释放,而新的请求会发生在新的网络上,此时设备内的通过的流量是多网卡的累积。
需要注意的是系统API返回的是字节数(byte),而我们计算的是bit,因此计算吞吐量时需要进行换算。
脏数据过滤
前面讲到“并发5个时,每个时间窗口内可以采集到约4个Http请求的响应数据”,然而运气并不会始终这样好。
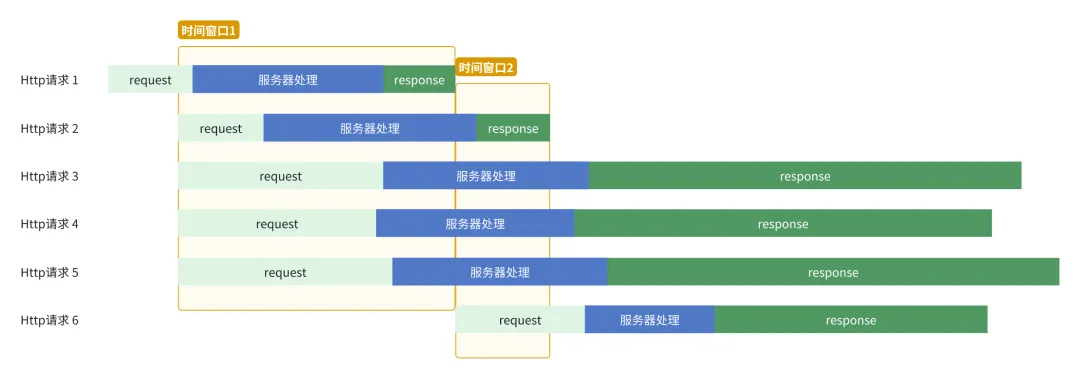
窗口挂起
如上图所示,时间窗口1内仅两个有效的response,时间窗口2内仅一个有效的response,其计算出的吞吐量必然是偏低的。因此,脏数据过滤就显得十分重要。
- 小数据量过滤
时间窗口内通过的流量小于32KB时,不会产生准确的速率,我们直接忽略这次采样。要知道,一个图片的数据量都可能会超过32KB。
- 低利用率过滤
低利用率是指由于数据需求较小,导致当前速率远未达到最大吞吐率的情况。如图4-时间窗口1,对于一个未被充分利用的网络,我至少希望一个HttpRTT的时间内接收到的数量大于15KB。
// 窗口是否挂起
fun isHangingWindow(bitsRx: Long, duration: Long): Boolean {val kCwndSizeBits = 10 * 1.5 * 1000 * 8val multiplier = 1val httpRTT = ??? //由Http RTT模块计算val bitsReceivedOverOneHttpRtt = bitsRx * httpRTT / durationreturn bitsReceivedOverOneHttpRtt < kCwndSizeBits * multiplier
}
为什么是15KB ?
如果TCP连接刚刚建立,由于Linux系统的默认设置,客户端能够同时发送10个数据段,每个数据段时1460字节,合计也就是15KB。
四、策略层
到这里,我们已经能采集到很多HttpRTT样本、throughput样本了,现在我们要考虑下怎么将这些样本综成计算出一个可以代表设备普遍意义上的HttpRTT、throughput,然后再归类出设备网络类型(慢的网络、一般的网络、快的网络、很快的网络…)。
中位数
首选是选取什么样的策略将众多的HttpRTT样本计算出最终值。可选方式如下:
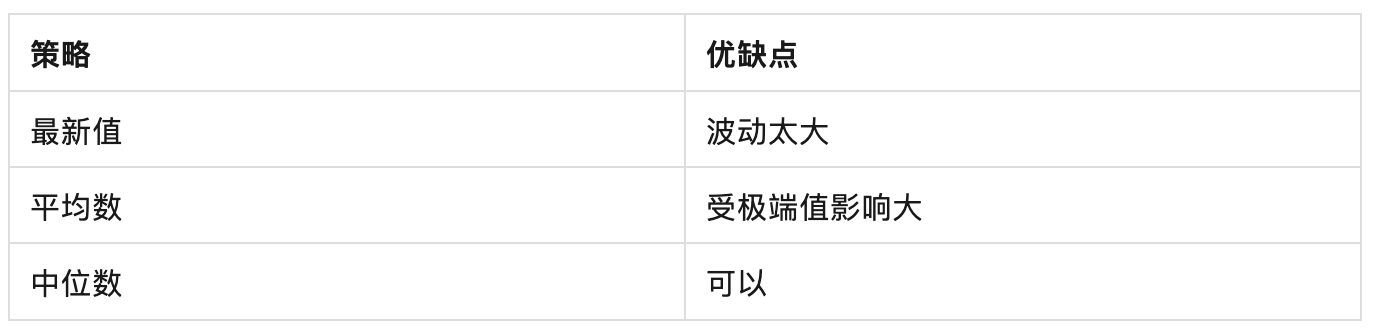
中位数相对于平均数等其他统计量来说,更适合处理包含极端值、偏态分布或受到干扰的数据集。
时间权重
用户网络质量可能随时间而发生变化,最新的样本数据更接近于当前网络环境。我们对样本数据施加时间权重,样本数据每60秒降低一半权重,那么越新的样本权重越高。
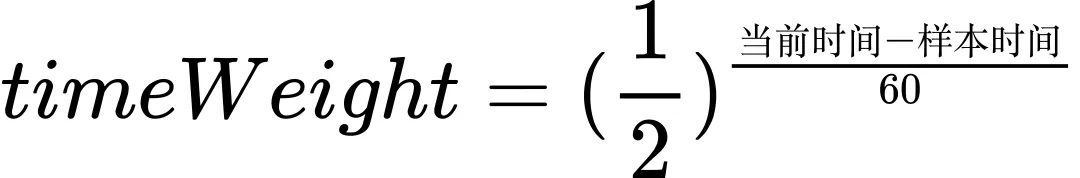
时间权重
60秒半衰期下不同时间差下的权重:
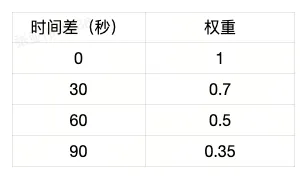
时间权重变化
信号强度权重
同样的,信号强度也可能会随用户移动位置而发生变更,不同信号强度下的网络质量也会不同。我们将用户信号强度划分为4个等级,再根据信号强度等级的变化施加不同的权重。那么,样本数据生成时的信号强度与当前信号强度越是接近,其样本权重就越高。
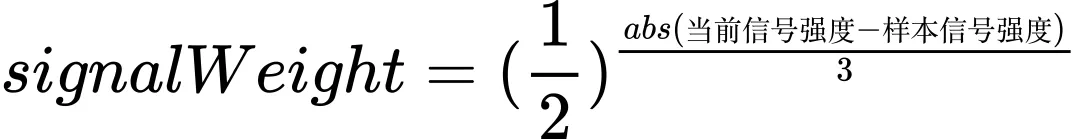
信号权重
目前仅Android且网络环境为WIFI会计算信号强度权重。
加权中位数
最终,将全部样本以加权中位数的方式,计算HttpRTT、throughput。而最终权重由时间权重与信号强度权重结合得出。
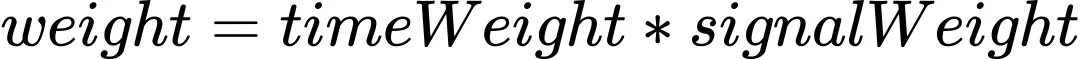
综合权重
计算与缓存
如图4所示,应用网络请求并发量能达到20+,而启动1分钟内总Http请求数到达了450,平均每秒约8个请求。而我们线下实测每次计算耗时1~10ms,样本总数越高时耗时也越高。因此,我们要考虑下如何降低计算频率。
适时计算
调用方总是期望在请求API时立刻能够拿到最新的、最准确的结果。一个简单的方式是业务请求时将全部样本重新计算一遍,一开始我们也确实是这么设计的,然而每次计算耗时1~10ms, 这个对调用方来说是显然是无法接受。
那么,我们真的需要在调用时将全部样本重算一遍吗?
首先来说,只有新的计算结果和旧的计算结果有差异时,我们才需要重新计算。我们的计算策略是加权中位数,其计算来源是样本总数、样本权重,而样本权重受时间、信号强度影响。
-
对于样本数、信号强度:其变化时必然会引起最终结果的变化;
-
对于时间,通过单个请求的时间权重公式(图4),我们可以推导出多个样本时,单个样本的权重不会随当前时间发生变化(图8),也就是我们无需考虑时间流逝对时间权重的计算影响。
那么,我们只需要在样本数、信号强度发生变化时重新计算,然后将计算结果缓存下来。
计算条件
也并非只要有新样本生成我们就要重新计算一遍,那样计算频率太高了。总的来说,当有新样本到来时,重新计算需满足以下任意一个条件:
-
从未计算出结果
-
网络类型发生变更
-
信号强度发生变更
-
当前时间较上次计算大于10秒
-
Http样本数较上次计算多出50%
-
throughput样本数较上次计算多出50%
-
HttpRTT样本+throughput样本合计增加20以上
网络变更监听
对于HttpRTT样本,throughput样本,我们各保留最新的300个。当网络发生变更时我们会清除全部,因为旧的船票不能登上新船。
五、接口层
现在我们有了具体的HttpRTT、throughput,然而大部分业务并不需要这些数字,他们只想知道当前网络怎么样,快不快,有多快。基于此,我们根据HttpRTT、throughput将用户网络划分为5个类型,通过接口提供给上层。

这里throughput的单位是kbps,如果换算成常见的KB/s,需要除以8
需要说明的是,这里的TYPE_2G并不是指我们手机信号里所展示的2G,而是基于被动探测对用户网络环境划分的结果。
即使用户连接的是5G网络,当其因信号不好等其他因素导致RTT较高或throughput较低时,也会被划分到TYPE_2G。换句话说,这里用TYPE_2G就是表明网络很慢,就和很多年前的2G一样慢。
此外,由于网络类型的计算是在网络请求完成时进行的异步计算,上层通过接口读取的始终是缓存,所以无需考虑调用时的性能问题。
六、阈值定义
网络类型划分里有4个关键数值:272ms、511ms、400kpbs、1600kpbs,这些数组是怎么定义出来的呢?

- 线下测试:首选通过弱网工具判断我们的HttpRTT、throughput估算的是否准确。通过Round-trip latancy(ms) 增加延迟观察HttpRTT是否同步改变,通过限制Bandwidth(kbps)观察throughput数值是否与之一致。
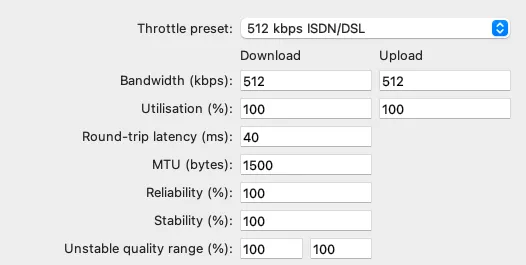
charless弱网模拟
-
线上验证:网络监控中携带当前网络类型,统计线上数据观察TYPE_2G、TYPE_3G、TYPE_4G网络请求耗时表现。
-
反复实验:通过调整关键参数找到最有区分度的阈值。如缓存的样本总数越高就表明参照了越多的老数据、时间权重半衰期越长老数据的权重就越高、窗口挂起判定中multiplier越高样本数越少结果越准确……通过实验数据调整我们预埋的参数,能使判定更加准确。
七、性能指标
HttpRTT 数值计算
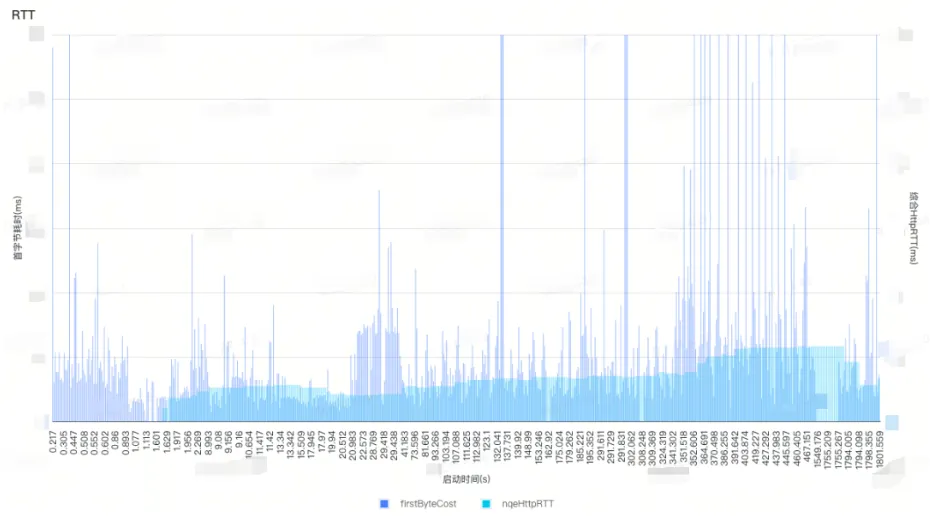
用户B 全部网络请求的首字节耗时与nqeHttpRTT
上图是线上某用户B的首字节耗时(HttpRTT)与最终计算出的nqeHttpRTT。单次网络请求耗时会有波动,但nqeHttpRTT维持准确与稳定。
注:
nqeHttpRTT指最终估算出的HttpRTT;
为优化显示,图中纵轴以xx ms为最高值,实际上部分请求远高于此;
nqeHttpRTT未伴随Http请求出立刻出现是因为诊断模块启动时机较晚,事实上nqeHttpRTT得计算最低只需要5个完成Head响应的Http请求。
吞吐量(throughput)数值
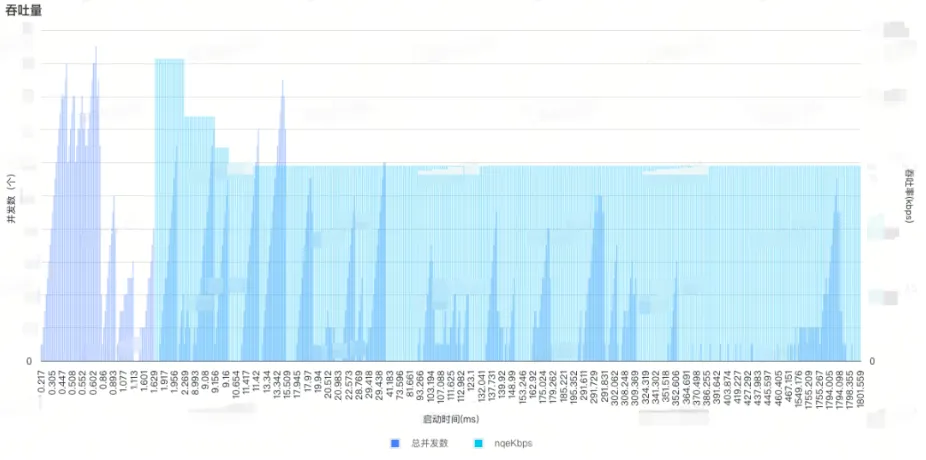
用户B 全部网络请求的并发数与吞吐率
上图是线上某用户B的并发数与吞吐率计算结果。并发5个以上时会采集出一个以上吞吐率样本,可以看到我们App内的并发数能够满足我们对吞吐率的采集需求,而估算出的吞吐率(nqeKbps)数值稳定。
准确性判定
大部分调用方并不关注具体的HttpRTT,吞吐量数值,而只关注我们划分出的网络类型。划分网络类型的准确性自然是调用方关注的重点。那么,如何衡量我们的准确性呢?换句话说,我们判断为弱网,他真的是弱网吗?
一个简单的方式是请求耗时大于500ms算作实际弱网,但是业务接口的耗时与CDN的耗时会有明显差异,500ms明显不能作为CDN耗时的弱网衡量标准。
如果我们以单个接口耗时500ms作为实际弱网呢?也会存在一些问题,比如西藏的用户与杭州(机房在这里)的用户在网络延迟上明显有巨大差异(物理距离决定的)。即使网络极佳的西藏用户,业务接口的耗时也会高于网络一般的杭州用户。但是网络极佳的西藏用户访问CDN时,其耗时又要优于杭州的网络一般的用户。
如果以某省份单接口耗时大于500ms呢?且不说可能以偏概全,就目前而言,同一省份的IPv4和IPv6的连接的机房都可能会不一样(有杭州,也有北京)。
…
目前的准确性判定
我们以实际耗时比50分位网络传播耗时慢一倍为实际弱网(判断准确),比50分位耗时小为实际正常(误判或其他)。

网络耗时阶段

怎么定义实际弱网?
实际弱网(请求慢)=(request耗时+response耗时)*2+服务器处理+其他=50分位总耗时+(request耗时+response耗时)
实际正常(请求快)=(request耗时+response耗时)+服务器处理+其他=50分位总耗时
怎么计算网络传播耗时?
网络传播耗时=request耗时+response耗时,即数据包在网络上传输的耗时。
数据发送速率(kbps) = TCP窗口大小 * 8 / RTT(TCP)
数据发送耗时 = 数据量 * 8 / 发送速率
网络传播耗时 = request + response = RTT + 数据发送耗时
以某接口为例,TCP RTT=50ms,窗口大小=16192,上行字节数=4095,下行字节数=24807,总网络耗时(50分位)=300ms;
那么:数据发送速率(bps)=16192*8/0.05=2590720(bps)、数据发送耗时=(4095+24807)8/35982221000=89ms、网络传播耗时=50+89=139ms;
最终得出,实际弱网耗时(比中位数多一倍网络耗时)=300+139=439ms;实际正常耗时(小于中位数)=300ms。
网络发生拥塞时,我们以16192作为TCP窗口大小;以上数据全部以50分位计算。
线上数据
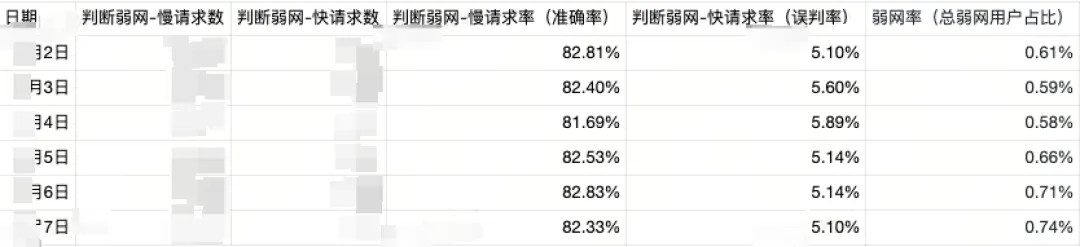
某接口的弱网准确率
数据说明:
-
判断弱网:指弱网诊断输出当前网络类型为弱网,即HttpRTT类型为2G、3G或吞吐量类型为2G。
-
判断弱网-慢请求率:在判断为弱网的前提下,实际上慢请求的比例。慢请求指上文中的实际弱网,即高于50分位耗时+网络传播耗时。
-
判断弱网-快请求率:在判断为弱网的前提下,实际上快请求的比例。快请求指上文中的实际正常,即低于50分位耗时。
-
弱网率:判断弱网的请求量占总请求量的比例。
可以看到:
- 判定为弱网的用户占比约为0.65%,而判定弱网中仅有约5%的请求耗时是低于50分位耗时。
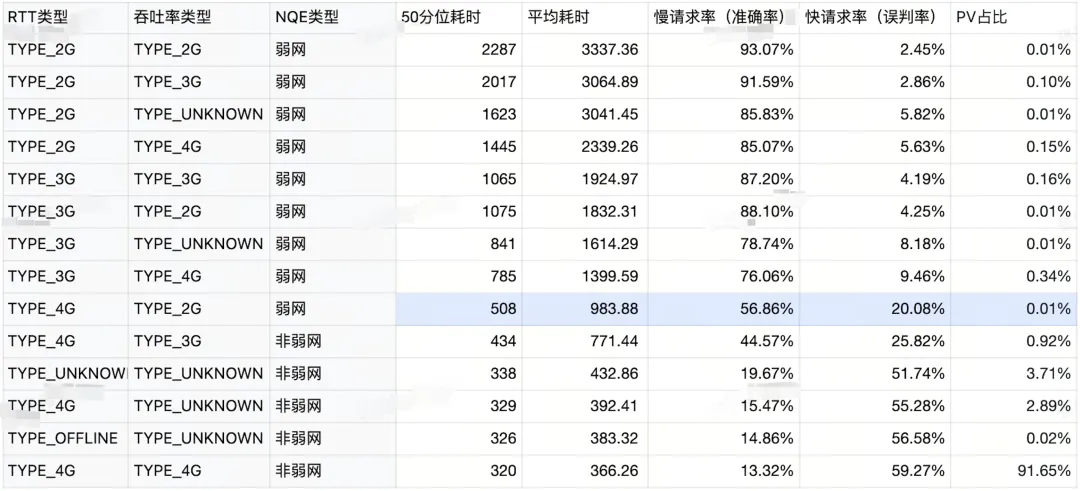
某请求HttpRTT类型、吞吐量类型与耗时表现
当我们以具体的HttpRTT类型、吞吐率类型来区分数据的时候,更能够清晰大看到不同分类下的数据差异。通过上图我们可以看到:判断的类型越差(4G>3G>2G),请求耗时的越高(AVG、P50…),同时慢请求率越高(准确率),快请求率越低(误判率)。
不准确性来源
即使我们尽力优化策略,但仍有一部分误判。其来源如下:
-
分位值判定带来的误差 (可以参考以上准确性说明);
-
用户RTT 恰好在阈值附近波动;
-
来自算法本身限制,中位数机制本身就决定了当用户网络环境快速变更后无法快速响应。比如,用户从WIFI信号差的地方移动到路由器附近,网络质量立即变得极好,此时没有足够数量的新样本积累,弱网诊断输出的仍是弱网;
-
大量请求异常高耗时,当用户吞吐量一般时, 用户高并发请求某HOST时,存在首包耗时异常高的情况。如图16第9秒、26秒、26秒都存在单HOST高并发高耗时,而导致估算值较高。(当然,后面我们会考虑优化并发数,但这和弱网诊断没有关系)。
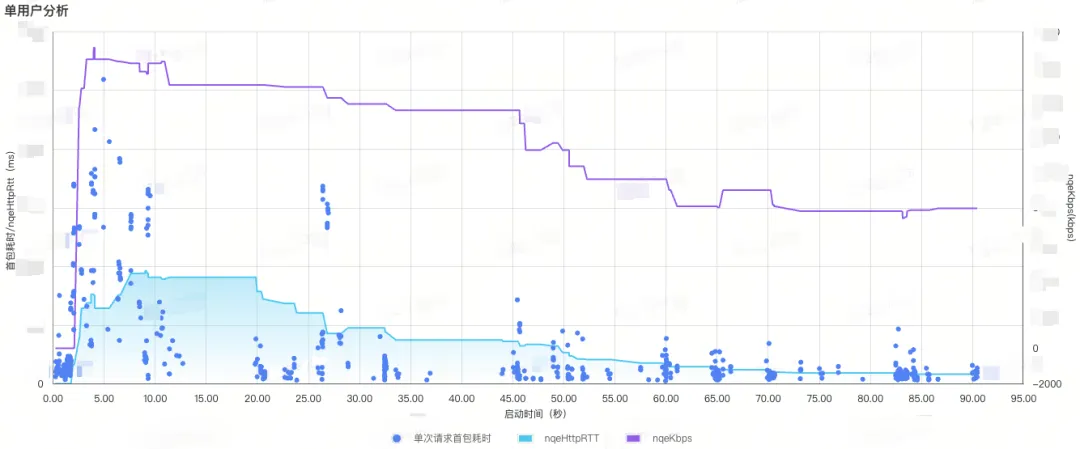
用户C全部请求及HttpRTT、吞吐率
八、应用场景
-
并行Http2.0连接:我们知道HTTP/2.0 支持多路复用,可以同一个TCP连接上进行并发的数据交换,而不像HTTP/1.1需要多个TCP连接。在正常网络环境下能够降低一部分延迟,然在弱网环境下TCP的队头阻塞问题将使请求变得更慢,那么我们在弱网时,并行建连多个H2连接将能在一定程度上缓解此问题;
-
全站加速:应用全站加速时,客户端会建连边缘节点,而不是中心业务服务器,这将能降低客户端到服务器的TCP RTT,从而响应速度、成功率得到提升,弱网环境下更契合全站加速的应用场景;
-
音视频降质:弱网时,降低画质以快速加载要好于加载速度慢;
-
预加载优化:当前App内有各式各样的预加载,其本意是为了加速页面访问速度,提升用户体验。然而弱网时可能会适得其反。弱网时,根据网络环境评级,逐步降低预加载数据,将带宽让给前台网络请求将能提升页面加载速度。
九、总结
通过监听App内的Http请求,按照一定策略采集HttpRTT、吞吐率样本,以加权中位数(时间权重、信号强度权重)的方式综合估算出HttpRTT、吞吐率,最后根据HttpRTT、吞吐率按照一定的策略划分出真实网络类型。经线上数据验证,弱网用户占比0.65%,而弱网请求中仅5%以下耗时低于50分位,具有明显的区分性。后续可应用于网络连接优化、全站加速、音视频降质等多个场景。
*文 / 厉飞雨
本文属得物技术原创,更多精彩文章请看:得物技术
未经得物技术许可严禁转载,否则依法追究法律责任!














![[C++] string管理:深浅拷贝写时拷贝](https://img-blog.csdnimg.cn/img_convert/09f829ec3a33b347a474d2c12728c7a4.png)
