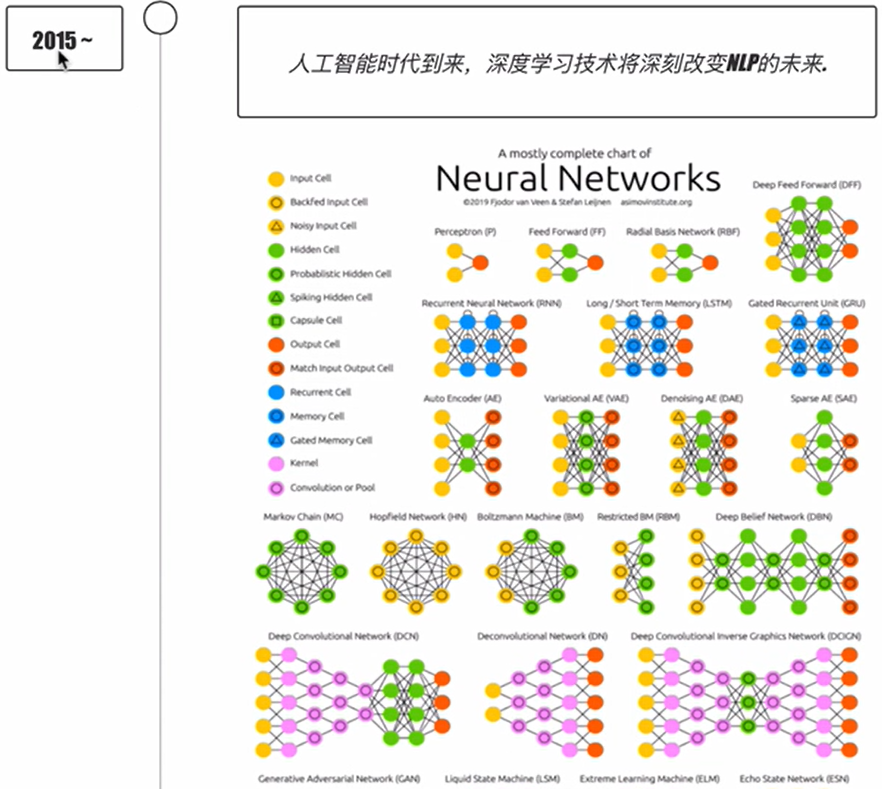
TensorFlow是一种基于数据流编程的开源软件库,是人工智能领域中的重要工具,广泛应用于深度学习、自然语言处理等领域。
TensorFlow的基本概念包括:
-
张量(Tensor):存储和传递数据的多维数组,包括标量、向量、矩阵等。
-
计算图(Graph):用于描述数据流的有向无环图,图中节点表示操作,边表示数据流。
-
会话(Session):用于执行计算图中的操作,并将输出结果返回。
TensorFlow的使用场景包括:
-
图像识别和处理:使用卷积神经网络训练模型进行图像分类、目标检测、图像分割等任务。
-
自然语言处理:使用循环神经网络和长短时记忆网络等模型进行文本分类、情感分析、机器翻译等任务。
-
聚类和降维:使用自编码器等模型对数据进行聚类和降维,提取数据特征。
-
强化学习:使用强化学习算法构建智能体,并使用TensorFlow训练智能体模型。以下是一些例子,可以帮助新手更容易地理解和学习:
具体实例
- 图像分类:使用 TensorFlow 实现图像分类模型,并将其应用于车辆识别。以下是示例代码:
import tensorflow as tf# 读取数据
dataset = tf.keras.preprocessing.image_dataset_from_directory(directory='path/to/data',validation_split=0.3,subset="training",seed=123,image_size=(224, 224),batch_size=32)# 创建模型
model = tf.keras.models.Sequential([tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(224, 224, 3)),tf.keras.layers.MaxPooling2D((2,2)),tf.keras.layers.Conv2D(64, (3,3), activation='relu'),tf.keras.layers.MaxPooling2D((2,2)),tf.keras.layers.Conv2D(128, (3,3), activation='relu'),tf.keras.layers.MaxPooling2D((2,2)),tf.keras.layers.Flatten(),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.5),tf.keras.layers.Dense(3)
])# 编译模型
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])# 训练模型
history = model.fit(dataset, epochs=10, validation_data=validation_dataset)
- 文本分类:使用 TensorFlow 实现文本分类模型,并将其应用于垃圾邮件过滤。以下是示例代码:
import tensorflow as tf# 读取数据
dataset = tf.data.TextLineDataset('path/to/data').map(lambda x: (x[:-1], tf.cast(tf.strings.regex_full_match(x[-1], 'ham'), tf.int32)))# 创建模型
model = tf.keras.Sequential([tf.keras.layers.Embedding(input_dim=5000, output_dim=16, input_length=100),tf.keras.layers.Flatten(),tf.keras.layers.Dense(1, activation='sigmoid')
])# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])# 训练模型
model.fit(dataset.batch(32), epochs=10)
- 目标检测:使用 TensorFlow 实现目标检测模型,并将其应用于行人检测。以下是示例代码:
import tensorflow as tf# 读取数据
train_dataset = tf.data.Dataset.from_generator(lambda: generator('path/to/train'), output_types=(tf.string)).map(parse_data).shuffle(10000).batch(32)
val_dataset = tf.data.Dataset.from_generator(lambda: generator('path/to/val'), output_types=(tf.string)).map(parse_data).batch(32)# 创建模型
model = tf.keras.models.Sequential([tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(256, 256, 3)),tf.keras.layers.MaxPooling2D((2, 2)),tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),tf.keras.layers.MaxPooling2D((2, 2)),tf.keras.layers.Conv2D(128, (3, 3), activation='relu'),tf.keras.layers.MaxPooling2D((2, 2)),tf.keras.layers.Flatten(),tf.keras.layers.Dense(512, activation='relu'),tf.keras.layers.Dropout(0.5),tf.keras.layers.Dense(1),
])# 编译模型
model.compile(optimizer='adam',loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),metrics=['accuracy'])# 训练模型
history = model.fit(train_dataset, epochs=10, validation_data=val_dataset)