写在前面:
首先感谢兄弟们的订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。
路虽远,行则将至;事虽难,做则必成。只要有愚公移山的志气、滴水穿石的毅力,脚踏实地,埋头苦干,积跬步以至千里,就一定能够把宏伟目标变为美好现实。
历史文章回顾:
灰狼优化算法:【智能优化算法】灰狼优化算法【附python实现代码】
白鲸优化算法:【智能优化算法】白鲸优化算法【附python实现代码】
【智能优化算法】粒子群优化KNN分类算法【附python实现代码】
【智能优化算法】粒子群优化随机森林分类算法【附python实现代码】
【智能优化算法】粒子群优化LightGBM分类算法【附python实现代码】
【模型参数优化】网格搜索对随机森林分类模型进行参数寻优【附python实现代码】
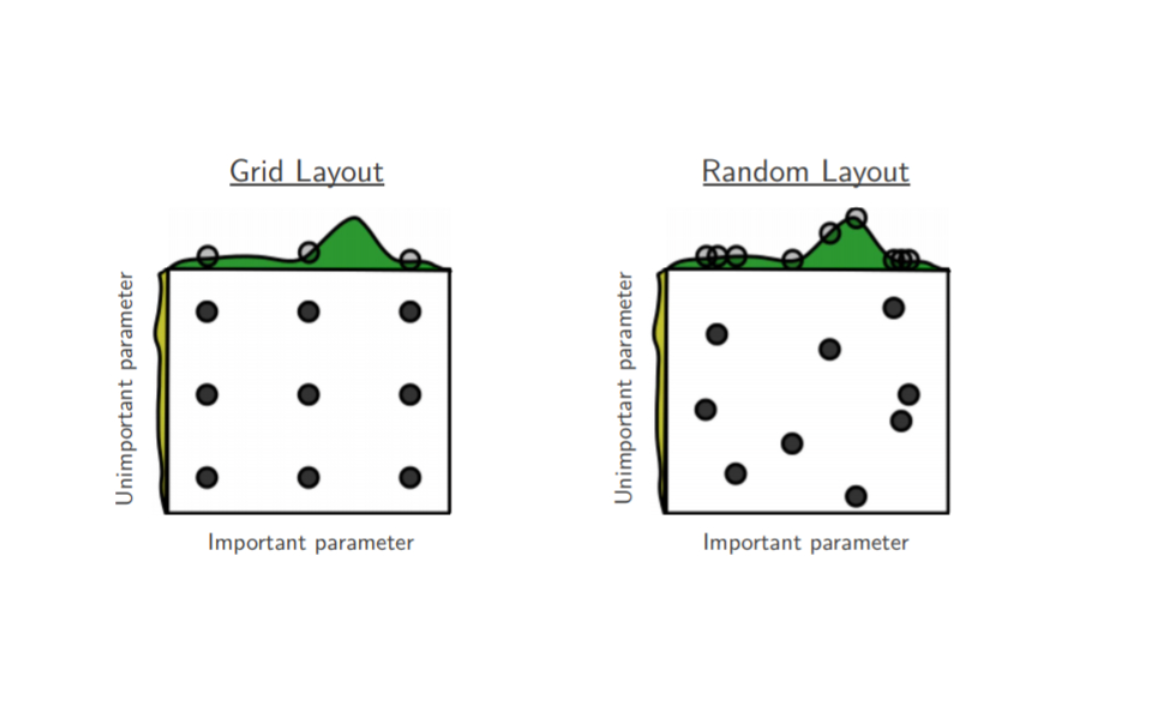
1、介绍
随机搜索(random search)是一种利用随机数求极小点来求得函数近似的最优解的方法。在变量允许的变化区间内,算法会不断随机地而非有倾向性地产生随机点,并计算这些点的约束函数和目标函数的值。对于满足约束条件的点,算法会逐个比较其目标函数的值,将表现较差的点抛弃,保留表现较好的点,最终得到最优解的近似解。
随机搜索算法是建立在概率论的基础上的,所取随机点越多,得到最优解的概率也就越大。由于其简单性和通用性,随机搜索算法可以用于各种不同类型的问题,包括优化问题、组合问题和约束问题等。例如,在优化问题中,随机搜索算法可以用于寻找最小值或最大值;在组合问题中,如旅行商问题,随机搜索算法可以用于找到旅行的最短路径;在约束问题中,如最大流问题,随机搜索算法可以用于找到最大的流量总和。
然而,随机搜索算法也存在一些缺点。首先,它可能会陷入局部最优解而无法找到全局最优解。其次,它的收敛速度较慢,相比其他优化算法需要更多的时间和计算资源。此外,随机搜索算法的性能高度依赖于初始解决方案的选择,如果初始解选择不当,可能会导致算法无法找到最优解。在处理高维超参数空间时,随机搜索算法也容易陷入低效的情况,因为它可能需要很多次采样才能找到最优的超参数组合。同时,随机搜索模型假设超参数之间是相互独立的,这可能会导致一些组合不合理的超参数被选中,从而影响优化的效果。
常用的随机搜索方法包括随机跳跃法和随机走步法等。这些方法通过随机地生成新的解,并在满足一定条件的情况下接受这些解来逼近最优解。在实际应用中,可以根据问题的具体性质和需求选择适合的随机搜索方法。
【From 大模型】
2、实战代码
使用随机搜索对随机森林分类模型进行参数寻优:
# -*- coding: utf-8 -*-
"""
Created on Fri May 3 21:55:32 2024@author: 63454https://zhuanlan.zhihu.com/p/647588686
"""from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import time# 加载数据集
wine = load_wine()
X = wine.data
y = wine.target # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10) print("---------------------使用默认参数----------------------------")
# 初始化随机森林分类器
model = RandomForestClassifier(random_state=99)
# 训练
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print("默认参数 accuracy:", acc)print("---------------------参数寻优----------------------------")
t1 = time.time()
# 定义参数网格
param_grid = { 'n_estimators': [500, 600, 700, 800], # range(500, 1000)'max_depth': [None, 5, 10, 15, 20], 'min_samples_split': [2, 5, 10], 'min_samples_leaf': [1, 2, 3, 4, 5, 6, 7, 8], 'max_features': ['auto', 'sqrt', 'log2'], 'bootstrap': [True, False],
} # 初始化随机森林分类器
model = RandomForestClassifier(random_state=99)
# 初始化网格搜索对象
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5, scoring='accuracy', verbose=2)
# 执行网格搜索
grid_search.fit(X_train, y_train)
t2 = time.time()
# 输出最优参数
print("Best parameters:")
print()
print(grid_search.best_params_)
print("time:", t2-t1)print("---------------------最优模型----------------------------")
model_best_params = grid_search.best_params_
model = grid_search.best_estimator_
# 训练
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print("最优参数 accuracy:", acc)终端输出:
[CV] END bootstrap=True, max_depth=None, max_features=sqrt, min_samples_leaf=5, min_samples_split=5, n_estimators=629; total time= 0.2s
[CV] END bootstrap=True, max_depth=None, max_features=sqrt, min_samples_leaf=5, min_samples_split=5, n_estimators=629; total time= 0.2s
[CV] END bootstrap=True, max_depth=None, max_features=sqrt, min_samples_leaf=5, min_samples_split=5, n_estimators=629; total time= 0.2s
[CV] END bootstrap=True, max_depth=None, max_features=sqrt, min_samples_leaf=5, min_samples_split=5, n_estimators=629; total time= 0.2s
[CV] END bootstrap=True, max_depth=None, max_features=auto, min_samples_leaf=7, min_samples_split=5, n_estimators=129; total time= 0.0s
[CV] END bootstrap=True, max_depth=None, max_features=auto, min_samples_leaf=7, min_samples_split=5, n_estimators=129; total time= 0.0s
[CV] END bootstrap=True, max_depth=None, max_features=auto, min_samples_leaf=7, min_samples_split=5, n_estimators=129; total time= 0.0s
[CV] END bootstrap=True, max_depth=None, max_features=auto, min_samples_leaf=7, min_samples_split=5, n_estimators=129; total time= 0.0s
[CV] END bootstrap=True, max_depth=None, max_features=auto, min_samples_leaf=7, min_samples_split=5, n_estimators=129; total time= 0.0s
[CV] END bootstrap=True, max_depth=10, max_features=log2, min_samples_leaf=8, min_samples_split=10, n_estimators=1986; total time= 0.9s
[CV] END bootstrap=True, max_depth=10, max_features=log2, min_samples_leaf=8, min_samples_split=10, n_estimators=1986; total time= 0.9s
[CV] END bootstrap=True, max_depth=10, max_features=log2, min_samples_leaf=8, min_samples_split=10, n_estimators=1986; total time= 0.8s
[CV] END bootstrap=True, max_depth=10, max_features=log2, min_samples_leaf=8, min_samples_split=10, n_estimators=1986; total time= 0.9s
[CV] END bootstrap=True, max_depth=10, max_features=log2, min_samples_leaf=8, min_samples_split=10, n_estimators=1986; total time= 0.9s
[CV] END bootstrap=False, max_depth=15, max_features=sqrt, min_samples_leaf=6, min_samples_split=10, n_estimators=1855; total time= 0.6s
[CV] END bootstrap=False, max_depth=15, max_features=sqrt, min_samples_leaf=6, min_samples_split=10, n_estimators=1855; total time= 0.6s
[CV] END bootstrap=False, max_depth=15, max_features=sqrt, min_samples_leaf=6, min_samples_split=10, n_estimators=1855; total time= 0.6s
[CV] END bootstrap=False, max_depth=15, max_features=sqrt, min_samples_leaf=6, min_samples_split=10, n_estimators=1855; total time= 0.6s
[CV] END bootstrap=False, max_depth=15, max_features=sqrt, min_samples_leaf=6, min_samples_split=10, n_estimators=1855; total time= 0.6s
[CV] END bootstrap=False, max_depth=20, max_features=sqrt, min_samples_leaf=1, min_samples_split=2, n_estimators=827; total time= 0.2s
[CV] END bootstrap=False, max_depth=20, max_features=sqrt, min_samples_leaf=1, min_samples_split=2, n_estimators=827; total time= 0.2s
[CV] END bootstrap=False, max_depth=20, max_features=sqrt, min_samples_leaf=1, min_samples_split=2, n_estimators=827; total time= 0.2s
[CV] END bootstrap=False, max_depth=20, max_features=sqrt, min_samples_leaf=1, min_samples_split=2, n_estimators=827; total time= 0.2s
[CV] END bootstrap=False, max_depth=20, max_features=sqrt, min_samples_leaf=1, min_samples_split=2, n_estimators=827; total time= 0.2s
[CV] END bootstrap=False, max_depth=5, max_features=log2, min_samples_leaf=6, min_samples_split=10, n_estimators=1316; total time= 0.4s
[CV] END bootstrap=False, max_depth=5, max_features=log2, min_samples_leaf=6, min_samples_split=10, n_estimators=1316; total time= 0.4s
[CV] END bootstrap=False, max_depth=5, max_features=log2, min_samples_leaf=6, min_samples_split=10, n_estimators=1316; total time= 0.4s
[CV] END bootstrap=False, max_depth=5, max_features=log2, min_samples_leaf=6, min_samples_split=10, n_estimators=1316; total time= 0.4s
[CV] END bootstrap=False, max_depth=5, max_features=log2, min_samples_leaf=6, min_samples_split=10, n_estimators=1316; total time= 0.4s
Best parameters:{'n_estimators': 868, 'min_samples_split': 2, 'min_samples_leaf': 7, 'max_features': 'auto', 'max_depth': 5, 'bootstrap': False}
time: 27.28244972229004
---------------------最优模型----------------------------
最优参数 accuracy: 0.8888888888888888
3、总结
随机搜索(Random Search)作为一种优化方法,具有其独特的优点和缺点。以下是随机搜索的主要优缺点:
优点:
- 简单性:随机搜索的实现非常简单,不需要复杂的数学推导或梯度计算。
- 全局性:由于搜索是随机的,随机搜索能够探索整个搜索空间,而不仅仅是局部区域,因此它有可能找到全局最优解,而不仅仅是局部最优解。
- 灵活性:随机搜索对问题的具体形式没有严格要求,可以应用于连续空间或离散空间,以及有约束或无约束的优化问题。
- 并行性:随机搜索可以很容易地并行化,通过同时评估多个随机样本,可以显著提高搜索效率。
缺点:
- 计算效率:相比于其他更复杂的优化算法(如梯度下降、遗传算法等),随机搜索的计算效率通常较低。因为它需要评估大量的随机样本,其中很多样本可能并不接近最优解。
- 收敛速度:随机搜索的收敛速度较慢。它可能需要大量的迭代次数才能找到接近最优解的参数组合。
- 精度问题:由于随机搜索的随机性,它可能无法找到精确的最优解,而只能找到接近最优解的近似解。
- 资源消耗:当搜索空间非常大或目标函数评估代价很高时,随机搜索可能会消耗大量的计算资源。
- 对初始条件的敏感性:虽然随机搜索具有全局搜索能力,但它的性能仍然受到初始条件的影响。如果初始搜索点远离最优解,那么可能需要更多的迭代次数才能找到接近最优解的参数组合。
- 缺乏方向性:随机搜索没有明确的搜索方向,它完全依赖于随机性来探索搜索空间。这可能导致搜索过程缺乏方向性,从而增加了找到最优解的难度。
综上所述,随机搜索作为一种优化方法具有其独特的优点和缺点。在实际应用中,需要根据问题的具体特点和需求来选择合适的优化方法。
参考:
https://blog.csdn.net/qq_41076797/article/details/102755904
https://zhuanlan.zhihu.com/p/647588686