note
- 图生文应用场景:比如电商领域根据产品图像生成产品描述、娱乐领域中根据电影海报生成电影介绍等
- MiniGPT-4将预训练的大语言模型和视觉编码器参数同时冻结,只需要单独训练线性投影层,使视觉特征和语言模型对齐。
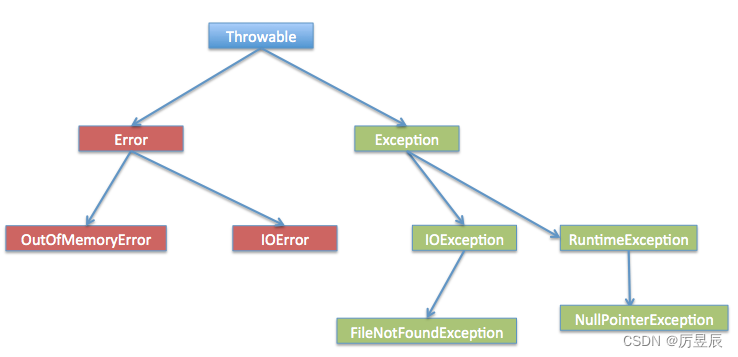
- MiniGPT4的视觉编码器:使用了与BLIP-2相同的预训练视觉语言模型,该模型由2个部分组成:
- 视觉编码器ViT(vision transformer):提取图像中的基本视觉特征。miniGPT-4使用了EVA-CLIP中的ViT-G/14进行实现(初始化该模块的代码如下)
- 图文对齐模块Q-former:进一步将视觉编码与文本编码对齐,得到语言模型可以理解的向量编码
文章目录
- note
- 零、
- 一、MiniGPT模型
- 1. Vicuna 模型
- 2. 视觉编码器
- 3. 线性投影层
- 二、训练过程
- 1. 预训练
- 2. 微调训练
- Reference
零、
一、MiniGPT模型
项目链接:https://github.com/Vision-CAIR/MiniGPT-4
多模态LLM的任务类型:

MiniGPT-4模型架构:三部分,预训练的大语言模型,预训练的视觉编码器以及一个单一的线性投影层。

1. Vicuna 模型
decoder类型的语言模型,其在miniGPT-4中任务是理解输入进来的文本和图像数据,对多模信息有感知理解能力,生成符合指令的文本描述。MiniGPT-4 并不从头开始训练大语言模型,而是直接利用现有的 Vicuna-13B 或 Vicuna-7B 版本,冻结所有的参数权重,降低计算开销。
2. 视觉编码器
使用了与BLIP-2相同的预训练视觉语言模型,该模型由2个部分组成:
- 视觉编码器ViT(vision transformer):提取图像中的基本视觉特征。miniGPT-4使用了EVA-CLIP中的ViT-G/14进行实现(初始化该模块的代码如下)
- 图文对齐模块Q-former:进一步将视觉编码与文本编码对齐,得到语言模型可以理解的向量编码
(1)视觉编码器ViT:miniGPT-4使用了EVA-CLIP中的ViT-G/14进行实现
# miniGPT-4使用了EVA-CLIP中的ViT-G/14进行实现def init_vision_encoder(cls, model_name, img_size, drop_path_rate, use_grad_checkpoint, precision, freeze):logging.info('Loading VIT')assert model_name == "eva_clip_g", "vit model must be eva_clip_g for current version of MiniGPT-4"if not freeze:precision = "fp32" # fp16 is not for trainingvisual_encoder = create_eva_vit_g(img_size, drop_path_rate, use_grad_checkpoint, precision)ln_vision = LayerNorm(visual_encoder.num_features)if freeze:for name, param in visual_encoder.named_parameters():param.requires_grad = Falsevisual_encoder = visual_encoder.eval()visual_encoder.train = disabled_trainfor name, param in ln_vision.named_parameters():param.requires_grad = Falseln_vision = ln_vision.eval()ln_vision.train = disabled_trainlogging.info("freeze vision encoder")logging.info('Loading VIT Done')return visual_encoder, ln_vision
miniGPT-4使用了EVA-CLIP中的ViT-G/14进行实现(初始化该模块的代码如上),其中:
img_size表示输入图像的尺寸;drop_path_rate表示使用 drop_path 的比例,这是一种正则化技术;use_grad_checkpoint表示是否使用梯度检查点技术来减少内存使用;precision表示训练过程中的精度设置。
该函数通过创建 ViT 视觉编码器模型,将输入图像转换为特征表示。
(2)图文对齐模块Q-former:通常使用预训练的BERT模型,通过计算图像编码和查询(一组可学习的参数)之间的交叉注意力,更好将图像emb和文本emb对齐。初始化该模块代码如下:
def init_Qformer(cls, num_query_token, vision_width, freeze):# 使用预训练的bert模型配置q-formerencoder_config = BertConfig.from_pretrained("bert-base-uncased")encoder_config.encoder_width = vision_width# insert cross-attention layer every other blockencoder_config.add_cross_attention = Trueencoder_config.cross_attention_freq = 2# 设置查询长度encoder_config.query_length = num_query_tokenQformer = BertLMHeadModel(config=encoder_config)# 创建查询标记并初始化,是一组可训练的参数,用于查询图像和文本之间的关系query_tokens = nn.Parameter(torch.zeros(1, num_query_token, encoder_config.hidden_size))query_tokens.data.normal_(mean=0.0, std=encoder_config.initializer_range)Qformer.cls = NoneQformer.bert.embeddings.word_embeddings = NoneQformer.bert.embeddings.position_embeddings = Nonefor layer in Qformer.bert.encoder.layer:layer.output = Nonelayer.intermediate = Noneif freeze:for name, param in Qformer.named_parameters():param.requires_grad = FalseQformer = Qformer.eval()Qformer.train = disabled_trainquery_tokens.requires_grad = Falselogging.info("freeze Qformer")# 返回初始化的q-former模型、查询标记return Qformer, query_tokens
3. 线性投影层
- 视觉编码器虽然已经在广泛的图像-文本任务中做了预训练,但它们本质上没有针对 LLaMA、Vicuna 等大语言模型做过微调。为了弥补视觉编码器和大语言模型之间的差距,MiniGPT-4 增加了一个可供训练的线性投影层,期望通过训练将编码的视觉特征与 Vicuna 语言模型对齐。
- 通过定义一个可训练的线性投影层,将 Q-Former 输出的图像特征映射到大语言模型的表示空间,以便结合后续的文本输入做进一步的处理和计算。
- miniGPT-4模型的前向传播过程如下:
self.llama_proj = nn.Linear(img_f_dim, self.llama_model.config.hidden_size
)def encode_img(self, image):device = image.deviceif len(image.shape) > 4:image = image.reshape(-1, *image.shape[-3:])with self.maybe_autocast():# 使用视觉编码器对图像编码后,再使用LayerNorm标准化image_embeds = self.ln_vision(self.visual_encoder(image)).to(device)# 默认使用冻结的q-formerif self.has_qformer:# 创建图像的注意力掩码image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(device)# 扩展查询标记以匹配图像特征的维度query_tokens = self.query_tokens.expand(image_embeds.shape[0], -1, -1)# 使用q-former模块计算查询标记和图像特征的交叉注意力,以更好的对齐图像和文本query_output = self.Qformer.bert(query_embeds=query_tokens,encoder_hidden_states=image_embeds,encoder_attention_mask=image_atts,return_dict=True,)# 通过线性投影层将q-former的output映射到语言模型的输入inputs_llama = self.llama_proj(query_output.last_hidden_state)else:image_embeds = image_embeds[:, 1:, :]bs, pn, hs = image_embeds.shapeimage_embeds = image_embeds.view(bs, int(pn / 4), int(hs * 4))inputs_llama = self.llama_proj(image_embeds)# 创建语言模型的注意力掩码atts_llama = torch.ones(inputs_llama.size()[:-1], dtype=torch.long).to(image.device)# 返回最终输入语言模型中的图像编码、注意力掩码return inputs_llama, atts_llama
miniGPT-4将预训练的大语言模型和视觉编码器参数同时冻结,只需要单独训练线性投影层,使视觉特征和语言模型对齐。
二、训练过程
1. 预训练
- 预训练数据:Conceptual Caption[175, 176]、SBU[177] 和 LAION[178] 的组合数据集进行模型预训练
- 预训练共进行了约 2 万步,批量大小为 256,覆盖了 500 万个图像-文本
对,在 4 张 A100 上训练了 10 个小时。
def preparing_embedding(self, samples):### prepare input tokensif 'image' in samples:# 对输入图像进行编码img_embeds, img_atts = self.encode_img(samples["image"])else:img_embeds = img_atts = Noneif 'conv_q' in samples:# handeling conversation datasetsconv_q, conv_a = samples['conv_q'], samples['conv_a']connect_sym = samples['connect_sym'][0]conv_q = [q.split(connect_sym)for q in conv_q]conv_a = [a.split(connect_sym) for a in conv_a]conv_q = [[self.prompt_template.format(item) for item in items] for items in conv_q]cond_embeds, cond_atts = self.prompt_wrap(img_embeds, img_atts, [q[0] for q in conv_q])regress_token_ids, regress_atts, part_targets = self.tokenize_conversation(conv_q, conv_a)else:# 生成文本指令if "instruction_input" in samples:instruction = samples["instruction_input"]elif self.prompt_list:instruction = random.choice(self.prompt_list)else:instruction = Noneif hasattr(self, 'chat_template') and self.chat_template:instruction = [self.prompt_template.format(instruct) for instruct in instruction]if 'length' in samples:# the input is a image train (like videos)bsz, pn, hs = img_embeds.shapeimg_embeds = img_embeds.reshape(len(samples['image']), -1, pn, hs)# 将指令包装到提示中cond_embeds, cond_atts = self.prompt_wrap(img_embeds, img_atts, instruction, samples['length'])else:cond_embeds, cond_atts = self.prompt_wrap(img_embeds, img_atts, instruction)### prepare target tokens# 配置tokenizer以正确处理文本输入self.llama_tokenizer.padding_side = "right"text = [t + self.end_sym for t in samples["answer"]]# 使用tokenizer对文本进行编码regress_tokens = self.llama_tokenizer(text,return_tensors="pt",padding="longest",truncation=True,max_length=self.max_txt_len,add_special_tokens=False).to(self.device)regress_token_ids = regress_tokens.input_idsregress_atts = regress_tokens.attention_maskpart_targets = regress_token_ids.masked_fill(regress_token_ids == self.llama_tokenizer.pad_token_id, -100)# 连接图像编码、图像注意力、文本编码和文本注意力regress_embeds = self.embed_tokens(regress_token_ids)return cond_embeds, cond_atts, regress_embeds, regress_atts, part_targetsdef forward(self, samples, reduction='mean'):# prepare the embedding to condition and the embedding to regresscond_embeds, cond_atts, regress_embeds, regress_atts, part_targets = \self.preparing_embedding(samples)# concat the embedding to condition and the embedding to regressinputs_embeds, attention_mask, input_lens = \self.concat_emb_input_output(cond_embeds, cond_atts, regress_embeds, regress_atts)# get bos token embeddingbos = torch.ones_like(part_targets[:, :1]) * self.llama_tokenizer.bos_token_idbos_embeds = self.embed_tokens(bos)bos_atts = cond_atts[:, :1]# add bos token at the begining# 获得整体的输入编码和注意力掩码inputs_embeds = torch.cat([bos_embeds, inputs_embeds], dim=1)attention_mask = torch.cat([bos_atts, attention_mask], dim=1)# ensemble the final targets# 创建完整的目标序列,用于计算损失targets = torch.ones([inputs_embeds.shape[0], inputs_embeds.shape[1]],dtype=torch.long).to(self.device).fill_(-100)for i, target in enumerate(part_targets):targets[i, input_lens[i]+1:input_lens[i]+len(target)+1] = target # plus 1 for bos# 在自动混合精度环境下,计算语言模型的输出with self.maybe_autocast():outputs = self.llama_model(inputs_embeds=inputs_embeds,attention_mask=attention_mask,return_dict=True,labels=targets,reduction=reduction)loss = outputs.lossreturn {"loss": loss}
2. 微调训练
- 预训练后的模型一般不能直接生成符合用户意图的文本输出,多模态LLM这里一样和语言模型类似可以进行指令微调和RLHF
- 优化策略1:改prompt让多模态LLM回答详细:
###Human: <Img><ImageFeature></Img> Describe this image in detail.
Give as many details as possible. Say everything you see. ###Assistant:
- 优化策略2:筛选高质量SFT图文对微调数据,用如下prompt+chatGPT的方法进行筛选,修正文本中的语义、语法错误or结构问题。最终miniGPT4作者从5k条图文文本对数据中筛出3.5k数据。
Fix the error in the given paragraph.
Remove any repeating sentences, meaningless characters, not English sentences, and so on.
Remove unnecessary repetition. Rewrite any incomplete sentences.
Return directly the results without explanation.
Return directly the input paragraph if it is already correct without explanation.
- 优化策略3:SFT阶段中query可以多样化,比如“详细描述该图像”、“你可以为我描述该图像的内容吗”、“解释这张图为啥有趣?”等。微调训练知识在训练数据和文本提示上与预训练过程略有不同。
- 微调:只需要 400 个训练步骤,批量大小为 12,使用单张 A100 训练 7 分钟即可完成
Reference
[1] https://github.com/Vision-CAIR/MiniGPT-4
[2] MiniGPT-4 知识点汇总
[3] 【vlm多模态大模型】minigpt-4详细解析